







此文转载与大佬~~~~
自动驾驶感知作为自动驾驶任务中的第一步,同时也是最重要的一个环节,只有感知的得足够精准,后续的一些诸如目标检测、语义分割或目标跟踪等任务才会有好的结果。如今,在汽车上的传感器主要包含了camera、lidar和radar,近年来camera、lidar以及camera和lidar融合的感知任务研究发展得十分迅速,相关的研究进展层出不穷。但受限于lidar高昂的价格,radar作为一种相对廉价的替代方案在工业界也许更受青睐。但由于学术界对radar作为自动驾驶中主要传感器的研究起步较晚,早期重视程度不够,再加上radar本身的固有缺陷,导致以radar为主的自动驾驶感知任务研究进展远不如lidar,相关研究与lidar相比较少。本文对近些年来,radar在自动驾驶感知任务中的研究进展和成果作了初步的调研,若有不详细之处,还请谅解。
一、radar基本介绍以及自动驾驶感知任务中的优势
雷达全称是radio detection and range,它通过发射无线电波和接收目标的反射波来计算目标的距离和速度。毫米波(MMW)雷达是雷达的一个重要分支,它工作在波长为1-10mm、频率为30-300GHz的毫米波段。目前,应用于自动驾驶中的汽车雷达通常有两种频率,分别为24GHz和77GHz。
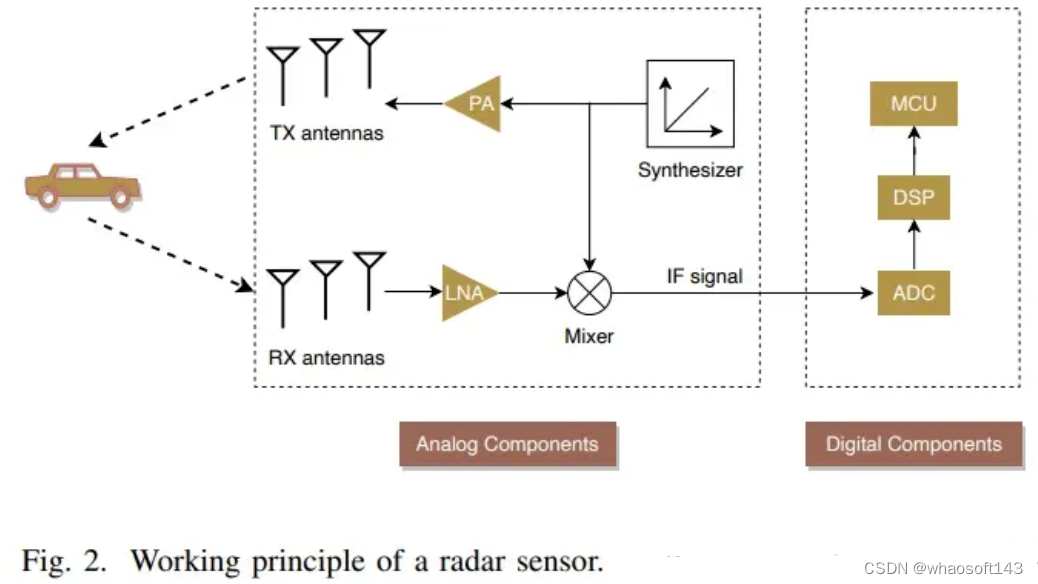
雷达的基本工作原理如图所示,合成器(Synthesizer)产生一个调频连续波,称为"稠啾信号"(chirp),通过TX天线在空间中传播到物体表面,而后反射回雷达,通过RX天线接收反射信号,与发射信号mixed产生中频信号,进入ADC模块转化成数字信号。通常,雷达系统包含多个TX和RX天线,从而产生多个IF信号。关于目标物体的信息,如距离、多普勒速度和方位角,包含在这些IF信号中,DSP可以使用嵌入的不同信号处理算法将其分离。基于从DSP提取的目标信息和自动态信息,MCU充当计算机来评估系统需求并做出明智的决策。
基于飞行时间(TOF)原理,雷达传感器通过发射信号和反射信号之间的时间差来计算距离物体的距离。基于多普勒原理,当发射的电磁波和检测到的目标之间存在相对运动时,返回波的频率与发射波的频率不同。因此,可以使用该频率差来测量目标相对于雷达的相对速度,利用阵列信号处理方法,通过从平行RX天线反射的chirp之间的相位差来计算方位角。由于传统3D雷达传感器的RX天线仅在2D方向上排列,因此仅在2D水平坐标中检测目标,而没有垂直高度信息。最近,随着雷达技术的进步,4D雷达传感器已经被开发出来,天线水平和垂直排列,能够测量高程信息。
