







我们知道,大模型到 GPT-3.5 这种千亿体量以后,训练和推理的算力就不是普通创业公司所能承担的了,人们用起来速度也会很慢。
但自本周起,这种观念已成为历史。10倍英伟达GPU,大模型专用芯片一夜成名,来自谷歌TPU创业团队,能带来完全不同的大模型体验。
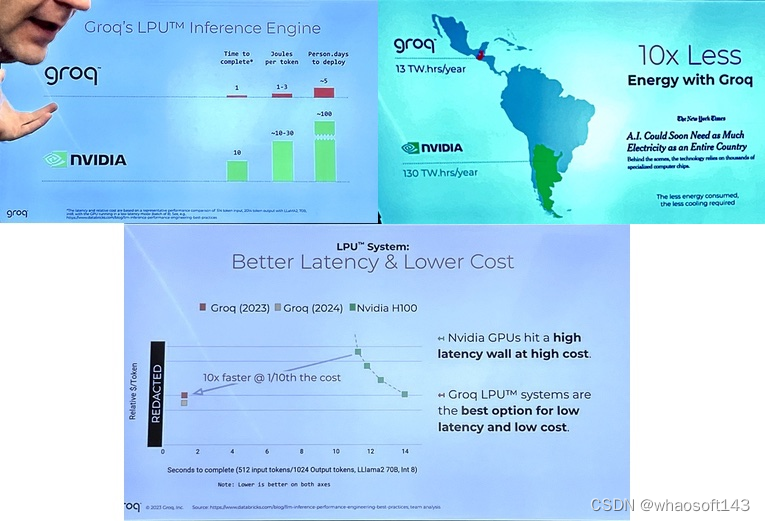
有名为 Groq 的初创公司开发出一种机器学习处理器,据称在大语言模型任务上彻底击败了 GPU—— 比英伟达的 GPU 快 10 倍,而成本仅为 GPU 的 10%,只需要十分之一的电力。
这是在 Groq 上运行 Llama 2 的速度:

这是 Groq(Llama 2)和 ChatGPT 面对同一个 prompt 的表现:
