







Taobao 开发板商城 whaosoft aiot http://143ai.com 天皓智联 自动驾驶合集
# 自动驾驶第一性之纯视觉静态重建
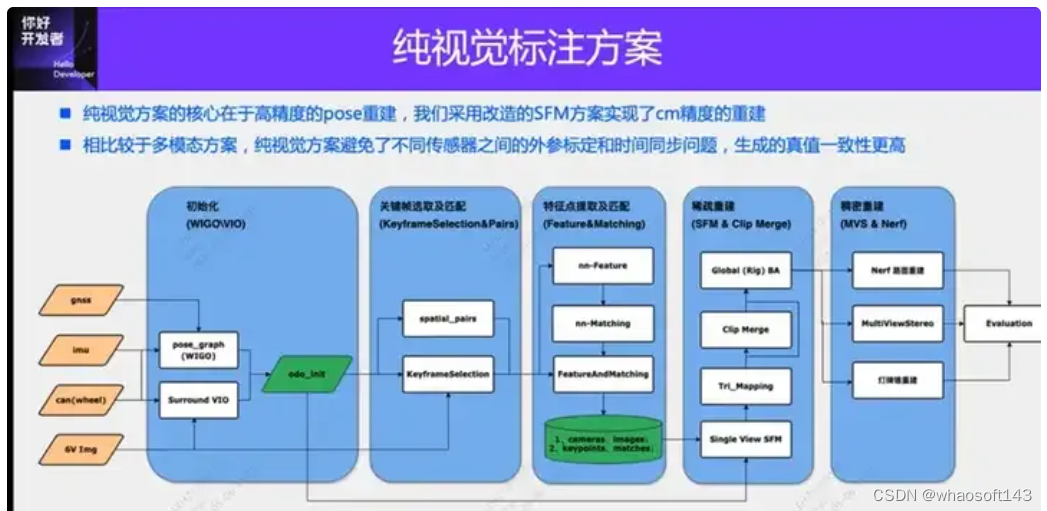
纯视觉的标注方案,主要是利用视觉加上一些GPS、IMU和轮速计传感器的数据进行动静态标注。当然面向量产场景的话,不一定非要是纯视觉,有一些量产的车辆里面,会有像固态雷达(AT128)这样的传感器。如果从量产的角度做数据闭环,把这些传感器都用上,可以有效地解决动态物体的标注问题。但是我们的方案里面,是没有固态雷达的。所以,我们就介绍这种最通用的量产标注方案。
纯视觉的标注方案的核心在于高精度的pose重建。我们采用Structure from motion (SFM) 的pose重建方案,来保证重建精度。但是传统的SFM,尤其是增量式的SFM,效率非常慢,计算复杂度是O(n^4),n是图像的数量。这种重建的效率,对于大规模的数据标注,是没有办法接受的,我们对SFM的方案进行了一些改进。
改进后的clip重建主要分为三个模块:1)利用多传感器的数据,GNSS、IMU和轮速计,构建pose_graph优化,得到初始的pose,这个算法我们称为Wheel-Imu-GNSS-Odometry (WIGO);2)图像进行特征提取和匹配,并直接利用初始化的pose进行三角化,得到初始的3D点;3)最后进行一次全局的BA(Bundle Adjustment)。我们的方案一方面避免了增量式SFM,另一方面不同的clip之间可以实现并行运算,从而大幅度的提升了pose重建的效率,比起现有的增量式的重建,可以实现10到20倍的效率提升。
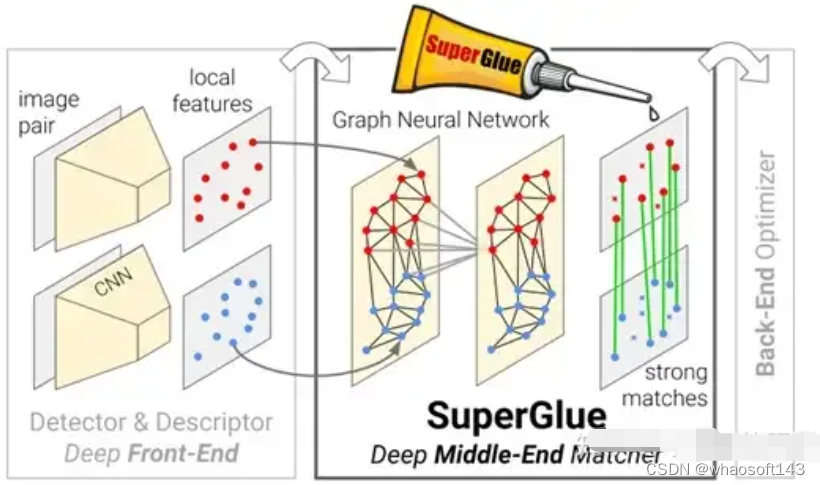
