







 文章介绍了SAM-6D,一个通过给定CAD模型进行零样本6D物体姿态估计的框架,它在RGB-D图像中实现实例分割和姿态估计,并在BOP核心数据集上展示优异性能。该方法利用分割一切模型的零样本分割能力和新颖的物体匹配策略,展现出在泛化性和性能上的优势。
文章介绍了SAM-6D,一个通过给定CAD模型进行零样本6D物体姿态估计的框架,它在RGB-D图像中实现实例分割和姿态估计,并在BOP核心数据集上展示优异性能。该方法利用分割一切模型的零样本分割能力和新颖的物体匹配策略,展现出在泛化性和性能上的优势。
SAM-6D 是一个创新的零样本 6D 姿态估计框架,通过给定任意物体的 CAD 模型,实现了从 RGB-D 图像中对目标物体进行实例分割和姿态估计,并在 BOP的七个核心数据集上表现优异
物体姿态估计在许多现实世界应用中起到至关重要的作用,例如具身智能、机器人灵巧操作和增强现实等。
在这一领域中,最先受到关注的任务是实例级别 6D 姿态估计,其需要关于目标物体的带标注数据进行模型训练,使深度模型具有物体特定性,无法迁移应用到新物体上。后来研究热点逐步转向类别级别 6D 姿态估计,用于处理未见过的物体,但要求该物体属于已知的感兴趣类别。
而零样本 6D 姿态估计是一种更具泛化性的任务设置,给定任意物体的 CAD 模型,旨在场景中检测出该目标物体,并估计其 6D 姿态。尽管其具有重要意义,这种零样本的任务设置在物体检测和姿态估计方面都面临着巨大的挑战。

图 1. 零样本 6D 物体姿态估计任务示意
最近,分割一切模型 SAM [1] 备受关注,其出色的零样本分割能力令人瞩目。SAM 通过各种提示,如像素点、包围框、文本和掩膜等,实现高精度的分割,这也为零样本 6D 物体姿态估计任务提供了可靠的支撑, 展现了其前景的潜力。
因此,来自跨维智能、香港中文大学(深圳)、华南理工大学的研究人员提出了一个新颖的零样本 6D 物体姿态估计框架 SAM-6D。该论文目前已被 CVPR 2024 接受。
-
论文链接: https://arxiv.org/pdf/2311.15707.pdf
-
代码链接: https://github.com/JiehongLin/SAM-6D
SAM-6D 通过两个步骤来实现零样本 6D 物体姿态估计,包括实例分割和姿态估计。相应地,给定任意目标物体,SAM-6D 利用两个专用子网络,即实例分割模型(ISM)和姿态估计模型(PEM),来从 RGB-D 场景图像中实现目标;其中,ISM 将 SAM 作为一个优秀的起点,结合精心设计的物体匹配分数来实现对任意物体的实例分割,PEM 通过局部到局部的两阶段点集匹配过程来解决物体姿态问题。SAM-6D 的总览如图 2 所示。