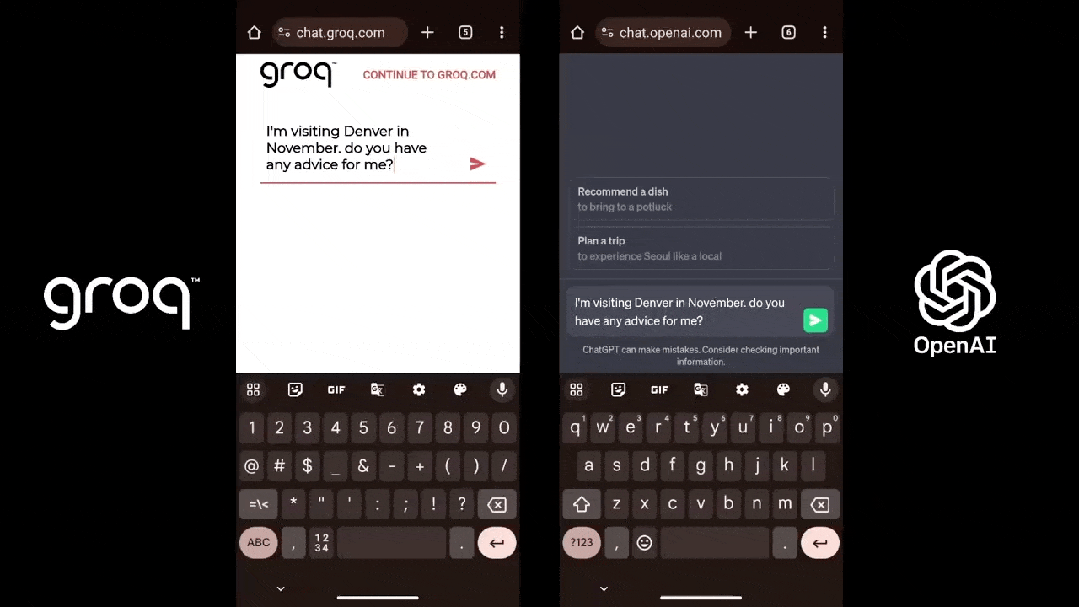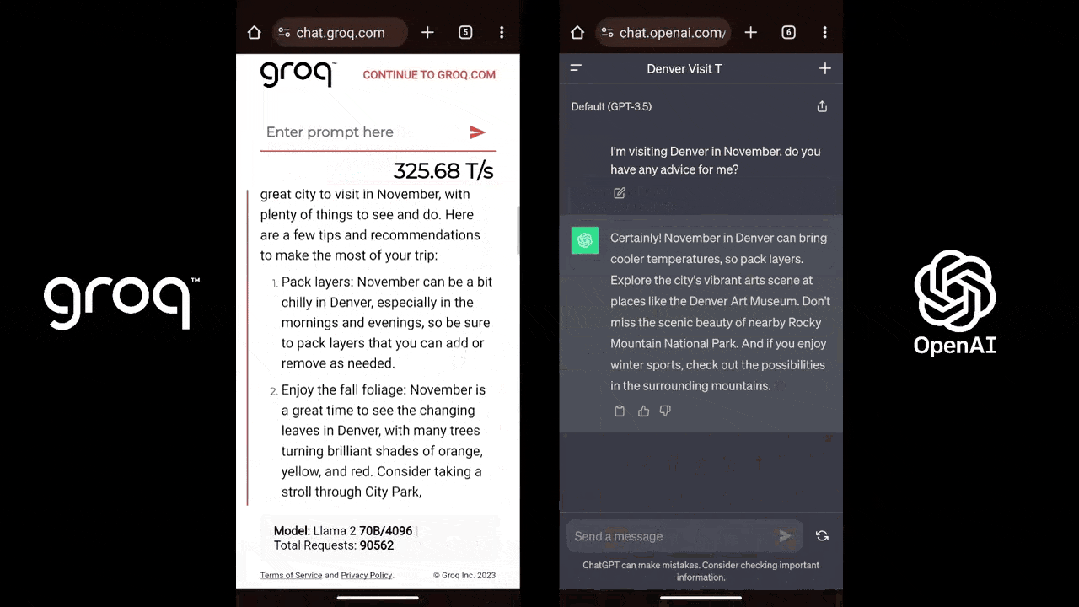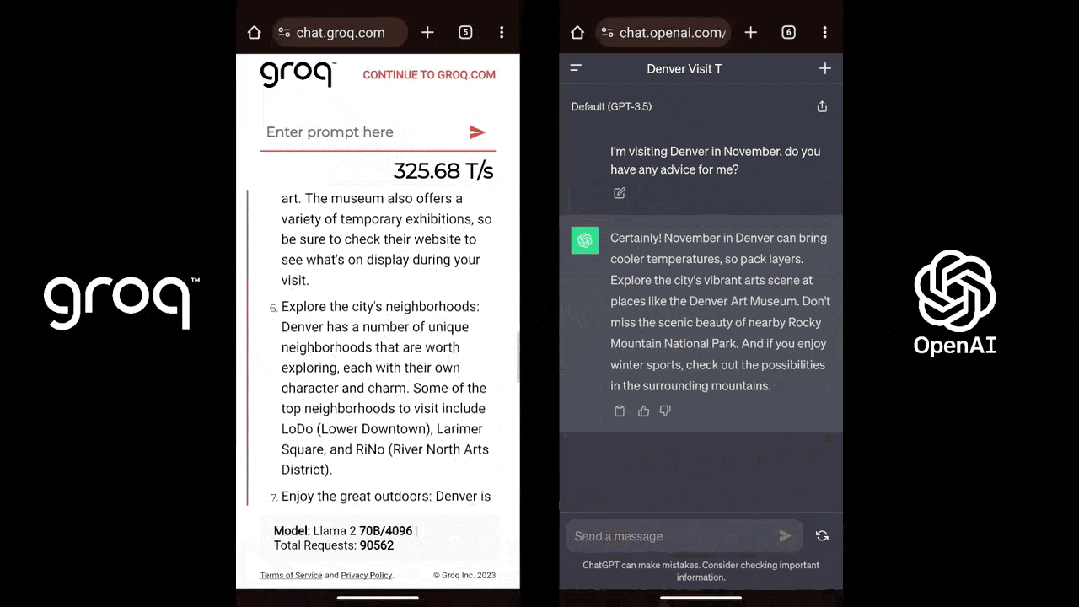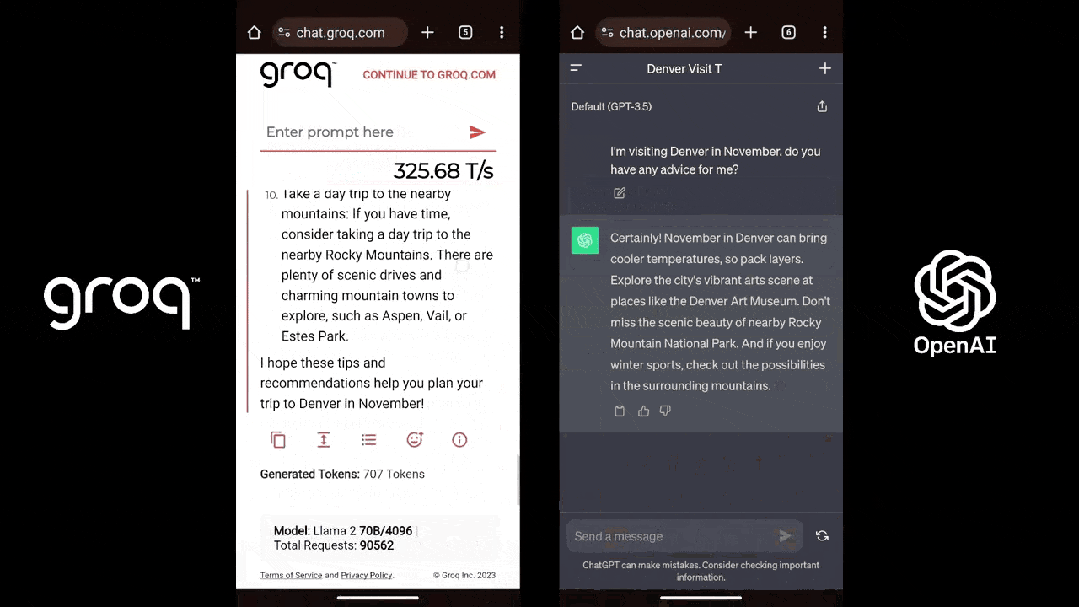
尽管看起来不可思议,但事实就是如此,感兴趣的朋友不妨一试。
目前,Groq 的官网提供了试用体验,有这些模型可选:
官网地址:https://groq.com/
Groq 的处理器名为 LPU(语言处理单元),是一种新型的端到端处理单元系统,可以为具备序列组件的计算密集型应用(比如 LLM)提供极快的推理速度。
它带动的大模型速度能达到前所未有的 500 Token/s,并且实现了极低的延迟。
用硬件加速软件,总能给人一种力大砖飞的感觉。Groq 还在 LPU 上运行了最新锐的开源模型 Mixtral,模型在不到一秒的时间内回复了包含数百个单词的事实性的、引用的答案(其中四分之三的时间是用来搜索):
Groq 放出的 Demo 视频下,有人评论道:这也太快了,不该这么快。
有网友因此提出建议:因为大模型生成内容的速度太快,所以从用户体验的角度来看不应该再自动翻页了,因为人眼看不过来。
或许在 LPU 的加持下,生成式 AI 真的要如同 Gartner 最近预测所言:在两年内对搜索引擎构成巨大威胁了。仔细一想也确实合理,毕竟当年神经网络就是被 GPU 算力的发展带飞的。
至于为什么这么快?
