







本文提出了一种名为Wear-Any-Way的虚拟试穿的新型框架。与以往的方法不同,Wear-Any-Way是一种可自由定制的试衣方案。除了生成高保真度的结果外,该方法还支持用户对穿着方式进行精准控制。
Wear-Any-Way: Manipulable Virtual Try-on via Sparse Correspondence Alignment
项目主页地址:https://mengtingchen.github.io/wear-any-way-page/
Arxiv地址:https://arxiv.org/abs/2403.12965
机构单位:阿里巴巴 拍立淘团队
我们提出了一种名为Wear-Any-Way的虚拟试穿的新型框架。与以往的方法不同,Wear-Any-Way是一种可自由定制的试衣方案。除了生成高保真度的结果外,该方法还支持用户对穿着方式进行精准控制。为了实现这一目标,我们首先构建了一个强大的标准虚拟试衣baseline,支持在复杂情景中进行单个/多个服装进行试穿。为了使上身状态能够被自由控制,我们提出了稀疏关系对齐方案,基于对应点的控制来引导特定部位的生成。通过这种设计,Wear-Any-Way在标准设定下达到了最先进的性能,并为定制化试衣提供了一种新颖的交互形式。例如,它支持用户拖动袖子使其挽起,拖动外套使其打开衣门襟,或者利用点击来控制下摆的扎穿形式等。Wear-Any-Way实现了更自由和灵活的服饰表达,对试衣算法在时尚行业落地有着重要的意义。

图1
效果展示
1. 对应点的控制

图2
Wear-Any-Way 支持用户在服装图像和人物图像上输入控制点对,以实现对上身状态的精准控制,为现实应用落地带来了更大的潜力和想象空间。
2. 拖拽控制
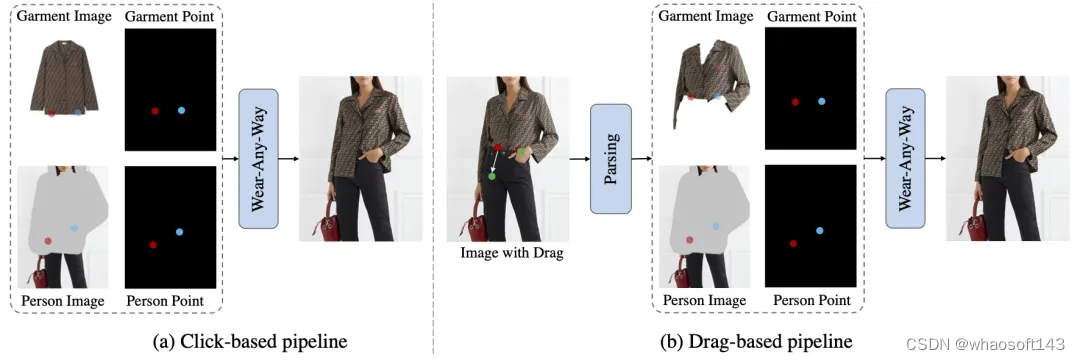
图3

图4
对于基于点击的控制,用户提供服装图像、人物图像和点对以定制生成结果。当用户拖动图像时,起始点和终点被分别视为服装图像和人物图像上的控制点,解析分割后的服装被视为服装图像输入。因此,拖动操作可以转换为基于点击的设置。
3. 自动控制
 图5
图5
我们可以通过结合人体关键点和密集姿势来计算控制点的位置。基于此我们可以通过设置不同的超参数来实现自动控制穿着风格。
4. 单件多场景试衣

图6
Wear-Any-Way 支持多种输入类型,包括平铺图到模特、模特图到模特、平铺图到街拍、模特图到街拍、街拍到街拍等。无论输入图像是什么形式,目标模特图的背景姿态如何复杂,我们的方案都能给出优质的生成结果。
5. 搭配多场景/各姿态试衣

