







本文提出了大视觉模型 AIM。AIM 是属于受到大语言模型 LLM 的启发,使用自回归训练策略来训练大视觉模型的方法。AIM 和 LLM 一样展示出了缩放能力,AIM 的预训练也类似于 LLM 的预训练。
本文的首发日期是 2024.01,也属于大视觉模型的开山之作行列,与上文 "CVPR 2024|大视觉模型的开山之作!无需任何语言数据即可打造大视觉模型"讲到的 LVM 属于同期工作。
本文提出了大视觉模型 AIM。AIM 是属于受到大语言模型 LLM 的启发,使用自回归训练策略来训练大视觉模型的方法。AIM 和 LLM 一样展示出了缩放能力,AIM 的预训练也类似于 LLM 的预训练。本文的关键发现是两点:
-
视觉模型提取的特征的质量随模型容量和数据量的增加而增加。
-
训练的目标函数的值与模型在下游任务的性能有关。
本文作者在 2B 张图片上训练了 7B 参数的 AIM 模型,在 ImageNet-1K 上面得到了 84.0% 的性能。而且有趣的是,即使在这个尺度上,仍然没有观察到性能饱和的迹象。
本文工作
提出大视觉模型 Autoregressive Image Models (AIM):自回归预训练 + Vision Transformer
技术细节1 (对 ViT 的改进):不像 LLM 一样使用精确的 Casual Self-attention,而是像 T5[1] 一样使用 Prefix Attention。(注意:这里就不再是真正的 Casual Transformer 了,准确讲应该叫 Prefix Transformer)
效果:使得 AIM 模型得以在下游任务时转成类似于 ViT 的 Bi-directional Self-attention。
技术细节2 (对 Prediction head 的改进):受对比学习 prediction head 的启发,使用一个参数量较大的 prediction head。
效果:使得 AIM 模型学到的特征得到很大改善,与此同时只在训练阶段增加少量开销。
最终效果:
AIM 的训练类似于 LLM 的训练,同时无需 ViT-22B, CaiT 模型中提出的稳定训练的技术。AIM 的模型大小范围从 600M 到 7B,使用 2B 图像数据集来训练。
图1是最终实现的缩放效果:
-
模型容量增加时:validation loss 下降,下游任务的精度提升。
-
训练数据量增加时 (指数级):下游任务的精度提升。
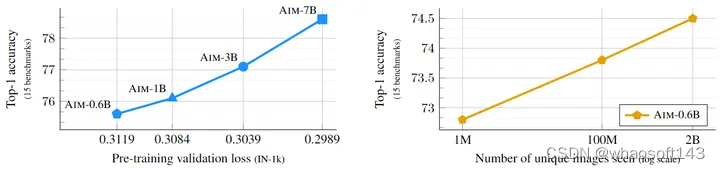
图1:AIM 模型最终实现的缩放效果
以上缩放效果与 LLM 结论一致。
1 大视觉模型的自回归预训练
论文名称:Scalable Pre-training of Large Autoregressive Image Models (Arxiv 24.01)
论文地址:https//arxiv.org/pdf/2401.08541.pdf
代码地址:https//github.com/apple/ml-aim
-
1 AIM 论文解读:
1.1 自回归预训练的大视觉模型会不会像 LLM 一样有缩放性质?
大语言模型 (LLM) 的革命性发展使得与任务无关的预训练成为自然语言处理任务的主流。大语言模型可以解决复杂的推理任务,遵从人类的指令,并且成为人工智能助手。LLM 成功的一个非常关键的因素是:随着模型容量和数据量的扩增,带来的模型能力的持续提升。
为什么大语言模型具有缩放性质?作者提出以下2点原因:
-
即使这些模型只使用最简单的目标函数进行 Next Token Prediction 的自回归预训练,它们也可以在复杂的上下文中学习到复杂的范式。
-
大语言模型的缩放性质是一些工作在 Transformer 架构中发现的,这也暗示了自回归预训练与 Transformer 架构之间的协同关系。
既然大语言模型具有缩放性质,那么大视觉模型有没有呢?
要思考这个问题,首先思考 LLM 的一些特质:自回归预训练,Transformer。
自回归预训练的范式在数据压缩领域[2]生根发芽,相似的方法也在音频[3]和图像[4]领域诞生。
Transformer 在视觉领域应用的工作就更多了,典型的比如 ViT[5]。
因此,似乎 LLM 的特质,即自回归预训练和 Transformer 都不是阻碍其在视觉领域奏效的主要原因。
所以本文探索的是:自回归预训练和 Transformer 可否适用于视觉模型,即 LLM 的缩放性能是否依然在视觉领域里奏效。
1.2 AIM 预训练数据集
AIM 预训练数据集使用的是 DFN[6]。该数据集是基于 12.8B 的图文对 DataComp。
-
从 Common Crawl 过滤得到。
-
数据预处理环节去除了 NSFW 内容,模糊人脸,并通过对评估集进行重复数据删除来减少污染。
-
使用 data filtering network 根据图像与其对应描述的分数进行排名。
-
保留前 15% 的样本,从 DataComp 12.8B 数据集中提取了 2B 图像的子集,称为 DFN2B。
注意,除了隐私和安全过滤器之外,此过程不包括任何基于图像内容的额外管理。
由于 AIM 模型的预训练过程不需要文本,因此 AIM 模型可以使用非配对的更大的图像数据集进行训练,也可以使用图文对应分数不那么好的其他数据来训练。

