







# 三维重建迈向3D GS新时代,NeRF成为过去?
3D Gaussian Splatting(3D-GS)已成为计算机图形学领域的一个重大进步,它提供了明确的场景表示和新颖的视图合成,而不依赖于神经网络,如神经辐射场(NeRF)。这项技术在机器人、城市地图、自主导航和虚拟现实/增强现实等领域有着不同的应用。鉴于3D Gaussian Splatting的日益流行和研究的不断扩展,本文对过去一年的相关论文进行了全面的综述。我们根据特征和应用对分类法进行了调查,介绍了3D Gaussian Splatting的理论基础。我们通过这项调查的目标是让新的研究人员熟悉3D Gaussian Splatting,为该领域的开创性工作提供宝贵的参考,并启发未来的研究方向。
总结来说,本文的主要贡献如下:
-
具有系统分类学的统一框架。我们引入了一个统一实用的框架来对现有作品进行3D高斯分类。该框架将该领域划分为6个主要方面。此外还提供了3D高斯应用的详细分类法,提供了该领域的全面视角。
-
全面和最新的调查。我们的综述对3D-GS进行了广泛而最新的调研,涵盖了经典和前沿方法。对于每个类别,我们提供细粒度的分类和简洁的摘要。
-
对3D-GS未来方向的见解。我们强调了当前研究的技术局限性,并为未来的工作提出了几个有希望的途径,旨在激励这一快速发展的领域取得进一步进展。特别强调探索3D-GS的潜在作用,为其未来应用提供见解。
相关背景
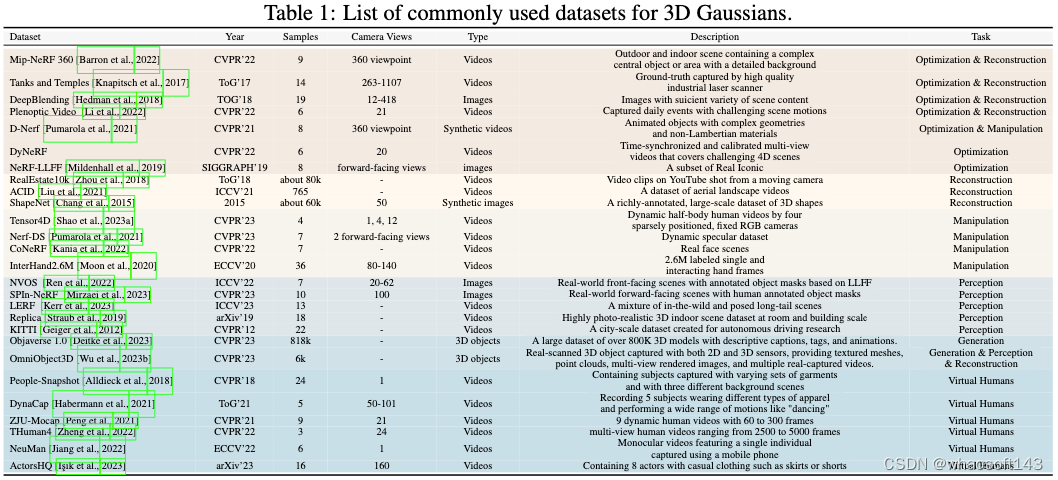
数据集:利用各种公开可用的数据集来评估3D-GS在各种任务上的性能。表1概述了3D-GS在优化、重建、操作、生成、感知和人体方面的一些数据集。
Gaussian Intrinsic Properties的优化
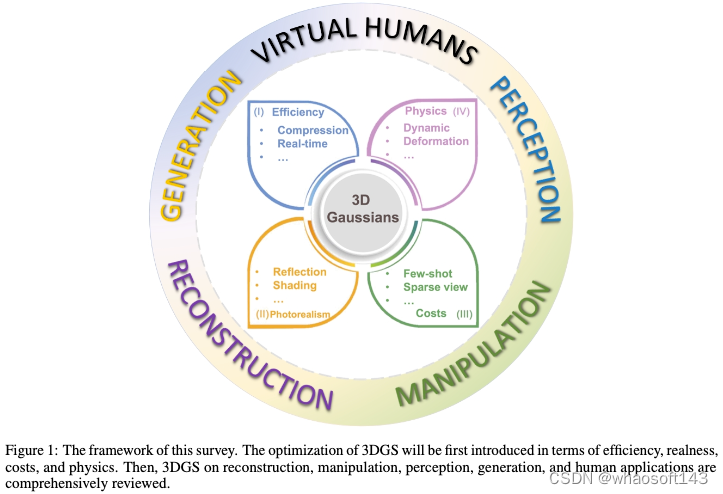
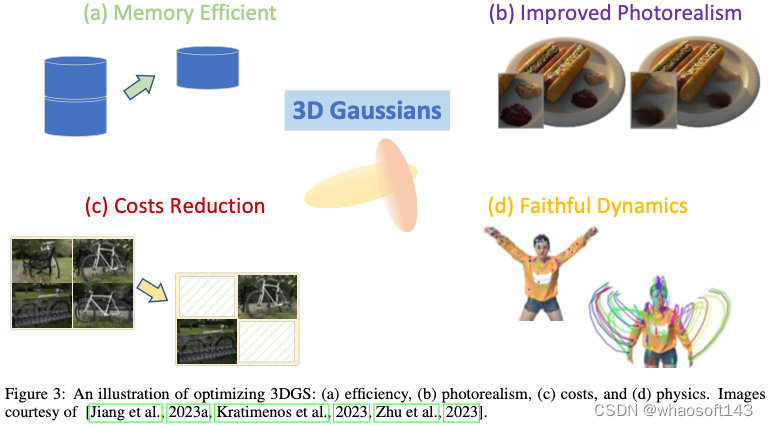
尽管已经展示了3D高斯Splatting的能力和效率,但在以下有希望的方向上仍有进一步改进的空间(如图3所示):(a)使3D-GS更具内存效率对于实时渲染至关重要;(b)可以进一步提高渲染图像的质量;(c)降低用于合成新颖视图的图像的成本;(d)使3D Gaussians能够用真实的动力学来表示动态场景。
效率
代表场景的数百万高斯内的参数需要巨大的存储空间,因此在保持质量的同时减少内存使用对于实时渲染至关重要且有益。
在grid-guided NeRF的启发下,Lu提出了Scaffold GS,它在保持可比渲染质量和速度的同时,具有内存效率。Scaffold GS利用底层场景结构来帮助修剪过度扩展的高斯球。它利用SfM中的初始化点来构建锚点的稀疏网格,每个锚点上都附加了一组可学习的高斯。这些高斯的属性是根据特定的锚点特征实时预测的。此外,在通过修剪操作消除重要和琐碎锚的地方,采用由神经高斯的聚合梯度引导的策略来生长锚点。增加了一个额外的体积正则化损失项,以鼓励高斯系数较小,重叠最小。
挑战:用复杂的细节来表现场景需要大量的3D高斯。Gaussians所需的巨大存储空间不仅阻碍了它在边缘设备上的应用,而且限制了渲染速度。
机会:现有的矢量量化和对不重要高斯方法的修剪已经证明了它们在压缩静态场景的3D高斯方面的有效性。然而,将它们扩展到动态场景并提高动态表示的紧凑性仍然没有得到充分的探索。
真实性
混叠问题和伪影在splatting过程中出现,解决它们显然有利于渲染图像的质量和真实性。此外,还可以进一步提高场景中反射的真实性。
Yan介绍了一种在3DGS中减少混叠效应的多尺度方法。他们假设,这样的问题主要是由填充在具有复杂3D细节的区域中的大量Gaussionssplatting引起的。因此,他们建议以不同的细节级别来表示场景。对于每个级别,在每个体素中低于特定大小阈值的小的和细粒度的高斯被聚集成较大的高斯,然后插入到随后的较粗级别中。这些多尺度高斯有效地对高频和低频信号进行编码,并使用原始图像及其下采样对应图像进行训练。在渲染过程中,相应地选择具有适当比例的高斯,这导致了质量的提高和渲染速度的提高。
挑战:尽管3D高斯投影到2D图像上大大加快了渲染过程,但它使遮挡的计算变得复杂,从而导致照明估计较差。同时,欠正则化的3D-GS无法捕捉精确的几何体,也无法原生地生成精确的法线。此外,混叠问题和伪影会降低渲染图像的质量,尤其是在为看不见的相机视图进行合成时。
机会:与视图相关的变化对于具有镜面反射目标和复杂反射的场景至关重要。因此,赋予3D-GS捕捉显著外观属性的能力有利于增强渲染的真实性。为了更好地减少混叠效应,值得研究在不影响其表达能力的情况下更有效地消除多余高斯的方法。此外,由于缺乏严格的正态估计和几何正则化,阻碍了图像质量的提高,可以进一步弥补这一不足。
开销
为了合成高质量的新颖视图,所需的图像量是巨大的。放松这一限制对于进一步探索3D-GS的潜力是可取的。
已经提出了一些工作来解决3D-GS中的few-shot问题。Chung引入了一种深度正则化方法来避免few-shot图像合成中的过拟合。通过分别利用从COLMAP和单目深度估计模型获得的稀疏和密集深度图来引入几何约束。为了防止过拟合,该方法对几何平滑度采用无监督约束,并利用Canny边缘检测器来避免深度变化显著的边缘区域的正则化。
挑战:3D-GS的性能在很大程度上取决于初始化稀疏点的数量和准确性。这种默认的初始化方法自然与降低图像成本的目标相矛盾,并使其难以实现。此外,初始化不充分可能导致过拟合,并产生过平滑的结果。
机会:使用额外的单目深度估计模型可以提供有用的几何先验来调整3D高斯,以有效覆盖场景。然而,这种对估计精度的强烈依赖性可能导致具有复杂表面的场景的重建较差,其中模型无法输出准确的预测。有希望进一步探索有效加密和调整3D高斯的方法,并充分利用几何信息来提高渲染质量。
物理性
通过将3D Gaussians的能力从静态场景扩展到4D场景,增强3D Gaussian的能力是有益的,4D场景可以结合与真实世界物理一致的动力学。
在动态场景中,学习变形比在每个时间步长对场景建模更方便。吴提出了一种新的实时3D动态场景渲染框架。他们的框架没有直接为每个时间戳构建3D高斯,而是首先使用时空编码器,利用多分辨率K-Planes和MLP进行有效的特征提取。然后,多头MLP充当解码器,并基于输入特征分别预测3D高斯的位置、旋转和缩放的变形。这种方法学习高斯变形场,从而实现高效的内存使用和快速收敛。
挑战:输入点云的内在稀疏性对重建具有真实动力学的场景提出了重要挑战。在保持质量的同时捕捉物理上合理的动力学更具挑战性,例如,以高保真度渲染阴影的变化。
机会:具有大运动的目标可能会在连续帧之间造成不自然的失真,将神经网络与学习的特定场景动力学相结合可以提高变形的保真度。当前用于重建动态场景的方法主要关注室内目标级变形,并且它们仍然需要从多个相机视图拍摄的图像以及精确的相机姿势。将3D-GS扩展到更大的动态场景并放松这种限制对现实世界的应用非常有益。
重建
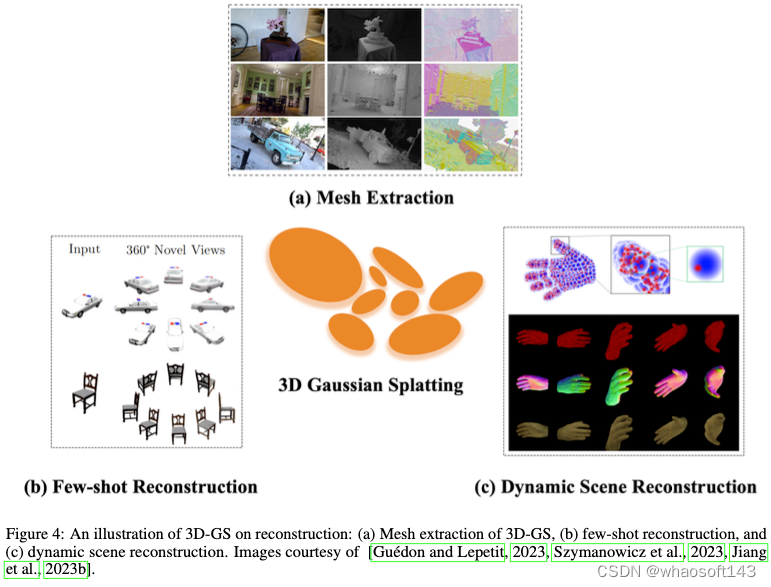
如前所述,3D-GS在从新颖视点捕捉和渲染3D场景中的广泛采用可归因于其卓越的渲染速度和产生逼真结果的能力。与NeRFs类似,3D-GS中曲面网格的提取(如图4a所示)是一个基本但必不可少的方面。有必要进行进一步的调查,以应对具有挑战性的场景,如单眼或few-shot的情况(如图4b所示),这在自动驾驶等实际应用中很常见。此外,3D-GS的训练时间约为分钟,实现了实时渲染并有助于动态场景的重建(如图4c所示)。
曲面网格提取
曲面网格提取是计算机视觉中的一个经典挑战。然而,通过3D高斯分布的场景的显式表示为该任务引入了显著的复杂性。因此,已经提出了几种新的方法来有效地解决这种复杂性并促进表面网格的提取。
Guédon介绍了用于3D网格重建和高质量网格渲染的SuGaR。SuGaR包含了一个正则化术语,以促进高斯和场景表面之间的对齐。然后使用泊松重建方法来利用这种对齐,并从高斯方程中导出网格。为了将高斯图绑定到网格表面,SuGaR提供了一种可选的细化策略,该策略使用高斯splatting渲染来优化高斯图和网格。然而,对高斯图的强制性限制会导致渲染质量下降。然而,这些限制会提高网格提取的性能。同时,陈介绍了NeuSG,它联合优化了NeuS和3D-GS,以实现高度精细的表面恢复。与SuGaR中的正则化项类似,NeuSG结合了正则化子,以确保由极薄的3D高斯生成的点云紧密附着在下表面上。这种方法利用了联合优化的优势,从而生成具有复杂细节的综合曲面。
单目和Few-shot重建
3D-GS的引入代表了单目和few-shot重建任务的一个有希望的进展。然而,这些任务中的一个重大挑战是缺乏几何信息。因此,许多研究都致力于解决这一挑战,并提出创新的方法来克服缺乏透视几何信息的问题。
