







 作者提出MVBench,一个包含20项视频任务的评测框架,评估多模态模型的视频理解。VideoChat2在MVBench上表现出色,并在其他数据集上显示竞争力。该研究还探讨了模型缺陷和改进方法,包括指令微调和强化视频编码器。
作者提出MVBench,一个包含20项视频任务的评测框架,评估多模态模型的视频理解。VideoChat2在MVBench上表现出色,并在其他数据集上显示竞争力。该研究还探讨了模型缺陷和改进方法,包括指令微调和强化视频编码器。
作者提出了MVBench,多模态视频理解能力的全面评测,由20项单帧无法有效解决的视频任务组成,用于全面评测现有多模态模型的视频理解能力。基于对已有视频多模态模型的缺陷分析,作者提出了更强大的基线模型VideoChat2,其不仅在MVBench上取得15个任务的领先,更在流行的视频问答、对话、推理数据集上取得有竞争力的性能。
[CVPR2024] MVBench 多模态视频理解能力的全面评测!
Paper: MVBench: A Comprehensive Multi-modal Video Understanding Benchmark
https//arxiv.org/abs/2311.17005
Code: MVBench & VideoChat
https//github.com/OpenGVLab/Ask-Anything/tree/main/video_chat2
Online Demo: Hugging Face
https//huggingface.co/spaces/OpenGVLab/VideoChat2
OpenXLab
https//openxlab.org.cn/apps/detail/yinanhe/VideoChat2
Benchmark Data: OpenGVLab/MVBench
https//huggingface.co/datasets/OpenGVLab/MVBench
Instruction-tuning Data: OpenGVLab/VideoChat2-IT
https//huggingface.co/datasets/OpenGVLab/VideoChat2-IT
我们提出了MVBench,由20项单帧无法有效解决的视频任务组成,用于全面评测现有多模态模型的视频理解能力。基于对已有视频多模态模型的缺陷分析,我们提出了更强大的基线模型VideoChat2,其不仅在MVBench上取得15个任务的领先,更在流行的视频问答、对话、推理数据集上取得有竞争力的性能。所有的代码、模型权重、训练数据、评测数据均已开源!
VideoChat2性能
Motivation
五月份做完VideoChat[1]之后,我们遇到了图像对话模型一样的窘境,应该如何科学全面地评测多模态对话模型的能力呢?
-
最直接有效的方法是用人类评测,这也是在Multi-Modality Arena[2]中使用的,但是人类评测效率低下,且存在认知偏差,很难公平地评判不同的模型。
-
一种间接的方式是使用大语言模型评价,但这种方式更公正,但大前提是语言模型足够聪明、强大、鲁棒,换句话说,足够“像人类”。目前常用的做法是使用ChatGPT(默认为3.5)甚至是GPT-4,且需要精心设计评价prompt,如VideoChatGPT[3]和MMVet[4]。
-
最后一种方式是使用传统的评价方式,如multiple-choice QA。但传统数据集往往侧重角度单一,无法较为全面地评价、诊断对话模型的能力。因此,最近的图像对话模型评测,倾向于从不同的感知和认知角度,考虑模型的多种能力,并基于不同的能力设计评测任务,再通过人工采集、标定数据。最后使用multiple-choice QA的方式,计算不同任务的准确率,从而实现全面的评测。
我们最终决定采用的也是最后一种方式,那么问题便来到了,如何确定合适的评测任务呢?
Temporal Task Definition
通过思考图像和视频任务的本质区别,我们确定了一种简单可扩展的方案:首先总结基本的图像评测任务,再由这些任务出发,思考无法通过单帧有效解决的视频任务。
我们首先从图像benchmark[5][6]里总结了上述9项空间理解任务,再思考延伸出20项时间理解任务如下:
Action. (1) Action Sequence: Retrieve the events occurring before or after a specific action. (2) Action Prediction: Infer the subsequent events based on the current actions. (3) Action Antonym: Distinguish the correct action from two inversely ordered actions. (4) Fine-grained Action: Identify the accurate action from a range of similar options. (5) Unexpected Action: Detect surprising actions in videos characterized by humor, creativity, or magic.
Object. (6) Object Existence: Determine the existence of a specific object during a particular event. (7) Object Interaction: Identify the object that participates in a particular event. (8) Object Shuffle: Locate the final position of an object in an occlusion game.
Position. (9) Moving Direction: Ascertain the trajectory of a specific object’s movement. (10) Action Localization: Determine the time period when a certain action occurs.
Scene. (11) Scene transition: Determine how the scene transitions in the video.
Count. (12) Action Count: Calculate how many times a specific action has been performed. (13) Moving Count: Calculate how many objects have performed a certain action.
Attribute. (14) Moving Attribute: Determine the appearance of a specific moving object at a given moment. (15) State Change: Determine whether the state of a certain object changes throughout the video.
Pose. (16) Fine-grained Pose: Identify the accurate pose category from a range of similar options.
Character. (17) Character Order: Determine the order in which the letters appear.
Cognition. (18) Egocentric Navigation: Forecast the subsequent action, based on an agent’s current navigation instructions. (19) Episodic Reasoning: Perform reasoning on the characters, events, and objects within an episode of a TV series. (20) Counterfactual Inference: Consider what might happen if a certain event occurs.