在单次重建的过程中,我们的方案也做了一些优化。例如我们采用了Learning based features(Superpoint和Superglue),一个是特征点,一个是匹配方式,来替代传统的SIFT关键点。用学习NN-Features的优势就在于,一方面可以根据数据驱动的方式去设计规则,满足一些定制化的需求,提升在一些弱纹理以及暗光照的情况下的鲁棒性;另一方面可以提升关键点检测和匹配的效率。我们做了一些对比的实验,在夜晚场景下NN-features的成功率会比SFIT提升大概4倍,从20%提升至80%。
得到单个Clip的重建结果之后,我们会进行多个clips的聚合。与现有的HDmap建图采用矢量结构匹配的方案不同,为了保证聚合的精度,我们采用特征点级别的聚合,也就是通过特征点的匹配进行clip之间的聚合约束。这个操作类似于SLAM中的回环检测,首先采用GPS来确定一些候选的匹配帧;之后,利用特征点以及描述进行图像之间的匹配;最后,结合这些回环约束,构造全局的BA(Bundle Adjustment)并进行优化。目前我们这套方案的精度,RTE指标远超于现在的一些视觉SLAM或者建图方案。
实验:采用colmap cuda版,使用180张图,3848* 2168分辨率,手动设置内参,其余使用默认设置,sparse重建耗时约15min,整个dense重建耗时极长(1-2h)

重建结果统计
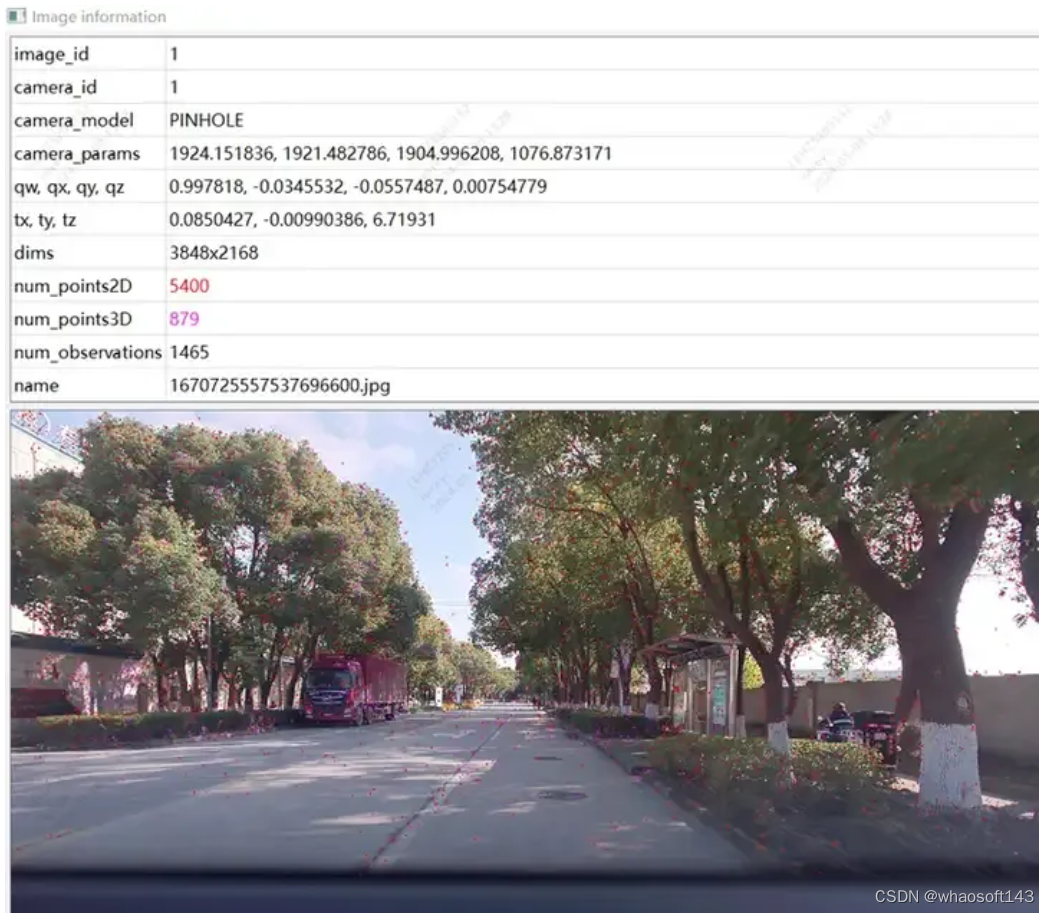
特征点示意图

sparse重建效果

直行路段整体效果
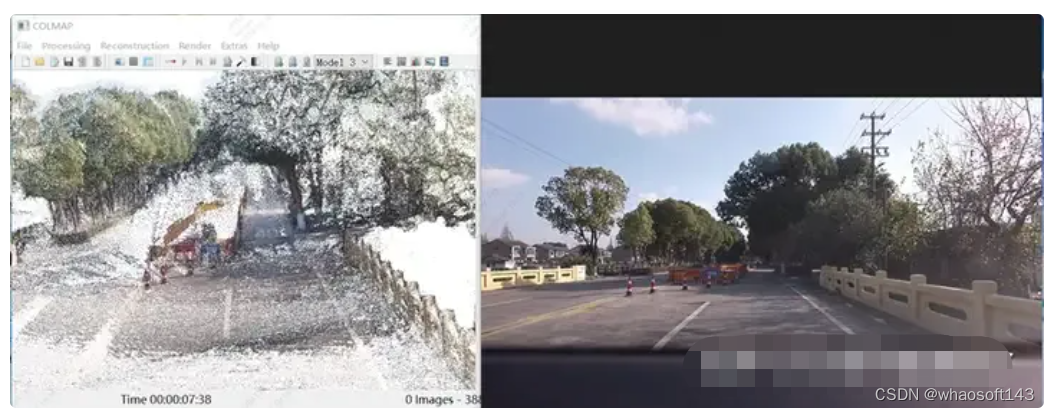
地面锥桶效果

高处限速牌效果

路口斑马线效果
@@@
