







 本文介绍了近期人脸技术领域的三项研究,包括Diff-Privacy的面部隐私保护方法、利用正常化流的语义分解人脸编辑技术以及3D融合的多面具真实面部再现。同时,还探讨了半监督学习在人脸活体检测中的应用。
本文介绍了近期人脸技术领域的三项研究,包括Diff-Privacy的面部隐私保护方法、利用正常化流的语义分解人脸编辑技术以及3D融合的多面具真实面部再现。同时,还探讨了半监督学习在人脸活体检测中的应用。
这是几份近期的人脸技术的工作,人脸图像处理识别技术作为CV领域的一大分支,仍然有很多内容值得探索。
Diff-Privacy: Diffusion-based Face Privacy Protection
论文作者:Xiao He,Mingrui Zhu,Dongxin Chen,Nannan Wang,Xinbo Gao
作者单位:Xidian University; Chongqing University of Posts and Telecommunications
论文链接:http://arxiv.org/abs/2309.05330v1
内容简介:
1)方向:人脸隐私保护
2)应用:网络图片、手机隐私保护
3)背景:随着人工智能技术的普及,个人数据的广泛收集和滥用,隐私保护已成为当务之急。匿名化和视觉身份信息隐藏是两个重要的面部隐私保护任务,它们的目标是在人类感知水平上从面部图像中移除识别特征。
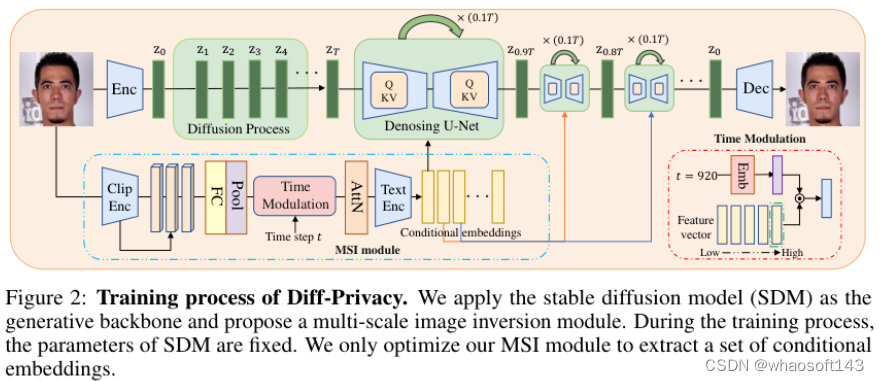
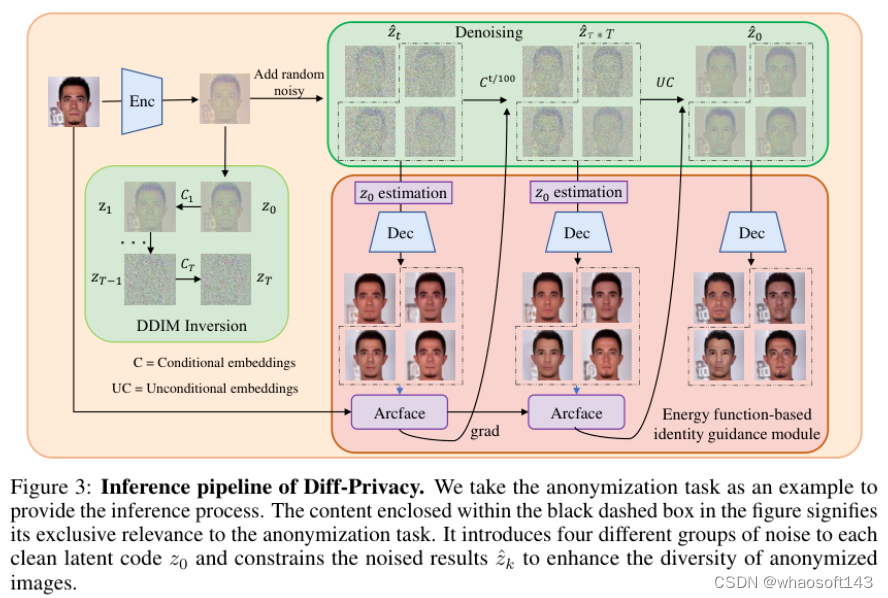
4)方法:本文提出了一种基于扩散模型的面部隐私保护方法,将匿名化和视觉身份信息隐藏统一为一个任务。通过训练多尺度图像反演模块(MSI)获取原始图像的一组SDM格式条件嵌入。基于这些条件嵌入,设计相应的嵌入调度策略,并在去噪过程中构建不同的能量函数,实现匿名化和视觉身份信息隐藏。
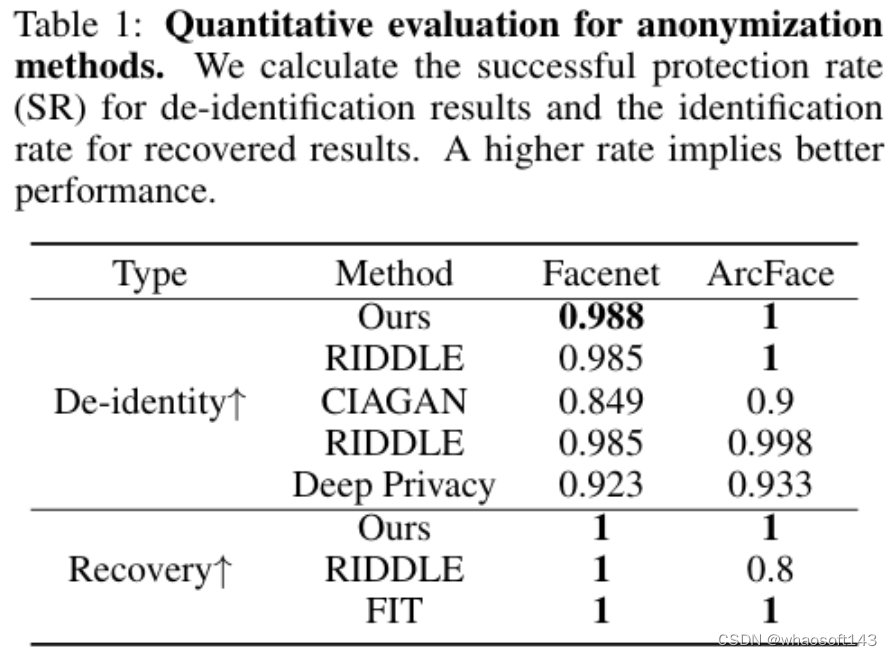
