







涵盖纯视觉 3D 目标检测、多模态 3D 检测、图像匹配、光流估计、3D 点云配准等领域。
近日,国际计算机视觉大会 ICCV(International Conference on Computer Vision)公布了 2023 年论文录用结果,本届会议共有 8068 篇投稿,接收率为26.8%。ICCV 是全球计算机领域顶级的学术会议,每两年召开一次,ICCV 2023 将于今年10月在法国巴黎举行。今年,旷视研究院 14 篇论文入选,涵盖纯视觉 3D 目标检测、多模态 3D 检测、图像匹配、光流估计、3D 点云配准等领域。以下为入选论文概览:
01
PETRv2: A Unified Framework for 3D Perception from Multi-Camera Images
PETRv2:一个统一的纯视觉 3D 感知框架
PETRv2 是一个统一的纯视觉3D感知的框架。基于 PETR,PETRv2 首先扩展了 PETR 中的 3D 位置编码进行时序建模,实现了不同帧之间物体位置的时序对齐。为了适用于多任务学习(如 BEV 分割和 3D 车道检测),PETRv2 针对不同任务设计了特定的查询向量,并使用统一的 Transformer 解码器进行解码。在 3D 物体检测、BEV 分割和 3D 车道检测方面,PETRv2 都取得了最先进的性能,并对噪声表现出了很强的鲁棒性。我们还对 PETR 框架进行了详细的稳健性分析。我们希望 PETRv2 能作为 3D 感知的一个稳健基础线。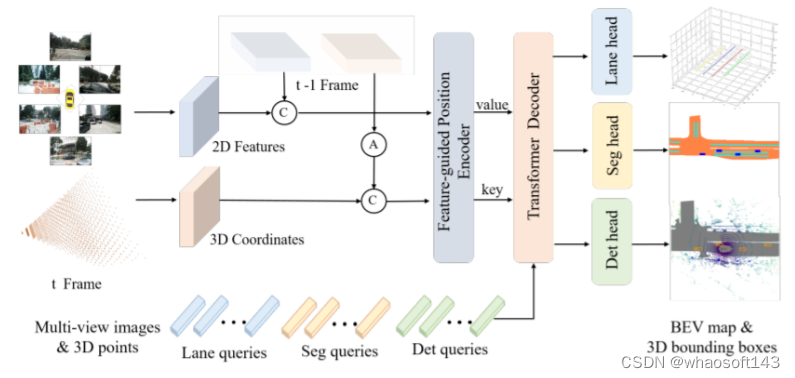 关键词:3D 位置编码,多任务,车道线,鲁棒性论文链接:https://arxiv.org/pdf/2206.01256.pdf代码链接:https://github.com/megvii-research/PETR.git
关键词:3D 位置编码,多任务,车道线,鲁棒性论文链接:https://arxiv.org/pdf/2206.01256.pdf代码链接:https://github.com/megvii-research/PETR.git
02
Exploring Object-Centric Temporal Modeling for Efficient Multi-View 3D Object Detection