l 容易不收敛,另外试了一组图像就没有收敛:静止ego过滤,根据自车运动每50-100m形成一个clip;高动态场景动态点滤除、隧道场景位姿 whaosoft aiot http://143ai.com
l 利用周视和环视多摄像头:特征点匹配图优化、内外参优化项
l 利用已有的odom
l https://github.com/colmap/colmap/blob/main/pycolmap/custom_bundle_adjustment.py
l pyceres.solve(solver_options, bundle_adjuster.problem, summary)
l 3DGS加速密集重建,否则时间太长无法接受
l
@@@
参考资料:
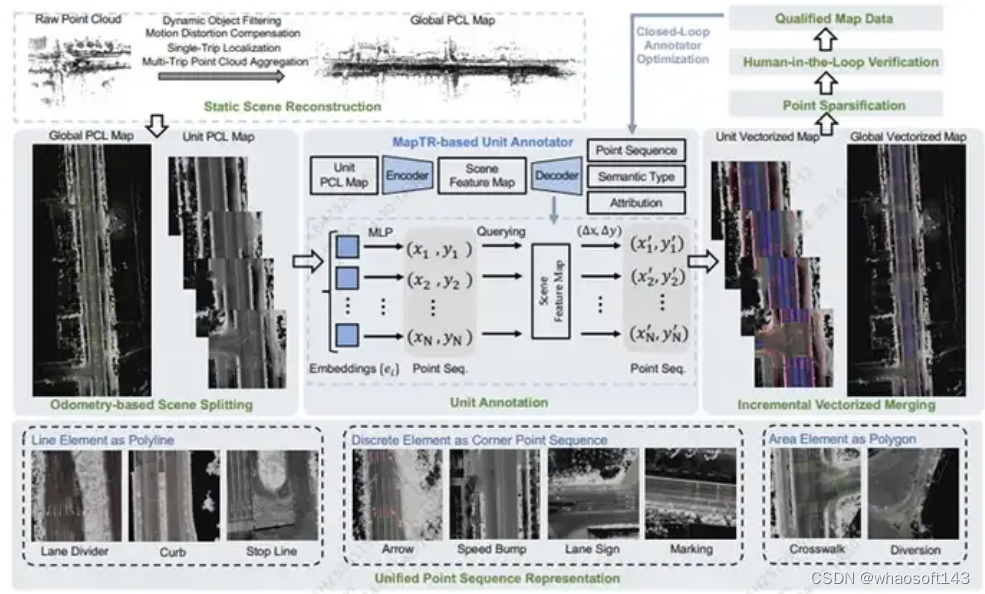
A Vision-Centric Approach for Static Map Element Annotation
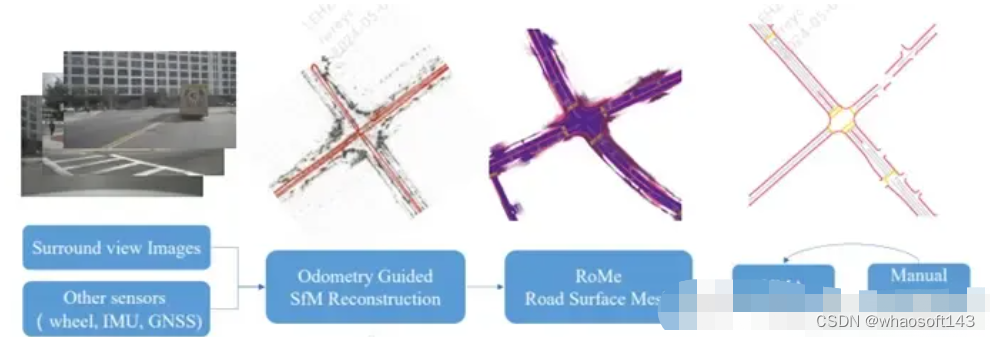
VRSO: Visual-Centric Reconstruction for Static Object Annotation
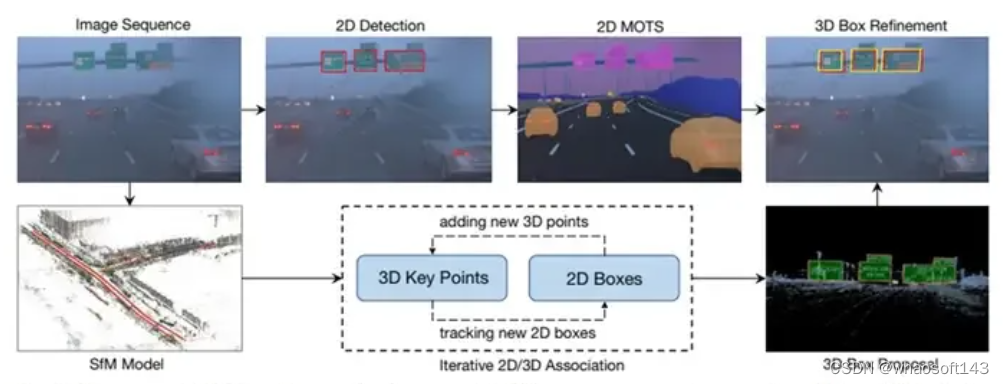
VMA: Divide-and-Conquer Vectorized Map Annotation System for Large-Scale Driving Scene
https://github.com/Xbbei/super-colmap
https://github.com/magicleap/SuperGluePretrainedNetwork
对于调参人员来说:
(1)为什么colmap如此慢?