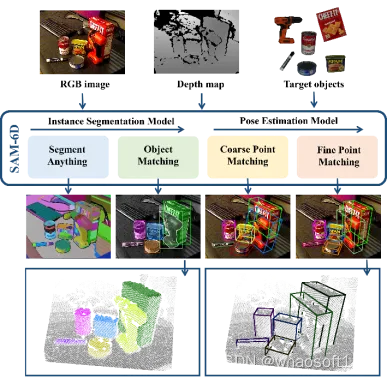
图 2. SAM-6D 总览图
总体来说,SAM-6D 的技术贡献可概括如下:
-
SAM-6D 是一个创新的零样本 6D 姿态估计框架,通过给定任意物体的 CAD 模型,实现了从 RGB-D 图像中对目标物体进行实例分割和姿态估计,并在 BOP [2] 的七个核心数据集上表现优异。
-
SAM-6D 利用分割一切模型的零样本分割能力,生成了所有可能的候选对象,并设计了一个新颖的物体匹配分数,以识别与目标物体对应的候选对象。
-
SAM-6D 将姿态估计视为一个局部到局部的点集匹配问题,采用了一个简单但有效的 Background Token 设计,并提出了一个针对任意物体的两阶段点集匹配模型;第一阶段实现粗糙的点集匹配以获得初始物体姿态,第二阶段使用一个新颖的稀疏到稠密点集变换器以进行精细点集匹配,从而对姿态进一步优化。
实例分割模型 (ISM)
SAM-6D 使用实例分割模型(ISM)来检测和分割出任意物体的掩膜。
给定一个由 RGB 图像表征的杂乱场景,ISM 利用分割一切模型(SAM)的零样本迁移能力生成所有可能的候选对象。对于每个候选对象,ISM 为其计算一个物体匹配分数,以估计其与目标物体之间在语义、外观和几何方面的匹配程度。最后通过简单设置一个匹配阈值,即可识别出与目标物体所匹配的实例。
物体匹配分数的计算通过三个匹配项的加权求和得到:
语义匹配项 —— 针对目标物体,ISM 渲染了多个视角下的物体模板,并利用 DINOv2 [3] 预训练的 ViT 模型提取候选对象和物体模板的语义特征,计算它们之间的相关性分数。对前 K 个最高的分数进行平均即可得到语义匹配项分数,而最高相关性分数对应的物体模板视为最匹配模板。
外观匹配项 —— 对于最匹配模板,利用 ViT 模型提取图像块特征,并计算其与候选对象的块特征之间的相关性,从而获得外观匹配项分数,用于区分语义相似但外观不同的物体。
几何匹配项 —— 鉴于不同物体的形状和大小差异等因素,ISM 还设计了几何匹配项分数。最匹配模板对应的旋转与候选对象点云的平均值可以给出粗略的物体姿态,利用该姿态对物体 CAD 模型进行刚性变换并投影可以得到边界框。计算该边界框与候选边界框的交并比(IoU)则可得几何匹配项分数。
姿态估计模型 (PEM)
对于每个与目标物体匹配的候选对象,SAM-6D 利用姿态估计模型(PEM)来预测其相对于物体 CAD 模型的 6D 姿态。