StreamPETR:面向纯视觉 3D 检测的以目标为中心的时序建模框架
我们提出了一种长时序建模的纯视觉 3D 目标检测框架——StreamPETR。该算法针对视频流进行设计,用可选择的有限帧进行训练,在测试时可以适应更长的时间帧乃至无限帧。StreamPETR 将使用目标查询组成的 memory queue 作为高效的时序表征,利用注意力机制进行高效时序建模,在几乎不添加额外计算成本的情况下,可以大幅提高单帧检测器的检测性能。在 nuScenes 榜单上,StreamPETR 是第一个与激光雷达性能相当的在线纯视觉 3D 目标检测算法。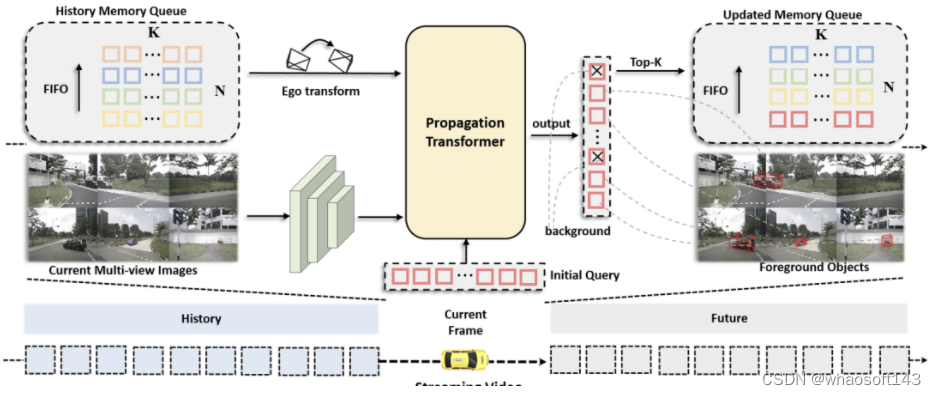 关键词:时序建模,稀疏目标查询,快速
关键词:时序建模,稀疏目标查询,快速
论文链接:https://arxiv.org/pdf/2303.11926.pdf
代码链接:https://github.com/exiawsh/StreamPETR
03
Cross Modal Transformer: Towards Fast and Robust 3D Object Detection
跨模态 Transformer:快速且鲁棒的多模态融合 3D 检测框架
我们提出了一个快速且鲁棒的 3D 检测器——Cross Modal Transformer(CMT)。我们的模型保留了 DETR 的设计,不同模态的特征仅在 token level 进行融合,融合方式就是最简单的 concat 。我们在 nuScenes 测试集上单模型架构取得了 SOTA 的检测结果 74.1% NDS,且推理速度超过所有现有方案。另外,我们的模型具有非常强的鲁棒性,用于对抗传感器损毁以及抖动问题,即使整个 LiDAR 在运行时损毁,我们的模型依旧能保持纯视觉模型的推理精度。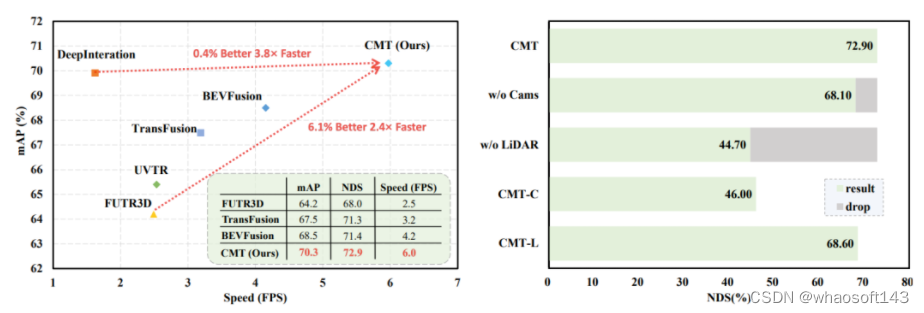 关键词:快速、鲁棒、传感器故障、高精度论文链接:https://arxiv.org/pdf/2301.01283.pdf代码链接:https://github.com/junjie18/CMT
关键词:快速、鲁棒、传感器故障、高精度论文链接:https://arxiv.org/pdf/2301.01283.pdf代码链接:https://github.com/junjie18/CMT
