







此文章转载于大佬~
Vary充分探索了视觉词表对感知能力的影响,提供了一套有效的视觉词表扩充方法。扩充Vision Vocabulary,提升LVLM的dense和细粒度视觉感知能力
很高兴向大家介绍我们最近在探索增强多模态大模型细粒度视觉感知方面的新工作:Vary(https://varybase.github.io/)。
Vary充分探索了视觉词表对感知能力的影响,提供了一套有效的视觉词表扩充方法。通过在公开数据集以及我们渲染的文档图表数据上训练,在保持vanilla多模态能力的同时,还激发出了端到端的中英文图片、公式截图和图表理解能力,是一套视觉感知上限极高的通用多模态框架。
Vary是我们在这个方向上的初步探索,目前Vary的基础版 demo(http://region-31.seetacloud.com:22701/) 已经上线,代码和模型(https://github.com/Ucas-HaoranWei/Vary) 均已开源,欢迎试玩和反馈,我们将继续增强Vary作为基座的各项能力,感谢大家的持续关注!
如果我们的工作对你有所启发,也希望能在Github(https://github.com/Ucas-HaoranWei/Vary)为我们点上一个 Star!
Project page:
https://varybase.github.io/
Demo:http://region-31.seetacloud.com:22701/:
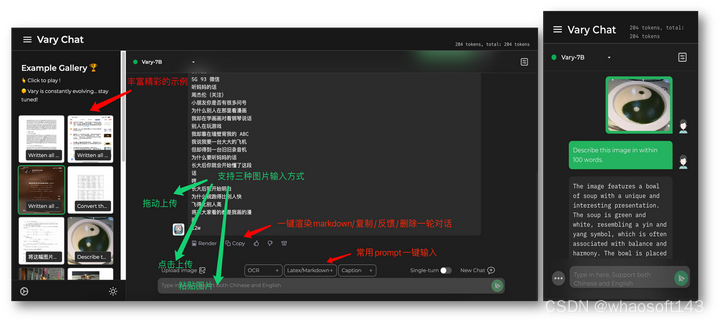
Demo的网页版和手机版(夜间主题)
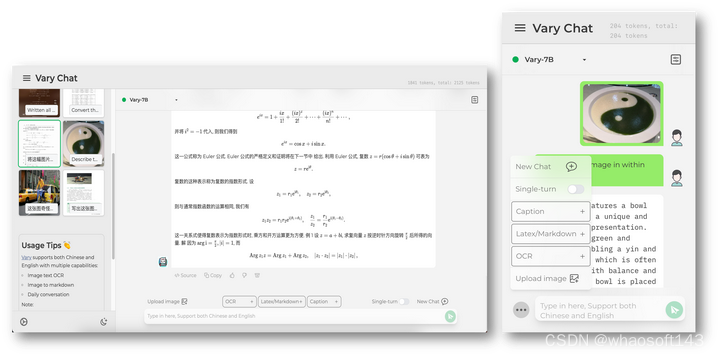
Demo的网页版和手机版(亮色主题)
我们研究的动机主要是目前的多模态大模型几乎都是用CLIP作为Vision Encoder或者说视觉词表。确实,在400M图像文本对训练的CLIP有很强的视觉文本对齐能力,可以cover多数日常任务下的图像编码。但是对于dense和细粒度感知任务,比如文档级别的OCR、Chart理解,特别是在非英文场景,CLIP表现出了明显的编码低效和out-of-vocabulary问题。受语言的LLMs启发,迁移英文LLM到其他语言时要扩充词表以提高编码效率和提高性能,我们也需要对视觉词表进行扩充。
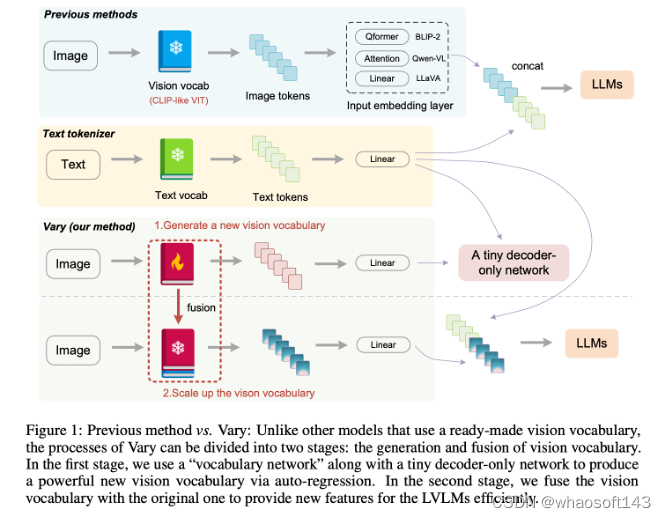