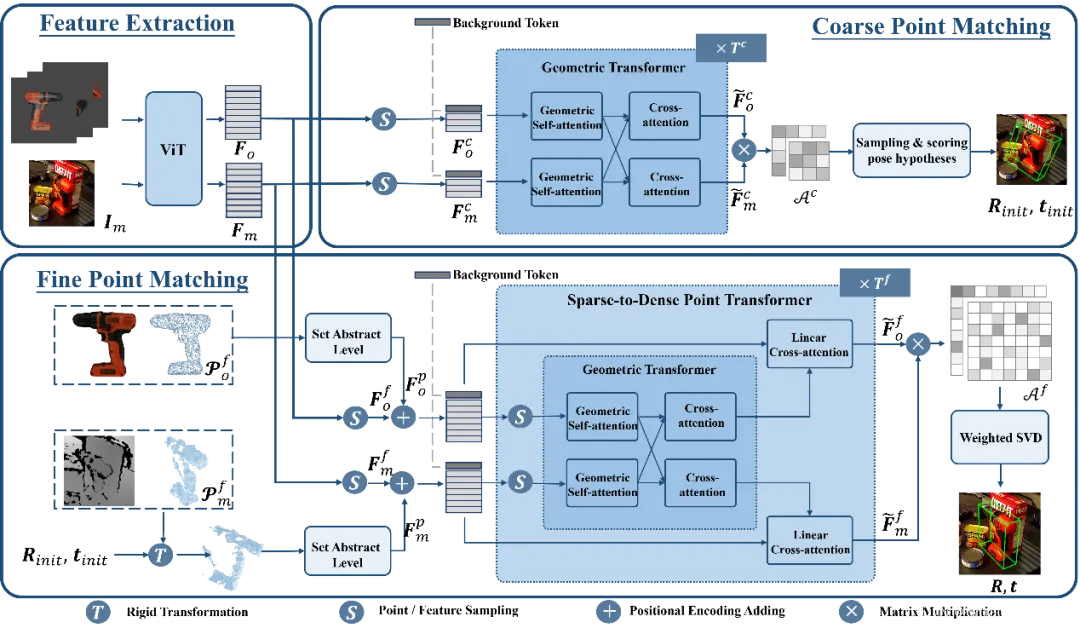
图 3. SAM-6D 中姿态估计模型 (PEM) 的示意图
利用上述基于 Background Token 的策略,PEM 中设计了两个点集匹配阶段,其模型结构如图 3 所示,包含了特征提取、粗略点集匹配和精细点集匹配三个模块。
粗糙点集匹配模块实现稀疏对应关系,以计算初始物体姿态,随后利用该姿态来对候选对象的点集进行变换,从而实现位置编码的学习。
精细点集匹配模块结合候选对象和目标物体的采样点集的位置编码,从而注入第一阶段的粗糙对应关系,并进一步建立密集对应关系以得到更精确的物体姿态。为了在这一阶段有效地学习密集交互,PEM 引入了一个新颖的稀疏到稠密点集变换器,它实现在密集特征的稀疏版本上的交互,并利用 Linear Transformer [5] 将增强后的稀疏特征扩散回密集特征。
实验结果
对于 SAM-6D 的两个子模型,实例分割模型(ISM)是基于 SAM 构建而成的,无需进行网络的重新训练和 finetune,而姿态估计模型(PEM)则利用 MegaPose [4] 提供的大规模 ShapeNet-Objects 和 Google-Scanned-Objects 合成数据集进行训练。
为验证其零样本能力,SAM-6D 在 BOP [2] 的七个核心数据集上进行了测试,包括了 LM-O,T-LESS,TUD-L,IC-BIN,ITODD,HB 和 YCB-V。表 1 和表 2 分别展示了不同方法在这七个数据集上的实例分割和姿态估计结果的比较。相较于其他方法,SAM-6D 在两个方法上的表现均十分优异,充分展现其强大的泛化能力。 whaosoft aiot http://143ai.com
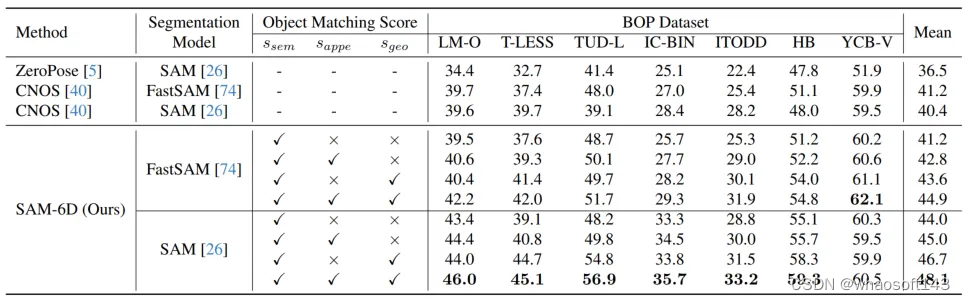
表 1. 不同方法在 BOP 七个核心数据集上的实例分割结果比较
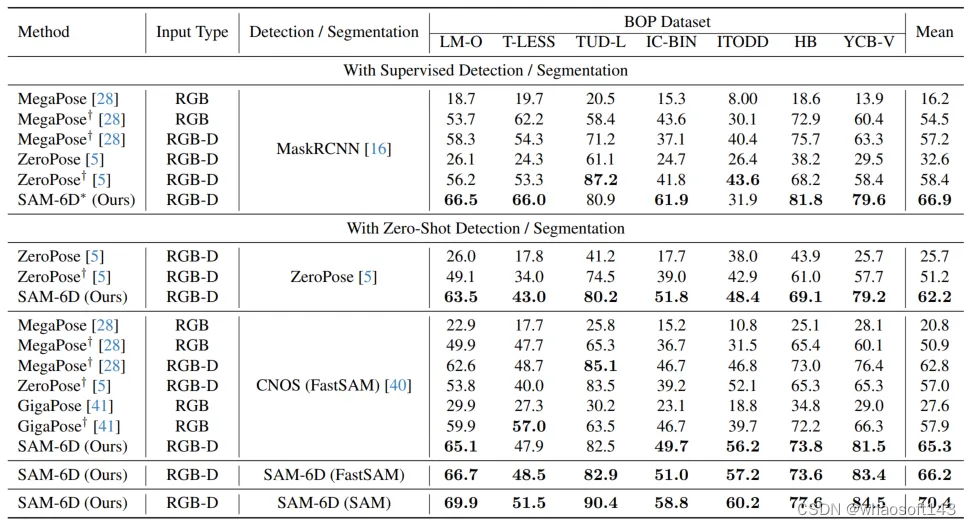
表 2. 不同方法在 BOP 七个核心数据集上的姿态估计结果比较
图 4 展示了 SAM-6D 在 BOP 七个数据集上的检测分割以及 6D 姿态估计的可视化结果,其中 (a) 和 (b) 分别为测试的 RGB 图像和深度图,(c) 为给定的目标物体,而 (d) 和 (e) 则分别为检测分割和 6D 姿态的可视化结果。

图 4. SAM-6D 在 BOP 的七个核心数据集上的可视化结果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