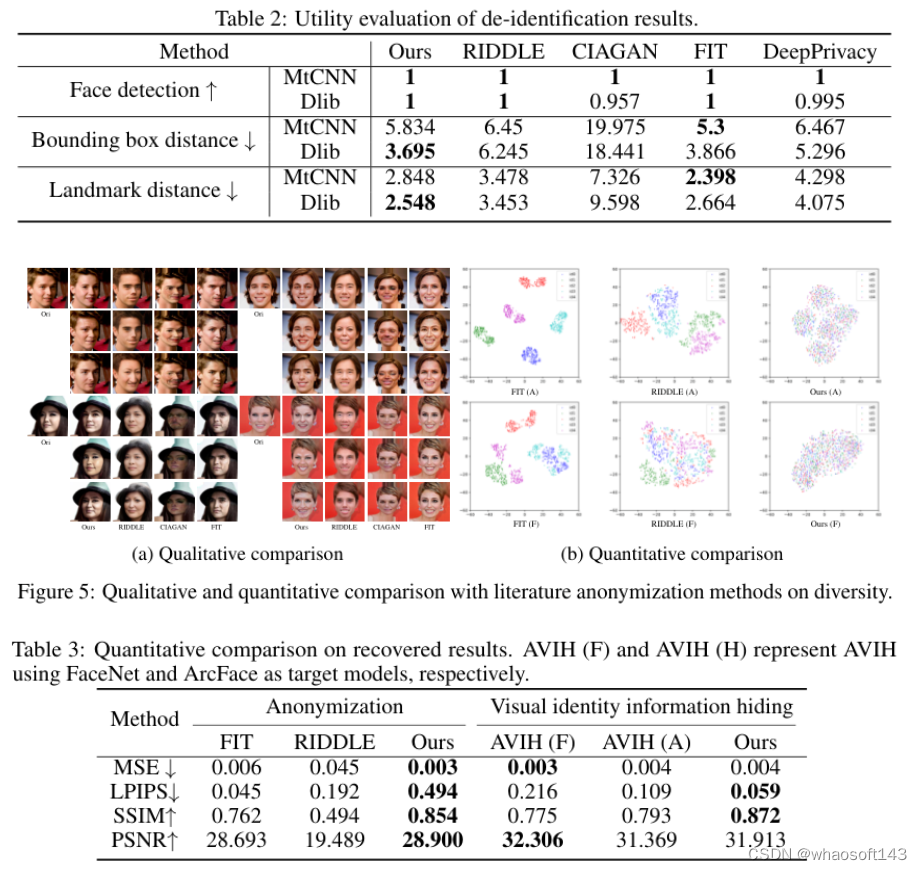
5)结果:大量实验证明了所提框架在保护面部隐私方面的有效性。

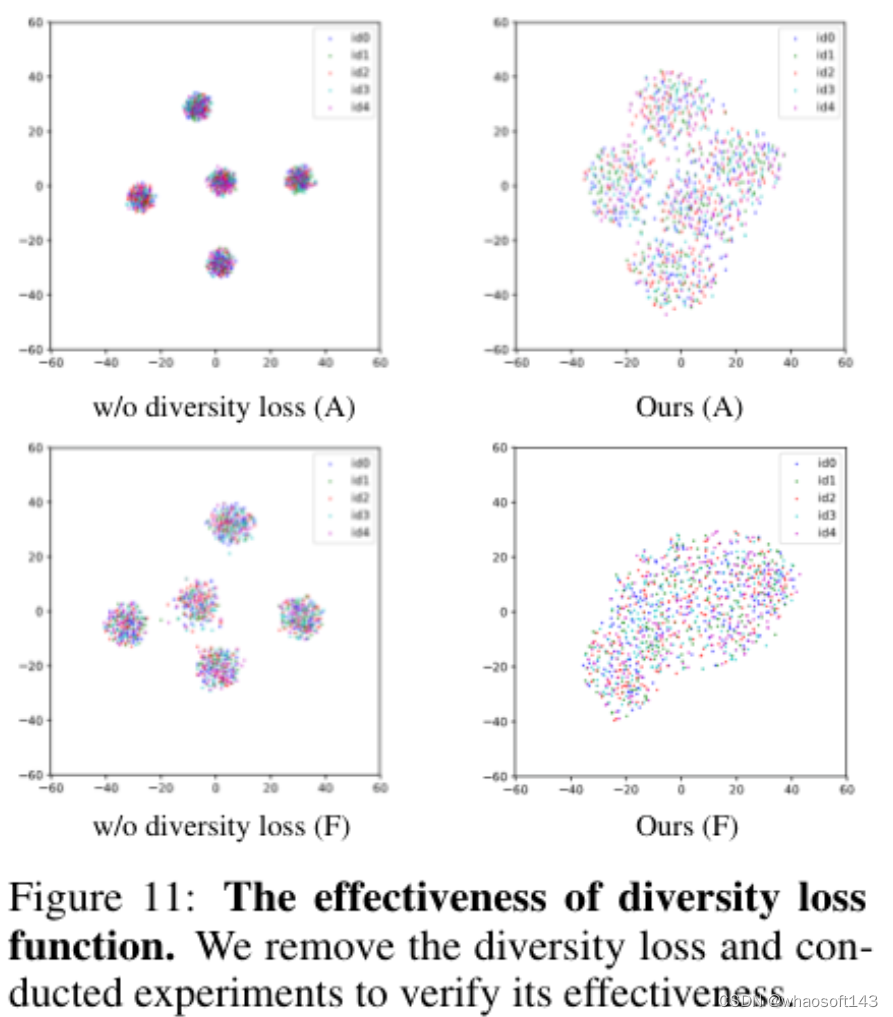
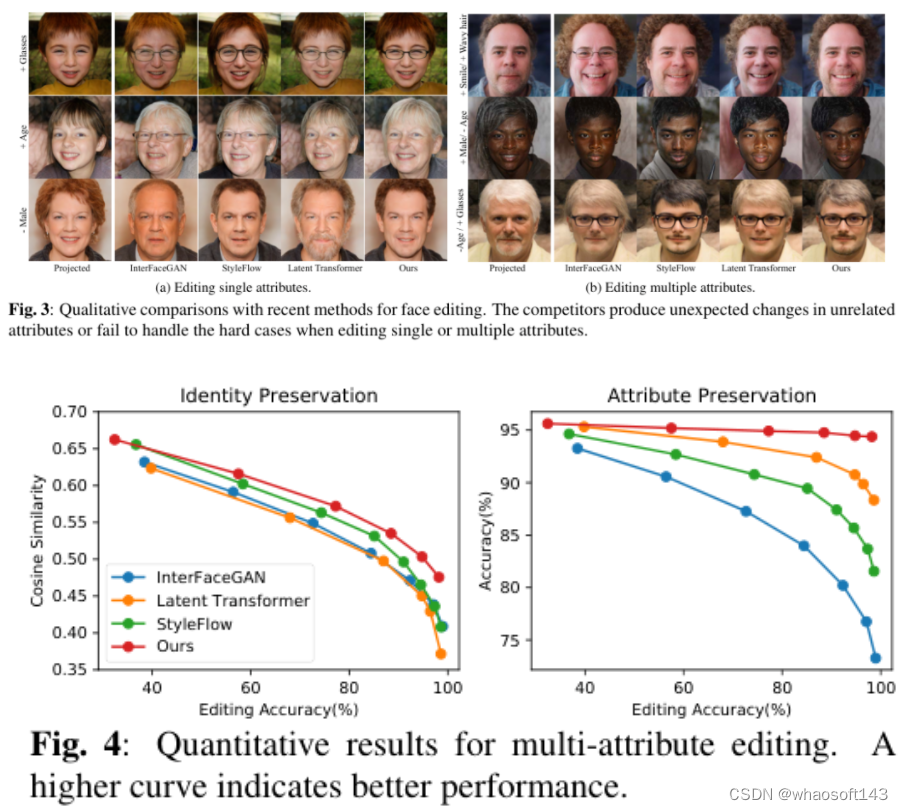
Semantic Latent Decomposition with Normalizing Flows for Face Editing
论文作者:Binglei Li,Zhizhong Huang,Hongming Shan,Junping Zhang
作者单位:Fudan University
论文链接:http://arxiv.org/abs/2309.05314v1
项目链接:https://github.com/phil329/SDFlow
内容简介:
1)方向:人脸编辑技术
2)应用:人脸编辑
3)背景:在StyleGAN的隐空间中导航已经显示出对于人脸编辑的有效性。然而,由于隐空间中不同属性之间的纠缠,导致现有方法在复杂导航中遇到挑战。