除了能够测量距离、多普勒速度和方位角外,毫米波段的电磁波具有较低的大气衰减和对雨水、烟雾和灰尘的更好穿透能力。这些特性使雷达传感器能够在恶劣天气条件下全天工作。然而,雷达传感器仍然有局限性,它们表现出较低的角分辨率,并且无法区分位置较近的物体。此外,雷达生成的点云分布稀疏,行人上只有几个点,汽车上只有十几个点。这些点不能充分勾勒出物体的轮廓,这使得提取几何信息具有挑战性。此外,雷达对静止障碍物的感知能力较弱,运动目标可以在一维范围和速度上与周围场景区分开来。然而,雷达对金属高度敏感,经常会导致地面井盖等静止物体的强烈反射。因此,在实践中,静止物体通常会被过滤,导致无法检测到静止的障碍物。
雷达在自动驾驶感知任务中的优势可总结为以下几点:
-
成本相对较低,一个毫米波雷达的价格通常不到激光雷达的十分之一。
-
环境适应性强,毫米波的穿透性使其能工作于较为雨雪雾等恶劣气候环境中。
-
探测距离远,长距毫米波雷达能探测到200米以外的目标,而lidar由于分辨率与探测距离呈负相关的属性,通常探测距离只有几十米。
-
可以提供额外的速度测量。
二、lidar-based方法
lidar数据通常为点云表示,由于该数据类型的稀疏性和无序性,需要设计独特的特征提取网络模型。用于lidar点云的目标检测方法通常可分为以下几种:
-
Point-based 3D Object Detector:直接利用原始点云数据,通过采样等方式提取特征,其中有两个重要组成模块,点云采样和特征学习。该方法的瓶颈在于推理时间过慢,点云采样过程通常采用的方法是最远点采样法(farthest point sampling),该过程耗时较长,当点云数据量过大时,计算资源和内存的消耗十分巨大。代表性的方法有PointRCNN等。
-
Grid-based 3D Object Detector:先对lidar点云进行网格化(rasterize),pillar、voxel、BEV 特征图等形式都属于此类方法,然后用2D卷积神经网络或3D稀疏卷积神经网络进行特征提取,最后将网格化后的特征图投影到BEV空间,进行3D目标检测。该类方法通过聚合一个固定范围内的点云信息,丢失了诸如高度在内的重要信息,带来了计算效率上的巨大提升。代表性方法有VoxelNet、PointPillar等。
-
Point-Voxel based 3D Object Detector:吸取了Point-based 和Grid-based方法思想,使用基于点和体素融合的方法,保证精度的同时,缩减了大量的计算量。Point-Voxel方法分为one-stage 和two-satage,one-stage方法直接融合体素和点特征,two-stage方法先由体素特征生成proposal,采样Keypoints,再由点特征进一步筛选检测结果。该方法仍然受限于计算量与推理时间的问题,融合过程需要消耗不可忽视的时间损失。代表性方法有PVCNN、Fast Point R-CNN。
-