下面列举了具体每个任务的例子
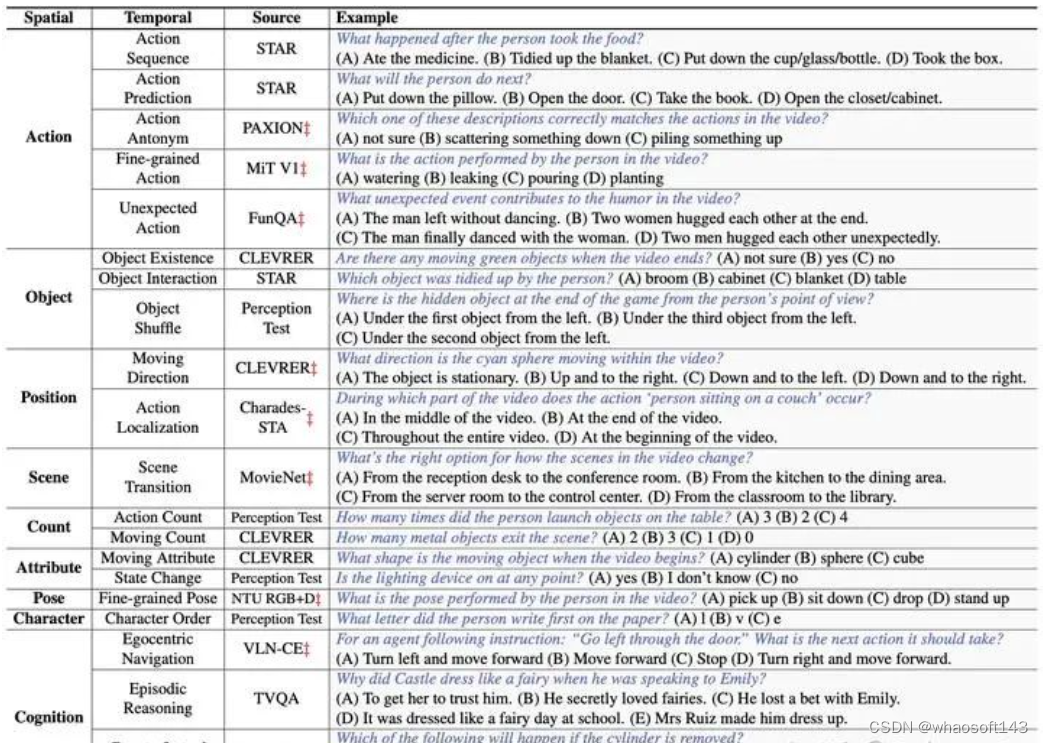
20项任务举例
Automatic QA Generation
有了评测任务定义之后,下一个问题便是如何制定评测数据,为了最大化地减少人力开销,我们收集了多个开源的视频数据集,利用开源的高质量数据标注,设计了一套自动生成评测数据的pipeline如下所示
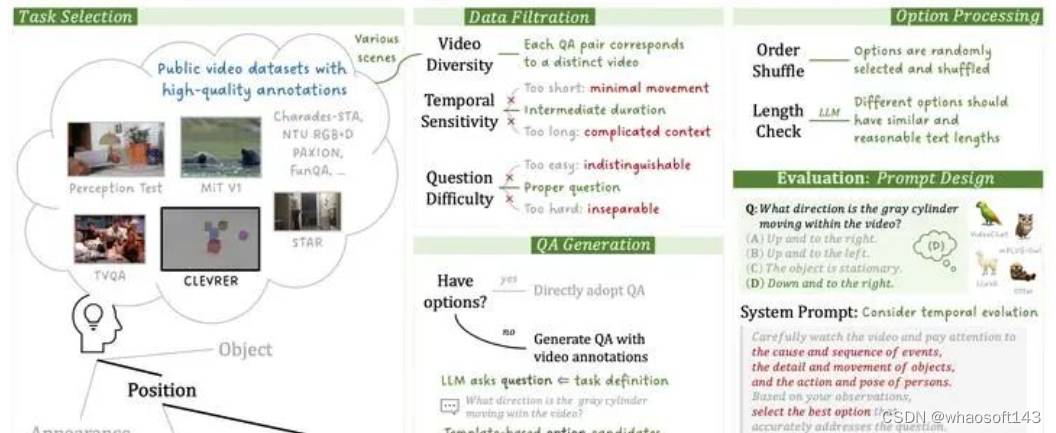
自动化生成pipeline
具体地我们从任务出发,敲定任务所需要的数据集,之后进行数据过滤:
-
考虑到视频多样性,我们尽可能地对不同的视频设计独立的问题;
-
考虑到时序敏感性,我们采取每个数据集中合适的视频长度,过短的视频往往动作幅度较小,而过长的视频包含过于复杂的上下文,问题过难会导致无法区分不同模型的能力;
-
考虑到问题复杂度,我们采取难度适中的问题,如在CLEVRER中,我们采取适当条件限制的问题;如对于时间定为问题,我们不采用精细的秒级别定位任务,而采用粗略的时间段定位,如发生在视频的开始、中间还是结束。
之后便来到生成多选题的问题及选项,对于已有多选QA的数据,我们直接采用。但对于没有多选QA的数据,我们接住ChatGPT来生成:
-
对于问题,我们基于ChatGPT任务的定义,并生成3-5个对应的问题随机选其一;
-
对于选项,我们设计两种策略:(a)基于模版的构造,我们设计固定的选项模版,结合GT匹配生成;(b)基于LLM的生成,我们将原始QA输入ChatGPT,并让ChatGPT生成新的问题以及选项。
具体对不同任务,我们处理如下所示:
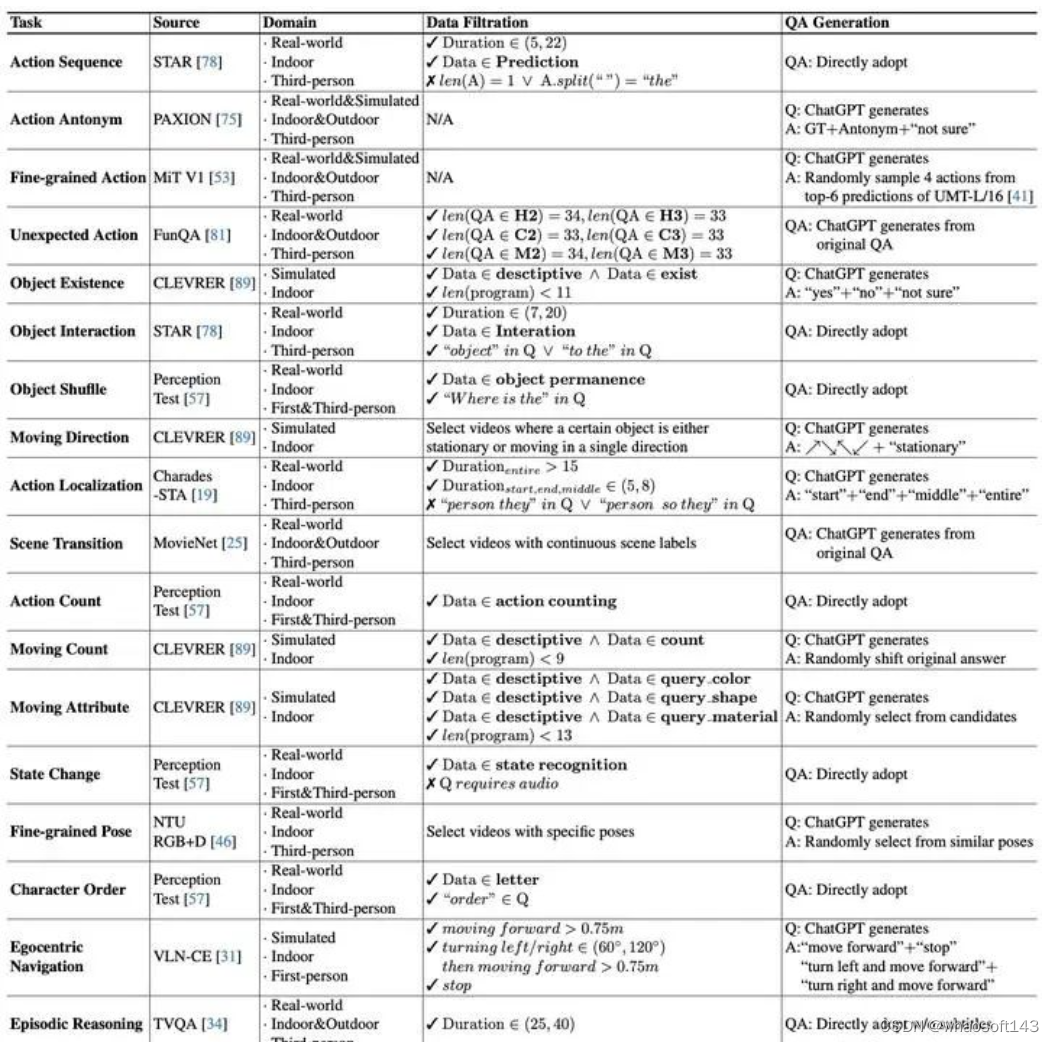