如果你的数据是车载数据即forward motion,那么其实local ba 足够,不需要太频繁的global ba(众所周知ba的复杂度是(camera_params+6N+3n)^3,因为每次新加入的图像主要和其周围的地图有关系。所以调整mapper以下参数即可:
i.减少ba_global_max_refinements次数 (5改为1)
ii.增大模型增大到一定比例触发global ba的参数
Mapper.ba_global_images_ratio 、 Mapper.ba_global_points_ratio 、Mapper.ba_global_images_freq
(2)为什么车载数据就跑了两帧程序就终止?如果你的数据质量不佳或者是车载数据,车载数据是比较困难处理的,因为baseline短且图像两边的特征消失的很快,这个时候采用默认参数去跑,通常会出现初始化完后就终止了程序,这个时候就要调小初始最小三角化角度Mapper.init_min_tri_angle(默认16调成5)。
对于研究源码的人员来说,colmap的improved方面数不胜数,离一个可用的状态需要做很多的工作:
(1)关于相机模型的选择,在处理数据的时候,如果相机模型选择简单的,会造成欠拟合,出现blend map之类的现象,如果选择复杂的相机模型就会出现不收敛的情况。
(2)关于匹配方面,colmap中匹配有词汇树匹配方法,但是deep learning的方法已经完全超越BOW,如可以用netvlad、cosplace近几年的方法来替换传统的检索方式。
(3)关于view graph,特征检测和匹配完后,会生成view graph,这时候并不是一股脑就去sfm,view graph 的优化既可以减少冗余,也可以改善整个网形,提升sfm的鲁棒性。
图5.view graph
(4)关于dirft问题,控制点(GCP)/gps约束都可以很好的改善,这个问题已经在三年前colmap课程中讲过,当然在加入外部约束的时候,less is more的约束同时也会增添不少风采,如sift的feature scale 定权可以很明显的降低误差,如图6:
图6.左边是feature sclae和右边没有feature scale
(5)关于colmap 慢的问题,这便是pipeline的问题,采用分组sfm便可解决,整个过程是:view graph 聚类分组-->每个组内 local sfm --> local sfm merge 。做好分组sfm的基本是local sfm 足够的鲁棒。
图7.vismap 11095张鱼眼sfm结果(不同颜色代表分组)
(6)关于colmap 鲁棒性方面,对于forword motion数据,p3p/pnp的效果并不一定好,这个时候采用hybird方式不免是一种明智的做法,流程是:先rotation averaging 然后采用p2p解算pose,具体参见HSfM: Hybrid Structure-from-Motion(崔海楠)的工作。初次之外,也可以在rotation averaging后,利用得到全局rotation 和pnp解算的r进行约束,也就是除了重投影误差,还有图像对之间Rotation的惩罚项。
(7)关于colmap sfm的评判机制/标准,目前所有的论文最终评判sfm的metric都是:track length、重投影误差、3D点个数、每张影响的2D点个数,但是重投影误差是无意义的,即使重投影误差很小,sfm也会出现dirft,因为3D点是源于pose和匹配点,Pose dirft会造成3D点不是"真",那么投影回来误差自然也不会大,所以选择一个合理的metric是值得思考的。