1.3 AIM 自回归的训练目标


1.4 AIM 模型架构
预训练时期 (Prefix Transformer,和 NLP 中的 T5 模型类似)
AIM 模型使用 ViT + Prefix Mask Self-Attention,不同容量的模型的配置如下图2所示。
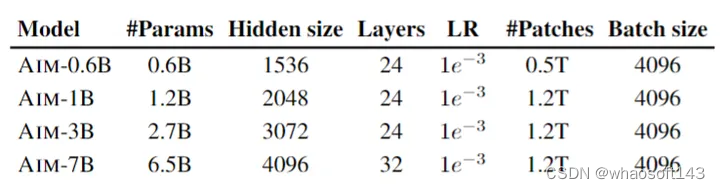
图2:AIM 模型配置
AIM 模型架构如下图3所示。
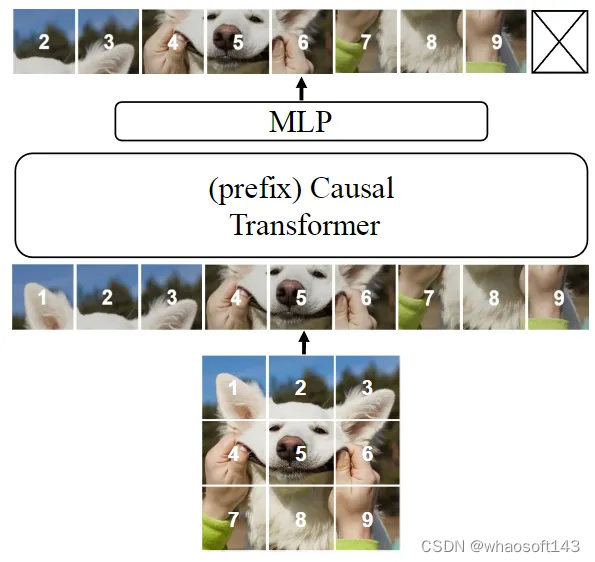
图3:AIM 的模型架构
在预训练时期,对 Self-Attention 进行 Casual Mask。本来在 Self-Attention 中,对于 Embedding 的计算方式是:

技术细节1 (对 ViT 的改进):
但是,作者在这里认为 Casual Mask 会影响下游任务的质量,因此像 T5[1] 一样使用 Prefix Attention。(注意:这里就不再是真正的 Casual Transformer 了,准确讲应该叫 Prefix Transformer)。
AIM 模型在自回归预训练和下游任务时的 Self-Attention 的架构。AIM 模型在自回归预训练时是一个 Prefix Transformer,和 T5 类似:

这种修改有助于模型在没有 Casual Mask 的情况下工作,使其能够在下游适应期间被去除。这种方法提高了模型在下游任务中的性能。
AIM 模型在下游任务推理时是 Bi-directional Transformer,和 ViT 一致。
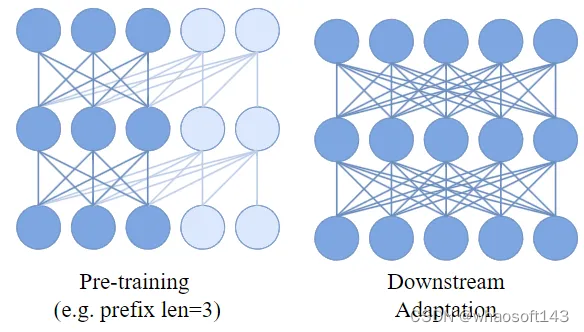
图4:AIM 模型在自回归预训练和下游任务时的 Self-Attention 的架构。AIM 模型在自回归预训练时是一个 Prefix Transformer,和 T5 类似。在下游任务时是 Bi-directional Transformer,和 ViT 一致
技术细节2 (对 Prediction head 的改进):