起初,用于few-shot3D重建的技术允许用有限量的输入数据来重建3D场景。Charatan展示了PixelSplat,用于从图像对进行3D重建。PixelSplat的主要重点是通过提出一种多视图核极变换器来解决比例因子推理的挑战。PixelSplat利用尺度感知特征图,提出了一种预测高斯基元集参数的新方法。场景通过像素对齐的高斯进行参数化,从而在训练过程中隐式生成或删除高斯基元。这种策略有助于避免局部极小值,同时确保梯度流的平滑。
单目3D重建能够使用单个相机从2D图像推断3D场景的形状和结构。单目3D重建的关键在于对图像中的透视关系、纹理和运动模式进行细致的分析。通过采用单目技术,可以准确估计物体之间的距离并辨别场景的整体形状。Szymanowicz介绍了Splatter Image,这是一种用于单目3D目标重建的超快速方法。这种方法利用2D CNN架构来有效地处理图像,预测伪图像,其中每个像素由彩色3D高斯表示。Splatter Image演示了在合成和真实基准上的快速训练和评估,而不需要标准的相机位姿。此外,它还能够通过结合跨视图注意力进行few-shot3D重建。
动态场景重建
3D-GS的高渲染速度和分辨率支持动态场景重建,包括人体跟踪和大型城市场景重建。
林介绍了基于3D-GS的高斯流,用于快速动态3D场景重建和实时渲染,方便了静态和动态3D场景的分割、编辑和合成。该方法引入了双域变形模型(DDDM),通过时域的多项式拟合和频域的傅立叶级数拟合来捕捉每个属性的时间相关残差。高斯流能够消除为每个帧训练单独的高斯算子的需要,或者引入额外的隐式神经场来建模3D动力学。
挑战:由于3D-GS是一个用于重建的显式表示模型,每个高斯核可能不一定位于某个目标的表面上,这对表面网格提取提出了挑战。需要约束高斯核以附着到目标的表面,但这可能会导致渲染精度降低。
机会:(i)对于few-shot重建,与扩散模型集成或消除对相机位姿的要求可以促进大规模训练。(ii)此外,对于表面网格提取,引入光照分解的方法可以提取更真实的表面纹理。(iii)在动态场景重建中,优先考虑速度和图像细节保存之间的平衡优化可能是相当可观的。
Manipulation
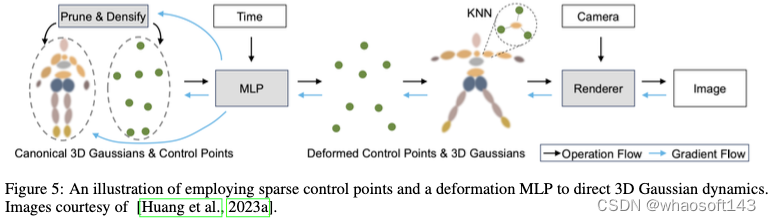
由于3D-GS的显式特性,它对于编辑任务具有很大的优势,因为每个3D高斯都单独存在(图5)。通过在应用所需约束的情况下直接操纵3D高斯,可以轻松编辑3D场景。
Text-guided Manipulation
近年来,文本引导操作的数量激增。因此,文本引导操作由于其接近人类语音而引起了越来越多的关注。此外,随着对大型语言模型的访问变得越来越广泛,LLM引导操作的使用有望成为未来的发展方向。方向GaussianEditor介绍了使用3D Gaussians和文本指令对3D场景进行精确编辑的方法。第一步涉及提取与所提供的文本指令相对应的感兴趣区域(RoI),并将其与3D高斯对齐。然后,该高斯RoI用于控制编辑过程,从而实现细粒度调整。
Non-rigid Manipulation
非刚性目标可以改变和变形形状,从而能够更逼真地模拟软目标、生物组织和流体。这些目标提供了几个优点,包括提高真实性和改进对目标变形和行为的描述。此外,这些模型允许不同的效果,因为它们可以通过变形来响应外力和约束。然而,非刚性物体也存在某些挑战。它们的特点是其复杂性,在编辑和模拟过程中需要仔细考虑目标变形、连续性和碰撞等因素。此外,非刚性目标的实时交互性能在应用中可能会受到限制,特别是在处理大规模和复杂的非刚性目标时。
Time-efficient Editing
虽然3DGS确实是一种快速渲染技术,但在编辑3D高斯图时,它的实时操作至关重要。因此,迫切需要开发具有时间效率的3DGS的编辑方法。
黄提出了Point'nMove,通过曝光区域修复实现场景目标的交互式操作。直观的目标选择和实时编辑增强了交互性。为了实现这一点,他们利用了高斯Splatting辐射场的明确性质和速度。显式表示公式允许开发双阶段自提示分割算法,其中2D提示点用于创建3D掩模。该算法有助于遮罩细化和合并,最大限度地减少更改,为场景修复提供良好的初始化,并实现实时编辑,而无需每次编辑训练。同时,陈介绍了用于3D编辑的GaussianEditor,该编辑器使用高斯splatting来增强整个编辑过程的控制和效率。GaussianEditor采用高斯语义跟踪来准确识别和定位特定的编辑区域。然后,它利用分层高斯splatting(HGS)在流动性和稳定性之间取得平衡,从而在随机原理的指导下产生详细的结果。此外,GaussianEditor还包括用于高斯splatting的专用3D修复算法,该算法简化了目标的移除和集成,并显著缩短了编辑时间。
4D Manipulation
随着动态神经3D表示的引入,4D场景重建领域取得了显著进展。这些进步极大地提高了捕捉和描绘动态场景的能力。然而,尽管取得了这些突破,这些4D场景的交互式编辑仍然存在重大障碍。主要挑战在于保证4D编辑过程中的时空一致性和保持高质量,同时提供交互式和高级编辑功能。
Shao介绍了使用文本指令编辑动态4D 资产的Control4D。Control4D旨在克服4D编辑中常见的挑战,特别是现有4D表示的局限性以及基于扩散的编辑器导致的不一致编辑结果。GaussianPlanes最初被提出作为一种新的4D表示,它通过在3D空间和时间中基于平面的分解来增强高斯splatting的结构。这种方法提高了4D编辑的效率和稳健性。此外,利用4D生成器从基于扩散的编辑器生成的编辑图像中学习更连续的生成空间,有效地增强了4D编辑的一致性和质量。
挑战:首先,在文本引导操作中,兴趣区域(ROI)的选择依赖于分割模型的性能,而分割模型受到噪声的影响。其次,在编辑3D高斯图时,经常会忽略几个重要的物理方面。最后,在4D编辑中实现帧一致性仍有改进的空间。
机会:i)在3D-GS的操作中,现有的2D扩散模型在为复杂的提示提供足够的指导方面遇到了困难,导致在3D编辑时受到限制。因此,高效准确的2D扩散模型可以作为编辑3D高斯的更好指导。ii)现有方法主要通过最小的运动变化和准确的相机姿态进行了测试。将其适用范围扩大到涉及激烈运动的场景仍然是一个有待调查的领域。
生成
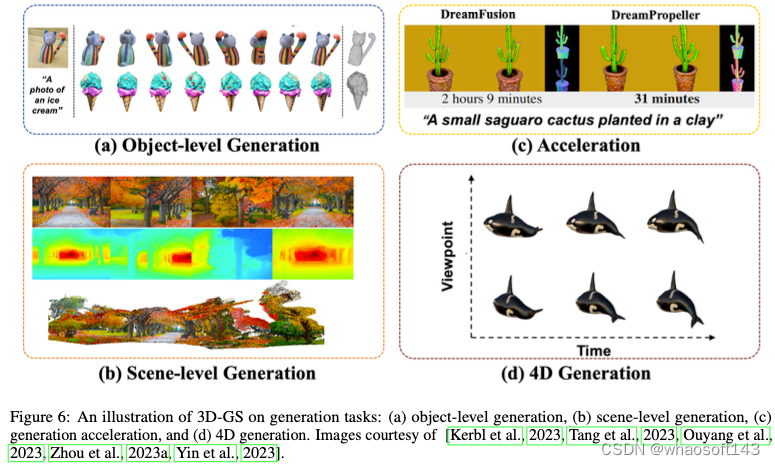
由于在扩散模型和3D表示方面取得了重大进展,从文本/图像提示生成3D资产现在是AIGC领域一项很有前途的任务。此外,采用3D-GS作为目标(图6a)和场景(图6b)的显式表示,可以实现快速甚至实时渲染。此外,一些工作侧重于改进分数蒸馏采样(SDS)管道中固有的耗时优化过程(图6c)。虽然3D生成已经显示出一些令人印象深刻的结果,但4D生成(图6d)仍然是一个具有挑战性且未充分探索的主题。
Object-level 3D Generation
3D扩散模型在3D生成中具有良好的3D一致性,而二维扩散模型具有较强的泛化能力。Yi将两者的优点结合起来,提出了用于快速生成和实时渲染的GaussianDreamer。GaussianDreamer首先在3D扩散模型的帮助下初始化3D Gaussians,以获取几何先验,并引入噪声点增长和颜色扰动两种操作来补充初始化的Gaussianss,以进一步丰富内容。随后,借助于2D扩散模型和SDS的文本提示,对3D高斯进行了优化。然而,这种方法仍然存在多人脸问题,并且无法生成大规模场景。
Scene-level 3D Generation
Vilesov提出CG3D以合成方式生成可缩放的3D资产,以仅从文本输入形成物理逼真的场景。CG3D用一组高斯表示场景中的每个目标,并将目标转换为具有旋转、平移和缩放等交互参数的合成坐标。
3D生成加速
具有NeRF表示的2D提升方法因其耗时的优化过程而臭名昭著。因此,唐提出了DreamGaussian,通过用3D Gaussian Splatting代替NeRF表示来提高3D生成效率。具体而言,DreamGaussian通过高斯splatting的渐进加密简化了优化环境,该方法用随机位置初始化高斯,并定期加密它们,以与生成进度保持一致。为了提高生成质量,它进一步引入了一种高效的网格提取算法,该算法具有逐块局部密度查询和执行图像空间监督的UV空间纹理细化阶段。因此,DreamGaussian可以在2分钟内从单目图像生成高质量的纹理网格。