Range-based 3D Object Detector:Range图像是一种密集而紧凑的2D表示,其中每个像素包含的是深度信息,而不是RGB值。Range-based方法的主要创新点在于针对Range图设计模型和算子,并要选择合适的视图。Range图由于和Image图像十分相似,可以采用2D目标检测的一些方法进行处理。然而,与鸟瞰图相比,RV视角存在易被遮挡和尺度变换的影响。由此,BEV视角下的3D目标检测已经成为主流。代表性方法有LaserNet等。
三、camera-based方法
1 Monocular 3D object detection
单目摄像头只能获取单个图像信息,缺乏深度信息,所以单目图像的3D目标检测是一个ill-posed问题。精确的预测物体的位置信息一直是单目3D检测的最大阻碍,对此,许多研究尝试解决这一问题作了多方面努力,比如由图像推测深度或是采用几何约束和形状先验。不过,这一问题并没有得道很好的解决,单目3D目标检测的精度与lidar相比还差很远。单目3D目标检测的方法可细分为以下几种:Image-Only、Prior-Guided、Depth-Assisted。
2 Stereo-Based 3D object detection
基于双目的3D目标检测是指从一对图像中检测出3D物体。与单目图像相比,双目提供了额外的几何约束,可用于推断更准确的深度信息。基于双目方法通常比基于单目的方法获得更好的检测性能。当然,基于双目的方法与基于激光雷达的方法在性能上仍有很大的差距。双目方法与单目检测方法相比,可以通过立体匹配技术获得更精确的深度和视差估计,从而带来更强的目标定位能力,显著提高了3D目标检测能力。
3 Multi-View 3D object detection
自动驾驶汽车通常会配备多个摄像头,从多个视角获取完整的周边环境信息。如今的研究热点集中于将多视角图像投影到BEV空间,通过BEV特征图进行目标检测任务。由于缺乏深度信息,如何精准地进行多视角图像到BEV的视角转换征是主流研究方向之一,如LSS、BevDet等;另一些研究方向则是将Transformer应用于视角转换模块,通过多视角交叉注意力构建BEV空间,如BevFormer等。
四、Lidar-Camera融合方法
lidar和camera拥有各自的优势和特点,融合这两种传感器目前也是自动驾驶感知任务中最重要的融合解决方案。由于在此前的研究中lidar-based方法表现出了远超camera-based方法,所以一些研究倾向于采用lidar-based方法作为pipeline并在其中尝试加入图像信息。
1 Early-Fusion Based 3D object detection