# 基础模型对于推动自动驾驶的重要作用
近年来,随着深度学习技术的发展和突破,大规模的基础模型(Foundation Models)在自然语言处理和计算机视觉领域取得了显著性的成果。基础模型在自动驾驶当中的应用也有很大的发展前景,可以提高对于场景的理解和推理。
-
通过对丰富的语言和视觉数据进行预训练,基础模型可以理解和解释自动驾驶场景中的各类元素并进行推理,为驾驶决策和规划提供语言和动作命令。
-
基础模型可以根据对驾驶场景的理解来实现数据增强,用于提供在常规驾驶和数据收集期间不太可能遇到的长尾分布中那些罕见的可行场景以实现提高自动驾驶系统准确性和可靠性的目的。
-
对基础模型应用的另外一个场景是在于世界模型,该模型展示了理解物理定律和动态事物的能力。通过采用自监督的学习范式对海量数据进行学习,世界模型可以生成不可见但是可信的驾驶场景,促进对于动态物体行为预测的增强以及驾驶策略的离线训练过程。
本文主要概述了基础模型在自动驾驶领域中的应用,并根据基础模型在自动驾驶模型方面的应用、基础模型在数据增强方面的应用以及基础模型中世界模型对于自动驾驶方面的应用三方面进行展开。
本文链接:https://arxiv.org/pdf/2405.02288
自动驾驶模型
基于语言和视觉基础模型的类人驾驶
在自动驾驶中,语言和视觉的基础模型显示出了巨大的应用潜力,通过增强自动驾驶模型在驾驶场景中的理解和推理,实现自动驾驶的类人驾驶。下图展示了基于语言和视觉的基础模型对驾驶场景的理解以及给出语言引导指令和驾驶行为的推理。
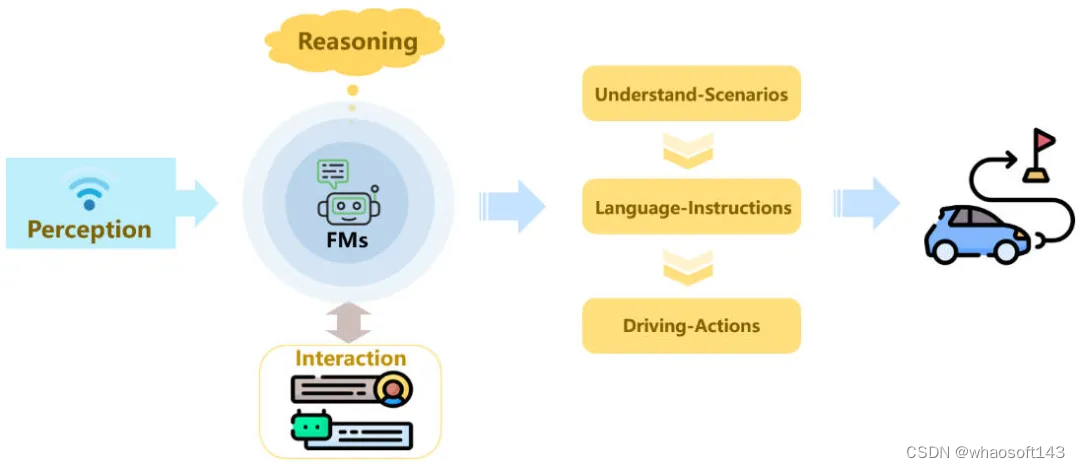
基础模型对于自动驾驶模型增强范式
目前很多工作都已经证明语言和视觉特征可以有效增强模型对于驾驶场景的理解,再获取到对于当前环境的整体感知理解后,基础模型就会给出一系列的语言命令,如:“前方有红灯,减速慢行”,“前方有十字路口,关注行人”等相关语言指令,便于自动驾驶汽车根据相关的语言指令执行最终的驾驶行为。
最近,学术界和工业界将GPT的语言知识嵌入到自动驾驶的决策过程中,以语言命令的形式提高自动驾驶的性能,以促进大模型自动驾驶中的应用。考虑到大模型有望真正部署在车辆端,它最终需要落在规划或控制指令上,基础模型最终应该从动作状态级别授权自动驾驶。一些学者已经进行了初步探索,但仍有很多发展空间。更重要的是,一些学者通过类似GPT的方法探索了自动驾驶模型的构建,该方法直接输出基于大规模语言模型的轨迹甚至控制命令,相关工作已经汇总在如下表格中。
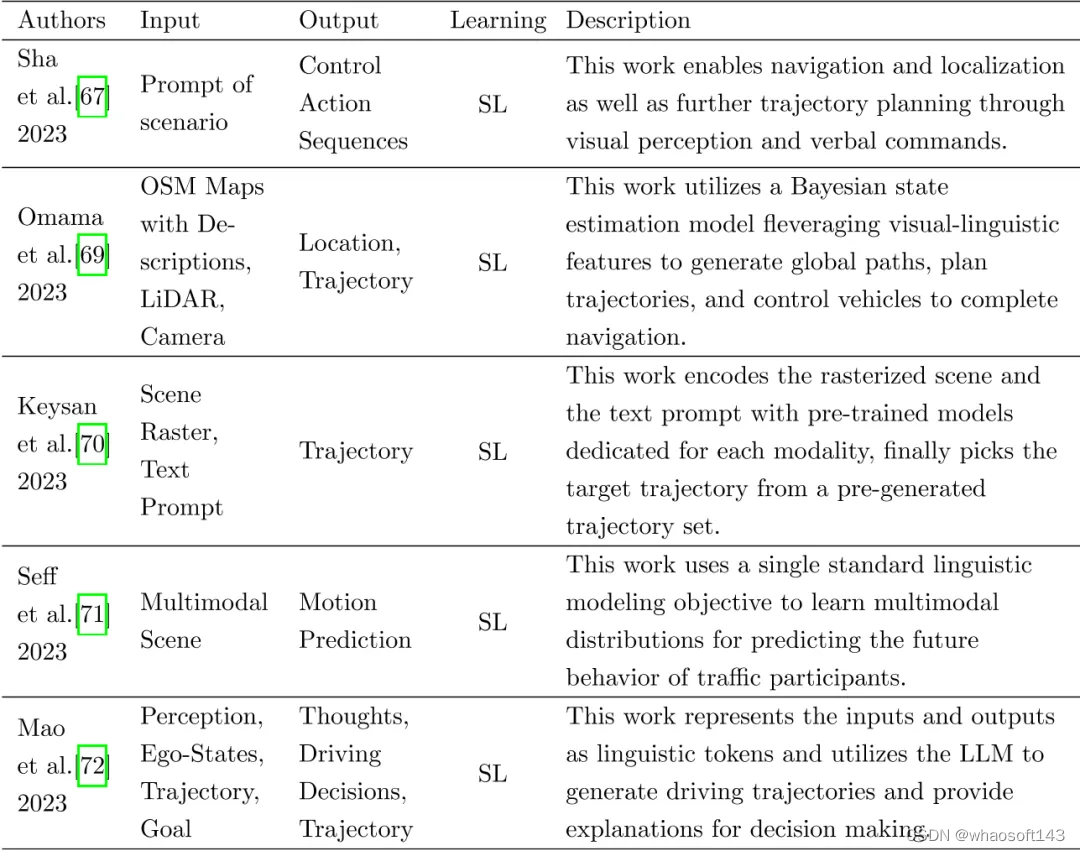
使用预训练主干网络进行端到端自动驾驶
上述的相关内容其核心思路是提高自动驾驶决策的可解释性,增强场景理解,指导自动驾驶系统的规划或控制。在过去的一段时间内,有许多工作一直以各种方式优化预训练主干网络,也有许多研究尝试开发基于Transformer架构的端到端框架,并且取得了非常不错的成绩。因此,为了更加全面的总结基础模型在自动驾驶中的应用,我们对预训练主干的端到端自动驾驶相关研究进行了总结和回顾。下图展示了端到端自动驾驶的整体过程。
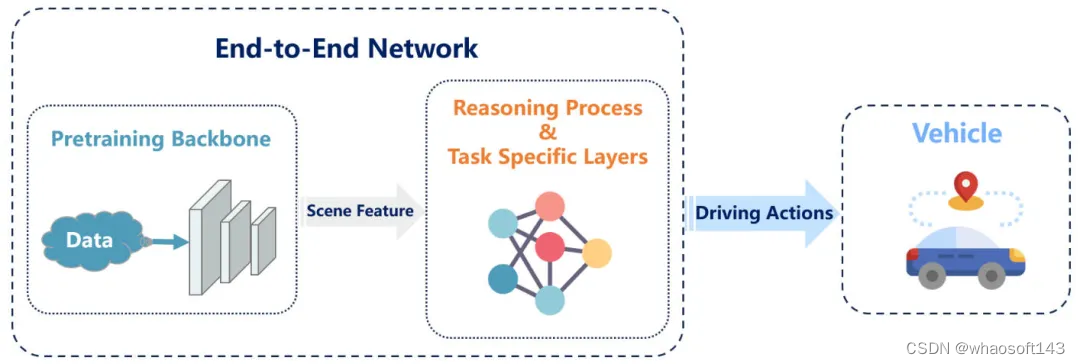
基于预训练主干网络的端到端自动驾驶系统的流程图