4)方法:本文提出了一种新的框架SDFlow,通过使用连续条件归一化流在原始隐空间中进行语义分解。具体而言,SDFlow通过联合优化两个组件来将原始隐代码分解为不同的无关变量:(i)一个语义编码器,用于从输入人脸估计语义变量;(ii)一个基于流的转换模块,将隐代码映射到高斯分布中的语义无关变量,条件是学习到的语义变量。为了消除变量之间的纠缠,采用了一个在互信息框架下的解缠学习策略,从而提供精确的操作控制。
5)结果:实验结果表明,SDFlow在定性和定量上都优于现有的最先进的人脸编辑方法。源代码可在https://github.com/phil329/SDFlow上获得。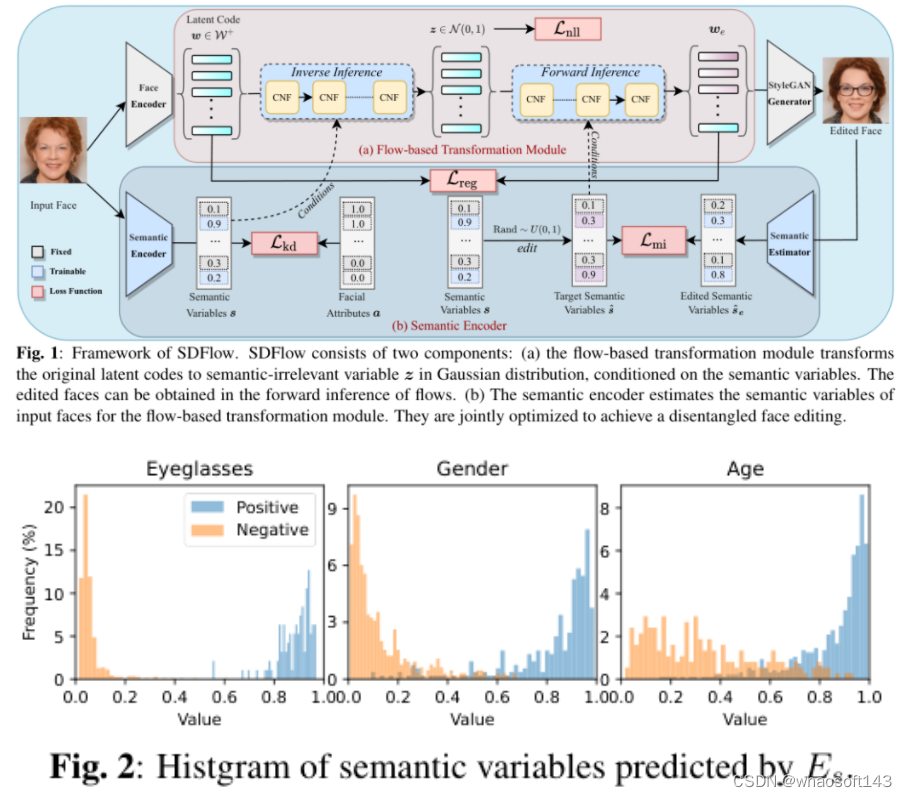
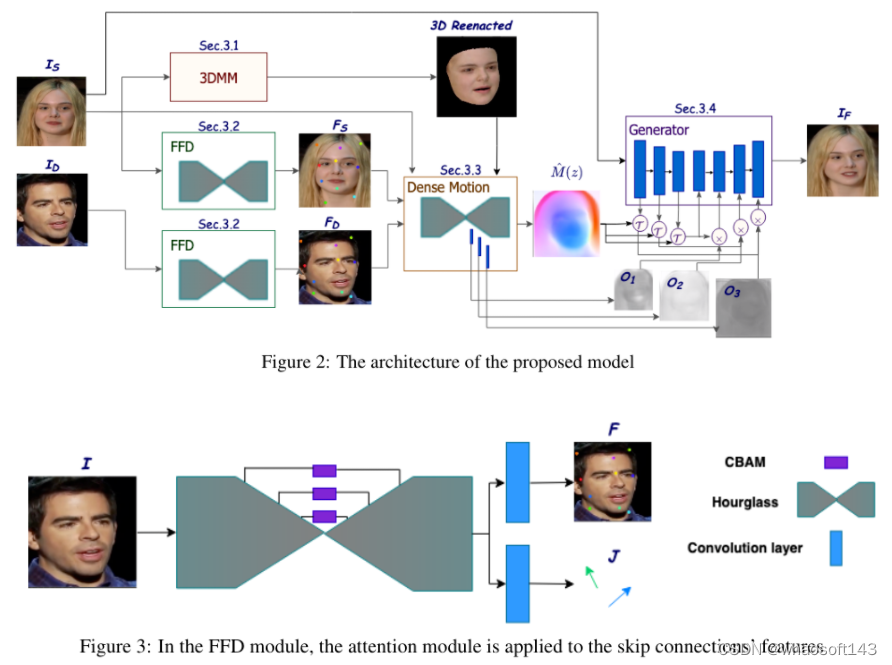
MaskRenderer: 3D-Infused Multi-Mask Realistic Face Reenactment