不同任务处理
在得到多选题的问题和选项后,我们还会额外进行一步后处理,对选项进行随机打乱,以及检查不同选项的长度,避免答案过长导致“答案泄露”,对过长的选项我们使用ChatGPT进行改写。
通过这种方式,我们为每个任务自动生成了200条问答,最后得到4000条数据用于高效评测。
Prompt Design for Evaluation
对于具体的评测,我们设计了合理的system prompt和高效的answer prompt,其中system prompt用于激发模型的时间理解能力:
Carefully watch the video and pay attention to the cause and sequence of events, the detail and movement of objects and the action and pose of persons. Based on your observations, select the best option that accurately addresses the question.
由于对话模型的输出倾向于输出完整的句子,难以直接输出选项,如何从对话的输出中抽取选项也成了一个难题。MMBench[6]中使用多个模版匹配选项,对于无法匹配的选项,使用ChatGPT进行抽取,然后这种抽取效率低下, 和人类相比,只取得了87%的对齐率。SEED-Bench[7]则比较不同选项的似然,选择最大似然对应的选项作为最终答案,然后这种方式仍不够直接,并且需要人为修改不同模型的forward函数。
我们采取一种更简单直接的方式,通过构造带括号"()"的选项,接着显著地通过控制对话模型输出的起始字符"Best Option: (",即answer prompt,在我们的实验里,这种方式不仅可以100%地保证不同模型地输出选项,同时能够提高答案的准确率。
VideoChat2
我们在MVBench上评价了现有的图像和视频对话模型,结果发现即便是最佳的视频对话模型VideoChat[1],性能与随机猜测相比也相差无几。分析原因可以发现,目前的视频对话模型存在两大缺陷:
-
缺乏多样的指令微调数据:由于视频数据难以标注,开源的指令微调数据扔规模较小;
-
缺乏强视频编码器:目前主流的方法仍是选强的多模态图像编码器CLIP-ViT,在上面进行时序改良,这难以本质地处理时序理解。
我们针对这两大缺陷进行了设计,首先我们借鉴了InstructBLIP[8]、M3IT[9]的思路,从现有的图像和视频数据集中转化出了1.9M统一形式的指令微调数据,如下所示
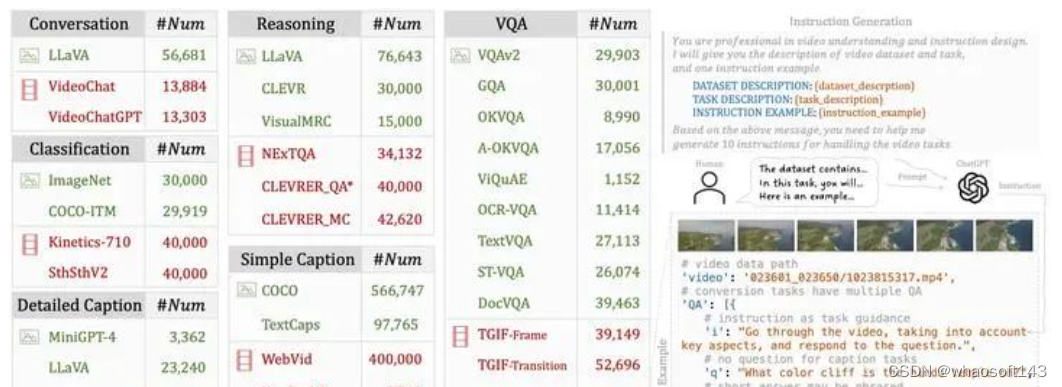
1.9M指令微调数据
这些数据主要分为6大类:Conversation, Classification, Simple Caption, Detailed Caption, VQA和Reasoning。并且都以右下角所示的形式进行统一,主要包括instruction任务提示、question问题和answer答案。对于instruction,我们借助ChatGPT进行自动生成,避免了M3IT[9]中的人工编写。而具体对不同的数据集,我们采用了不同的处理方式,详情可见:
https//huggingface.co/datasets/OpenGVLab/VideoChat2-IT
对于模型架构,我们采用了BLIP2结构,基于强多模态视频编码器UMT[10],设计了渐进式跨模态训练流程