有人分析,GPU 专为具有数百个核心的并行处理而设计,主要用于图形渲染,而 LPU 的架构旨在为 AI 计算提供确定性的性能。
LPU 的架构不同于 GPU 使用的 SIMD(单指令、多数据)模型,而是采用更精简的方法,消除了对复杂调度硬件的需求。这种设计允许有效利用每个时钟周期,确保一致的延迟和吞吐量。
能源效率是 LPU 相对于 GPU 的另一个值得注意的优势。通过减少与管理多个线程相关的开销并避免核心利用率不足,LPU 可以提供更多的每瓦计算量,将其定位为更环保的替代方案。
Groq 的芯片设计允许将多个 TSP 连接在一起,不会出现 GPU 集群中的传统瓶颈,使其具有极高的可扩展性。随着更多 LPU 的添加,这可以实现性能的线性扩展,从而简化大规模 AI 模型的硬件要求,并使开发人员更轻松地扩展其应用程序,而无需重新架构其系统。
在 A100 和 H100 相对紧缺的时代,LPU 或许会成为大模型开发商的新选择。
Groq 成立于 2016 年,这家公司的创始团队出自谷歌,曾经设计了谷歌自研 AI 芯片张量处理单元 TPU 系列。据官网介绍,Groq 公司创始人、首席执行官 Jonathan Ross 曾经承担了 TPU 的 20% 工作。 whaosoft aiot http://143ai.com
在去年的高性能计算会议 SC23 上,Groq 就展示过在 LPU 上运行 LLM 的全球最佳低延迟性能。当时,Groq 能够以每秒超过 280 个 Token 的速度生成回复,刷新了 Llama-2 70B 推理的性能记录。
今年 1 月,Groq 首次参与公开基准测试,就在 Anyscale 的 LLMPerf 排行榜上取得了突出的成绩,远超其他基于云的推理提供商。
人工智能已经在科技界掀起了一场风暴。2023 年可能是世界意识到人工智能将成为现实的一年,而 2024 年则是人工智能真正成为现实而不仅仅是假设的一年。这是 Jonathan Ross 曾经表达的一个观点。
当我们拥有 100 万 Token 上下文的 Gemini Pro 1.5、每秒 500 Token 推理速度的 Groq、推理能力更进一步的 GPT-5,梦想还会远吗?
论文地址:https://wow.groq.com/wp-content/uploads/2024/02/GroqISCAPaper2022_ASoftwareDefinedTensorStreamingMultiprocessorForLargeScaleMachineLearning.pdf
具体来说,LPU的工作原理与GPU截然不同。
它采用了时序指令集计算机(Temporal Instruction Set Computer)架构,这意味着它无需像使用高带宽存储器(HBM)的GPU那样频繁地从内存中加载数据。
这一特点不仅有助于避免HBM短缺的问题,还能有效降低成本。
这种设计使得每个时钟周期(every clock cycle)都能被有效利用,从而保证了稳定的延迟和吞吐量。
在能效方面,LPU也显示出其优势。通过减少多线程管理的开销和避免核心资源的未充分利用,LPU能够实现更高的每瓦特计算性能。
目前,Groq可支持多种用于模型推理的机器学习开发框架,包括PyTorch、TensorFlow和ONNX。但不支持使用LPU推理引擎进行ML训练。
甚至有网友表示,「Groq的LPU在处理请求和响应方面,速度超越了英伟达的GPU」。
不同于英伟达GPU需要依赖高速数据传输,Groq的LPU在其系统中没有采用高带宽存储器(HBM)。
它使用的是SRAM,其速度比GPU所用的存储器快约20倍。
鉴于AI的推理计算,相较于模型训练需要的数据量远小,Groq的LPU因此更节能。
在执行推理任务时,它从外部内存读取的数据更少,消耗的电量也低于英伟达的GPU。
LPU并不像GPU那样对存储速度有极高要求。
如果在AI处理场景中采用Groq的LPU,可能就无需为英伟达GPU配置特殊的存储解决方案。
Groq的创新芯片设计实现了多个TSP的无缝链接,避免了GPU集群中常见的瓶颈问题,极大地提高了可扩展性。
这意味着随着更多LPU的加入,性能可以实现线性扩展,简化了大规模AI模型的硬件需求,使开发者能够更容易地扩展应用,而无需重构系统。
Groq公司宣称,其技术能够通过其强大的芯片和软件,在推理任务中取代GPU的角色。
对开发者来说,这意味着性能可以被精确预测并优化,这一点对于实时AI应用至关重要。
对于未来AI应用的服务而言,LPU可能会带来与GPU相比巨大的性能提升!