论文作者:Tina Behrouzi,Atefeh Shahroudnejad,Payam Mousavi
作者单位:University of Toronto; Amii (Alberta Machine Intelligence Institute)
论文链接:http://arxiv.org/abs/2309.05095v1
内容简介:
1)方向:人脸再现技术
2)应用:生成逼真的面部图像
3)背景:尽管最近的人脸再现研究取得了一些有希望的结果,但仍然存在一些挑战,如身份泄露和模仿口部动作,特别是对于大幅度的姿势变化和被遮挡的面部。whaosoft aiot http://143ai.com
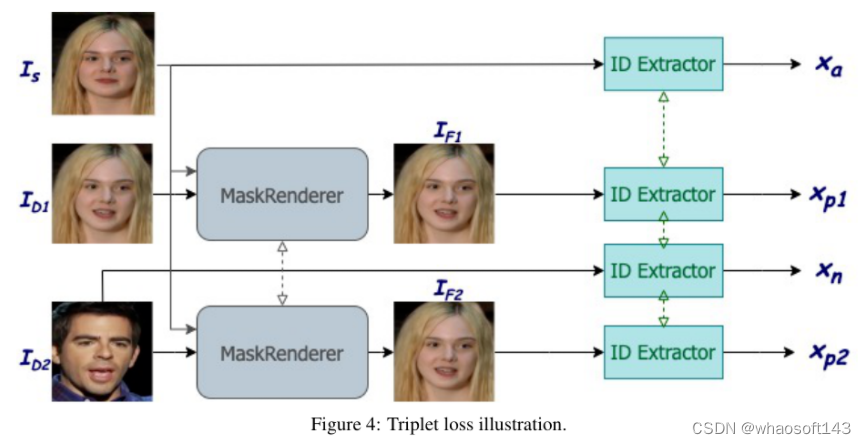
4)方法:MaskRenderer通过以下方法解决了这些问题:(i) 使用3DMM对3D面部结构建模,相对于2D表示更好地处理了姿态变化、遮挡和口部运动;(ii) 在训练过程中使用三元损失函数进行交叉再现以更好地保留身份信息;(iii) 多尺度遮挡,改善修复和恢复缺失区域。