04
OnlineRefer: A Simple Online Baseline for Referring Video Object Segmentation
OnlineRefer:一个简单的在线参考视频目标分割框架
RVOS 任务旨在利用语言指令分割视频目标,而目前主流的方案是 offline model。在本文中,我们打破了以往只有 offline model 适合 RVOS 的认知,并给出了一个 online baseline,名为OnlineRefer。该方法基于 Deformable DETR,使用上一帧的预测框作为当前帧的参考点(query propogation),逐帧分割目标。我们的工作对单帧检测器进行简单的 query propogation,就在 Refer-Youtube-VOS 和 Refer-DAVIS17 上实现了 SOTA 表现, 也期待该工作能够为 Segment Anything Model(SAM)在视频领域的应用提供启发。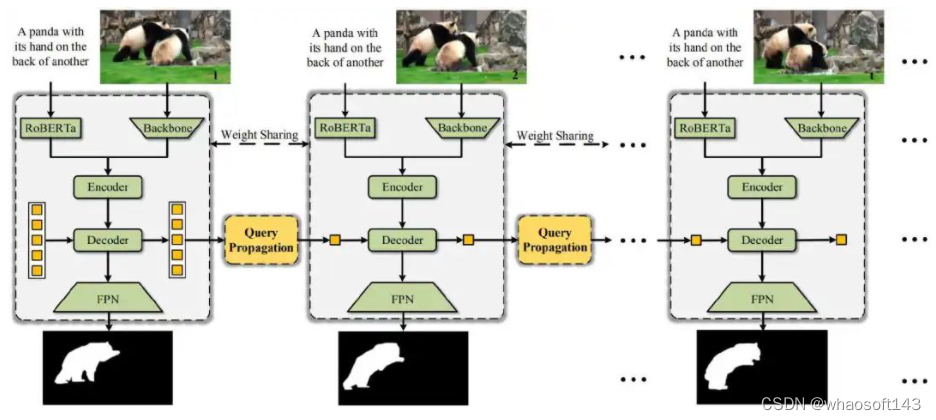
关键词:视频分割、提示词分割、SAM论文链接:https://arxiv.org/abs/2307.09356代码:https://github.com/wudongming97/OnlineRefer
05
Uncertainty Guided Adaptive Warping for Robust and Efficient Stereo Matching
通过由不确定度引导的自适应图像扭曲实现鲁棒高效的立体匹配
对于双目视觉中的深度估计问题,基于关联性的立体匹配技术是目前的主流方案。但现有技术存在着难以使用一套固定参数的模型,在多种复杂场景下维持稳定表现的问题。因此,我们对立体匹配算法的鲁棒性进行了深入研究,提出了基于不确定度引导的自适应图像扭曲模块,设计了新的立体匹配框架 CREStereo++,实现了模型鲁棒性的有效提升。本算法在 Robust Vision Challenge 2022 比赛中取得冠军,其轻量级版本在 KITTI 数据集上与同计算量级的其他算法相比也有更出色的表现。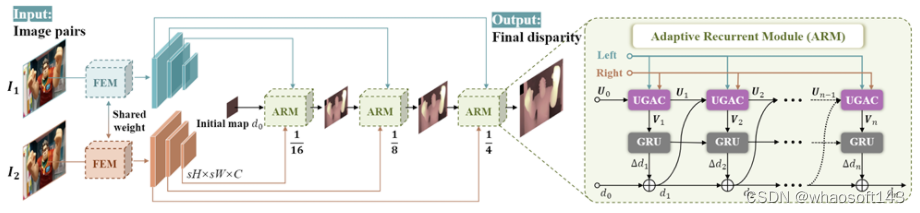
关键词:立体匹配、自适应、鲁棒任务论文链接:https://arxiv.org/abs/2307.14071
