







Lightning Attention-2 是一种新型的线性注意力机制,让长序列的训练和推理成本与 1K 序列长度的一致。无限序列长度、恒定算力开销、更高建模精度
大语言模型序列长度的限制,极大地制约了其在人工智能领域的应用,比如多轮对话、长文本理解、多模态数据的处理与生成等。造成这一限制的根本原因在于当前大语言模型均采用的 Transformer 架构有着相对于序列长度的二次计算复杂度。这意味着随着序列长度的增加,需要的计算资源成几何倍数提升。如何高效地处理长序列一直是大语言模型的挑战之一。
之前的方法往往集中在如何让大语言模型在推理阶段适应更长的序列。比如采用 Alibi 或者类似的相对位置编码的方式来让模型自适应不同的输入序列长度,亦或采用对 RoPE 等类似的相对位置编码进行差值的方式,在已经完成训练的模型上再进行进一步的短暂精调来达到扩增序列长度的目的。这些方法只是让大模型具有了一定的长序列建模能力,但实际训练和推理的开销并没有减少。
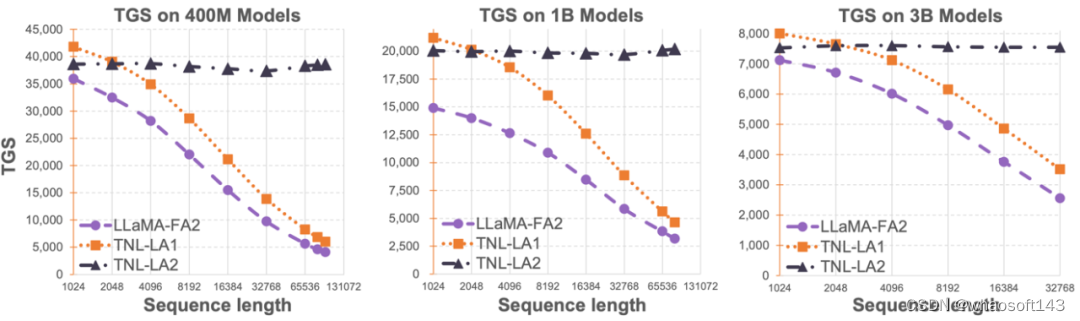
OpenNLPLab 团队尝试一劳永逸地解决大语言模型长序列问题。他们提出并开源了 Lightning Attention-2—— 一种新型的线性注意力机制,让长序列的训练和推理成本与 1K 序列长度的一致。在遇到显存瓶颈之前,无限地增大序列长度并不会对于模型训练速度产生负面影响。这让无限长度预训练成为了可能。同时,超长文本的推理成本也与 1K Tokens 的成本一致甚至更少,这将极大地减少当前大语言模型的推理成本。如下图所示,在 400M、1B、3B 的模型大小下,随着序列长度的增加,FlashAttention2 加持的 LLaMA 的训练速度开始快速下降,然而 Lightning Attention-2 加持的 TansNormerLLM 的速度几无变化。
-
论文:Lightning Attention-2: A Free Lunch for Handling Unlimited Sequence Lengths in Large Language Models
-
论文地址:https://arxiv.org/pdf/2401.04658.pdf
-
开源地址:https://github.com/OpenNLPLab/lightning-attention
Lightning Attention-2 简介
让大模型的预训练速度在不同序列长度下保持一致,这
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