尽管与基于NeRF的方法相比,利用3D-GS的文本到3D方法具有时间效率优势,但它们仍然会经历较长的生成时间。这主要归因于SDS或变分分数蒸馏(VSD)过程中基于梯度的优化所涉及的复杂计算和广泛迭代。周介绍了Dreamprompt,这是一种嵌入式算法,利用并行计算通过更快地求解ODE来加快蒸馏过程。Dreampromert推广的Picard迭代算法允许并行化涉及可变维度变化的顺序梯度更新步骤。这一功能使Dreamproper非常适合使用3D-GS的3D方法,因为由于其拆分和修剪操作,优化过程可能涉及不同数量的高斯。实验结果表明,速度提高了4.7倍,对发电质量的影响最小。
Text-to-4D Generation
Ling引入了Align Your Gaussians(AYG),将3D合成扩展到具有额外时间维度的4D生成。4D表示将3D高斯场与变形场相结合,对3D高斯场的场景动力学进行建模,并变换它们的集合以表示目标运动。AYG从生成具有3D感知的多视图扩散模型和常规文本到图像模型的初始静态3D形状开始。然后,使用文本到视频模型和文本到图像模型来优化变形场,以分别捕获时间动态并保持所有帧的高视觉质量。此外,采用运动放大机制和新的自回归合成方案来生成和组合多个4D序列,以实现更长的世代。值得注意的是,由于3D高斯的明确性质,可以组合不同的动态场景,每个场景都有自己的高斯集和变形场,从而能够将多个4D目标组合成大型动态场景。
挑战:i)合成生成仍然是一个悬而未决的问题,因为大多数方法都不支持这种创建。尽管CG3D提出了一个组成框架,但它只支持物体之间的刚体相互作用。此外,AYG中的组成4D序列不能描述动态目标的拓扑变化。ii)使原始3D-GS中的自适应密度控制操作适应生成框架是不平凡的,因此简单的方法是固定用于表示目标的高斯数。然而,这样的设计严重限制了模型创建复杂几何体的能力。
机会:i)多面问题,也称为Janus问题,存在于大多数2D提升方法中。如上所述,GaussianDreamer通过引入3D先验来缓解这种不足。有鉴于此,利用3D感知扩散模型或多视图2D扩散模型可以是进一步改进的可能方向。ii)以各种类型的定制数据作为输入并让用户对生成过程有更多控制权的个性化生成应该是未来工作的一条令人兴奋的途径。iii)当文本提示由模糊信息和复杂逻辑组成时,文本到3D的方法往往会产生不令人满意的结果。在这方面,增强文本编码器的语言理解能力也可以提高生成质量。
感知
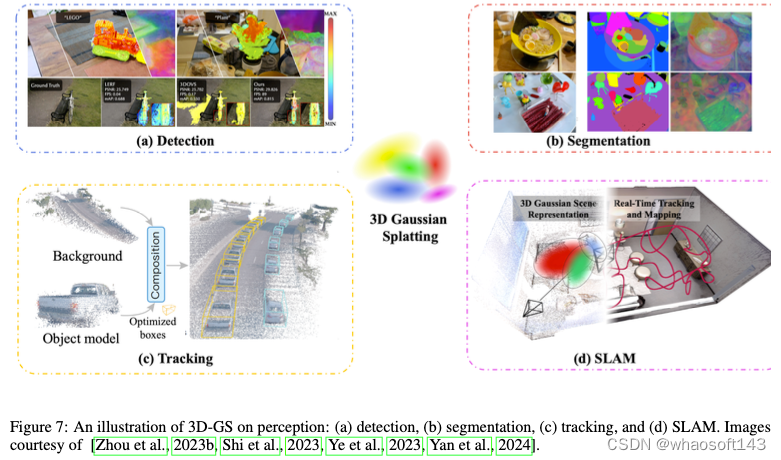
利用3D-GS,3D感知有可能增强开放词汇语义目标检测和定位(图7a)、3D分割(图7b)、运动目标象跟踪(图7c)和SLAM系统的开发(图7d)。
检测
3D场景中的语义目标检测或定位过程可以显著增强对环境的理解和感知,并有利于自动驾驶系统和智能制造等应用。受ChatGPT成功的鼓舞,施介绍了专门为开放词汇查询任务设计的场景表示语言嵌入式3D高斯,它成功地将量化的紧凑语义特征融入到广泛的3D高斯中,最大限度地减少了内存和存储需求。为了缓解不同视角下产生的语义不一致,提出了一种特征平滑程序,利用3D高斯的空间位置和语义不确定性,动态降低嵌入语义特征的空间频率。同时,Zuo提出了基础模型嵌入高斯Splatting(FMGS),它集成了3D-GS来表示几何和外观,以及多分辨率哈希编码(MHE)来实现高效的语言嵌入。FMGS旨在解决房间尺度场景中的内存限制问题。此外,为了解决像素错位的问题,FMGS结合了像素对齐损失,以将相同语义实体的渲染特征距离与像素级语义边界对齐。FMGS的结果显示出显著的多视图语义一致性和在开放词汇上下文中定位语义目标的令人印象深刻的性能。
分割
3D场景分割的意义不仅在于提高场景分割的准确性,还在于为真实世界的3D感知任务提供强大的支持。从实时场景编辑和目标去除到目标修复和场景重组,3D场景分割方法的应用无疑拓宽了计算机视觉在虚拟现实和自动驾驶等领域的视野。
2D分割模型的结合可以成为指导3D-GS分割过程的宝贵资产。这种直观的概念有可能提高分割过程的准确性和效率。Lan介绍了一种3D高斯分割方法,该方法利用2D分割作为监督,为每个3D高斯分配一个目标代码来表示其分类概率分布。提供指导以通过最小化在特定姿势处的2D分割图和渲染的分割图之间的差异来确保每个3D高斯的准确分类。此外,KNN聚类用于解决3D高斯图中的语义模糊问题,而统计滤波用于消除不正确分割的3D高斯图。这种方法成功地获取了3D场景的语义知识,并在短时间内从特定视点有效地分割多个目标,输出了令人信服的结果。
跟踪
3D-GS的使用方便了动态场景的重建。因此,在这些场景中跟踪动态目标已成为一个新的探索领域,对自动驾驶等应用做出了重大贡献。
Zhou介绍了DrivingGaussian重构动态大尺度驾驶场景的方法。DrivingGaussian通过在包含移动目标的场景中使用增量静态3D高斯逐步对静态背景进行建模。DrivingGaussian利用复合动态高斯图来准确重建单个目标,恢复它们的位置,并在存在多个移动目标的情况下有效处理遮挡关系。此外,在3D-GS之前使用激光雷达有助于通过捕捉更精细的细节和确保全景一致性来改进场景重建。DrivingGaussian成功实现了高保真度和多摄像头一致的真实感环绕视图合成,使其适用于广泛的任务,包括角落案例的模拟。
SLAM
在3D感知领域,将3D-GS集成到SLAM系统中引起了人们的极大关注。在本节中,我们将探讨SLAM的各种应用和进步,这些应用和进步是通过集成3D高斯表示而实现的。此外,本节强调了当前方法在解决现实世界场景中的有效性,并强调了SLAM领域内可能性的持续增长。
由于效率的重要性,Yan提出了GS-SLAM,将3D高斯表示集成到SLAM系统中。GS-SLAM利用了实时可微分的splatting渲染管道,显著提高了地图优化和RGB-D重渲染速度。GS-SLAM引入了一种用于扩展3D高斯的自适应策略,旨在有效地重建新观测到的场景几何结构。此外,它采用了从粗到细的技术来选择可靠的3D高斯,提高了相机姿态估计的准确性。GS-SLAM有效地提高了效率和准确性之间的权衡,超过了最近使用神经隐式表示的SLAM方法。
相机位姿估计
相机位姿估计是3D重建和感知领域的一个基础方面。3D-GS的结合有可能为这一重要主题提供有见地的方法。
在SLAM中,估计6D姿态的任务提出了相当大的挑战。为了解决这一挑战,Sun引入了iComMa,将传统的几何匹配方法与渲染比较技术相结合。iComMa反转3D-GS以捕捉姿态梯度信息,用于精确的姿态计算,并采用渲染和比较策略,以确保在优化的最后阶段提高精度。此外,还引入了匹配模块,通过最小化2D关键点之间的距离来增强模型对不利初始化的鲁棒性。iComMa旨在有效处理各种复杂和具有挑战性的场景,包括具有显著角度偏差的情况,同时保持预测结果的高精度。
挑战:(i)现有的基于3D-GS的动态场景目标跟踪方法在跟踪可变形目标(如行人)方面可能会遇到挑战,这给自动驾驶等系统带来了困难。(ii)此外,检测高反射或半透明物体,如电视和镜子,仍然是一项具有挑战性的任务,因为3D-GS对这些物体的建模能力有限。(iii)SLAM系统可能对各种因素表现出敏感性,包括运动模糊、大量深度噪声和剧烈旋转。(vi)此外,在3D-GS的表示中,高斯分布可以链接到多个目标,从而增加了利用特征匹配精确分割单个目标的复杂性。
机会:(i)基于3D-GS的实时跟踪有潜力应用于各种医疗场景,包括放射治疗。(ii)此外,输入已知的相机本质和密集深度对于执行SLAM至关重要,消除这些依赖性为未来的探索提供了一个有趣的方向。 whaosoft aiot http://143ai.com
虚拟人体
学习具有NeRF和SDF等隐式神经表示的虚拟人化身需要很长的优化和渲染时间,并且难以生成令人满意的质量新颖的身体姿势。相反,实验证明,利用3D高斯表示可以提高训练和渲染速度,并提供对人体变形的显式控制。此外,3D高斯方法中的forward skinning避免了神经隐式表示中使用的inverse skinning中存在的对应模糊性。
通常,基于3D高斯的方法首先使用SMPL模板初始化高斯,然后使用线性混合蒙皮(LBS)将表示变形到观测空间中。然后通过多视图(图8a)或单目视频(图8b)渲染和监督高斯。此外,一些方法专门用于重建人头头像(图8c),而一些方法则专注于可推广的管道,而不是每个主题的优化。
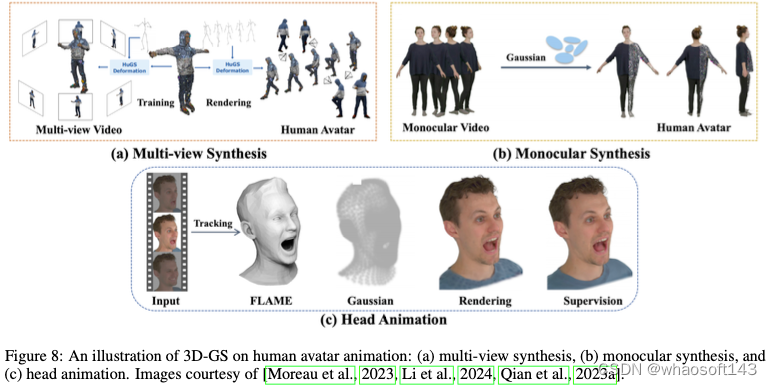
Multi-view Video Synthesis
Moreau提出了一种HuGS,用可动画化的人体从多视图视频中渲染照片逼真的人体化身,该人体用一组3D高斯表示人体。HuGS中的3D高斯在原始设置的基础上添加了一个蒙皮权重向量,该向量调节每个身体关节对高斯运动方式的影响,以及一个对非刚性运动进行编码的潜在代码。HuGS应用LBS来变形由SMPL模型初始化的规范基元,并且仅学习蒙皮权重。由于LBS仅对身体关节的刚性变形进行编码,因此HuGS随后引入了局部非刚性细化阶段,以对服装的非刚性变形进行建模,同时考虑身体姿势编码和环境遮挡。尽管在新的姿态合成上取得了有竞争力的性能,但HuGS独立地优化和变形每个高斯,忽略了局部邻域中高斯之间的内在关系。