06
OccNet:Robust Image Matching Based on 3D Occupancy Estimation for Occluded Regions
带有遮挡的匹配网络:基于3D占据估计的鲁棒的图片匹配网络
图像匹配方法大部分忽略了由于相机运动和场景结构造成的物体之间的遮挡关系。针对这个问题,我们提出了一种名为OccNet的图像匹配方法,它利用3D占位模型来描述物体之间的遮挡关系,并找出遮挡区域内的匹配点。借助占用估计(OE)模块中编码的归纳偏差与遮挡感知(OA)模块结合,OccNet能大幅简化启动多视图一致的3D表征的过程。我们在真实世界和模拟数据集上评估了OccNet的性能,实验结果显示,无论是否在遮挡场景下,OccNet的表现都优于现有的最先进方法。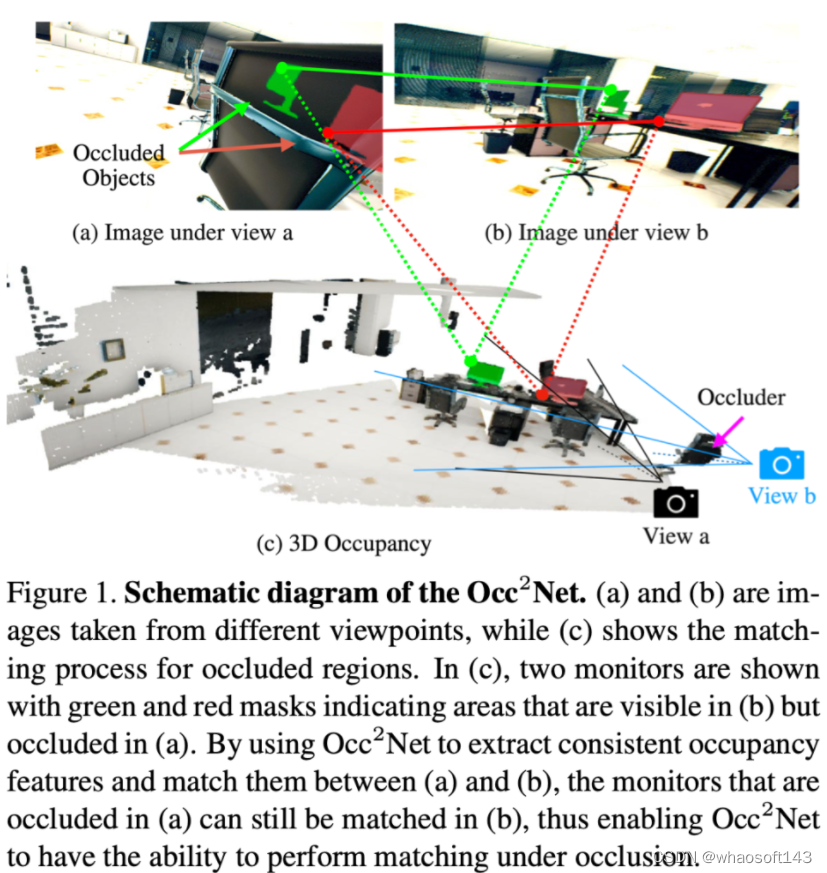 不仅可以匹配可见点,还可以匹配图中的连线(遮挡点)
不仅可以匹配可见点,还可以匹配图中的连线(遮挡点)
关键词:匹配、遮挡、占位估计、3D、位姿
07
DOT: A Distillation-Oriented Trainer
DOT:一个面向蒸馏的优化器
知识蒸馏将大模型中的知识传递给小模型,其损失函数往往包含具体任务损失和蒸馏损失。我们发现引入蒸馏损失后,学生模型的任务损失反而更大了。这是一个不直观的权衡。我们猜测这是因为蒸馏损失优化不足,因为教师模型的任务损失低于学生模型,而较低的蒸馏损失使学生更接近教师,从而获得更好的任务损失收敛。本文针对蒸馏损失优化不足的问题,提出了一种面向蒸馏的优化器 DOT。DOT 分别考虑任务和蒸馏损失的梯度,然后对蒸馏损失应用较大的动量以加速其优化。我们通过实验证明 DOT 打破了这种权衡,即两种损失都得到了充分优化。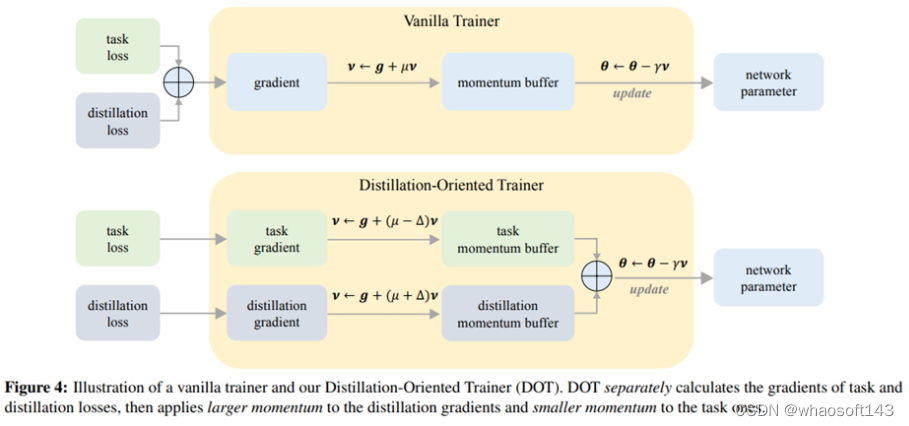
关键词:知识蒸馏、优化算法、动量法论文链接:https://arxiv.org/abs/2307.08436
08
Cumulative Spatial Knowledge Distillation for Vision Transformers
用于 ViT 的渐变空间知识蒸馏