图7
Wear-Any-Way使用户能够同时提供上衣和下衣,并在一次推理中获得整套搭配试穿结果。和单件试穿一样,我们对服饰输入形式和目标人像的场景和姿态都有非常强的泛化能力。
背景
虚拟试穿旨在合成特定人物穿着所提供服装的图像。对时尚行业落地具有重要影响,为消费者提供了一种沉浸式和交互式的方式,让他们在不亲身试穿的情况下就能真切感受服装的上身效果,同时也可以为服饰商品的模特图拍摄提供全新的方式。
之前大多数解决方案仅支持简单情况,例如输入为简单纹理的精心摆放的单个服装。对于具有复杂纹理或图案的服装,现有解决方案通常无法保证细节的保真度。此外,大多数以前的解决方案没有解决在实际应用中面临的挑战,如模特到模特的试衣、多件服装的搭配试衣、复杂的人体姿势和复杂的场景等。
此外,以前的方法无法对穿着方式进行有效控制。在时尚领域,实际的上身风格具有重要意义。例如,袖子挽起或者放下,上衣的扎穿或者叠穿,外套衣门襟的闭合,这些特定的穿着方式可以展示出同一件服装的不同状态,为服饰的上身表达提供了更高的自由度,能更加贴近服饰本身的风格和用户的偏好。
因此在这项工作中,我们提出了一种新颖的虚拟试穿框架 Wear-Any-Way,一举解决了前述的两个挑战。Wear-Any-Way 可作为标准虚拟试穿的strong baseline,它能生成高质量的图像并保留了服装上图案的精细细节。此外,他还是实际应用中一种更通用的解决方案,支持各种子任务,如模特到模特的试衣、多件服装的搭配试衣,以及像街拍/坐姿这样的复杂情景。最重要的特点是 Wear-Any-Way 支持用户定制穿着风格。如图 1 所示,用户可以使用简单的交互,如点击和拖动,来控制袖子的挽起、外套的开合程度,甚至是扎穿的方式。
总的来说,我们的贡献可以总结为三个方面:
我们构建了一个新颖的框架 Wear-Any-Way,生成高质量的试衣结果并支持用户精确控制上身状态。
我们提出了一个强大、灵活、鲁棒的虚拟试穿baseline,通过与以前方法的广泛比较达到了最先进的水平。
我们设计了稀疏对应对齐以实现基于对应点的控制,并进一步开发了几种策略(如条件丢弃、零初始化、点加权损失)有效增强了生成流程的可控性。 whaosoft aiot http://143ai.com
方法
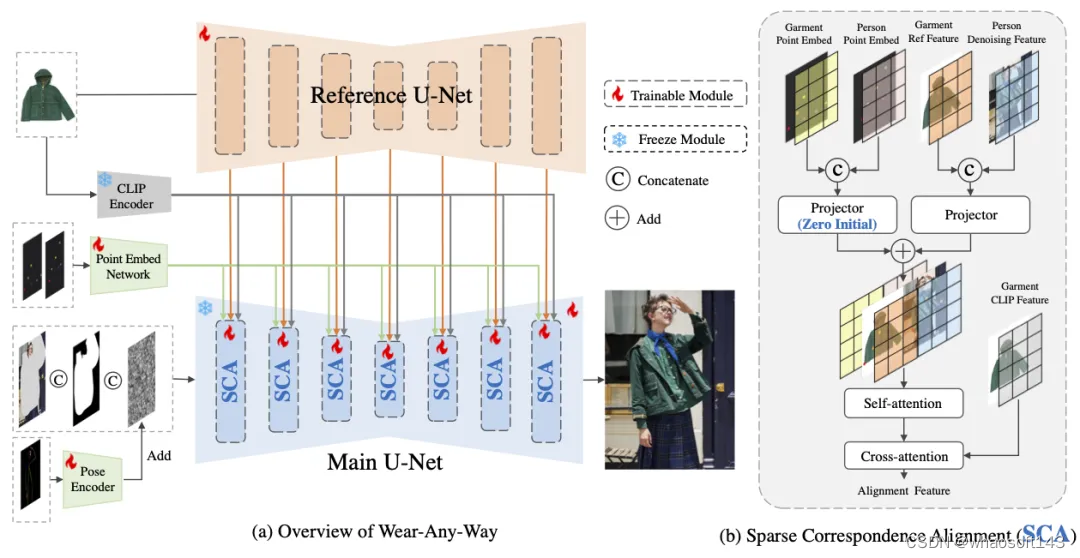
图8
1. 试衣整体流程
我们的baseline由两个分支组成。主分支是使用的是inpainting扩散模型。它以一个9通道tensor作为输入,其中包括4个通道的潜在噪声,4个通道的待试衣图像 (即,mask服装区域的人物图像),以及1个通道的二进制掩码(表示需要重绘区域)。原始的Stable Diffusion使用文本嵌入作为条件来指导扩散过程。相反,我们用由CLIP图像编码器提取的服装图像嵌入替换了文本嵌入。
CLIP图像嵌入可以保证服装的整体颜色和大致纹理,但无法很好地保留服饰细节信息。因此,我们还使用一个Reference U-Net来提取服装的细粒度特征。我们的Reference U-Net是一个标准的文本到图像的扩散模型。我们在每个block通过将主U-Net和Reference U-Net的“key”和“value”进行拼接的方式对两部分特征进行融合。
为了进一步提高生成效果,我们添加了人体姿势图作为额外的控制。我们构建了一个小型卷积网络来提取姿势图的特征,并直接将其添加到主U-Net的潜在噪声中。
2. 稀疏关系对齐模块