不同于现有方法直接用现成的CLIP词表,Vary分两个阶段:第一阶段先用一个很小的decoder-only网络用自回归方式帮助产生一个强大的新视觉词表;然后在第二阶段融合新词表和CLIP词表,从而高效的训练LVLM拥有新feature。Vary的训练方法和模型结构如下图:
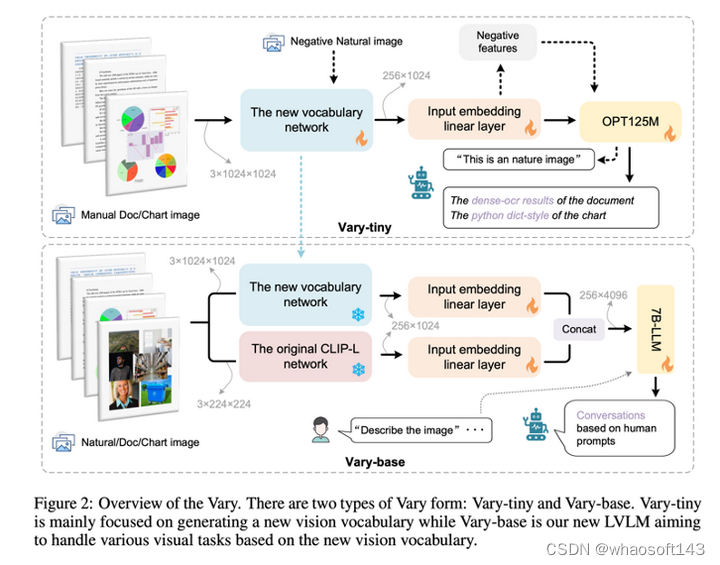
更多的模型结构和实验数据细节欢迎阅读论文了解~ whaosoft aiot http://143ai.com
下面是一些Vary的例子,欢迎来demo体验和创造更多有趣的例子
各种中英文图片OCR:
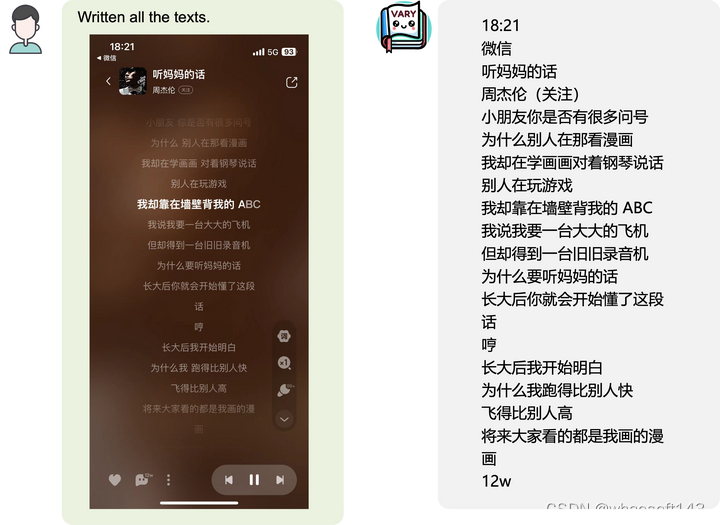
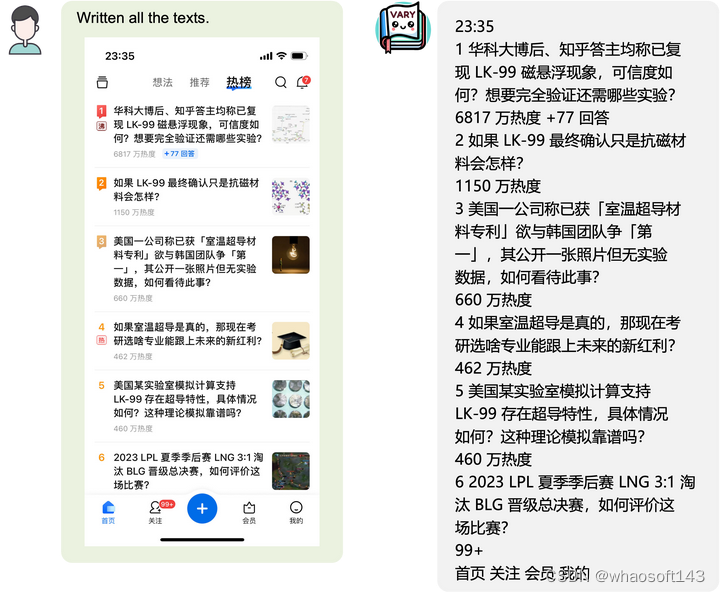


图片转成markdown格式:


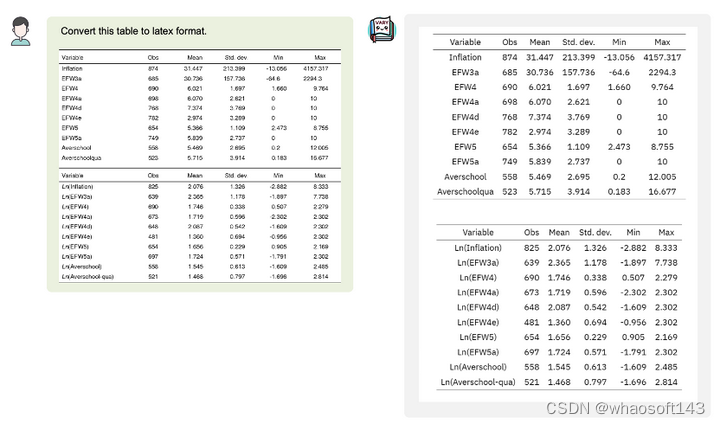
表格转换:
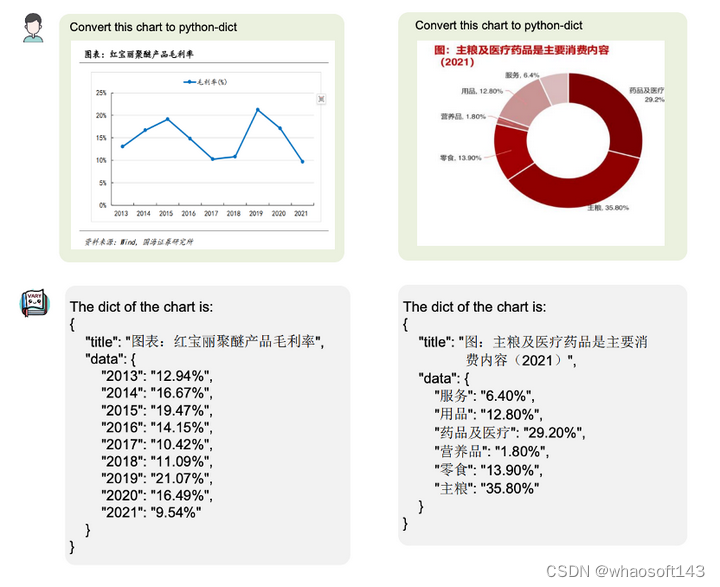
图表理解:
通用理解和对话:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