下游任务迁移学习时期 (Bi-directional Transformer,和 CV 中的 ViT 模型类似)
在下游任务期间,所有模型权重都固定,只训练一个分类头。

1.5 AIM 模型的缩放性质结果
如下图5所示是随着预训练过程的进行,validation loss 的值与下游任务 ImageNet-1K 精度的变化。而且,随着模型容量的增加,validation loss 和 ImageNet-1K 的性能都会改善,这一结果与 LLM 中观察到的趋势一致。 whaosoft aiot http://143ai.com
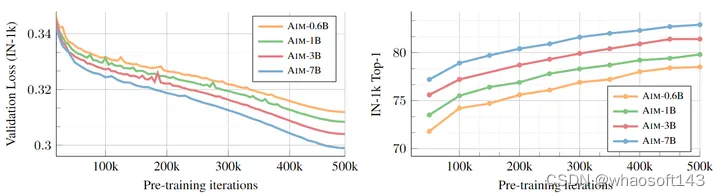
图5:模型容量和训练长度对于预训练的影响。随着 AIM 模型容量的增加,预训练目标的性能有了明显的提高。此外,下游任务的性能 (IN-1K) 也会随着模型容量的增加和训练时长的增加而改善
下图6表示在 1M 图像的小数据集 (IN-1k) 或更大的 2B 图像集 (即 DFN-2B+) 上进行预训练时,验证集的损失。由于验证集也是 IN-1K,所以以它自己作为预训练数据集得到的 validation loss 比较低也就不足为奇了。然而,validation loss 在训练结束时会恶化,这表明对训练数据的过拟合。
当预训练数据集换成更大的 DFN-2B 时,没有出现过拟合的迹象。当相同的数据集用少量 IN-1K 数据增强,即预训练的数据集变为 DFN-2B+ 时,最终超过 IN-1K 预训练的性能。
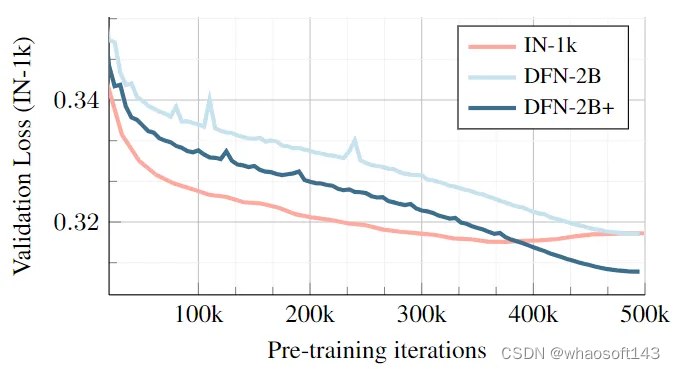
图6:数据集规模对于预训练的影响
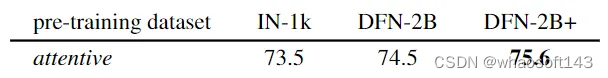
图7:在15个 benchmark 上得到的数据集规模对于预训练的影响
如下图8所示,作者研究了将预训练的长度从 500k 增加到 1.2M iteration 的影响,即训练过程中见到的数据从 2B 到 5B 大小。可以观察到,通过增加模型容量,或者增加预训练的数据集数量,都可以降低 validation loss,从而提高 AIM 模型的性能。值得一提的是,当总的 FLOPs 一致时,大一点的模型 + 小一点的数据集训练出的模型效果与小一点的模型 + 大一点的数据集训练出的模型效果接近。
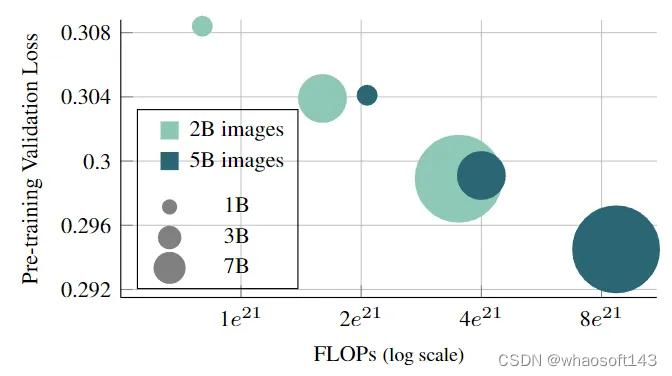
图8:FLOPs 对于预训练的影响
1.6 消融实验结果
自回归范式的影响
作者还对比了不同的自回归范式,如下图9所示。自回归预训练通常遵循特定的遍历顺序,以促进下一个标记的预测。在语言的情况下,因为语言是天然有序的,因此自回归的范式很清晰。但是对于无序的图像来讲,自回归的范式就是无序的了。因此作者探索了图9的各种范式:Raster,Spiral,Checkerboard 等等。