我们在扩散过程中引入了一种稀疏关系对齐机制。具体来说,给定成对的控制点,一个点标记在服装图像上,另一个点标记在人物图像上。我们利用这两个点之间的对应关系来控制生成结果:服装的标记位置将与人物图像上的目标位置匹配。通过这种方式,用户可以通过操作多个点对来精确控制服饰上身的状态。
如图8所示,我们首先学习一系列点的嵌入,以表示控制点对。随后,我们将这个控制信号注入到主U-Net和Reference U-Net中。这个注意力层使得从Reference U-Net提取的服装特征能够被整合到主U-Net中。为了使点引导的对应控制起作用,我们通过将模特和服装的关系点嵌入添加到“query”和“key”中对相应信息进行融合,让模型在将服装特征整合到主U-Net的同时受控于点对的对应关系,让服装的点所在的特征可以与模特图像上的点的位置对齐。因此,用户可以通过点击和拖动来控制生成结果。
3. 训练策略
为了提高模型对对应关系的学习效率,我们提出了几种优化策略。
条件drop:我们观察到,即使没有点对的指导,mask的形状和姿态图在一定程度也提供了一些状态信息。为了强制模型从控制点中学习,我们提高了放弃姿势图的概率,并增大遮罩范围,将其扩大为围绕遮罩的矩形框。
零初始化:将点嵌入添加到注意力的“key”和“value”中会导致训练优化初期的不稳定性。为了实现渐进性的融合,受到 ControlNet的启发,我们在点嵌入网络的输出处添加了一个零初始化的卷积层。这种零初始化带来了更好的收敛效果。
点加权损失:为了增强对点对的可控性,我们增加了围绕人物图像上控制点附近的损失权重。
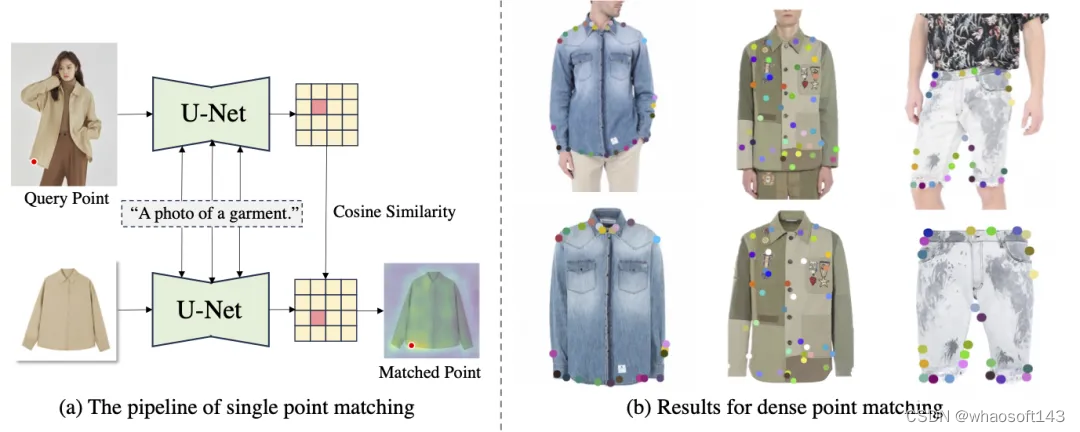
图9
4. 训练过程中对应点的收集
确保获得精确匹配的点对于上述训练是至关重要的。主要的挑战在于服装是非刚体,上身过程中服装会发生较大的形变。先前的virtual matching/correspondence learning方法只能处理像建筑物这样的刚性对象。
服饰关键点检测方法可以进行点的定位,但是它们只能检测到少量预定义的关键点,无法生成用于真正高自由度,灵活的控制。
我们利用孪生文本到图像的扩散模型分别从人物图像和服装图像中提取特征。我们采用最后一层的特征图,并在多个时间step上ensemble预测结果以获得稳定准确的匹配结果。给定人物图像上的一个点,我们选择在服装图像上具有最大余弦相似度的相应点作为对应点。匹配结果如图9所示。
实验
1. 标准试衣设置下的对比

图10
如图10所示,Wear-Any-Way 在生成质量和细节保留方面明显优于其他方案。
2. 对穿着方式的控制能力评测
 图11
图11
我们使用服饰关键点在服饰图像和模特图像(第一、第二列)上标记相应的关键点作为控制点(绿色)。同样的关键点检测模型也用于生成的结果(第三、第四列,红色)。我们计算红点和绿点之间的距离来评估控制能力。如图11所示,和不加任何控制的模型相比,Wear-Any-Way能对服饰的上身状态进行有效控制。
展望
Wear-Any-Way在虚拟试衣领域显著提升了试衣效果,对各种服饰输入形式(平铺图,模特图等)和目标模特状态(棚拍图/街拍图,站姿/坐姿)都能产出高质量的试衣结果。同时,通过其精准控制能力,可以为不同的服饰自定义不同的穿着方式,让服饰的展示状态更加贴合服饰特点和用户偏好。未来为了能进一步实现比拟专业模特的服饰展示效果,我们将进一步拓展试穿类目,同时实现对身材,风格,场景等各维度的控制能力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