Monocular Video Synthesis
同时,Kocabas设计了一个变形模型,仅从单眼视频中用3D高斯表示可动画化的人类和静态场景。在实践中,人体和场景被解开,并从SMPL身体模型中分别构建运动点云的结构。人类高斯通过其在规范空间中的中心位置、一个特征三平面和三个MLP进行参数化,这些MLP预测高斯的特性,并在类似于Moreau的管道中进行进一步优化。
Human Head Animation
GaussianAvatars专注于通过将3D Gaussians装配到参数化可变形人脸模型来重建头部化身。特别是,3D高斯在FLAME网格的每个三角形的中心进行初始化,其参数由三角形属性定义。此外,为了在不破坏三角形和splats之间的连接的情况下适应该方法的自适应密度控制操作,设计了一种绑定继承策略,以使用其父三角形的索引对高斯进行额外的参数化,从而使新的高斯点保持在FLAME网格上。然而,这种方法缺乏对FLAME未建模的区域(如头发和其他配件)的控制。
Generalizable Methods
与大多数依赖于每个受试者优化的方法相反,Zheng提出了一种可推广的3D-GS,在没有任何微调或优化的情况下实时合成看不见的人类表演者的新颖视图。所提出的GPS Gaussian直接从具有不同性质的海量3D人体扫描数据中以前馈的方式回归高斯参数,以学习丰富的人体先验,从而实现即时的人体外观渲染。此外,GPS Gaussion采用高效的2D CNN对源视图图像进行编码,并预测2D高斯参数图。具体地,经由深度估计模块学习的深度图和RGB图像分别用作3D位置图和颜色图,以形成高斯表示,同时以逐像素的方式预测3D高斯的其他参数。稍后,将这些参数贴图取消投影到3D空间,并聚合以进行新颖的视图渲染。
挑战:i)在由SMPL模型和LBS初始化的3D高斯人体中,服装变形没有得到很好的学习。ii)在大多数方法中,环境照明没有参数化,这使得重新照明化身是不可行的。iii)尽管在从单目视频重建人类化身方面已经取得了很大进展,但恢复精细细节仍然是一个棘手的问题,因为从稀疏视图仅提供有限的信息。iv)目前,大多数方法中的3D高斯都是独立优化和变形的,忽略了局部区域高斯之间的内在结构和连通关系。
机会:i)对于人类头部建模,利用3DMM控制运动的方法也无法表达微妙的面部表情。探索一种更有效的方法来单独控制非刚性变形是未来工作的重点。ii)如何从学习的3D高斯中提取网格仍然是未来有待研究的工作。iii)基于3DMM的方法和基于SMPL的方法的重建性能都受到模型参数初始化的约束。固定参数的不准确可能会严重影响模型与监督的一致性,从而导致纹理模糊。注意到3DMM和SMPL未能对人体的松散结构进行建模。在这方面,在优化过程中增强模板模型的表达能力是未来工作的一个有希望的突破。
讨论和未来工作
3D高斯Splatting在计算机图形学和计算机视觉领域显示出巨大的潜力。然而,由于与3D高斯splatting相关的复杂结构和不同任务,各种挑战仍然存在。本节旨在应对这些挑战,并提出未来研究的潜在途径。
处理3D-GS中的浮动元素。3D高斯splatting中的一个显著问题是渲染空间中浮动元素的普遍性,主要来源于图像背景。已经建议使用不透明度阈值来减少这些浮动的发生,从而增强通过PSNR和SSIM度量测量的图像渲染质量。然而,这些浮动元素会显著影响渲染图像的视觉质量。一个潜在的研究领域可以集中在将这些漂浮物锚定在更靠近表面的位置的策略上,从而增强它们的位置相关性和对图像质量的贡献。
渲染和重建之间的权衡。如前所述,浮动元素的存在显著影响图像的视觉质量。但是,它们的影响超出了渲染范围,影响了网格重建过程。SuGaR方法利用基于不透明度的方法在网格表面周围生成3D高斯,这虽然有利于重建,但可能会影响渲染质量。这突出了需要一种细致入微的方法来平衡卓越渲染和准确重建。探索3D-GS如何增强或补充其他先进的多视图重建技术是另一条有前景的研究途径。
渲染真实性。当前的照明分解方法在边界模糊的场景中显示出有限的有效性,通常需要在优化过程中包含对象遮罩。这种限制主要源于背景对优化过程的不利影响,这是通过3D高斯散射生成的点云的独特质量的结果。与传统的曲面点不同,这些点云显示类似粒子的特性,包括颜色和部分透明度,与传统曲面点不同。考虑到这些挑战,将多视图立体(MVS)集成到优化过程中成为一个很有前途的方向。这种集成可以显著提高几何精度,为未来的研究提供了一条有希望的途径。
实时渲染。为了便于实时渲染,Scaffold GS引入了来自稀疏体素网格的锚点,这有助于分布局部3D高斯,从而提高渲染速度。然而,该方法对统一网格大小的依赖限制了其适应性。八叉树表示的使用是一种很有前途的替代方法,它可以灵活地将更复杂的区域划分为更小的网格进行详细处理。虽然这些方法显示出在小场景中实现实时渲染的潜力,但要扩展到大环境(如城市景观),还需要进一步的创新和额外的努力。
Few-shot的3D-GS。最近的一些few-shot研究探索了在一些few-shot设置中使用深度引导优化高斯飞溅。虽然这些方法很有希望,但也面临着显著的挑战。few-shot方法的成功在很大程度上取决于单目深度估计模型的准确性。此外,它们的性能可能因不同的数据域而异,从而影响3D-GS的优化过程。此外,对将估计深度拟合到COLMAP点的依赖性引入了对COLMAP本身性能的依赖。因此,这些限制在处理COLMAP可能遇到困难的无纹理区域或复杂表面方面带来了挑战。对于未来的研究,使用相互依存的深度估计来研究3D场景的优化将是有益的,从而减少对COLMAP点的依赖。未来工作的另一个途径是研究在不同数据集中正则化几何体的方法,特别是在深度估计(如天空)面临挑战的领域。
物理学的融合。与材料的物理行为和视觉外观本质上相互关联的自然世界不同,传统的基于物理的视觉内容生成管道是一个费力且多阶段的过程。这个过程包括构建几何体,为模拟做准备(通常使用四面体化等技术),模拟物理,并最终渲染场景。尽管该序列是有效的,但它引入了中间阶段,这可能会导致模拟和最终可视化之间的差异。这种差异在NeRF范式中也很明显,其中渲染几何体嵌入模拟几何体中。为了解决这个问题,建议将这两个方面结合起来,提倡对可用于模拟和渲染目的的物质进行统一表示。此外,一个很有前途的方向是将材料自动分配给3D-GS。
精确重建。原始3D-GS无法区分镜面反射区域和非镜面反射区域。因此,3D-GS会在镜面反射部分产生不合理的三维高斯。非理性三维高斯的存在会显著影响重建过程,导致产生有缺陷的网格。此外,已经观察到,包括镜面反射分量也会导致产生不可靠的网格。因此,为了实现精确的重建,在精确重建网格之前,必须通过照明分解3D高斯。
真实生成。由DreamGaussianDreamer开创的3D-GS开始了其3D生成之旅。但是,生成的三维资产的几何图形和纹理仍需要改进。在几何图形方面,将更精确的SDF和UDF集成到3D-GS中,可以生成更逼真、更准确的网格。此外,可以有效地利用各种传统的图形技术,例如Medial Fields。关于纹理,最近提出的两种方法,MVD和TexFusion,在纹理生成方面表现出了令人印象深刻的能力。这些进步有可能应用于3D-GS纹理网格生成。此外,Relightable3DGaussianShader和GaussianShadowr已经探索了3D-GS的着色方面。然而,在生成的网格上进行BRDF分解的问题仍然没有答案。
使用大型基础模型扩展3D-GS。施等最近的研究表明,将语言嵌入3D-GS可以显著增强对3D场景的理解。随着2023年大型基础模型的出现,它们的非凡能力在广泛的视觉任务中得到了展示。值得注意的是,SAM模型已成为一种强大的分割工具,并在3D-GS中成功应用。除了分割,LLM模型还有望用于语言引导的生成、操作和感知任务。这突出了这些模型在广泛应用中的多功能性和实用性,进一步强调了它们在3D-GS中的重要性。值得注意的是,SAM模型已成为一种强大的分割工具,在3D-GS中获得了成功的应用。除了分割,LLM模型还有望用于语言引导的生成、操作和感知任务。这突出了这些模型在广泛应用中的多功能性和实用性,进一步强调了它们在3D-GS中的重要性。
训练3D-GS用于其他方法。一些工作使用3D-GS作为辅助工具来提高性能。例如,NeuSG利用3D-GS来增强NeuS的重建,而SpecNerf结合了高斯方向编码来对镜面反射进行建模。因此,3D-GS的独特特性可以无缝集成到现有方法中,以进一步提高其性能。可以想象,3D-GS可以与大型重建模型(LRM)相结合,或者与自动驾驶汽车领域现有的感知技术相结合,以增强其感知能力。
#端到端自动驾驶的基石是什么