渐进式多模态训练
在第一阶段,我们将冻结的视觉编码器和QFormer对齐,用于将冗余的视频信息压缩,这里采用了BLIP2训练的三种损失VTC/VTM/VTG。在第二阶段,我们打开视觉编码器,并引入冻结的LLM,使用VTG损失进行视觉文本链接。在最后一阶段,我们使用准备好的1.9M指令微调数据,并在LLM中插入LoRA模块进行高效微调。借鉴InstructBLIP,我们在QFormer中也插入了instruction,用于引入QFormer对视觉信息进行压缩。
Experiments
开源对话模型评测

MVBench评测结果
从结果中我们可以发现,现有对话模型在MVBench性能表现很不理想,最强的图像对话模型LLaVA和视频对话模型VideoChat,相比随机的27.7%准确率只高了不到9个点。而我们提供的强大基线模型VideoChat2相比前述最强模型,提升将近15个点。值得一提的是,这里的VideoChat2_text,输入为空白视频,即QFormer输出噪声embedding,模型仅靠文本上下文进行输出,结果居然与前述最强模型接近。这个结果也揭示了目前对话模型,在时序理解任务上,仍有很大的不足。
GPT-4V评测

MVBench子集评测结果
我们也在一个小的子集上评测了GPT-4V的性能,结果显示GPT-4V具备较好的时序理解能力。
完整Leadeboard
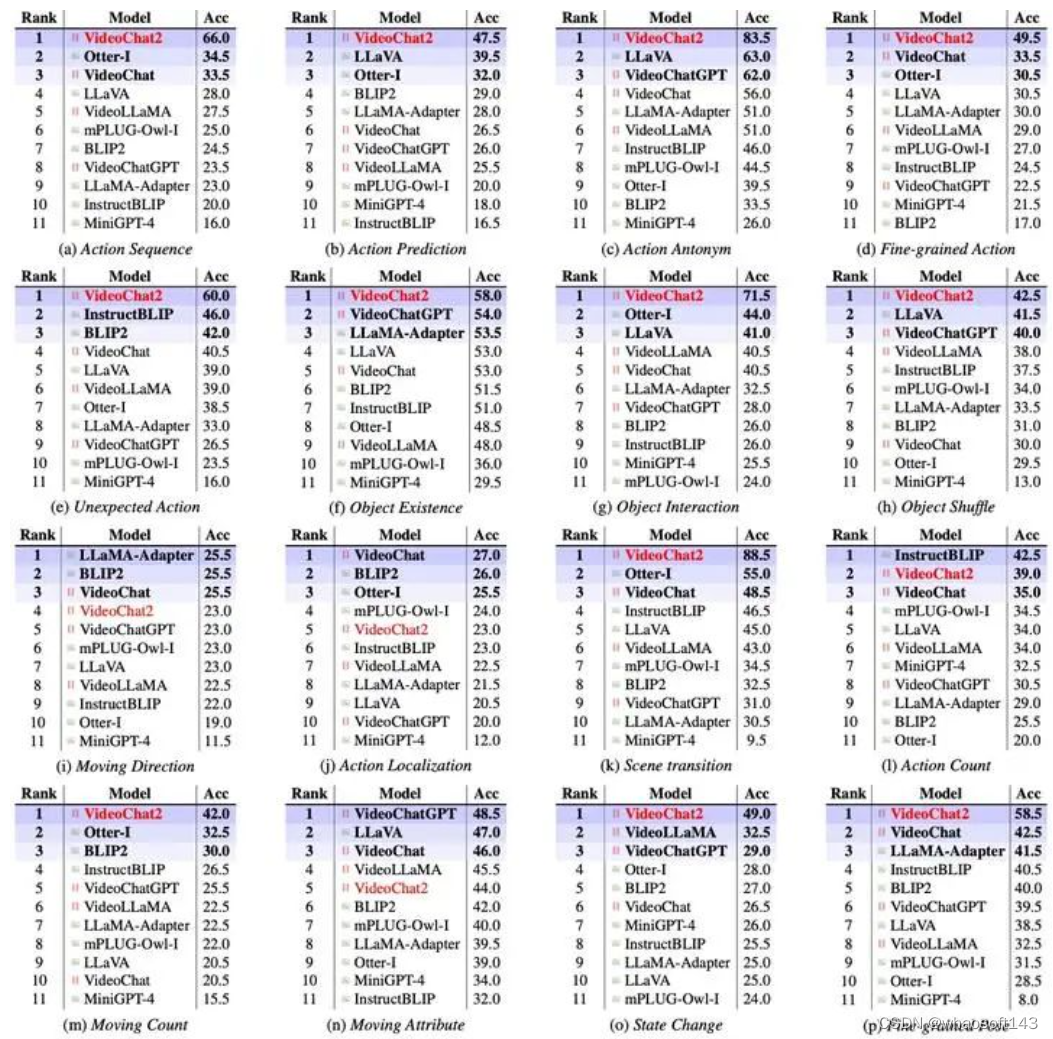
Leaderboard
我们的VideoChat2在15个任务上取得最佳性能,但也能看到,它在处理移动方向、动作定位、计数等任务上仍有不足。最近的一些图像对话模型,已经开始引入grouding数据增强相关能力,这也是后续视频对话模型可以突破的方向。