图9:不同自回归范式的结果
Self-attention 方法的影响
作者还对比了不同 attention 方法的结果,如图10所示。使用 Casual Self-attention 做预训练时,推理时只有保留 Casual Self-attention,才会有效,否则使用 Bi-directional Self-attention 时模型无效了。但是,当使用 Prefix Self-attention 做预训练时,推理时无论是使用 Casual Self-attention,还是使用 Bi-directional Self-attention 时模型都有效。

图10:不同 attention 方法的结果
Head 设计的影响
如下图11所示为使用不同的 Head 实现的结果。不使用任何 Head 得到的结果还不错,但是添加一个简单的 MLP 进一步提升了模型特征的质量。有趣的是,将 MLP 替换为更加复杂的 Transformer 层得到的改进微不足道,但是计算成本却高了不少。因此,作者最终选择一个 MLP 作为 Head,并假设 Head 专门用于捕获像素级别预测所需要的低级信息。通过引入 Head,主干模型可以学习到更适合迁移到下游任务的更高级别的特征。
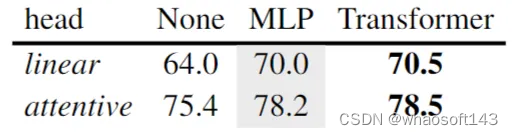
图11:不同 Head 方法的结果
作者又在下图12中讨论了 MLP 具体的配置对模型性能的影响。默认的 MLP 使用 12 层,维度是 2048。通过深度或宽度增加 MLP 的容量会导致下游性能的持续改进。有趣的是,作者并没有找到 MLP 容量的增加使得性能饱和的这个饱和点。但作者也没有继续寻找,因为这会带来 Head 的容量与主干模型不成比例。
 图12:MLP 具体配置的影响
图12:MLP 具体配置的影响
Attentive Probe 还是 Linear Probe
Attentive Probe 和 Linear Probe 都是适配下游任务的方式,作者观察到,在所有的实验中,Attentive Probe 的性能都更好。因为它允许细微的局部特征通过聚合,规避了自监督学习缺乏全局描述符的缺点。
更深还是更宽的网络
与 ViT 不同,本文采用的是 LLaMA 的缩放策略,结果如下图13所示。可以看到,更宽的架构不仅性能更强,而且训练更加稳定。

图13:更宽的架构不仅性能更强,而且训练更加稳定
与其他自监督方法的比较
如下图14所示是 AIM 与其他自监督方法在 15 个图像分类 benchmark 上比较的结果。AIM 相比于生成式方法 MAE, BEiT,以及对比学习式方法 DINO, DINOv2 等展示出了更好的性能。
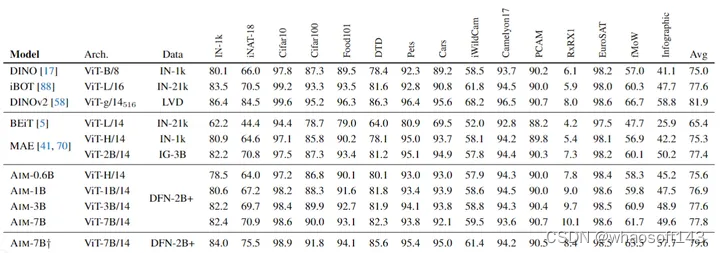
图14:AIM 在15个图像分类 Benchmark 的结果


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