基于前融合的方法的目的在Lidar数据进入pipeline之前,将图像信息加入进来与Lidar数据进行融合。一般首先通过2D检测或分割网络提取图像知识,将知识传递给lidar点云,在把增强后的lidar点云送入pipeline。可分为point-level和region-level。
-
region-level:通过2D检测网络生成一些2D检测框,将2D检测框逆向映射到图像的视锥空间,后续lidar-based方法可在筛选后的视锥空间中进行检测,缩小了检测范围。
-
point-level:通过语义分割网络得到pixel-wise的语义标签,将这些带有语义标签的像素通过point-to-pixel投影与点关联,在将这些关联后的点云信息送给lidar-based pipeline。
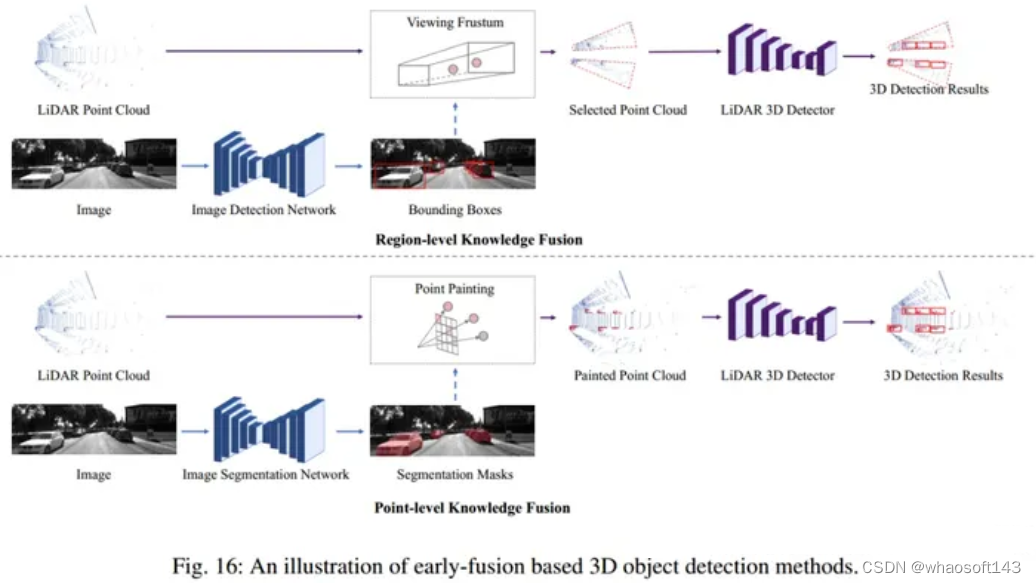
Early-Fusion Based 3D object detection的优势在于兼容性好,基本可以将现有的lidar-based模型直接搬过来使用,在数据预处理模块加上所要使用的图像知识提取方式,与lidar点云进行融合即可。显而易见的是,在进入lidar-based pipeline之前就进行了一次图像的2D目标检测或分割任务,所带来的问题就是推理时间的延迟,如何更加高效的使用前融合方法值得继续研究。
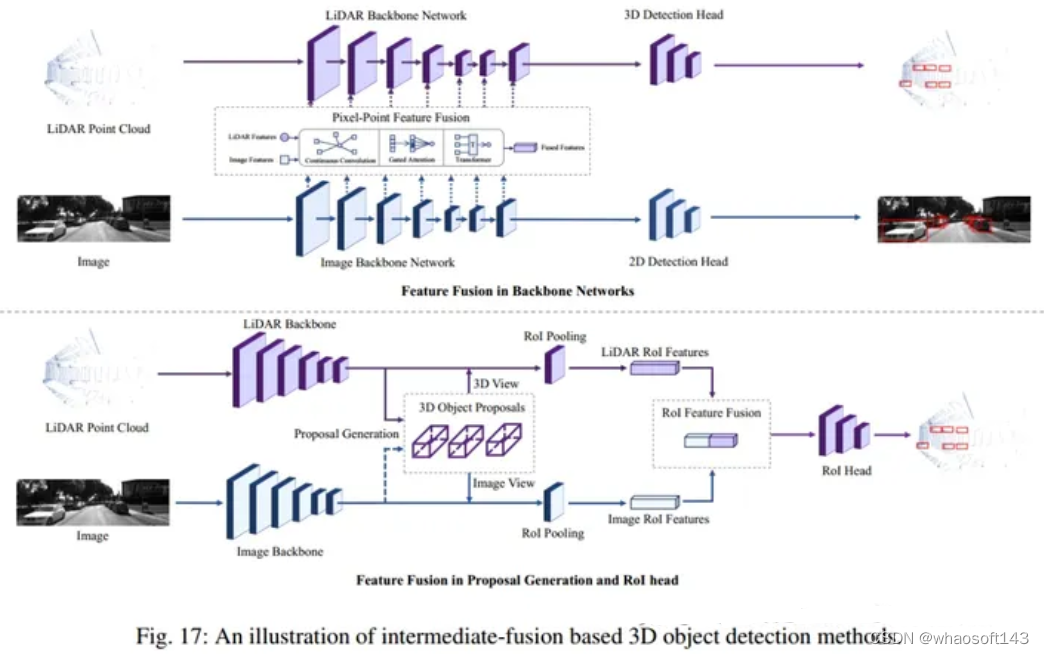
2 Intermediate-Fusion Based 3D object detection
基于中融合的3D目标检测旨在融合image特征到lidar-based pipeline中间阶段,比如backbone网络,proposal生成阶段或是RoI提炼阶段。
-
backbone阶段:一般用于grid-based方法的backbone中,在LiDAR backbone中,点云被网格化,这与图像特征图类似,这这一阶段进行融合具有先天的优势。
-
Proposal generation和RoI head阶段:先由LiDAR detector生成3D proposal,投影到多视角图像上,分别从图像和LiDAR backbone中裁剪特征,最后将裁剪后的特征融合到RoI head中预测3D检测的参数。
中融合方法建议对多模态表示进行更深入的融合,并产生更高质量的3D框。然而,相机和激光雷达的特征本质上是异构的,来自不同的视角,因此在融合机制和视角对齐方面还存在一些问题。因此,如何有效地融合异构数据,以及如何处理来自多个视角的特征聚合,仍然是研究领域面临的挑战。
3 Late-Fusion Based 3D object detection
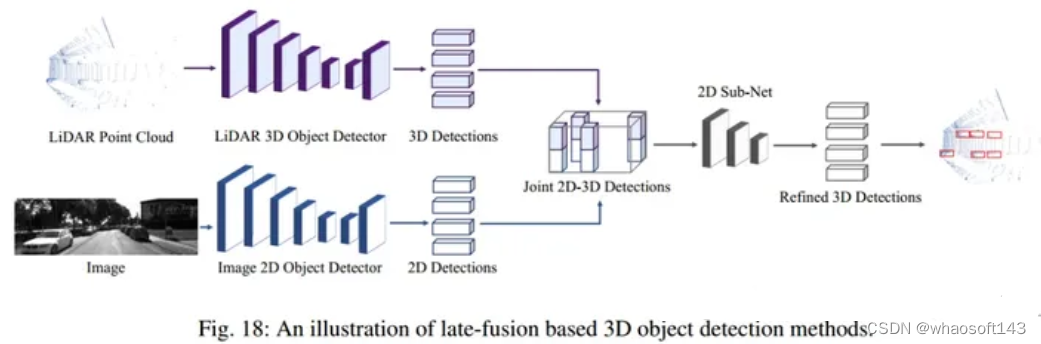