在端到端自动驾驶的整体流程中,从原始数据中提取低级信息在一定程度上决定了后续模型性能的潜力,优秀的预训练骨干可以使模型具有更强的特征学习能力。ResNet和VGG等预训练卷积网络是端到端模型视觉特征提取应用最广泛的主干网络。这些预训练网络通常利用目标检测或分割作为提取广义特征的任务进行训练,并且他们所取得的性能已经在很多工作中得到了验证。
此外,早期的端到端自动驾驶模型主要是基于各种类型的卷积神经网络,通过模仿学习或者强化学习的方式来完成。最近的一些工作试图建立一个具有Transformer网络结构的端到端自动驾驶系统,并且同样取得了比较不错的成绩,比如Transfuser、FusionAD、UniAD等工作。
数据增强
随着深度学习技术的进一步发展,底层网络架构的进一步完善和升级,具有预训练和微调的基础模型已经展现出了越来越强大的性能。由GPT代表的基础模型已经使得大模型从学习范式的规则向数据驱动的方式进行转换。数据作为模型学习关键环节的重要性是无可替代的。在自动驾驶模型的训练和测试过程中,大量的场景数据被用来使模型能够对各种道路和交通场景具有良好的理解和决策能力。自动驾驶面临的长尾问题也是这样一种事实,即存在无穷无尽的未知边缘场景,使模型的泛化能力似乎永远不足,导致性能较差。
数据增强对于提高自动驾驶模型的泛化能力至关重要。数据增强的实现需要考虑两个方面
-
一方面:如何获取大规模的数据,使提供给自动驾驶模型的数据具有足够的多样性和广泛性
-
另一方面:如何获取尽可能多的高质量数据,使用于训练和测试自动驾驶模型的数据准确可靠
所以,相关的研究工作主要从以上两个方面开展相关的技术研究,一是丰富现有的数据集中的数据内容,增强驾驶场景中的数据特征。二是通过模拟的方式生成多层次的驾驶场景。
扩展自动驾驶数据集
现有的自动驾驶数据集主要是通过记录传感器数据然后标记数据来获得的。通过这种方式获得的数据特征通常是很低级的,同时数据集的量级也是比较差,这对于自动驾驶场景的视觉特征空间是完全不够的。语言模型表示的基础模型在高级语义理解、推理和解释能力为自动驾驶数据集的丰富和扩展提供了新的思路和技术途径。通过利用基础模型的高级理解、推理和解释能力来扩展数据集可以帮助更好地评估自动驾驶系统的可解释性和控制,从而提高自动驾驶系统的安全性和可靠性。
生成驾驶场景
驾驶场景对自动驾驶来说具有重要的意义。为了获得不同的驾驶场景数据,仅依赖采集车辆的传感器进行实时采集需要消耗巨大的成本,很难为一些边缘场景获得足够的场景数据。通过仿真生成逼真的驾驶场景引起了许多研究者的关注,交通仿真研究主要分为基于规则和数据驱动两大类。
-
基于规则的方法:使用预定义的规则,这些规则通常不足以描述复杂的驾驶场景,并且模拟的驾驶场景更简单、更通用
-
基于数据驱动的方法:使用驾驶数据来训练模型,模型可以从中持续学习和适应。然而,数据驱动的方法通常需要大量的标记数据进行训练,这阻碍了流量模拟的进一步发展
随着技术的发展,目前数据的生成方式已经逐渐由规则的方式转换为数据驱动的方式。通过高效、准确地模拟驾驶场景,包括各种复杂和危险的情况,为模型学习提供了大量的训练数据,可以有效提高自动驾驶系统的泛化能力。同时,生成的驾驶场景也可用于评估不同的自动驾驶系统和算法来测试和验证系统性能。下表是不同数据增强策略的总结。

不同数据增强策略总结
世界模型
世界模型被认为是为一种人工智能模型,它包含了它运行的环境的整体理解或表示。该模型能够模拟环境做出预测或决策。在最近的文献中,强化学习的背景下提到了术语”世界模型”。这个概念在自动驾驶应用中也得到了关注,因为它能够理解和阐明驾驶环境的动态特性。世界模型与强化学习、模仿学习和深度生成模型高度相关。然而,在强化学习和模仿学习中利用世界模型通常需要标注好的数据,并且SEM2以及MILE等方法都是在监督范式中进行的。同时,也有尝试根据标记的数据的局限性将强化学习和无监督学习结合起来。由于与自监督学习密切相关,深度生成模型变得越来越流行,目前已经提出了很多工作。下图展示出来了使用世界模型增强自动驾驶模型的整体流程图。