从 CNN 中提取知识对于 ViT 来说是一把双刃剑。CNN 的图像友好的局部归纳偏差有助于 ViT 更快、更好地学习,但带来了两个问题:(1) CNN 和 ViT 的网络设计完全不同,导致中间特征的语义层次不同,使得基于空间的知识传递方法效率低下。(2) 从 CNN 中提取知识限制了后期训练过程中网络的收敛,因为 ViT 整合全局信息的能力受到 CNN 局部归纳偏差监督的抑制。为此,我们提出了渐变空间知识蒸馏(CSKD)。CSKD 将 CNN 的空间知识蒸馏到 ViT 的对应token,无需引入中间特征。CSKD 利用渐变知识融合(CKF)模块,引入了 CNN 的全局响应,并在训练过程中逐渐强调其重要性。CKF 在早期训练阶段利用 CNN 的局部归纳偏差,并在后期充分发挥 ViT 的全局能力。whaosoft aiot http://143ai.com 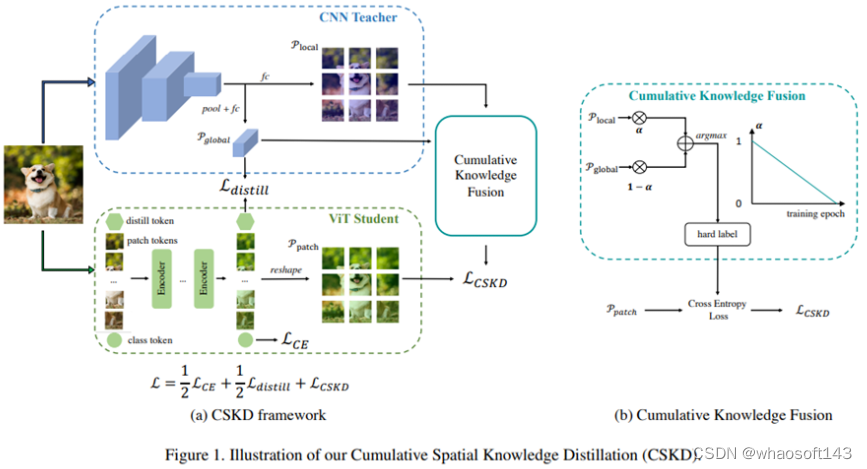
关键词:知识蒸馏、异构网络、归纳偏置论文链接:https://arxiv.org/abs/2307.08500
09
Supervised Homography Learning with Realistic Dataset Generation
基于真实数据集生成的有监督单应性矩阵学习
本文提出了一个迭代框架,包括生成阶段和训练阶段,以生成真实的训练数据用于有监督单应性学习。在生成阶段,给定一组 unlabeled 的图像对,利用预先估计的主平面 mask 和图像对之间的单应性矩阵生成具有真实运动的有 GT 图像对。在训练阶段,生成的数据通过所提出的两个模块 CCM 和 QAM 进行完善并用于训练网络。训练好的网络将用于更新下一阶段预先估计的单应性矩阵;通过这种迭代策略,数据质量和网络性能可以逐步的同时提高。 关键词:单应性矩阵估计、有监督学习、数据生成论文链接:https://arxiv.org/abs/2307.15353
关键词:单应性矩阵估计、有监督学习、数据生成论文链接:https://arxiv.org/abs/2307.15353
10
MEFLUT: Unsupervised 1D Lookup Tables for Multi-exposure Image Fusion
MEFLUT: 基于无监督1D查找表的多曝光融合