后融合就是将图像得到的2D结果和LiDAR得到的3D结果进行融合的方法。该方法采用相机与激光雷达并行进行目标检测,并将输出的2D和3D框进行融合,得到更精确的3D检测结果。
后融合方法聚焦于实例级聚合,对不同模态输出结果进行融合,避免了前融合和中融合的复杂交互,因此,该方法的效率远高于前融合和中融合的方法。然而,由于不依赖于相机和激光雷达传感器的深度特征,这些方法无法整合不同模式的丰富语义信息,限制了这类方法的潜力。
五、基于radar的3D目标检测
因为lidar和radar数据的相似性(都可以点云的的形式表示),相当多的radar-camera融合方案沿用了lidar-camera的融合方式,类似地,雷视融合大体上也可分为三类:前融合、后融合和深度(特征)融合。
前融合方法原理与lidar-camera前融合方法类似,在数据进行特征提取等一系列操作前进行融合,不同的是,相对于radar而言,基于camera的目标检测pipeline方案效果显著更好。通常先对通过过基于radar的目标检测算法生成proposals或RoI区域,再投影至图像上,并使用启发式的方法收集该区域的图像特征。同lidar-camera融合方法类似,这并不是一个可靠的方案,因为关键物体可能会事先在radar点云处理中被过滤掉,我们甚至不会尝试在图像中寻找被过滤调的目标。
后融合方法是最简单的一类方法,其核心思想是分别基于radar和camera作两遍目标检测,把两组检测的结果合并为一组,其优势在于可直接沿用现成的单一模态目标检测算法。这类方法并不能对各自模态特征进行互补,例如camera擅长检测出物体的边界,radar能探测物体的速度,但两者在进行各自的目标检测时并没有作任何信息交互。
深度(特征)融合是目前研究的主流,这是一类基于学习的方法,采用并行计算camera和radar特征的同时,相互进行软关联。进一步具体可分为三种方法:
-
基于雷达图生成:为了将雷达信息带入图像域,提取雷达特征并将其转换为类似图像的矩阵信息。这称为雷达图像。该雷达图像的通道表示来自雷达点表示的信息,即距离、速度等物理量。类似与lidar-camera中融合中的backbone阶段的融合方式。这种方法并不是很成功,因为雷达点云固有的稀疏性使得它们无法形成良好的类图像矩阵。
-
基于CNN:这一工作重点是卷积神经网络(CNN),用于从两种不同的模态进行特征融合。
-
基于Transformer:这一系列工作通常利用 Transformer 模块,即交叉关注来自不同模态的交叉关注特征,并形成更精细的特征表示。
六、radarfusion主要论文
找了几篇个人觉得还算代表性的论文,作简要说明,旨在对近年radar自动驾驶感知领域内做一个大致的了解,论文的具体内容建议看原论文或CSDN等网站上的详细解析。
1 CenterFusion(WACV2021)