基础模型的出现彻底改变了自然语言处理和计算机视觉领域,为其在自动驾驶(AD)中的应用铺平了道路。这项调查对40多篇研究论文进行了全面回顾,展示了基础模型在增强AD中的作用。大型语言模型有助于AD的规划和模拟,特别是通过其在推理、代码生成和翻译方面的熟练程度。与此同时,视觉基础模型越来越适用于关键任务,如3D目标检测和跟踪,以及为仿真和测试创建逼真的驾驶场景。多模态基础模型,集成了不同的输入,显示了非凡的视觉理解和空间推理,对端到端AD至关重要。这项调查不仅提供了一个结构化的分类法,根据基础模型在AD领域的模式和功能对其进行分类,还深入研究了当前研究中使用的方法。它确定了现有基础模型和尖端AD方法之间的差距,从而规划了未来的研究方向,并提出了弥合这些差距的路线图。
简介
深度学习(DL)与自动驾驶(AD)的融合标志着该领域的重大飞跃,吸引了学术界和工业界的关注。配备了摄像头和激光雷达的AD系统模拟了类似人类的决策过程。这些系统基本上由三个关键组成部分组成:感知、预测和规划。Perception利用DL和计算机视觉算法,专注于物体检测和跟踪。预测预测交通代理的行为及其与自动驾驶汽车的相互作用。规划通常是分层结构的,包括做出战略性驾驶决策、计算最佳轨迹和执行车辆控制命令。基础模型的出现,特别是在自然语言处理和计算机视觉领域,为AD研究引入了新的维度。这些模型是不同的,因为它们在广泛的网络规模数据集上进行训练,并且参数大小巨大。考虑到自动驾驶汽车服务产生的大量数据和人工智能的进步,包括NLP和人工智能生成内容(AIGC),人们对基础模型在AD中的潜力越来越好奇。这些模型可能有助于执行一系列AD任务,如物体检测、场景理解和决策,具有与人类驾驶员相似的智力水平。
基础模型解决了AD中的几个挑战。传统上,AD模型是以监督的方式训练的,依赖于手动注释的数据,这些数据往往缺乏多样性,限制了它们的适应性。然而,基础模型由于在不同的网络规模数据上进行训练,显示出卓越的泛化能力。它们可以用从广泛的预训练中获得的推理能力和知识,潜在地取代规划中复杂的启发式基于规则的系统。例如,LLM具有从预训练数据集中获得的推理能力和常识性驾驶知识,这可能会取代启发式基于规则的规划系统,后者需要在软件代码中手工制定规则并在角落案例中进行调试的复杂工程工作。该领域中的生成模型可以为模拟创建真实的交通场景,这对于在罕见或具有挑战性的情况下测试安全性和可靠性至关重要。此外,基础模型有助于使AD技术更加以用户为中心,语言模型可以用自然语言理解和执行用户命令。
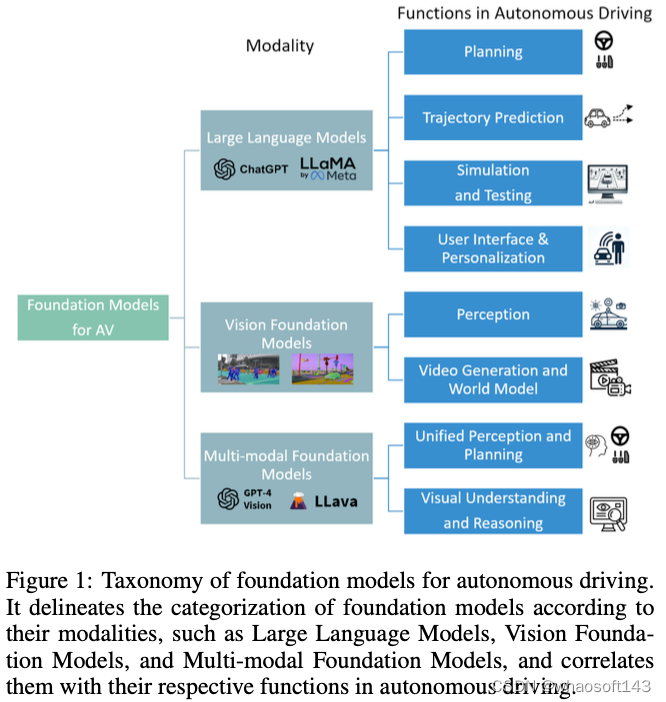
尽管在将基础模型应用于AD方面进行了大量研究,但在实际应用中仍存在显著的局限性和差距。我们的调查旨在提供一个系统的重新审视,并提出未来的研究方向。LLM4Drive更侧重于大型语言模型。我们在现有调查的基础上,涵盖了视觉基础模型和多模态基础模型,分析了它们在预测和感知任务中的应用。这种综合方法包括对技术方面的详细检查,如预先训练的模型和方法,并确定未来的研究机会。创新性地,我们提出了一种基于模式和功能对AD中的基础模型进行分类的分类法,如图1所示。以下部分将探讨各种基础模型在AD环境中的应用,包括大型语言模型、视觉基础模型和多模态基础模型。
Large Language Models in AD
概述
LLM最初在NLP中具有变革性,现在正在推动AD的创新。BERT开创了NLP中的基础模型,利用转换器架构来理解语言语义。这种预先训练的模型可以在特定的数据集上进行微调,并在广泛的任务中实现最先进的结果。在此之后,OpenAI的生成预训练转换器(GPT)系列,包括GPT-4,由于在广泛的数据集上进行了训练,展示了非凡的NLP能力。后来的GPT模型,包括ChatGPT、GPT-4,使用数十亿个参数和数万亿个单词的爬行网络数据进行训练,并在许多NLP任务上取得了强大的性能,包括翻译、文本摘要、问题回答。它还展示了从上下文中学习新技能的一次性和少量推理能力。越来越多的研究人员已经开始应用这些推理、理解和上下文学习能力来应对AD中的挑战。
AD中的应用
推理与规划
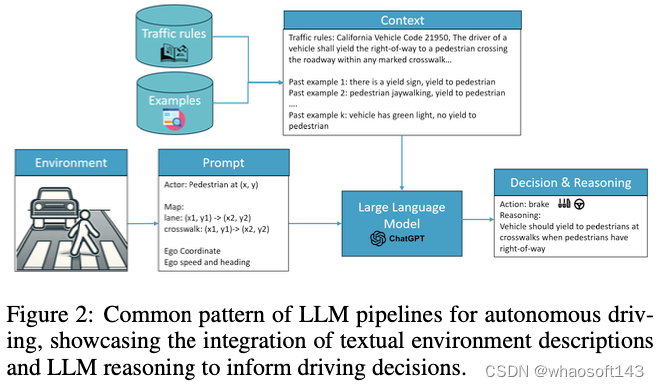
AD的决策过程与人类推理密切相似,因此必须对环境线索进行解释,才能做出安全舒适的驾驶决策。LLM通过对各种网络数据的培训,吸收了与驾驶相关的常识性知识,这些知识来自包括网络论坛和政府官方网站在内的众多来源。这些丰富的信息使LLM能够参与AD所需的细微决策。在AD中利用LLM的一种方法是向他们提供驾驶环境的详细文本描述,促使他们提出驾驶决策或控制命令。如图2所示,这个过程通常包括全面的提示,详细说明代理状态,如坐标、速度和过去的轨迹,车辆的状态,即速度和加速度,以及地图细节,包括红绿灯、车道信息和预定路线)。为了增强对交互的理解,LLM还可以被引导在其响应的同时提供推理。例如,GPT驾驶员不仅建议车辆行动,还阐明了这些建议背后的理由,大大提高了自动驾驶决策的透明度和可解释性。这种方法,以LLM驾驶为例,增强了自动驾驶决策的可解释性。同样,“接收、推理和反应”方法指示LLM代理人评估车道占用情况并评估潜在行动的安全性,从而促进对动态驾驶场景的更深入理解。这些方法不仅利用LLM理解复杂场景的固有能力,还利用它们的推理能力来模拟类似人类的决策过程。通过整合详细的环境描述和战略提示,LLM对AD的规划和推理方面做出了重大贡献,提供了反映人类判断和专业知识的见解和决策。
预测
Prediction预测交通参与者未来的轨迹、意图以及可能与自车交通工具的互动。常见的基于深度学习的模型基于交通场景的光栅化或矢量图像,对空间信息进行编码。然而,准确预测高度互动的场景仍然具有挑战性,这需要推理和语义信息,例如路权、车辆的转向信号和行人的手势。场景的文本表示可以提供更多的语义信息,并更好地利用LLM的推理能力和预训练数据集中的公共知识。将LLM应用于轨迹预测的研究还不多。与仅使用图像编码或文本编码的基线相比,他们的评估显示出显著的改进。
用户界面和个性化
自动驾驶汽车应便于用户使用,并能够遵循乘客或远程操作员的指示。当前的Robotaxi远程辅助界面仅用于执行一组有限的预定义命令。然而,LLM的理解和交互能力使自动驾驶汽车能够理解人类的自由形式指令,从而更好地控制自动驾驶汽车,满足用户的个性化需求。LLM代理还能够基于预定义的业务规则和系统要求来接受或拒绝用户命令。
仿真和测试
LLM可以从现有的文本数据中总结和提取知识,并生成新的内容,这有助于仿真和测试。ADEPT系统使用GPT使用QA方法从NHTSA事故报告中提取关键信息,并能够生成用于模拟和测试的各种场景代码。TARGET系统能够使用GPT将流量规则从自然语言转换为特定领域的语言,用于生成测试场景。LCTGen使用LLM作为强大的解释器,将用户的文本查询转换为交通模拟场景中地图车道和车辆位置的结构化规范。
方法和技巧
研究人员在自然语言处理中使用类似的技术,将LLM用于自动驾驶任务,如即时工程、上下文和少镜头学习,以及来自人类反馈的强化学习。
Prompt Engineering
Prompt engineering采用复杂的输入提示和问题设计来指导大型语言模型生成我们想要的答案。
一些论文增加了交通规则作为前置提示,以使LLM代理符合法律。Driving with LLMs有交通规则,涵盖红绿灯过渡和左侧或右侧驾驶等方面。
LanguageMPC采用自上而下的决策系统:给定不同的情况,车辆有不同的可能动作。LLM代理还被指示识别场景中的重要代理,并输出注意力、权重和偏差矩阵,以从预先定义的动作中进行选择。
Fine-tuning v.s. In-context Learning
微调和上下文学习都用于使预先训练的模型适应自动驾驶。微调在较小的特定领域数据集上重新训练模型参数,而上下文学习或少镜头学习利用LLM的知识和推理能力,在输入提示中从给定的例子中学习。大多数论文都专注于上下文学习,但只有少数论文使用微调。研究人员对哪一个更好的结果喜忧参半:GPT-Driver有一个不同的结论,即使用OpenAI微调比少镜头学习表现得更好。
强化学习和人类反馈
DILU提出了反射模块,通过人工校正来存储好的驾驶示例和坏的驾驶示例,以进一步增强其推理能力。通过这种方式,LLM可以学会思考什么行动是安全的和不安全的,并不断反思过去的大量驾驶经验。Surreal Driver采访了24名驾驶员,并将他们对驾驶行为的描述作为思维链提示,开发了一个“教练-代理”模块,该模块可以指导LLM模型具有类似人类的驾驶风格。
限制和未来方向
幻觉与危害