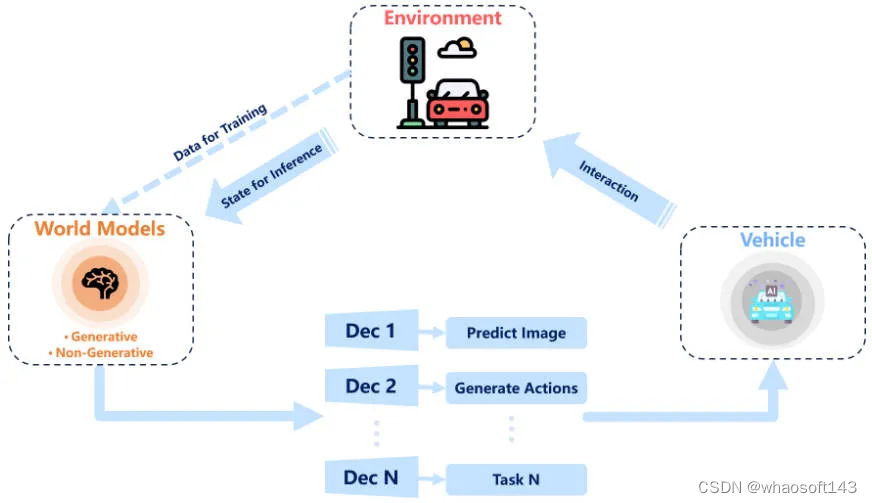
世界模型进行自动驾驶模型增强的整体流程图
深度生成模型
深度生成模型通常包括变分自动编码器、生成对抗网络、流模型以及自回归模型。
-
变分自动编码器结合了自动编码器和概率图形模型的思想来学习数据的底层结构并生成新样本
-
生成对抗网络由两个神经网络、生成器和鉴别器组成,它们利用对抗训练相互竞争和增强,最终实现生成真实样本的目标
-
流模型通过一系列可逆变换将简单的先验分布转换为复杂的后验分布来生成相似的数据样本
-
自回归模型是一类序列分析方法,基于序列数据之间的自相关,描述当前观测值与过去观测值之间的关系,模型参数的估计通常是利用最小二乘法和最大似然估计来完成的。扩散模型是一种典型的自回归模型,它从纯噪声数据中学习逐步去噪的过程。由于其强大的生成性能,扩散模型是当前深度生成模型中的新SOTA模型
生成式方法
基于深度生成模型的强大能力,利用深度生成模型作为世界模型学习驾驶场景以增强自动驾驶已经逐渐成为研究热点。接下来我们将回顾利用深度生成模型作为自动驾驶中的世界模型的应用。视觉是人类获取有关世界信息的最直接有效的方法之一,因为图像数据中包含的特征信息极其丰富。许多以前的工作通过世界模型完成了图像生成的任务,表明世界模型对图像数据具有良好的理解和推理能力。目前整体来看,研究者们希望可以从图像数据中学习世界的内在进化规律,然后预测未来的状态。结合自监督学习,世界模型用于从图像数据中学习,充分释放模型的推理能力,为视觉域构建广义基础模型提供了一种可行的方向。下图展示了一些利用世界模型的相关工作内容汇总。
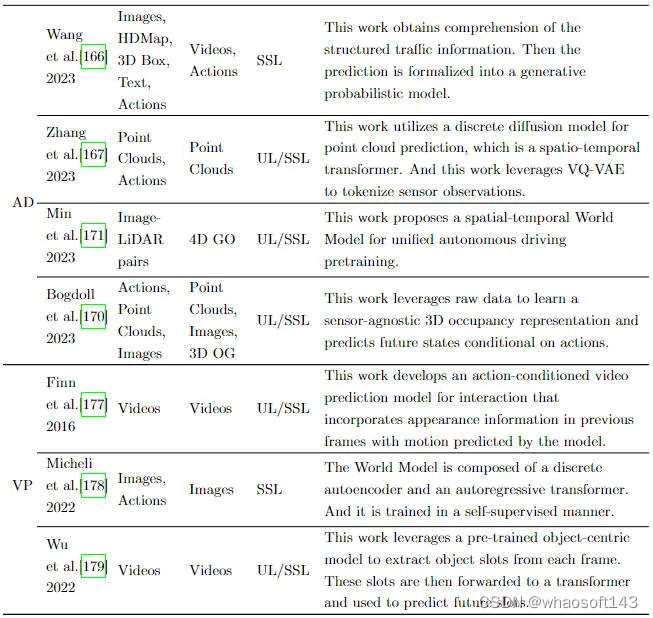
使用世界模型进行预测的工作汇总
非生成式方法
与生成世界模型相比,LeCun通过提出联合提取和预测架构 (JEPA) 详细阐述了他对世界模型的不同概念。这是一个非生成和自监督的架构,因为它不直接根据输入数据来预测输出结果,而是将输入数据编码在一种抽象空间中进行编码完成最终的预测。这种预测方式的优点是它不需要预测关于输出结果的所有信息,并且可以消除不相关的细节信息。
JEPA是一种基于能量模型的自监督学习架构,它观察和学习世界如何工作和高度概括的规律。JEPA在自动驾驶中也有很大的潜力,有望通过学习驾驶是如何工作的来生成高质量的驾驶场景和驾驶策略。
结论
本文全面概述了基础模型在自动驾驶应用中的重要作用。从本文调研的相关研究工作的总结和发现来看,另一个值得进一步探索的方向是如何为自监督学习设计一个有效的网络架构。自监督学习可以有效地突破数据标注的局限性,允许模型大规模的对数据进行学习,充分释放模型的推理能力。如果自动驾驶的基础模型可以在自监督学习范式下使用不同规模的驾驶场景数据进行训练,则预计其泛化能力将大大提高。这种进步可能会实现更通用的基础模型。
总之,虽然在将基础模型应用于自动驾驶方面存在许多挑战,但其具有非常广阔的应用空间和发展前景。未来,我们将继续观察应用于自动驾驶的基础模型的相关进展。
# 关于端到端自动驾驶的一些基本概念
最近两年关于端到端自动驾驶的消息很多,加上不同的定语修饰,有很多单位都发布了国内首个端到端智能驾驶系统:
-
首发端到端自动驾驶大模型,目标2025年L4:小鹏开启AI智驾 ...