考虑到A100和H100如此紧缺,对于那些初创公司拥有这样的高性能替代硬件,无疑是一个巨大的优势。
目前,OpenAI正在向全球政府和投资者寻求7万亿美元的资金,以开发自己的芯片,解决扩展其产品时遇到算力不足的问题。
2倍吞吐量,响应速度仅0.8秒
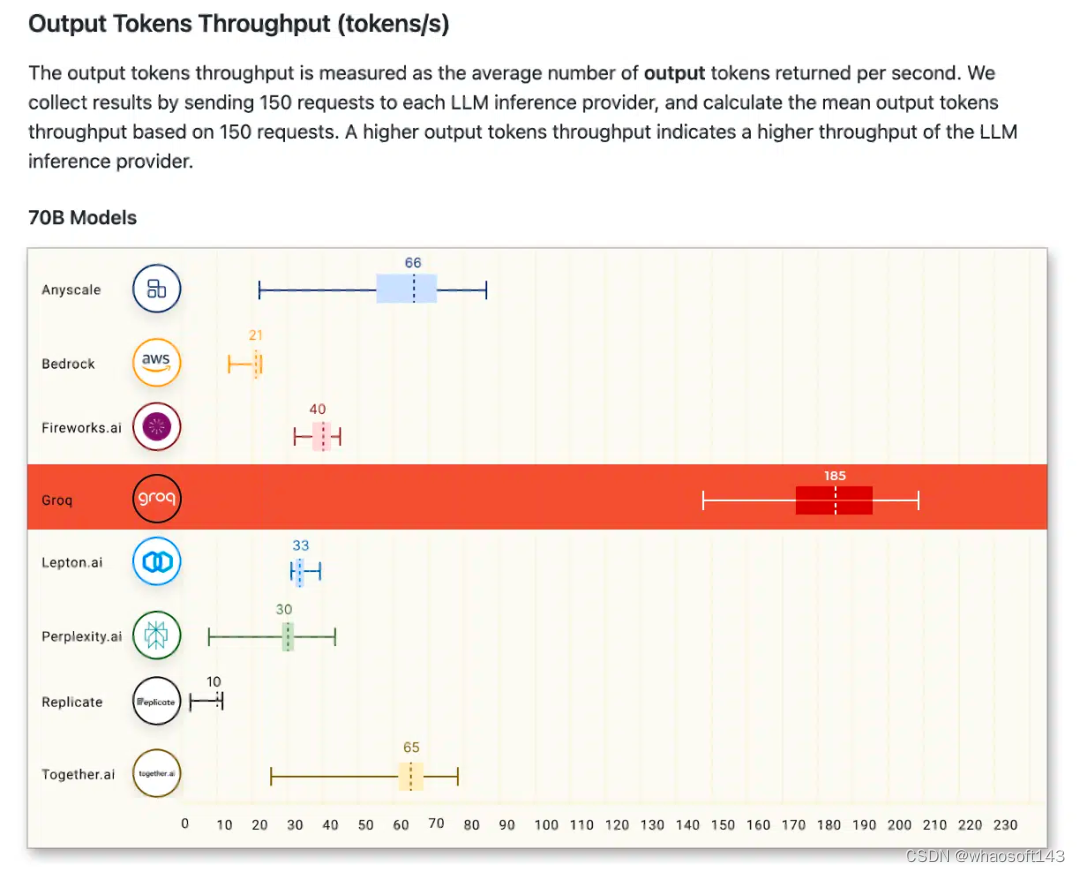
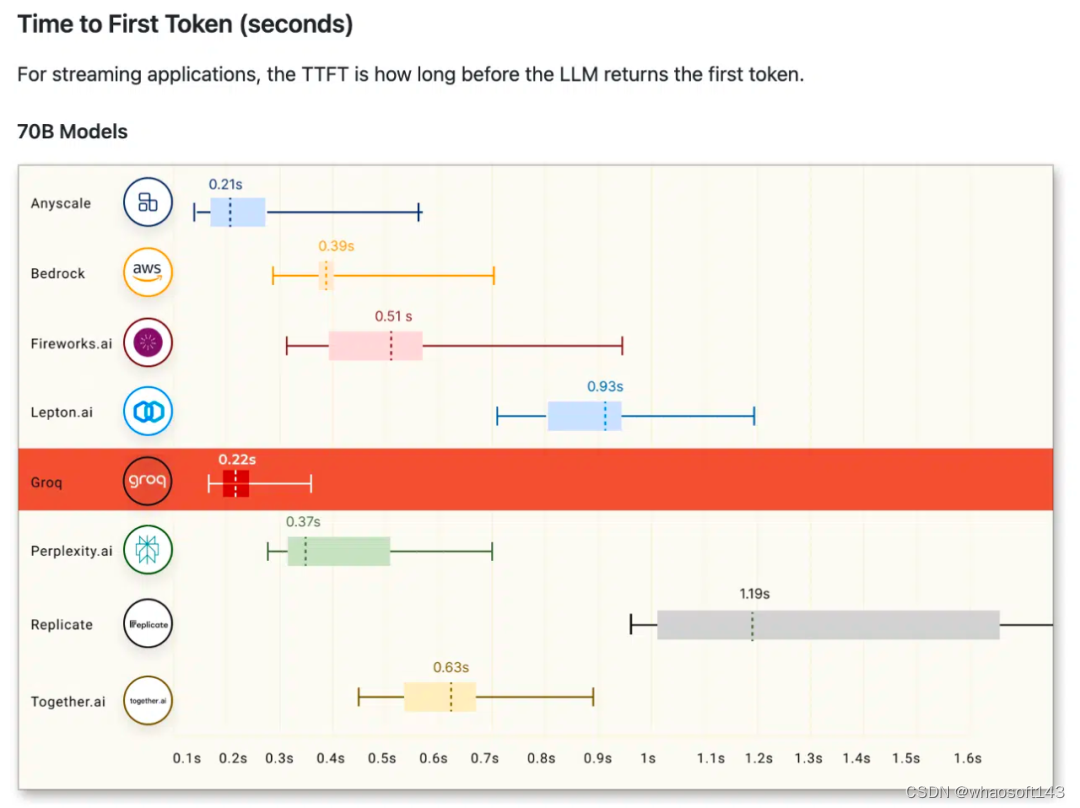
前段时间,在ArtifialAnalysis.ai的LLM基准测试中,Groq的方案击败了8个关键性能指标。
其中包括在延迟与吞吐量、随时间的吞吐量、总响应时间和吞吐量差异。
在右下角的绿色象限中,Groq取得最优的成绩。
Llama 2 70B在Groq LPU推理引擎上效果最为出色,达到了每秒241个token的吞吐量,是其他大厂的2倍还要多。
Groq的响应时间也是最少的,接收100个token后输出只有0.8秒。
另外,Groq已经运行了几个内部基准,可以达到每秒300个token,再次设定了全新的速度标准。
Groq首席执行官Jonathan Ross曾表示,「Groq的存在是为了消除「富人和穷人」,并帮助人工智能社区中的每个人发展。而推理是实现这一目标的关键,因为『速度』是将开发人员的想法转化为商业解决方案和改变生APP的关键」。
一块卡2万刀,内存230MB
想必大家在前面已经注意到了,一张LPU卡仅有230MB的内存。
而且,售价为2万+美元。
根据The Next Platform的报道,在以上的测试中,Groq实际上使用了576个GroqChip,才实现了对Llama 2 70B的推理。
通常来说,GroqRack配备有9个节点,其中8个节点负责计算任务,剩下1个节点作为备用。但这次,9个节点全部被用于计算工作。