幻觉是LLM中的一大挑战,最先进的大型语言模型仍然会产生误导和虚假信息。现有论文中提出的大多数方法仍然需要从LLM的响应中解析驱动动作。当给定一个看不见的场景时,LLM模型仍然可能产生无益或错误的驾驶决策。自动驾驶是一种安全关键应用程序,其可靠性和安全性要求远高于聊天机器人。根据评估结果,用于自动驾驶的LLM模型的碰撞率为0.44%,高于其他方法。经过预先培训的LLM也可能包括有害内容,例如,激烈驾驶和超速行驶。更多的人在环训练和调整可以减少幻觉和有害的驾驶决策。
耗时和效率
大型语言模型通常存在高延迟,生成详细的驾驶决策可能会耗尽车内有限计算资源的延迟预算。推理需要几秒钟的时间。具有数十亿个参数的LLM可能会消耗超过100GB的内存,这可能会干扰自动驾驶汽车中的其他关键模块。在这一领域还需要做更多的研究,如模型压缩和知识提取,以使LLM更高效、更容易部署。
对感知系统的依赖
尽管LLM具有最高的推理能力,但环境描述仍然依赖于上游感知模块。驾驶决策可能会出错,并在环境输入中出现轻微错误,从而导致重大事故。LLM还需要更好地适应感知模型,并在出现错误和不确定性时做出更好的决策。
Sim to Real Gap
大多数研究都是在仿真环境中进行的,驾驶场景比真实世界的环境简单得多。为了覆盖现实世界中的所有场景,需要进行大量的工程和人类详细的注释工作,例如,该模型知道如何向人类屈服,但可能不擅长处理与小动物的互动。
视觉基础模型
视觉基础模型在多个计算机视觉任务中取得了巨大成功,如物体检测和分割。DINO使用ViT架构,并以自监督的方式进行训练,在给定局部图像块的情况下预测全局图像特征。DINOV2利用10亿个参数和12亿幅图像的多样化数据集对训练进行了扩展,并在多任务中取得了最先进的结果。Segment-anything模型是图像分割的基础模型。该模型使用不同类型的提示(点、框或文本)进行训练,以生成分割掩码。在数据集中使用数十亿分割掩码进行训练后,该模型显示了零样本传递能力,可以在适当的提示下分割新目标。
扩散模型是一种广泛应用于图像生成的生成基础模型。扩散模型迭代地将噪声添加到图像,并应用反向扩散过程来恢复图像。为了生成图像,我们可以从学习的分布中进行采样,并从随机噪声中恢复高度逼真的图像。稳定扩散模型使用VAE将图像编码为潜在表示,并使用UNet将潜在变量解码为逐像素图像。它还有一个可选的文本编码器,并应用交叉注意力机制生成基于提示的图像(文本描述或其他图像)。DALL-E模型使用数十亿对图像和文本进行训练,并使用稳定的扩散来生成高保真图像和遵循人类指令的创造性艺术。
人们对视觉基础模型在自动驾驶中的应用越来越感兴趣,主要用于3D感知和视频生成任务。
感知
SAM3D将SAM应用于自动驾驶中的3D物体检测。激光雷达点云被投影到BEV(鸟瞰图)图像中,它使用32x32网格生成点提示,以检测前景目标的遮罩。它利用SAM模型的零样本传输能力来生成分割掩模和2D盒。然后,它使用2D box内的激光雷达点的垂直属性来生成3D box。然而,Waymo开放数据集评估显示,平均精度指标与现有最先进的3D目标检测模型仍有很大差距。他们观察到,SAM训练的基础模型不能很好地处理那些稀疏和有噪声的点,并且经常导致对远处物体的假阴性。
SAM应用于3D分割任务的领域自适应,利用SAM模型的特征空间,该特征空间包含更多的语义信息和泛化能力。
SAM和Grounding DINO用于创建一个统一的分割和跟踪框架,利用视频帧之间的时间一致性。Grounding DINO是一个开放集目标检测器,它从目标的文本描述中获取输入并输出相应的边界框。给定与自动驾驶相关的目标类的文本提示,它可以检测视频帧中的目标,并生成车辆和行人的边界框。SAM模型进一步将这些框作为提示,并为检测到的目标生成分割掩码。然后将生成的目标掩码传递给下游跟踪器,后者比较连续帧中的掩码,以确定是否存在新目标。
视频生成和世界模型
基础模型,特别是生成模型和世界模型可以生成逼真的虚拟驾驶场景,用于自动驾驶仿真。许多研究人员已经开始将扩散模型应用于真实场景生成的自动驾驶。视频生成问题通常被公式化为一个世界模型:给定当前世界状态,以环境输入为条件,该模型预测下一个世界状态,并使用扩散来解码高度逼真的驾驶场景。
GAIA-1由Wayve开发,用于生成逼真的驾驶视频。世界模型使用相机图像、文本描述和车辆控制信号作为输入标记,并预测下一帧。本文利用预训练的DINO模型的嵌入和余弦相似性损失提取更多的语义知识用于图像标记嵌入。他们使用视频扩散模型从预测的图像标记中解码高保真驾驶场景。有两个单独的任务来训练扩散模型:图像生成和视频生成。图像生成任务帮助解码器生成高质量的图像,而视频生成任务使用时间注意力来生成时间一致的视频帧。生成的视频遵循高级真实世界约束,并具有逼真的场景动力学,例如目标的位置、交互、交通规则和道路结构。视频还展示了多样性和创造力,这些都有现实的可能结果,取决于不同的文本描述和自我载体的行动。
DriveDreamer还使用世界模型和扩散模型为自动驾驶生成视频。除了图像、文本描述和车辆动作,该模型还使用了更多的结构性交通信息作为输入,如HDMap和目标3D框,使模型能够更好地理解交通场景的更高层结构约束。模型训练分为两个阶段:第一阶段是使用基于结构化交通信息的扩散模型生成视频。
限制和未来方向
目前最先进的基础模型(如SAM)对于3D自动驾驶感知任务(如物体检测和分割)没有足够好的零样本泛化能力。自动驾驶感知依赖于多个摄像头、激光雷达和传感器融合来获得最高精度的物体检测结果,这与从网络上随机收集的图像数据集大不相同。当前用于自动驾驶感知任务的公共数据集的规模仍然不足以训练基础模型并覆盖所有可能的长尾场景。尽管存在局限性,现有的2D视觉基础模型可以作为有用的特征提取器进行知识提取,这有助于模型更好地结合语义信息。在视频生成和预测任务领域,我们已经看到了利用现有扩散模型进行视频生成和点云预测的有希望的进展,这可以进一步应用于创建自动驾驶模拟和测试的高保真场景。
多模态基础模型
多模态基础模型通过从多种模态(如声音、图像和视频)获取输入数据来执行更复杂的任务,例如从图像生成文本、使用视觉输入进行分析和推理,从而受益更多。
最著名的多模态基础模型之一是CLIP。使用对比预训练方法对模型进行预训练。输入是有噪声的图像和文本对,并且训练模型来预测给定的图像和文字是否是正确的对。训练该模型以最大化来自图像编码器和文本编码器的嵌入的余弦相似性。CLIP模型显示了其他计算机视觉任务的零样本转移能力,如图像分类,以及在没有监督训练的情况下预测类的正确文本描述。
LLaVA、LISA和CogVLM等多模态基础模型可用于通用视觉人工智能代理,它在视觉任务中表现出优异的性能,如目标分割、检测、定位和空间推理。
将通用知识从大规模预训练数据集转移到自动驾驶中,多模态基础模型可用于目标检测、视觉理解和空间推理,从而在自动驾驶中实现更强大的应用。
视觉理解和推理
传统的物体检测或分类模型对于自动驾驶来说是不够的,因为我们需要更好地理解场景的语义和视觉推理,例如识别危险物体,了解交通参与者的意图。现有的基于深度学习的预测和规划模型大多是暗箱模型,当事故或不适事件发生时,这些模型的可解释性和可调试性较差。在多模态基础模型的帮助下,我们可以生成模型的解释和推理过程,以更好地研究问题。
Talk2BEV提出了一种融合视觉和语义信息的场景创新鸟瞰图(BEV)表示。该管道首先从图像和激光雷达数据中生成BEV地图,并使用通用视觉语言基础模型添加对物体裁剪图像的更详细的文本描述。然后,BEV映射的JSON文本表示被传递给通用LLM,以执行Visual QA,其中包括空间和视觉推理任务。结果表明,它很好地理解了详细的实例属性和目标的更高层次意图,并能够就自我载体的行为提供自由形成的建议。
统一感知和规划
Wen对GPT-4Vision在感知和规划任务中的应用进行了早期探索,并评估了其在几个场景中的能力。它表明GPT-4Vision可以了解天气、交通标志和红绿灯,并识别场景中的交通参与者。它还可以提供这些目标的更详细的语义描述,如车辆尾灯、U型转弯等意图和详细的车辆类型(如水泥搅拌车、拖车和SUV)。它还显示了基础模型理解点云数据的潜力,GPT-4V可以从BEV图像中投影的点云轮廓识别车辆。他们还评估了模型在规划任务中的性能。考虑到交通场景,GPT4-V被要求描述其对车辆行动的观察和决定。结果显示,与其他交通参与者的互动良好,遵守了交通规则和常识,例如在安全距离内跟车,在人行横道上向骑自行车的人让行,在绿灯变绿之前保持停车。它甚至可以很好地处理一些长尾场景,比如门控停车场。
限制和未来方向
多模态基础模型显示了自动驾驶任务所需的空间和视觉推理能力。与传统的目标检测相比,在闭集数据集上训练的分类模型、视觉推理能力和自由形式的文本描述可以提供更丰富的语义信息,可以解决许多长尾检测问题,如特种车辆的分类、警察和交通管制员对手势的理解。多模态基础模型具有良好的泛化能力,可以很好地利用常识处理一些具有挑战性的长尾场景,例如在受控访问的门口停车。进一步利用其规划任务的推理能力,视觉语言模型可用于统一感知规划和端到端自动驾驶。