VideoChatGPT对话Benchmark
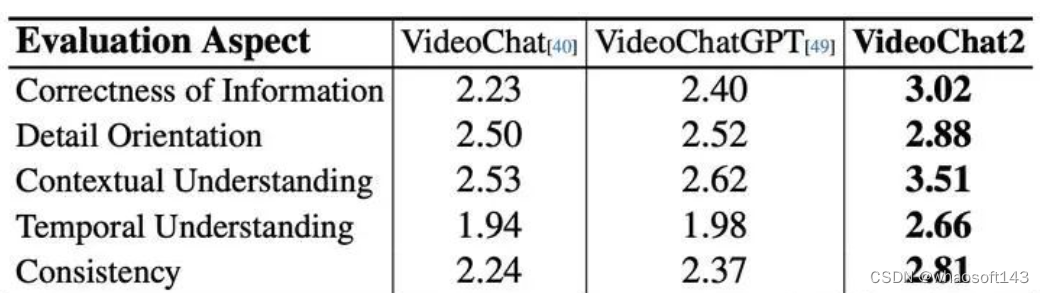
VideoChatGPT Benchamrk
在VideoChatGPT对话Benchmark上的结果显示,我们的VideoChat2在各方面能力上都有大幅度提升。
零样本传统QA
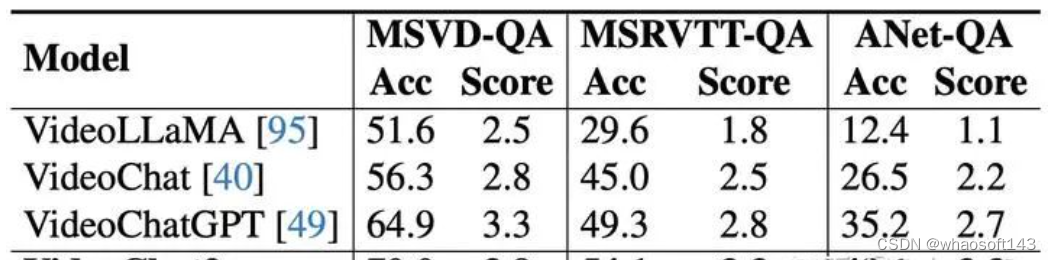
零样本传统QA
零样本传统QA任务上,VideoChat2同样优于其他视频对话模型,且在长时ActivityNet QA上有显著提升。
视频问答推理
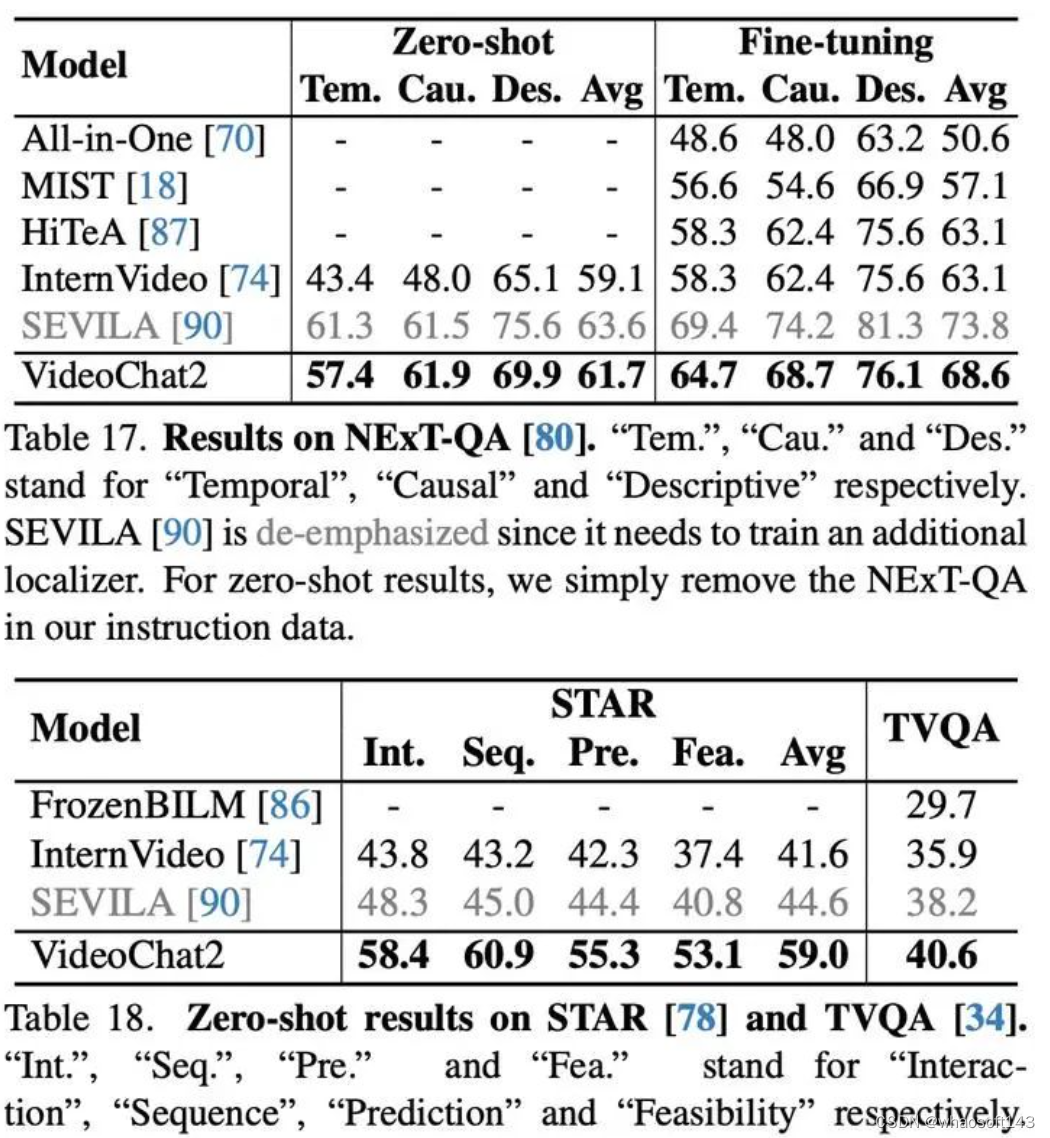
视频问答推理
在视频问答推理任务上,VideoChat2同样取得了很强的零样本性能。
消融实验
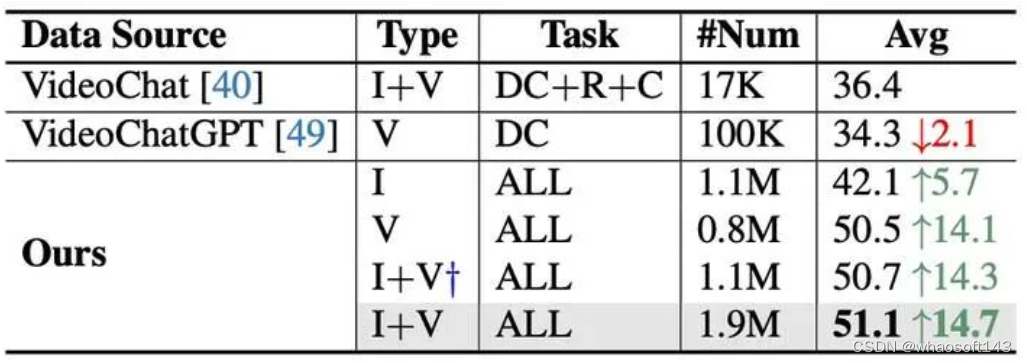
指令微调数据
在指令微调数据上的实验表明,更多样的指令数据、图像视频联合训练,都提升了模型性能。考虑到simple caption数据的冗余,我们简单进行了随机压缩,性能差异不明显。
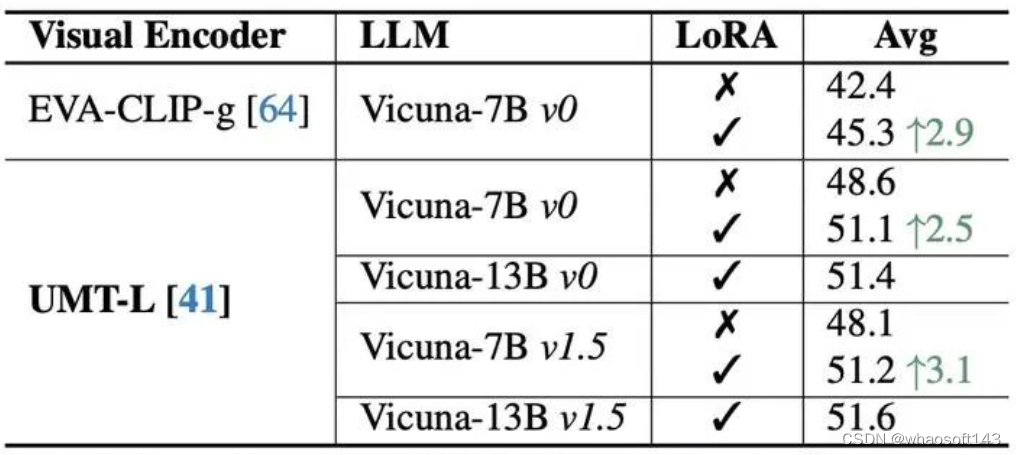
模型结构
在模型结构上的实验表明,使用强视频编码器相比图像编码器,提升显著。LoRA微调对于对话模型能力的提升十分关键,而使用更大更新的LLM,提升不明显。 whaosoft aiot http://143ai.com
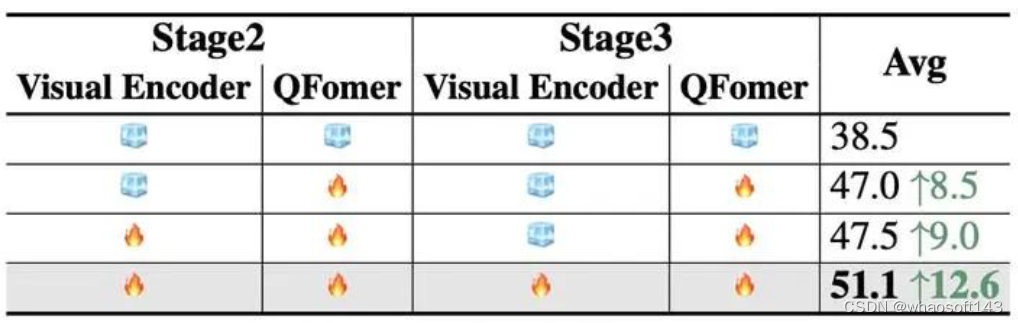
训练方式