这篇论文发布时间较早,检测效果在今天看来并不是很理想,但此篇论文的融合思想确实对后续研究产生了不小的影响,所以放在第一篇简单介绍一下。
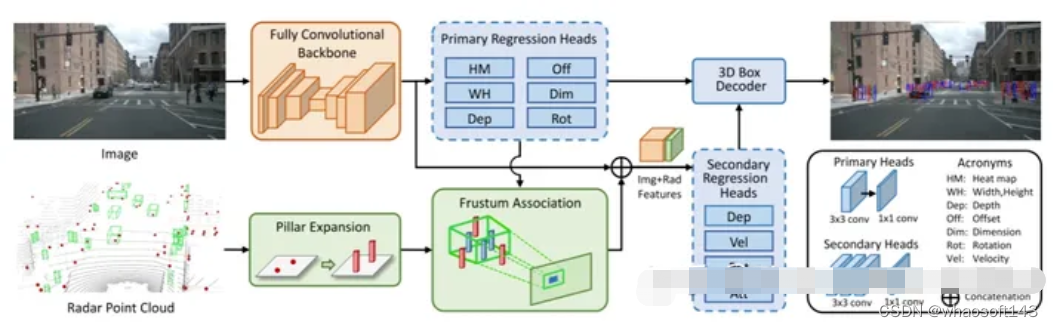
网络模型结构如图,CenterFusion以CenterNet作为baseline模型。整个模型结构可分为两个stage,首先,采用CenterNet对图像进行特征提取和预测,完成基于图像的2D和3D预测,得到目标物的中心点热力图、中心点偏移量、2D宽高、3D维度、距离和旋转角度,并生成2D边界框,通过视锥投影关联到radar数据(经过Pillar Expansion后),在这个物体范围内提取radar数据,这在论文中称之为RoI截锥关联方法,从物体截锥体范围内提取的毫米波雷达数据就是深度信息和速度信息,将radar的深度和速度信息,作为图像的补充特征,将这3个新的热力图通道与之前CenterNet模型的bachbone的输出特征沿深度维拼接在一起,如此便实现了毫米波雷达信息与可见光相机数据的中段融合。CenterFusion可归类于特征融合的Proposal generation和RoI head阶段的融合方式。
在nuScenes数据集上应用评估,在3D目标检测标签下,比之前所有基于Camera的目标检测方法都要好。
2 CRF-Net(2019 IEEE会议)
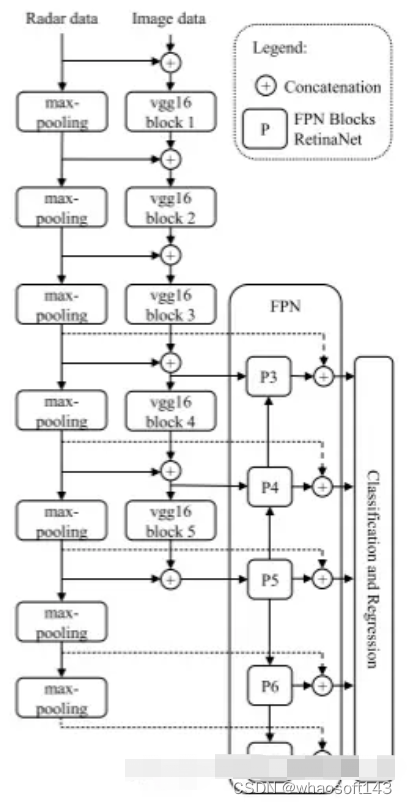
作者提出了CRF-Net的融合网络,其借鉴了RetinaNet的网络结构,如上图,利用VGG网络提取图像特征,在每个block后都进行特征融合,作者认为这样的融合方式可以使模型自行选择在合适的层级进行融合。这一方法属于特征融合中的backbone阶段融合方式。
其创新点主要有两个方面:第一,radar数据的预处理方式,先将radar数据映射到图像坐标下,并在高度上扩充至3米(检测的车辆通常在这个高度之内),如此处理后,在融合时,直接将图像或图像特征直接与radar数据在深度维度上进行拼接即可;第二,作者引入了BlackIn方法,由于图像信息的丰富程度和在训练中重要性远大于radar数据,BlackIn方法尝试在训练中直接丢弃图像信息输入流(图中的虚线部分),使网络单纯依赖radar数据进行训练,这一方式提升了radar数据在整个模型中占有的重要性。
CRF-Net相较于baseline提升效果比较一般,但在论文中作者还使用了十分逼近于真实场景的radar数据进行训练验证(GRF,ground-truth radar filter),验证精度较之前的43.95%提升到了55.99%,由此可以看出,若是能在radar数据与处理方面做得更出色,radar在目标检测中的潜力会十分巨大。
3 CRAFT(AAAI 2023)(NuScenes2022.7)