多基础模型在自动驾驶中仍然存在局限性。GPT-4V模型仍然存在幻觉,并在几个例子中产生不清楚的反应或错误的答案。该模型还显示出在利用多视图相机和激光雷达数据进行精确的3D物体检测和定位方面的无能,因为预训练数据集只包含来自网络的2D图像。需要更多特定领域的微调或预训练来训练多模态基础模型,以更好地理解点云数据和传感器融合,从而实现最先进的感知系统的可比性能。
结论和未来方向
我们对最近将基础模型应用于自动驾驶的论文进行了总结和分类。我们基于自动驾驶中的模态和功能建立了一个新的分类法。我们详细讨论了使基础模型适应自动驾驶的方法和技术,例如上下文学习、微调、强化学习和视觉教学调整。我们还分析了自动驾驶基础模型的局限性,如幻觉、延迟和效率,以及数据集中的领域差距,从而提出了以下研究方向:
-
在自动驾驶数据集上进行特定领域的预训练或微调;
-
强化学习和人在环对齐,以提高安全性并减少幻觉;
-
2D基础模型对3D的适应,例如语言引导的传感器融合、微调或3D数据集上的few-shot学习;
-
用于将基础模型部署到车辆的延迟和内存优化、模型压缩和知识提取。
我们还注意到,数据集是自动驾驶基础模型未来发展的最大障碍之一。现有的1000小时规模的自动驾驶开源数据集远远少于最先进的LLM所使用的预训练数据集。用于现有基础模型的网络数据集并没有利用自动驾驶所需的所有模式,如激光雷达和环视摄像头。网络数据域也与真实的驾驶场景大不相同。 whaosoft aiot http://143ai.com
我们在图5中提出了长期的未来路线图。在第一阶段,我们可以收集一个大规模的2D数据集,该数据集可以覆盖真实世界环境中驾驶场景的所有数据分布、多样性和复杂性,用于预训练或微调。大多数车辆都可以配备前置摄像头,在一天中的不同时间收集不同城市的数据。在第二阶段,我们可以使用激光雷达使用更小但质量更高的3D数据集来改善基础模型的3D感知和推理,例如,我们可以作为教师使用现有最先进的3D目标检测模型来微调基础模型。最后,我们可以在规划和推理中利用人类驾驶示例或注释来进行对齐,从而达到自动驾驶的最大安全目标。
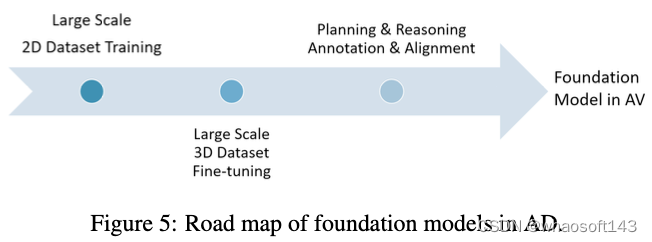
#鱼眼相机与超声波传感器融合实现鸟瞰近场障碍物感知
-
论文链接:https://browse.arxiv.org/pdf/2402.00637.pdf
-
视频链接:https://youtu.be/JmSLBBL9Ruo
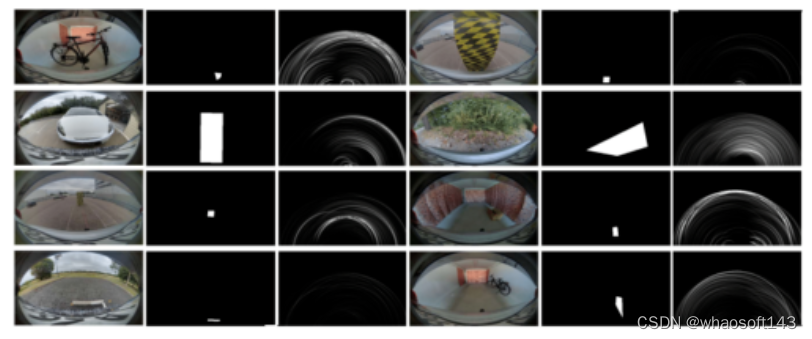
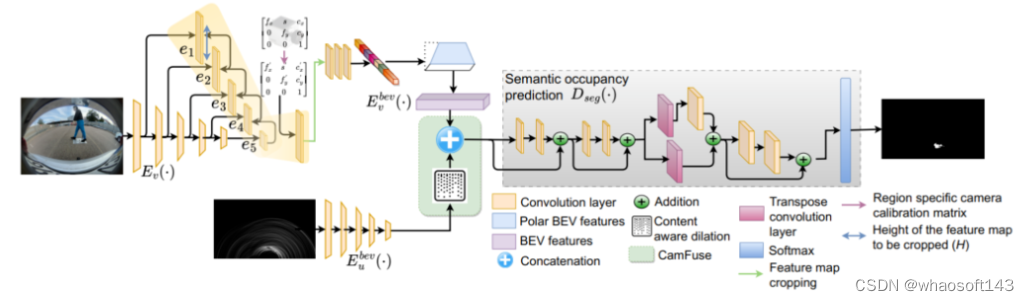
本文介绍了鱼眼相机与超声传感器融合实现鸟瞰图中近场障碍物感知。准确的障碍物识别是自动驾驶近场感知范围内的一项基本挑战。传统上,鱼眼相机经常用于全面的环视感知,包括后视障碍物定位。然而,这类相机的性能在弱光照条件、夜间或者受到强烈阳光照射时会显著下降。相反,像超声传感器这类成本较低的传感器在这些条件下基本不受影响。因此,本文提出了首个端到端的多模态融合模型,其利用鱼眼相机和超声传感器在鸟瞰图(BEV)中实现高效的障碍物感知。最初,采用ResNeXt-50作为一组单模态编码器,以提取每个模态特有的特征。随后,与可见光谱相关联的特征空间被转换为BEV。这两种模态的融合是通过级联来实现的。同时,基于超声频谱的单模态特征图通过内容感知的空洞卷积,用于缓解融合特征空间中两种传感器之间的传感器错误对齐。最后,融合的特征被两阶段语义占用编码器用来生成用于精确障碍物感知的逐网格预测。本文进行了系统性研究,以确定两种传感器多模态融合的最优策略。本文深入展示了数据集创建过程、标注指南,并且进行全面的数据分析,以确保充分覆盖所有场景。当应用于本文数据集时,结果证明了本文所提出的多模态融合方法的鲁棒性和有效性。
本文主要贡献
1)引入了一种新型的多传感器深度网络,其专门为鸟瞰图中的近场障碍物感知而设计。本文所提出的网络结合了鱼眼相机和超声传感器系统,这是首次朝着该方向努力;
2)建立了构建包括鱼眼相机和超声传感器数据的多传感器数据集的策略。本文定义了标注规则,并且提供了相关的数据统计,这对于构建适用于类似应用的多模态模型是至关重要的;
3)本文描述了一个实现非常高精度的端到端可训练网络的实现过程。此外,本文还提出了对proposal进行重构,以支持具有单模态输入的相同特征,从而对基于多模态解决方案的优势进行深入分析;
4)本文进行了全面的消融研究,涉及各种提出的网络组件、不同的特征融合技术、不同的增强方法和各种损失函数。

#自动驾驶与轨迹预测
轨迹预测在自动驾驶中承担着重要的角色,自动驾驶轨迹预测是指通过分析车辆行驶过程中的各种数据,预测车辆未来的行驶轨迹。作为自动驾驶的核心模块,轨迹预测的质量对于下游的规划控制至关重要。轨迹预测任务技术栈丰富,需要熟悉自动驾驶动/静态感知、高精地图、车道线、神经网络架构(CNN&GNN&Transformer)技能等,入门难度很大!
入门相关知识
1.预习的论文有没有切入顺序?
A:先看survey,problem formulation, deep learning-based methods里的sequential network,graph neural network和Evaluation。
2.行为预测是轨迹预测吗
A:是耦合的,但不一样。行为一般指目标车未来会采取什么动作,变道停车超车加速左右转直行等等。轨迹的话就是具体的具有时间信息的未来可能的位置点
3.请问Argoverse数据集里提到的数据组成中,labels and targets指的是什么呢?labels是指要预测时间段内的ground truth吗
A:我猜这里想说的是右边表格里的OBJECT_TYPE那一列。AV代表自动驾驶车自己,然后数据集往往会给每个场景指定一个或多个待预测的障碍物,一般会叫这些待预测的目标为target或者focal agent。某些数据集还会给出每个障碍物的语义标签,比如是车辆、行人还是自行车等。
Q2:车辆和行人的数据形式是一样的吗?我的意思是说,比如一个点云点代表行人,几十个点代表车辆?
A:这种轨迹数据集里面其实给的都是物体中心点的xyz坐标,行人和车辆都是
Q3:argo1和argo2的数据集都是只指定了一个被预测的障碍物吧?那在做multi-agent prediction的时候 这两个数据集是怎么用的
A:argo1是只指定了一个,argo2其实指定了多个,最多可能有二十来个的样子。但是只指定一个并不妨碍你自己的模型预测多个障碍物。
4.路径规划一般考虑低速和静态障碍物 轨迹预测结合的作用是??关键snapshot?
A:”预测“自车轨迹当成自车规划轨迹,可以参考uniad
5.轨迹预测对于车辆动力学模型的要求高吗?就是需要数学和汽车理论等来建立一个精准的车辆动力学模型么?
A:nn网络基本不需要哈,rule based的需要懂一些
6. 模模糊糊的新手小白,应该从哪里在着手拓宽一下知识面(还不会代码撰写)
A:先看综述,把思维导图整理出来,例如《Machine Learning for Autonomous Vehicle's Trajectory Prediction: A comprehensive survey, Challenges, and Future Research Directions》这篇综述去看看英文原文
7.预测和决策啥关系捏,为啥我觉得好像预测没那么重要?
A1(stu): 默认预测属于感知吧,或者决策中隐含预测,反正没有预测不行。
A2(stu): 决策该规控做,有行为规划,高级一点的就是做交互和博弈,有的公司会有单独的交互博弈组
8.目前头部公司,一般预测是属于感知大模块还是规控大模块?
A:预测是出他车轨迹,规控是出自车轨迹,这俩轨迹还互相影响,所以预测一般放规控。
Q: 一些公开的资料,比如小鹏的感知xnet会同时出预测轨迹,这时候又感觉预测的工作是放在感知大模块下,还是说两个模块都有自己的预测模块,目标不一样?
A:是会相互影响,所以有的地方预测和决策就是一个组。比如自车规划的轨迹意图去挤别的车,他车一般情况是会让道的。所以有些工作会把自车的规划当成他车模型输入的一部分。可以参考下M2I(M2I: From Factored Marginal Trajectory Prediction to Interactive Prediction). 这篇思路差不多,可以了解 PiP: Planning-informed Trajectory Prediction for Autonomous Driving
9.argoverse的这种车道中线地图,在路口里面没有车道线的地方是怎么得到的呀?
