







 文章介绍了小红书搜索算法团队在AAAI2024上提出的一种新框架,通过在大模型蒸馏过程中充分利用负样本知识,尤其是处理复杂数学问题时。该框架包括负向协助训练、负向校准增强和动态自洽性,实验结果表明这种方法能有效提升模型的专业化和性能。
文章介绍了小红书搜索算法团队在AAAI2024上提出的一种新框架,通过在大模型蒸馏过程中充分利用负样本知识,尤其是处理复杂数学问题时。该框架包括负向协助训练、负向校准增强和动态自洽性,实验结果表明这种方法能有效提升模型的专业化和性能。
大语言模型(LLMs)在各种推理任务上表现优异,但其黑盒属性和庞大参数量阻碍了它在实践中的广泛应用。特别是在处理复杂的数学问题时,LLMs 有时会产生错误的推理链。传统研究方法仅从正样本中迁移知识,而忽略了那些带有错误答案的合成数据。
在 AAAI 2024 上,小红书搜索算法团队提出了一个创新框架,在蒸馏大模型推理能力的过程中充分利用负样本知识。负样本,即那些在推理过程中未能得出正确答案的数据,虽常被视为无用,实则蕴含着宝贵的信息。验证负样本对大模型蒸馏的价值
论文提出并验证了负样本在大模型蒸馏过程中的价值,构建一个模型专业化框架:除了使用正样本外,还充分利用负样本来提炼 LLM 的知识。该框架包括三个序列化步骤,包括负向协助训练(NAT)、负向校准增强(NCE)和动态自洽性(ASC),涵盖从训练到推理的全阶段过程。通过一系列广泛的实验,我们展示了负向数据在 LLM 知识蒸馏中的关键作用。
背景
如今,在思维链(CoT)提示的帮助下,大语言模型(LLMs)展现出强大的推理能力。然而,思维链已被证明是千亿级参数模型才具有的涌现能力。这些模型的繁重计算需求和高推理成本,阻碍了它们在资源受限场景中的应用。因此,我们研究的目标是使小模型能够进行复杂的算术推理,以便在实际应用中进行大规模部署。
知识蒸馏提供了一种有效的方法,可以将 LLMs 的特定能力迁移到更小的模型中。这个过程也被称为模型专业化(model specialization),它强制小模型专注于某些能力。先前的研究利用 LLMs 的上下文学习(ICL)来生成数学问题的推理路径,将其作为训练数据,有助于小模型获得复杂推理能力。然而,这些研究只使用了生成的具有正确答案的推理路径(即正样本)作为训练样本,忽略了在错误答案(即负样本)的推理步骤中有价值的知识。
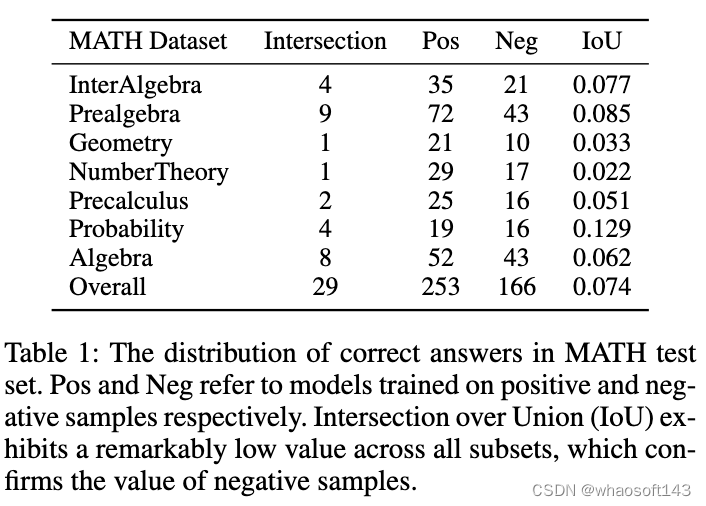
如图所示,表 1 展示了一个有趣的现象:分别在正、负样本数据上训练的模型,在 MATH 测试集上的准确答案重叠非常小。尽管负样本训练的模型准确性较低,但它能够解决一些正样本模型无法正确回答的问题,这证实了负样本中包含着宝贵的知识。此外,负样本中的错误链路能够帮助模型避免犯类
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