本文介绍了一种用于多曝光图像融合(MEF)的新方法。我们发现曝光图像的融合权重可以编码为一个 1D lookup table (1D LUT),该表以像素强度值作为输入,并输出相应的融合权重。我们为每个曝光图像学习一个独立的1D LUT,然后不同曝光下的所有像素都可以独立地查询对应的1D LUT,以实现高质量、高效率的融合。为了学习这些1D LUT,我们将注意力机制引入到构建的MEF网络的多个维度中,以显著提升融合质量。其次,与之前很少考虑实际部署的方法不同,我们通过已经训练好的网络来构建1D LUT,在实际部署中只需要部署1D LUT而不需要部署整个网络,通过该方法可以不受任何平台约束,能够高质量、高效率的进行部署。此外,我们收集了一个新的包含960个样本的MEF数据集。我们在收集的数据集以及公开的数据集上进行了大量实验,验证了我们的方法的有效性。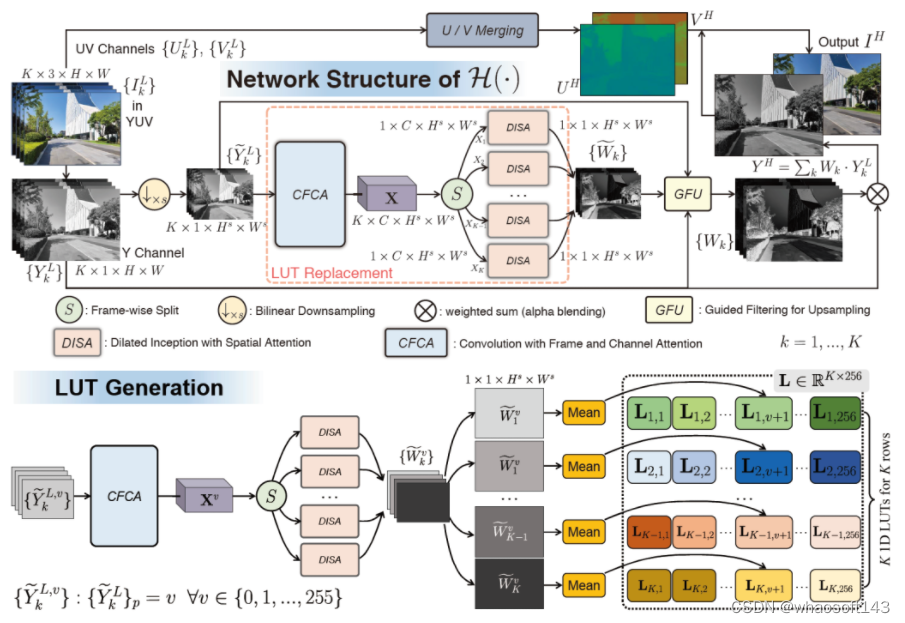 关键词:多曝光图像、高动态范围、无监督、快速、高效
关键词:多曝光图像、高动态范围、无监督、快速、高效
11
Learning Optical Flow from Event Camera with Rendered Dataset
基于渲染数据的事件相机光流学习
本文基于计算机图形渲染技术提出了一个具有准确的事件数据和光流标签的高质量数据集,被称为 MDR。另外,本文提出了一个即插即用的自适应调节模块 ADM,用于将输入的事件数据调整到最佳的稠密度区间,配合光流估计网络得到更准确的估计结果。实验表明,我们的 MDR 数据集可以促进基于事件相机的光流估计的学习,以前的光流估计网络在我们的数据集上进行训练时,可以不断地提高它们的性能。此外,主流的光流估计管道配备我们的 ADM 模块可以进一步提高性能。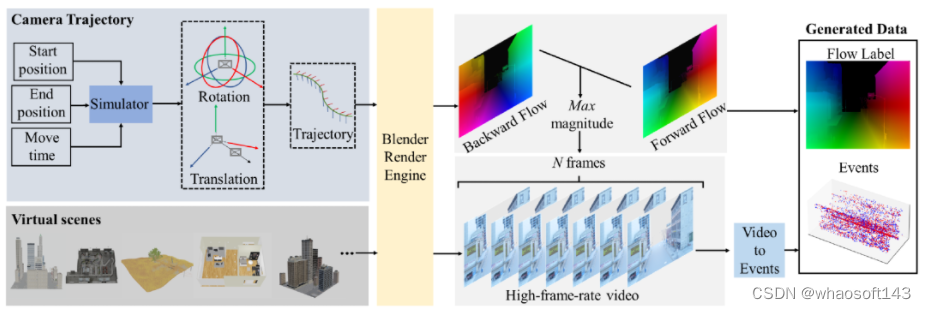
关键词:事件相机、光流、合成数据集论文链接:https://arxiv.org/abs/2303.11011
12
GAFlow: Incorporating Gaussian Attention into Optical Flow
GAFlow:融入高斯注意力机制的光流估计
本文提出一种新的光流估计方法,将高斯注意力引入光流模型(GAFlow),以在表征学习过程中强调局部特性,并在匹配过程中强化运动关联性。具体来说,本文提出高斯约束层(GCL)和高斯引导注意力模块(GGAM),这些基于高斯的模块可以自然地融入到现有光流框架中。高斯约束层可插入现有的 Transformer 模块,以强化包含细粒度结构信息的局部邻域的特征学习;高斯引导注意力模块不仅继承了高斯分布的邻域特性,还能在匹配过程中将重点放在场景相关的可动态学习区域。实验证明 GAFlow 在泛化性测试和在线基准上都实现了较好的性能。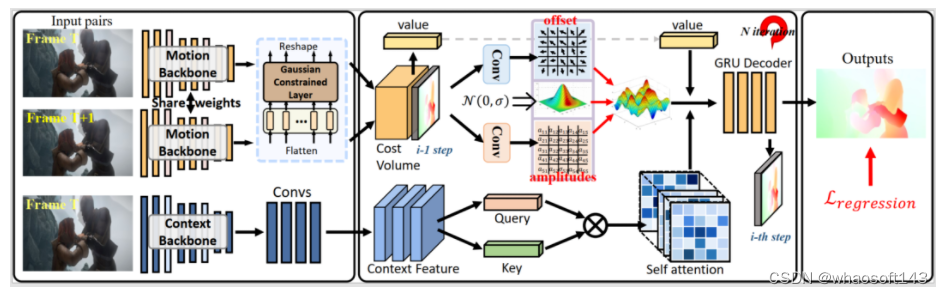