A: 人工标注的
10.用轨迹预测写论文的话,哪篇论文的代码可以做baseline?
A: hivt可以做baseline,蛮多人用的
11.现在轨迹预测基本都依赖地图,如果换一个新的地图环境,原模型是否就不适用了,要重新训练吗?
A: 有一定的泛化能力,不需要重新训练效果也还行
12.对多模态输出而言,选择最佳轨迹的时候是根据概率值最大的选吗
A(stu): 选择结果最好的
Q2:结果最好是根据什么来判定呢?是根据概率值大小还是根据和gt的距离
A: 实际在没有ground truth的情况下,你要取“最好”的轨迹,那只能选择相信预测概率值最大的那条轨迹了
Q3: 那有gt的情况下,选择最好轨迹的时候,根据和gt之间的end point或者average都可以是吗
A: 嗯嗯,看指标咋定义
轨迹预测基础模块
1.Argoverse数据集里HD-Map怎么用,能结合motion forecast作为输入,构建驾驶场景图吗,异构图又怎么理解?
A:这个课程里都有讲的,可以参照第二章,后续的第四章也会讲. 异构图和同构图的区别:同构图中,node的种类只有一种,一个node和另一个node的连接关系只有一种,例如在社交网络中,可以想象node只有‘人’这一个种类,edge只有‘认识’这一种连接。而人和人要么认识,要么不认识。但是也可能细分有人,点赞,推文。则人和人可能通过认识连接,人和推文可能通过点赞连接,人和人也可能通过点赞同一篇推文连接(meta path)。这里节点、节点之间关系的多样性表达就需要引入异构图了。异构图中,有很多种node。node之间也有很多种连接关系(edge),这些连接关系的组合则种类更多(meta-path), 而这些node之间的关系有轻重之分,不同连接关系也有轻重之分。
2.A-A交互考虑的是哪些车辆与被预测车辆的交互呢?
A:可以选择一定半径范围内的车,也可以考虑K近邻的车,你甚至可以自己提出更高级的启发式邻居筛选策略,甚至有可能可以让模型自己学出来两个车是否是邻居
Q2:还是考虑一定范围内的吧,那半径大小有什么选取的原则吗?另外,选取的这些车辆是在哪个时间步下的呢
A:半径的选择很难有标准答案,这本质上就是在问模型做预测的时候到底需要多远程的信息,有点像在选择卷积核的大小对于第二个问题,我个人的准则是,想要建模哪个时刻下物体之间的交互,就根据哪个时刻下的物体相对位置来选取邻居
Q3:这样的话对于历史时域都要建模吗?不同时间步下在一定范围内的周边车辆也会变化吧,还是说只考虑在当前时刻的周边车辆信息
A:都行啊,看你模型怎么设计
3.老师uniad端到端模型中预测部分存在什么缺陷啊?
A:只看它motion former的操作比较常规,你在很多论文里都会看到类似的SA和CA。现在sota的模型很多都比较重,比如decoder会有循环的refine
A2:做的是marginal prediction不是joint prediction;2. prediction和planning是分开来做的,没有显式考虑ego和周围agent的交互博弈;3.用的是scene-centric representation,没有考虑对称性,效果必拉
Q2:啥是marginal prediction啊
A:具体可以参考scene transformer
Q3:关于第三点,scene centric没有考虑对称性,怎么理解呢
A:建议看HiVT, QCNet, MTR++.当然对于端到端模型来说对称性的设计也不好做就是了
A2:可以理解成输入的是scene的数据,但在网络里会建模成以每个目标为中心视角去看它周边的scene,这样你就在forward里得到了每个目标以它自己为中心的编码,后续可以再考虑这些编码间的交互
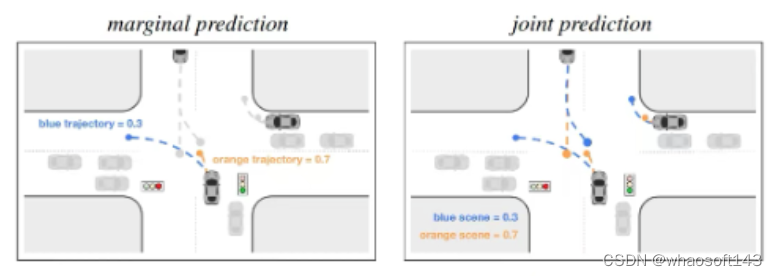
4. 什么是以agent为中心?
A:每个agent有自己的local region,local region是以这个agent为中心
5.轨迹预测里yaw和heading是混用的吗
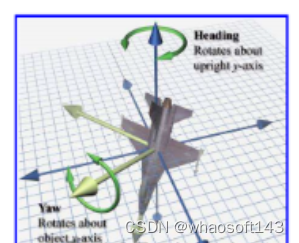
A:可以理解为车头朝向
6.argoverse地图中的has_traffic_control这个属性具体代表什么意思?
A:其实我也不知道我理解的对不对,我猜是指某个lane是否被红绿灯/stop sign/限速标志等所影响
7. 请问Laplace loss和huber loss 对于轨迹预测而言所存在的优劣势在哪里呢?如果我只预测一条车道线的话
A:两个都试一下,哪个效果好哪个就有优势。Laplace loss要效果好还是有些细节要注意的
Q2:是指参数要调的好吗
A:Laplace loss相比L1 loss其实就是多预测了一个scale参数
Q3:对的 但似乎这个我不知道有啥用 如果只预测一个轨迹的话。感觉像是多余的。我把它理解为不确定性 不知道是否正确
A:如果你从零推导过最小二乘法就会知道,MSE其实是假设了方差为常数的高斯分布的NLL。同理,L1 loss也是假设了方差为常数的Laplace分布的NLL。所以说LaplaceNLL也可以理解为方差非定值的L1 loss。这个方差是模型自己预测出来的。为了使loss更低,模型会给那些拟合得不太好的样本一个比较大的方差,而给拟合得好的样本比较小的方差
Q4:那是不是可以理解为对于非常随机的数据集【轨迹数据存在缺帧 抖动】 就不太适合Laplace 因为模型需要去拟合这个方差?需要数据集质量比较高
A:这个说法我觉得不一定成立。从效果上来看,会鼓励模型优先学习比较容易拟合的样本,再去学习难学习的样本
Q5:还想请问下这句话(Laplace loss要效果好还是有些细节要注意的)如何理解 A:主要是预测scale那里。在模型上,预测location的分支和预测scale的分支要尽量解耦,不要让他们相互干扰。预测scale的分支要保证输出结果>0,一般人会用exp作为激活函数保证非负,但是我发现用ELU +1会更好。然后其实scale的下界最好不要是0,最好让scale>0.01或者>0.1啥的。以上都是个人看法。其实我开源的代码(周梓康大佬的github开源代码)里都有这些细节,不过可能大家不一定注意到。
给出链接:https://github.com/ZikangZhou/QCNet
https://github.com/ZikangZhou/HiVT
8. 有拿VAE做轨迹预测的吗,给个链接!
https://github.com/L1aoXingyu/pytorch-beginner/tree/master/08-AutoEncoder
9. 请问大伙一个问题,就是Polyline到底是啥?另外说polyline由向量Vector组成,这些Vector是相当于节点吗?
A:Polyline就是折线,折线就是一段一段的,每一段都可以看成是一段向量
Q2:请问这个折线段和图神经网络的节点之间的边有关系吗?或者说Polyline这个折现向量相当于是图神经网络当中的节点还是边呀?
A:一根折线可以理解为一个节点。轨迹预测里面没有明确定义的边,边如何定义取决于你怎么理解这个问题。
Q3: VectorNet里面有很多个子图,每个子图下面有很多个Polyline,把Polyline当做向量的话,就相当于把Polyline这个节点变成了向量,相当于将节点进行特征向量化对吗?然后Polyline里面有多个Vector向量,就是相当于是构成这个节点的特征矩阵么?
A: 一个地图里有很多条polyline;一个Polyline就是一个子图;一个polyline由很多段比较短的向量组成,每一段向量都是子图上的一个节点
10. 有的论文,像multipath++对于地图两个点就作为一个单元,有的像vectornet是一条线作为一个单元,这两种有什么区别吗?
A: 节点的粒度不同,要说效果的话那得看具体实现;速度的话,显然粒度越粗效率越高
Q2:从效果角度看,什么时候选用哪种有没有什么原则?
A: 没有原则,都可以尝试
11.有什么可以判断score的平滑性吗? 如果一定要做的话
A: 这个需要你输入是流动的输入比如0-19和1-20帧然后比较两帧之间的对应轨迹的score的差的平方,统计下就可以了
Q2: Thomas老师有哪些指标推荐呢,我目前用一阶导数和二阶导数。但好像不是很明显,绝大多数一阶导和二阶导都集中在0附近。
A: 我感觉连续帧的对应轨迹的score的差值平方就可以了呀,比如你有连续n个输入,求和再除以n。但是scene是实时变化的,发生交互或者从非路口到路口的时候score就应该是突变的
12.hivt里的轨迹没有进行缩放吗,就比如×0.01+10这种。分布尽可能在0附近。我看有的方法就就用了,有的方法就没有。取舍该如何界定?
A:就是把数据标准化归一化呗。可能有点用 但应该不多
13.HiVT里地图的类别属性经过embedding之后为什么和数值属性是相加的,而不是concat?
A:相加和concat区别不大,而对于类别embedding和数值embedding融合来说,实际上完全等价
Q2: 完全等价应该怎么理解?
A: 两者Concat之后再过一层线性层,实际上等价于把数值embedding过一层线性层以及把类别embedding过一层线性层后,两者再相加起来.把类别embedding过一层线性层其实没啥意义,理论上这一层线性层可以跟nn.Embeddding里面的参数融合起来
14.作为用户可能更关心的是,HiVT如果要实际部署的话,最小的硬件要求是多少?
A:我不知道,但根据我了解到的信息,不知道是NV还是哪家车厂是拿HiVT来预测行人的,所以实际部署肯定是可行的
15. 基于occupancy network的预测有什么特别吗?有没有论文推荐?
A:目前基于occupancy的未来预测的方案里面最有前途的应该是这个:https://arxiv.org/abs/2308.01471
16.考虑规划轨迹的预测有什么论文推荐吗?就是预测其他障碍物的时候,考虑自车的规划轨迹?
A:这个可能公开的数据集比较困难,一般不会提供自车的规划轨迹。上古时期有一篇叫做PiP的,港科Haoran Song。我感觉那种做conditional prediction的文章都可以算是你想要的,比如M2I
17.有没有适合预测算法进行性能测试的仿真项目可以学习参考的呢
A(stu):这个论文有讨论:Choose Your Simulator Wisely A Review on Open-source Simulators for Autonomous Driving
18.请问如何估计GPU显存需要多大,如果使用Argoverse数据集的话,怎么算
A:和怎么用有关系,之前跑hivt我1070都可以,现在一般电脑应该都可以


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









