







关于数据库优化,网上有不少资料和方法,但是不少质量参差不齐,有些总结的不够到位,内容冗杂。所以小编要结合自己的一些优化经验,做一个小小的总结,积累优质文章,提升个人能力,希望对大家今后开发中也有帮助(篇章内容,实属原创,如有雷同,纯属巧合,不当之处,敬请指正!)
1、优化基本原则
网上有很多这些优化的小技巧,基本的方法的就是使用缓存,走索引等等,其中对于走索引索引的说法也是各种各样,像什么使用or不走索引啊,!= 不走索引等等很多也都是扯犊子, 鉴于这些情况是否走索引,不是一成不变的,mysql会根据表的数据分布情况来决定是否走索引,以下列举部分不走索引的情况,以供参考。
1 列上使用函数或运算索引无效
例:SELECT * FROM t WHERE YEAR(d) >= 2016;
由于MySQL不像Oracle那样支持函数索引,即使d字段有索引,也会直接全表扫描。
应改为—–>
SELECT * FROM t WHERE d >= ‘2016-01-01’;
2 模糊查询以“%”开头
SELECT * FROM t WHERE name LIKE ‘%de%’;
—–>
SELECT * FROM t WHERE name LIKE ‘de%’;
目前只有MySQL5.7支持全文索引(支持中文)
3 数据类型不一致
SELECT * FROM t WHERE id = ’19’;
—–>
SELECT * FROM t WHERE id = 19;
4 分组统计可以禁止排序
SELECT goods_id,count(*) FROM t GROUP BY goods_id;
默认情况下,MySQL对所有GROUP BY col1,col2…的字段进行排序。如果查询包括GROUP BY,想要避免排序结果的消耗,则可以指定ORDER BY NULL禁止排序。
—–>
SELECT goods_id,count(*) FROM t GROUP BY goods_id ORDER BY NULL;
5 禁止不必要的ORDER BY排序
SELECT count(1) FROM user u LEFT JOIN user_info i ON u.id = i.user_id WHERE 1 = 1 ORDER BY u.create_time DESC;
—–>
SELECT count(1) FROM user u LEFT JOIN user_info i ON u.id = i.user_id;
6 批量INSERT插入
INSERT INTO t (id, name) VALUES(1,’Bea’);
INSERT INTO t (id, name) VALUES(2,’Belle’);
INSERT INTO t (id, name) VALUES(3,’Bernice’);
—–>
INSERT INTO t (id, name) VALUES(1,’Bea’), (2,’Belle’),(3,’Bernice’);
2、连表查询优化策略
在实际查询中,大部分查询都会涉及到多表的查询,就让我们一起来看看多表查询中的一些优化策略吧。MySQL 表关联的算法是 Nest Loop Join, NestedLoopJoin实际上就是通过驱动表的结果集作为循环基础数据,然后一条一条的通过该结果集中的数据作为过滤条件到下一个表中查询数据,然后合并结果。如果还有第三个参与Join,则再通过前两个表的Join结果集作为循环基础数据,再一次通过循环查询条件到第三个表中查询数据,如此往复
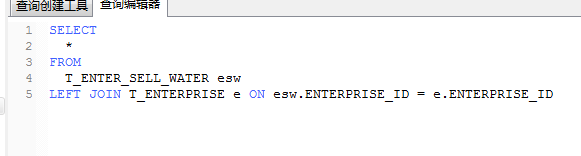
对于此种类型的查询esw就是驱动表,e就是被驱动表,我们要做的就是尽量用小的结果集去驱动大的结果集,对于左连接而言,右表示我们优化的关键,因为查询结果会取esw中的每条记录去过滤e表,所以在这里,小编的个人建议是给所有表的外键字段(T_ENTERPRISE表的ENTERPRISE_ID字段)都加上索引,以此来提高检索速度。
对于网上说的,在多表连接查询的时候通过子查询来缩小驱动表的结果集数量,来达到优化的目的。是否子查询真的能达到一个优化的效果,这里我们暂不做结论,且待下回分解。
3. 索引冲突与解决方案
索引冲突与解决方案,是小编本次要重要讲的内容,在一张表中可能会有多个索引,但是每次mysql只会用其中的一个索引,那到底mysql会选择哪个索引呢?且让我们探究一二。。。无图无真相,机智的小编要开始上图了。

这个表索引贼多,如果查询的时候用到多个索引的列,那么它会 使用哪个索引呢?我们继续上图~

在这里我们可以看到在where条件的三个列上都是有索引的,然而mysql选择的是主键索引。难道是主键比较特别的原因?

在这里我们去掉了id字段,我们发现它使用了SALE_ID字段对应的索引,
在图一中执行show index from T_sale_item显示的信息中我们可以发现cardinality字段,该字段的意思是索引字段唯一值出现的个数,该字段值越大,则表示该索引越有效,无疑的表主键的唯一值是最大的,在这个表中brand_code对应的cardinality字段的值是最小的,也就是说创建该索引的意义不大。
综上所述,在遇到多个索引字段同时使用的时候,mysql会优先使用cardinality值中值最大的那个对应的索引。
通过了以上知识的分析,让我们一起来一波sql优化实战吧~

我们可以看到这里我们的查询时间用了77秒,我们再来分析一波这个sql的执行计划。。。

T_SALE_ITEM表中sale_ID与brand_Code两个字段都有索引,然而这是在这里执行计划却选择了brand_code字段的索引,这是我们不愿意看到的,因为这会导致T_sale与t_sale_item这两张大表在通过关联字段 s.id = i.sale_id进行连接的时候没有合适的索
引可用,导致了sql的缓慢,在这里小编打算通过人为的手段进行执行计划的干扰来看看效果。。。

在这里,我们ignore index(..)来我强行忽视了品牌的索引(当然了,我们也可以删除这个索引,效果也是一样的),让t_sale_item与t_sale两个大表通过sale_id索引快速形成驱动结果集(至于小表t_brand我们可以忽视它了),达到了一个优化的目标的 ,从优化前的70秒变成0.1秒.。最后我们再看一下优化后的执行计划

我们发现t_sale_item表使用了idx_saleitem_modelcode索引(这个索引名称对应的列也就是sale_id了)。
4.总结
技术有限,mysql优化小编只领略了其中的皮毛,至于跟多优化技巧,容我日后再说,路漫漫其修远兮,吾将上下而求索!















 499
499











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









