







搬运工主要参考来自Calvin luo的论文,扩散模型可以说是近期的圈内的顶流了,本文将试图尽量简要地概括一遍大一统视角下的扩散模型的推导过程
针对的对象主要是对扩散模型已经有一些基础了解的读者。Calvin luo 的这篇论文为理解扩散模型提供了一个统一的视角,尤其是其中的数理公式推导非常详尽,本文将试图尽量简要地概括一遍大一统视角下的扩散模型的推导过程。在结尾处,笔者附上了一些推导过程中的强假设的思考和疑惑,并简要讨论了下扩散模型应用在自然语言处理时的一些思考。
本篇阅读笔记一共参考了以下技术博客。其中如果不了解扩散模型的读者可以考虑先阅读lilian-weng的科普博客。Calvin-Luo的这篇介绍性论文在书写的时候经过了包括Jonathan Ho(DDPM作者), SongYang博士 和一系列相关扩散模型论文的发表者的审核,非常值得一读。
1. What are Diffusion Models? by Lilian Weng
2. Generative Modeling by Estimating Gradients of the Data Distribution by Song Yang
3. Understanding Diffusion Models: A Unified Perspective by Calvin Luo
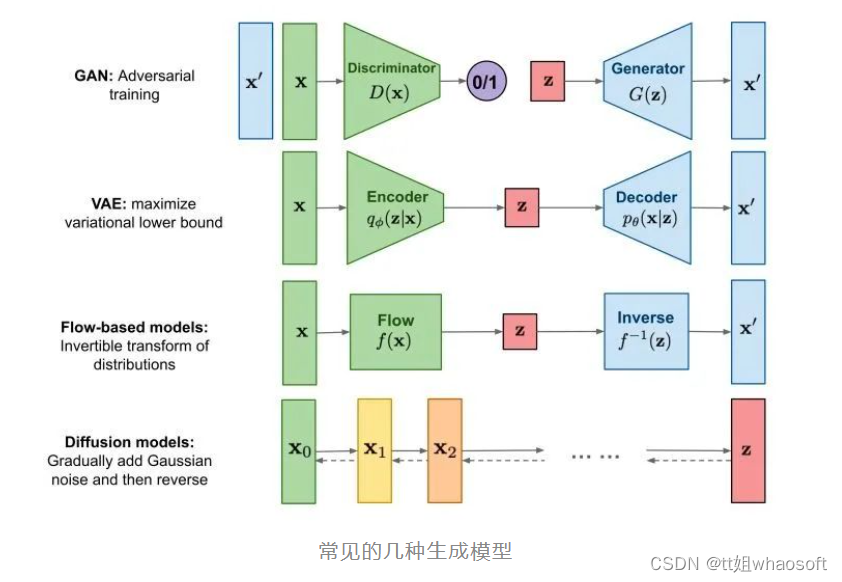
生成模型希望可以生成符合真实分布(或给定数据集)的数据。我们常见的几种生成模型有GANs,Flow-based Models, VAEs, Energy-Based Models 以及我们今天希望讨论的扩散模型Diffusion Models. 其中扩散模型和变分自编码器VAEs, 和基于能量的模型EBMs有一些联系和区别,笔者会在接下来的章节阐述。
ELBO & VAE
在介绍扩散模型前,我们先来回顾一下变分自编码器VAE。我们知道VAE最大的特点是引入了一个潜在向量的分布来辅助建模真实的数据分布。那么为什么我们要引入潜在向量?有两个直观的原因,一个是直接建模高维表征十分困难,常常需要引入很强的先验假设并且有维度诅咒的问题存在。另外一个是直接学习低维的潜在向量,一方面起到了维度压缩的作用,一方面也希望能够在低维空间上探索具有语义化的结构信息(例如图像领域里的GAN往往可以通过操控具体的某个维度影响输出图像的某个具体特征)。
引入了潜在向量后,我们可以将我们的目标分布的对数似然logP(x),也称为“证据evidence“写成下列形式:

其中,我们重点关注式15. 等式的左边是生成模型想要接近的真实数据分布(evidence),等式右边由两项组成,其中第二项的KL散度因为恒大于零,所以不等式恒成立。如果在等式右边减去该KL散度,则我们得到了真实数据分布的下界,即证据下界ELBO。对ELBO进行进一步的展开,我们就可以得到VAE的优化目标

对该证据下界的变形的形式,我们可以直观地这么理解:证据下界等价于这么一个过程,我们用编码器将输入x编码为一个后验的潜在向量分布q(z|x)。我们希望这个向量分布尽可能地和真实的潜在向量分布p(z)相似,所以用KL散度约束,这也可以避免学习到的后验分布q(z|x)坍塌成一个狄拉克delta函数(式19的右侧)。而得到的潜在向量我们用一个解码器重构出原数据,对应的是式19的左边P(x|z)。
VAE为什么叫变分自编码器。变分的部分来自于寻找最优的潜在向量分布q(z|x)的这个过程。自编码器的部分是上面提到的对输入数据的编码,再解码为原数据的行为。
那么提炼一下为什么VAE可以比较好地贴合原数据的分布?因为根据上述的公式推导我们发现:原数据分布的对数似然(称为证据evidence)可以写成证据下界加上我们希望近似的后验潜在向量分布和真实的潜在向量分布间的KL散度(即式15)。如果把该式写为A = B+C的形式。因为evidence(即A)是个常数(与我们要学习的参数无关),所以最大化B,也就是我们的证据下界,等价于最小化C,也即是我们希望拟合的分布和真实分布间的差别。而因为证据下界,我们可以重新写成式19那样一个自编码器的形式,我们也就得到了自编码器的训练目标。优化该目标,等价于近似真实数据分布,也等价于用变分手法来优化后验潜在向量分布q(z|x)的过程。
但VAE自身依然有很多问题。一个最明显的就是我们如何选定后验分布q_phi(z|x)。绝大多数的VAE实现里,这个后验分布被选定为了一个多维高斯分布。但这个选择更多的是为了计算和优化的方便而选择。这样的简单形式极大地限制了模型逼近真实后验分布的能力。VAE的原作者kingma曾经有篇非常经典的工作就是通过引入normalization flow[1]在改进后验分布的表达能力。而扩散模型同样可以看做是对后验分布q_phi(z|x)的改进。
Hierarchical VAE
下图展示了一个变分自编码器里,潜在向量和输入间的闭环关系。即从输入中提取低维的潜在向量后,我们可以通过这个潜在向量重构出输入。
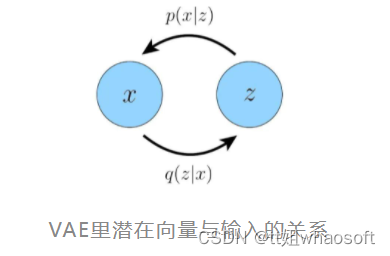
很明显,我们认为这个低维的潜在向量里一定是高效地编码了原数据分布的一些重要特性,才使得我们的解码器可以成功重构出原数据分布里的各式数据。那么如果我们递归式地对这个潜在向量再次计算“潜在向量的潜在向量”,我们就得到了一个多层的HVAE,其中每一层的潜在向量条件于所有前序的潜在向量。但是在这篇文章里,我们主要关注具有马尔可夫性质的层级变分自编码器MHVAE,即每一层的潜在向量仅条件于前一层的潜在向量。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