5)结果:在VoxCeleb1测试集上进行的综合定量和定性实验证明,与最先进的模型相比,MaskRenderer在未见过的面孔上表现更好,特别是在源身份和驱动身份非常不同的情况下。
Semi-Supervised learning for Face Anti-Spoofing using Apex frame
论文作者:Usman Muhammad,Mourad Oussalah,Jorma Laaksonen
作者单位:University of Oulu;Aalto University
论文链接:http://arxiv.org/abs/2309.04958v1
内容简介:
1)方向:人脸活体检测
2)应用:金融、授权活体验证
3)背景:传统的人脸活体检测领域特征提取技术要么分析整个视频序列,要么专注于特定片段以提升模型性能。然而,确定哪些帧为人脸活体检测提供了最有价值的输入仍然是一个具有挑战性的任务。
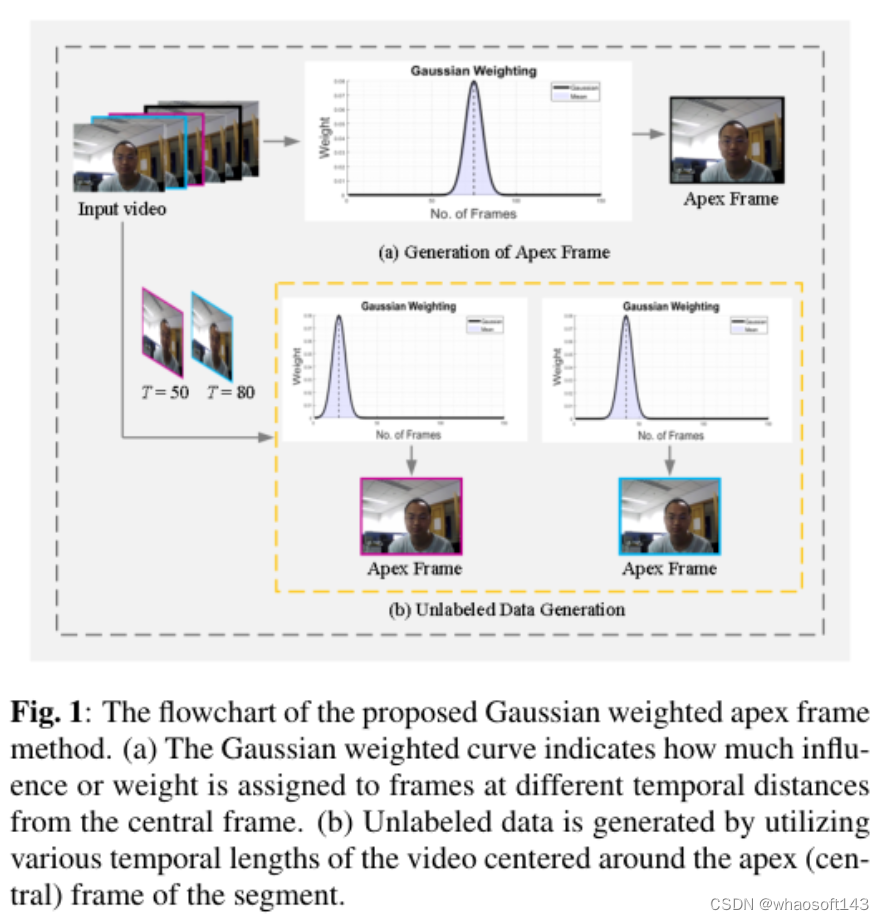
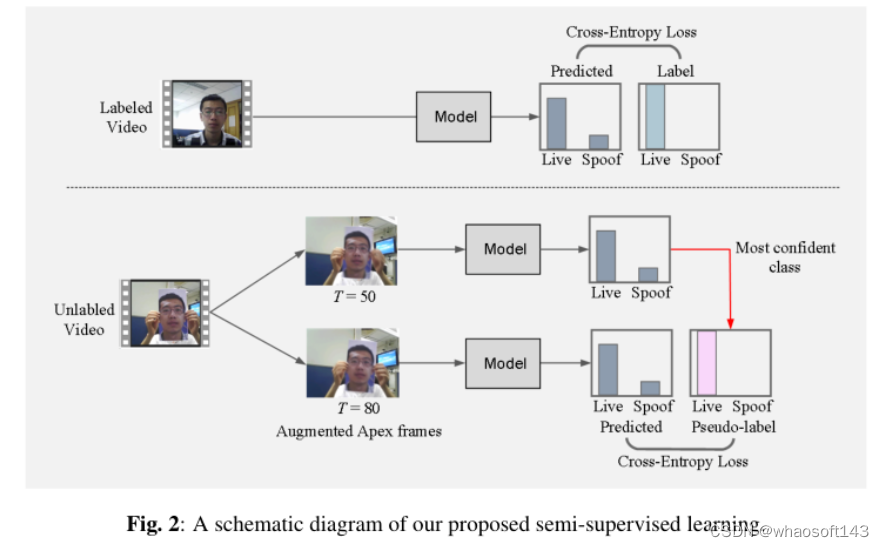
4)方法:本文通过采用高斯加权方法来创建视频的顶点帧来解决这个挑战。具体来说,通过计算视频的帧的加权和来得出一个顶点帧,其中权重是使用以视频中心帧为中心的高斯分布确定的。此外,通过探索各种时间长度,使用高斯函数产生多个未标记的顶点帧,无需进行卷积。通过这样做,作者充分利用了半监督学习的好处,它考虑了标记和未标记的顶点帧,从而有效地区分了真实和伪造的类别。
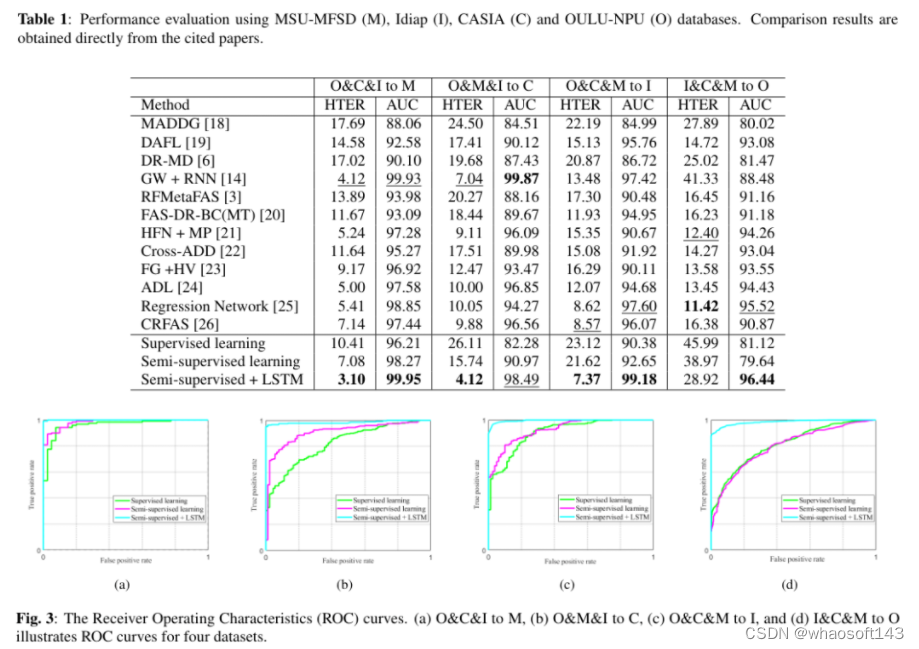
5)结果:实验证明,使用四个人脸活体检测数据库:CASIA、REPLAY-ATTACK、OULU-NPU 和 MSU-MFSD,顶点帧在推动人脸活体检测技术方面具有显著的有效性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