对此网友表示,Groq LPU面临的一个关键问题是,它们完全不配备高带宽存储器(HBM),而是仅配备了一小块(230MiB)的超高速静态随机存取存储器(SRAM),这种SRAM的速度比HBM3快20倍。
这意味着,为了支持运行单个AI模型,你需要配置大约256个LPU,相当于4个满载的服务器机架。每个机架可以容纳8个LPU单元,每个单元中又包含8个LPU。
相比之下,你只需要一个H200(相当于1/4个服务器机架的密度)就可以相当有效地运行这些模型。
这种配置如果用于只需运行一个模型且有大量用户的场景下可能表现良好。但是,一旦需要同时运行多个模型,特别是需要进行大量的模型微调或使用高级别的LoRA等操作时,这种配置就不再适用。
此外,对于需要在本地部署的情况,Groq LPU的这一配置优势也不明显,因为其主要优势在于能够集中多个用户使用同一个模型。
另有网友表示,「Groq LPU似乎没有任何HBM,而且每个芯片基本上都带有少量的SRAM?也就是说他们需要大约256个芯片来运行Llama 70B?」
没想到得到了官方回应:是的,我们的LLM在数百个芯片上运行。
还有人对LPU的卡的价钱提出了异议,「这难道不会让你的产品比H100贵得离谱吗」?
马斯克Grok,同音不同字
前段时间,Groq曾公开基准测试结果后,已经引来了一大波关注。
而这次,Groq这个最新的AI模型,凭借其快速响应和可能取代GPU的新技术,又一次在社交媒体上掀起了风暴。
不过,Groq背后的公司并非大模型时代后的新星。
它成立于2016年,并直接注册了Groq这一名字。
CEO兼联合创始人Jonathan Ross在创立Groq之前,曾是谷歌的员工。
曾在一个20%的项目中,设计并实现了第一代TPU芯片的核心元素,这就是后来的谷歌张量处理单元(TPU)。