为了解决late-fusion无法充分发挥两种模态互补性的缺点,作者提出了一种proposal-level的毫米波与相机融合方法,有效地利用相机和雷达的空间和上下文属性进行3D目标检测。我们的融合框架首先将图像proposal与极坐标系中的雷达点相关联,以有效地处理坐标系和空间属性之间的差异。使用此作为第一阶段,然后基于交叉注意的特征融合层自适应地交换相机和雷达之间的spatio-contextual信息,在nuScenes测试集上实现了最先进的41.1%mAP和52.3%NDS,比仅使用相机的bameline高出8.7和10.8分。
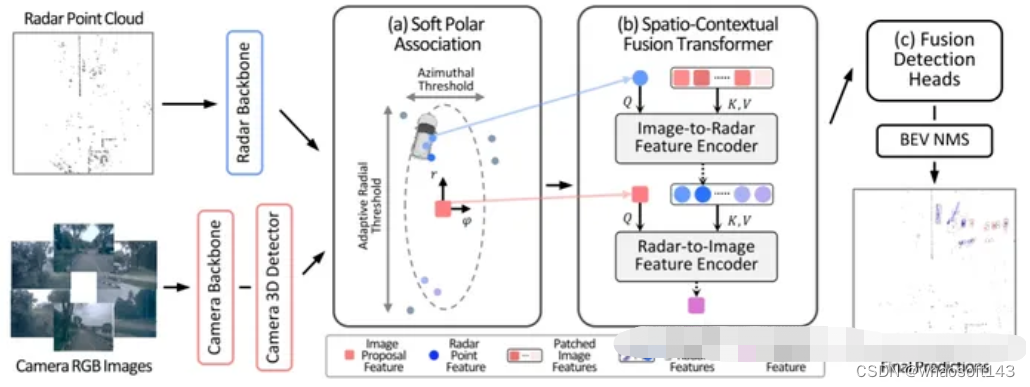
CRAFT提出了Soft-Polar-Association (SPA)和 Spatio-Contextual Fusion Transformer(SCFT)两种结构,在相机和radar之间可高效地进行信息交互。SPA建立起radar点云特征与图像proposal之间的软关联,再通过SCFT中的连续两个交叉注意力encoder利用单个模态的信息补充到另一模块。
CRAFT用到了很多目前较为火热的方法,属于特征融合中的proposal阶段融合,采用了软关联和在两个模态间互相作cross-attention的方式融合特征,在CenterNet的banseline上提升明显。
4 CRN(ICCV2023)
CRN是2023年3月进入了NuScenes的排行榜,达到了57.5%mAP,62.4%NDS,领先于当时所有基于camera和camera-radar的目标检测方法。
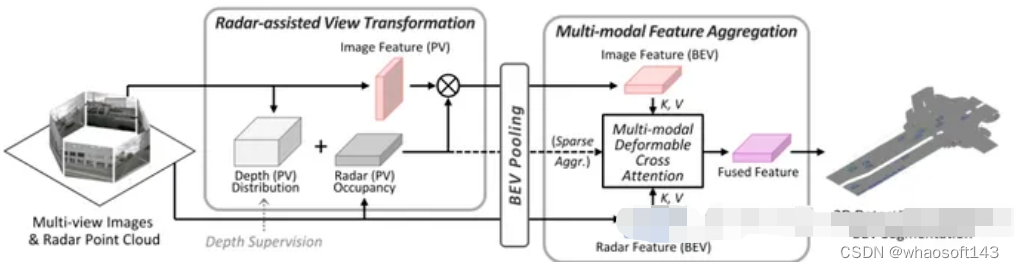
整体网络结构如上图,主要流程分为两步,首先,利用radar数据作辅助将图像信息转换到BEV空间,其次,通过多模态特征聚合模块对radar和图像的BEV特征进行融合,后续进行相应的检测、跟踪或分割等任务。
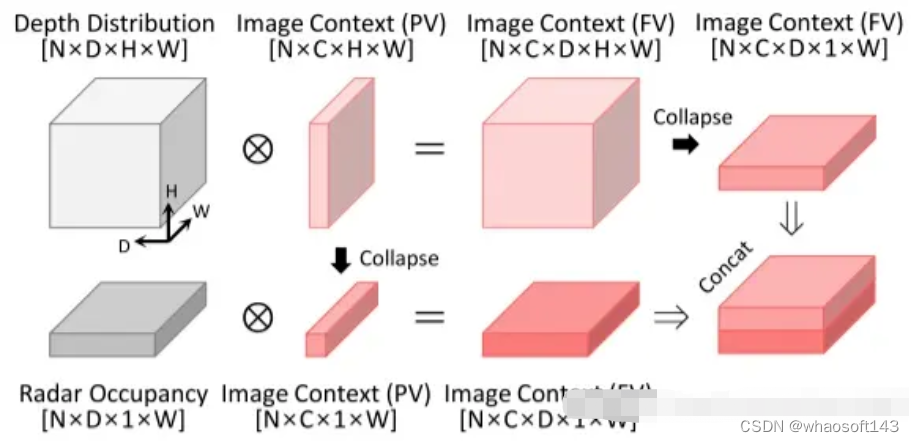
CRN的创新点主要有RVT(雷达辅助视角转换)和MFA(多模态特征聚合)两个模块。RVT模块核心思想是通过radar中精准的深度距离信息辅助图像信息转换至BEV视角下,这一模块提升了图像信息视角转化的精确度。MFA改变了以往拼接或直接相加的特征融合方式,作者认为这些简单的方式不能处理两种模态之间的空间未对准和模糊性,效果十分一般,于是便提出了使用可变形的注意力机制以自适应学习的方式利用多模态特征。
5 FUTR3D(CVPR 2023)