关键词:光流、高斯注意力
13
Explicit Motion Disentangling for Efficient Optical Flow Estimation
基于显式运动解耦的高效光流估计
本文提出了一种新的光流估计框架 EMD-Flow,将全局运动学习与局部光流估计分离开,这样就能用更少的运算资源处理全局匹配和局部细化。网络包含两个新模块:多尺度运动聚合(MMA)和置信度引导光流传播(CFP),这两个模块充分利用跨尺度匹配信息和自包含的置信度图,以全局方式处理密集匹配的不确定性,生成较密集的初始光流。最后,配合一个轻量级解码模块处理小位移,实现一个高效且稳定的光流估计框架。实验证明 EMD-Flow 在标准光流数据集上取得了性能和运行时间之间更好的平衡。
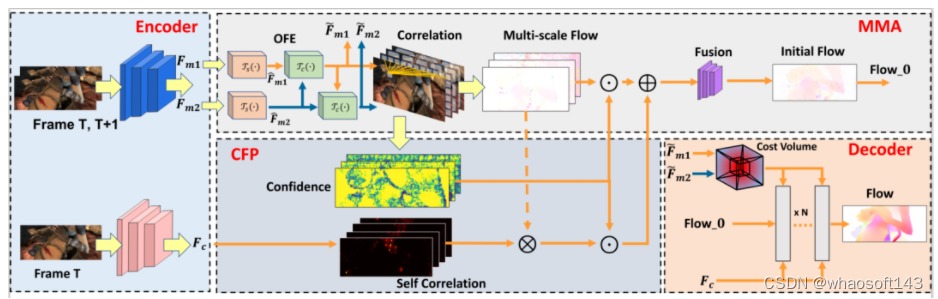 关键词:光流、运动解耦、高效模型
关键词:光流、运动解耦、高效模型
14
SIRA-PCR: Sim-to-Real Adaptation for 3D Point Cloud Registration
SIRA-PCR: 基于合成到真实域适应的 3D 点云配准
我们基于仿真室内场景数据集 3D-FRONT 构建了第一个用于 3D 点云配准的大规模室内场景合成数据集,名为 FlyingShapes。同时,我们还提出了一种生成式的从合成数据到真实数据的域适应 pipeline,名为 SIRA。其中,一种自适应的重采样模块被用于消除合成与真实点云数据之间的低层次分布差异。通过这种方法,我们训练得到的模型在室内场景数据集 3DMatch 和室外场景数据集 ETH 上取得了 SOTA 的配准结果,分别达到了 94.1% 和 99.0% 的配准召回率。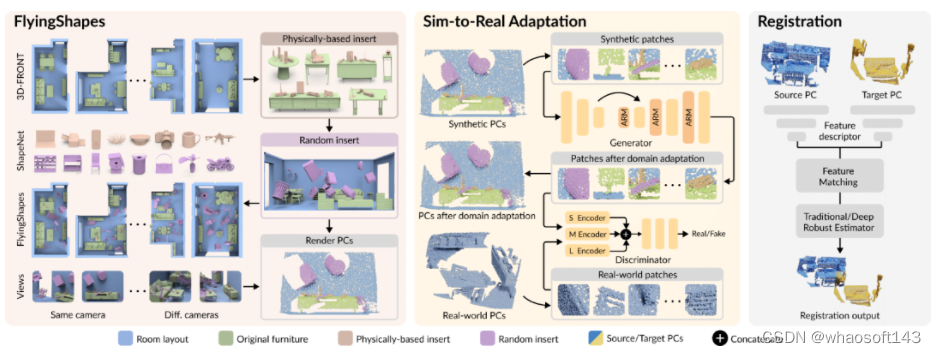 关键词:点云配准、域适应、合成数据集
关键词:点云配准、域适应、合成数据集


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