随后,Ross加入了谷歌X实验室的快速评估团队(著名的「登月工厂」项目初始阶段),为谷歌母公司Alphabet设计和孵化新的Bets(单元)。
或许大多数人对马斯克Grok,还有Groq模型的名字感到迷惑。
其实,在劝退马斯克使用这个名字时,还有个小插曲。
去年11月,当马斯克的同名AI模型Grok(拼写有所不同)开始受到关注时,Groq的开发团队发表了一篇博客,幽默地请马斯克另选一个名字:
我们明白你为什么会喜欢我们的名字。你对快速的事物(如火箭、超级高铁、单字母公司名称)情有独钟,而我们的Groq LPU推理引擎正是运行LLM和其他生成式AI应用的最快方式。但我们还是得请你赶紧换个名字。
不过,马斯克并未对两个模型名称的相似之处作出回应。
参考资料:
https://x.com/JayScambler/status/1759372542530261154?s=20
https://x.com/gabor/status/1759662691688587706?s=20
https://x.com/GroqInc/status/1759622931057934404?s=20
https://blocksandfiles.com/2024/01/23/grokking-groqs-groqness/
https://siliconangle.com/2024/01/18/ai-leaders-discuss-state-ai-implemented-enterprise-cescoverage-cubeconversations/

















 1468
1468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