现有的多模态3D检测模型通常涉及定制设计,具体取决于传感器组合或设置。这项工作,是一个统一的、用于3D检测、端到端传感器融合框架FUTR3D,它可以用于(几乎)任何传感器配置。FUTR3D采用了一个基于查询的不可知模态特征采样器(Modality-Agnostic Feature Sampler,MAFS),以及一个具有用于3D检测的集合-集合损失函数的transformer解码器,从而避免后融合的启发式方法和后处理等。在摄像机、低分辨率激光雷达、高分辨率激光雷达和雷达的各种组合上验证了该框架的有效性。FUTR3D通过不同的传感器配置实现了极大的灵活性,并实现了低成本的自动驾驶。
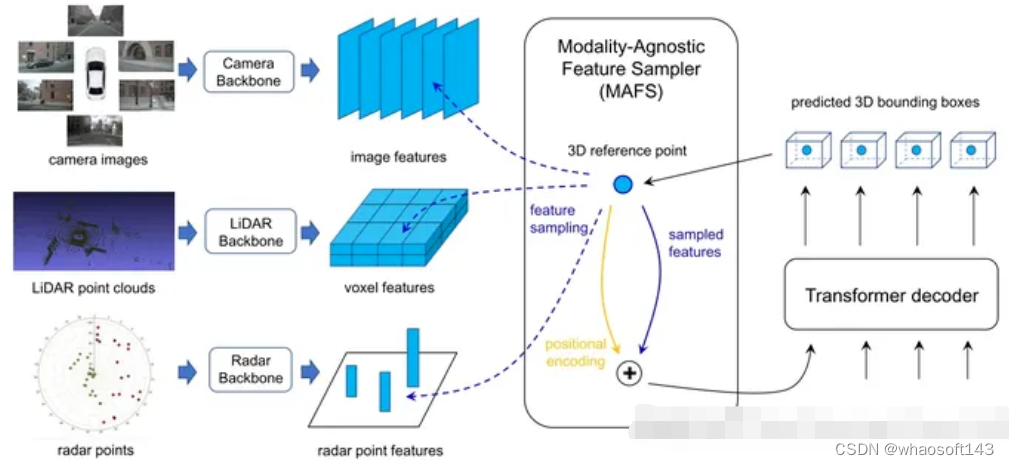
FUTR3D的主要创新是基于查询的不可知模态特征采样器(Modality-Agnostic Feature Sampler,MAFS),论文中先通过不同的backbone分别对各自模态做特征提取。初始化3D参考点查询,依次查询不同模态的输出特征,每融合一种模态特征相当于更新一次查询,融合完所有特征后,再作一次self attention和前馈神经网络。 whaosoft aiot http://143ai.com
FUTR3D提出了一个统一的端对端的传感器融合的3D目标检测框架,MAFS模块使模型能够融合多个传感器共同工作,这一架构为之后的多传感器融合框架提供了一个范式。
6 EchoFusion(NIPS 2023)
EchoFusion是一篇比较新的工作,刚被NIPS接收,代码还在上传过程中,不同于前面提到的几篇论文,EchoFusion使用的雷达数据为4D雷达原始数据,文中将未经过滤波处理的一系列雷达数据称为原始雷达数据,如RA,RAD,RD张量以及ADC数据。
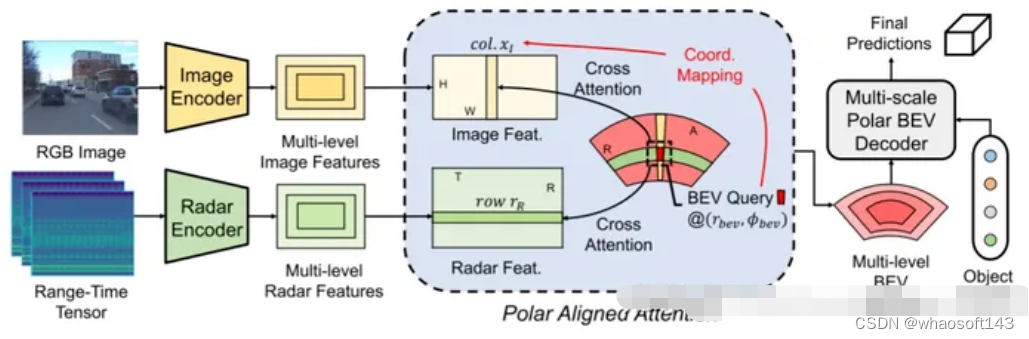
EchoFusion的主要创新点在于Polar Aligned Attention(PAA),在极坐标BEV空间中生成Query,由于图片特征缺少深度信息,采用图像中col维度与极坐标BEV空间中的A(角度)维度对应的方式进行cross attention计算,同样对于radar特征来说,采用距离维度对应的方式即可。这里的雷达数据虽然没有显式解码AoA,但AoA信息已经隐式地被编码到了不同虚拟天线的响应相位差中。
EchoFusion在RADIal数据集上的多个指标中取得了最佳性能,包括AP、AR等评价指标。这一工作证明了雷达可以作为自动驾驶系统中Lidar的低成本的有力替代品,利用原始雷达数据能取得非常不错的性能,使雷达感知可以摈弃冗余的前处理步骤,使端到端模型能成为主流。不过目前自动驾驶雷达数据集,尤其是原始雷达数据集十分匮乏,能建立其一个庞大的基于雷达的自动驾驶数据集将会促进进一步的研究进展。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