我们同样探索了不同的冻结训练方式,结果表明,在第二第三阶段,均打开视觉编码器和QFormer效果最好。
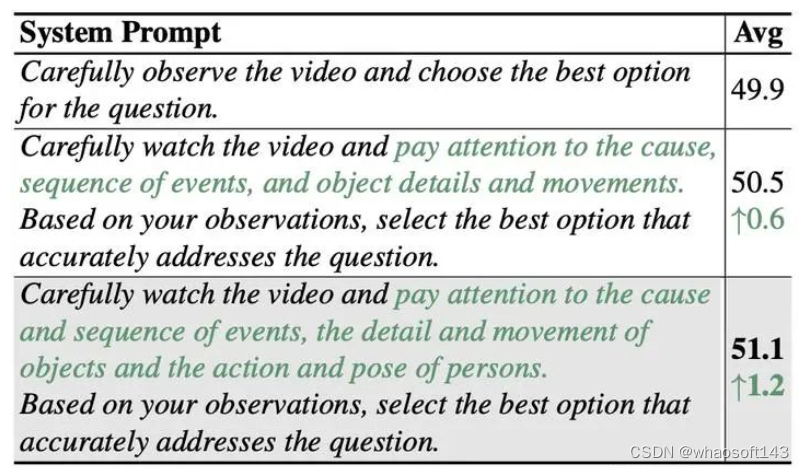
使用精心设计的system prompt,能较好地激发模型的时序理解能力。
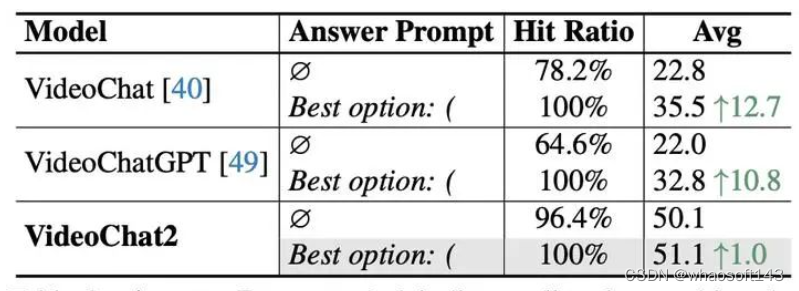
使用我们设计的简单answer prompt,不仅可以100%提取选项,同时显著提升答案准确率。
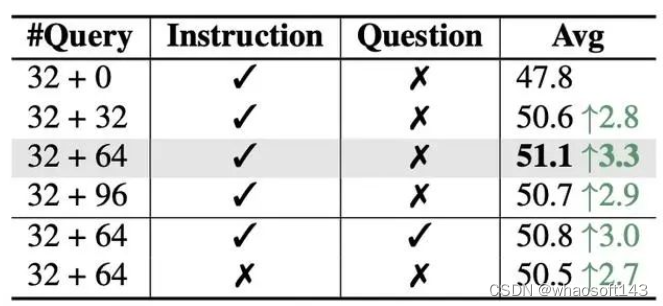
对于QFormer,我们在第二第三阶段引入了额外可学习的token,用于和LLM对齐,结果显示额外引入64个token效果最佳。并且在QFormer中插入instruction引导,结果提升明显,而继续插入question则有副作用。
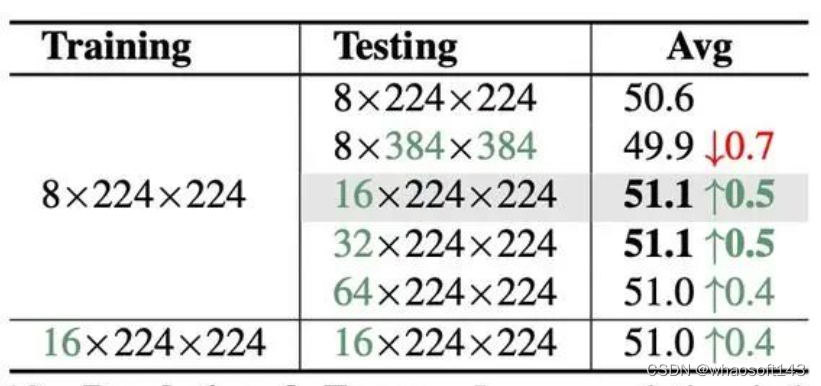
对于训练和测试输入,实验表明训练使用8帧,测试使用16帧效果较好,训练开销也较小。但使用大分辨率,在MVBench上并没有提升,侧面验证了MVBench更依赖于模型的时序理解能力。
定性结果
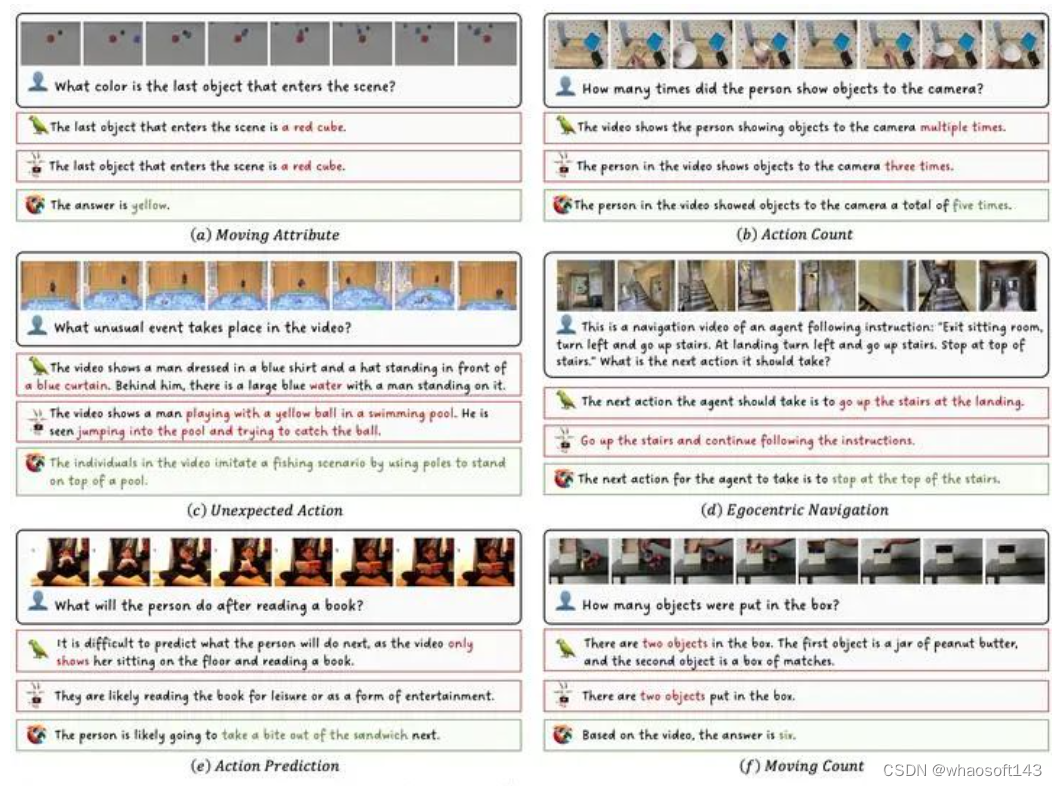
MVBench结果可视化
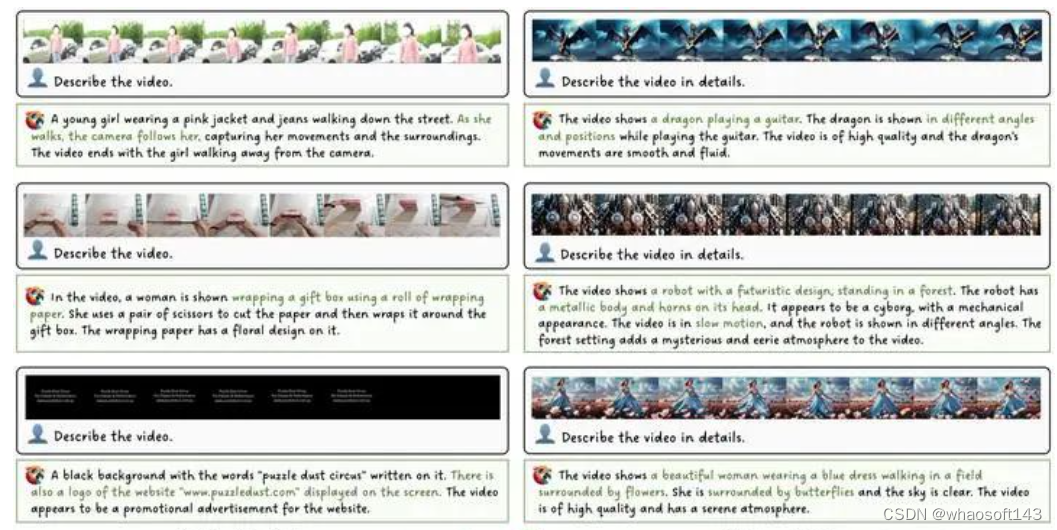
定性描述例子
Conclusion
总而言之,在MVBench中我们提出了较为全面的视频理解能力评测方案,针对现有视频对话模型的缺陷,构造了更丰富的指令微调数据,训练了更强大的基线模型VideoChat2。目前所有数据、模型、代码均已开源,期待更通用更智能的多模态对话模型涌现!
参考
1.VideoChat
https://github.com/OpenGVLab/Ask-Anything/tree/main/video_chat
2.Multi-Modality Arena
https://github.com/OpenGVLab/Multi-Modality-Arena
3.VideoChatGPT
https://github.com/mbzuai-oryx/Video-ChatGPT/tree/main/quantitative_evaluation
4.MM-Vet
https://github.com/yuweihao/MM-Vet
5.MME
https://github.com/bradyfu/awesome-multimodal-large-language-models/tree/Evaluation
6.MMBench
https://opencompass.org.cn/mmbench
7.)SEED-Bench
https://github.com/AILab-CVC/SEED-Bench/blob/main/DATASET.md
8.InstructBLIP
https://github.com/salesforce/LAVIS/tree/main/projects/instructblip
9.M3IT
https://huggingface.co/datasets/MMInstruction/M3IT
10.UMT
https://github.com/OpenGVLab/unmasked_teacher


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