-
车辆学院科研团队完成国内首套全栈式端到端自动驾驶系统 ...
-
首个感知决策一体化自动驾驶大模型!上海AI实验室等斩获 ...
-
特斯拉向用户推送FSD V12,首个端到端AI自动驾驶系统上线...
-
完成国内首次端到端智驾大模型路测,千挂科技实现「弯道超车」...
-
元戎启行是国内第一家能够将端到端模型成功上车的人工智能企业...
感觉自动驾驶已经到来,前途一片光明(与之对应的是,各大车企疯狂裁员),属实看不懂。
下边列举了一些机器学习的一些基本概念。
1.端到端学习:
指的是一个模型直接从原始输入数据(例如图像像素)到最终输出结果(例如分类标签)的学习过程,不需要手动设计和提取特征。一个端到端的神经网络模型可以通过训练数据直接学习映射关系
2.机器学习:
机器学习是人工智能的一个子领域,涉及通过数据驱动的方法让计算机系统自动学习和改进性能,而不需要明确的编程指令。包括监督学习、无监督学习和强化学习等
3.强化学习:
强化学习是一种机器学习方法,系统通过试错与环境交互,学习在不同状态下采取最佳行动,以最大化累计奖励。
4.深度学习:
深度学习是机器学习的一个子领域,使用多层神经网络(深度神经网络)来学习数据中的复杂模式和高级特征。
5.卷积神经网络(CNN):
主要用于图像处理和计算机视觉任务,是深度学习中的一个常见模型
6.循环神经网络(RNN):
主要用于序列数据处理,如自然语言处理和时间序列预测。
7.模仿学习:
模仿学习是一种机器学习方法,系统通过观察和模仿专家的行为来学习任务
8.神经网络模型:
神经网络是受生物神经系统启发的计算模型,通过模仿大脑神经元的连接和处理方式来解决复杂的计算问题,神经网络是机器学习的一种方法。
9.长短期记忆网络(Long Short-Term Memory, LSTM):
是一种特殊类型的循环神经网络(RNN),属于深度学习的范畴。LSTM是为了解决传统RNN在处理长序列数据时存在的长期依赖问题而设计的。
10.Transformer:
是一种深度学习模型,主要用于处理序列数据,尤其在自然语言处理(NLP)任务中表现出色。Transformer模型属于深度学习的范畴,是一种基于注意力机制的模型,解决了传统RNN和LSTM在处理长序列数据时的效率和性能问题。
11.深度学习框架
-
PyTorch:
-
TensorFlow:是一个广泛使用的深度学习框架,支持构建和训练各种类型的神经网络模型,包括卷积神经网络(CNN)、循环神经网络(RNN)、生成对抗网络(GAN)等。
-
Keras:最初由François Chollet开发,现为TensorFlow的高级API
-
Caffe:
-
百度飞桨:
12.Mediapipe:
其本身并不是用于训练深度学习模型的框架,而是一个用于部署和运行预训练模型的框架。它常常结合深度学习模型来实现复杂的计算机视觉任务。Mediapipe的模块中有许多是基于深度学习模型构建的,例如人脸检测模块使用了基于深度学习的模型。
13.端到端自动驾驶:
指的是使用深度学习和其他机器学习技术直接从传感器输入(如摄像头图像、激光雷达数据)到驾驶控制输出(如方向盘角度、加速、制动)的全流程自动化。与传统的分层方法不同,端到端方法不需要显式的模块化步骤(如检测、跟踪、规划等),而是通过一个统一的模型来实现。
14.Transformer与端到端自动驾驶的关系:
Transformer模型在自然语言处理(NLP)领域取得了巨大成功,近年来其自注意力机制也被应用于计算机视觉和自动驾驶等领域。在端到端自动驾驶中,Transformer模型可以通过其强大的特征提取和全局上下文理解能力,处理和融合多模态数据(如摄像头图像、LiDAR点云、雷达数据等),从而实现更高效和准确的驾驶决策
15.嵌入式深度学习(Embedded Deep Learning):
指的是在资源受限的嵌入式系统上运行深度学习模型。嵌入式系统通常具有有限的计算能力、存储空间和电源供应,例如物联网设备、智能手机、边缘设备、无人机和机器人。为了在这些设备上高效运行深度学习模型,需要对模型进行优化和调整。
-
模型压缩与优化:
-
-
-
量化(Quantization):将模型权重和激活值从浮点数转换为低精度整数(如8位),减少模型大小和计算需求。
-
剪枝(Pruning):删除对模型性能影响较小的权重和神经元,减少模型复杂度。
-
蒸馏(Distillation):用复杂模型(教师模型)训练较小的模型(学生模型),使小模型保留大模型的性能。
-
低秩分解(Low-rank Decomposition):将模型权重矩阵分解为低秩近似,减少计算量。
-
-
-
硬件加速:
-
-
-
专用加速器:如Google TPU、NVIDIA Jetson、Intel Movidius等专用硬件,加速深度学习计算。
-
嵌入式GPU和DSP:利用嵌入式设备上的图形处理单元(GPU)和数字信号处理器(DSP)进行加速计算。
-
-
-
软件框架与工具:
-
-
-
TensorFlow Lite:针对移动和嵌入式设备优化的TensorFlow版本,支持模型量化和加速。
-
PyTorch Mobile:PyTorch的移动版本,支持在Android和iOS设备上运行。
-
ONNX Runtime:支持跨平台的高效推理引擎,可以将模型导出为ONNX格式并在嵌入式设备上运行。
-
-
16.L4自动驾驶与端到端自动驾驶的关系:
L4自动驾驶,强调在特定环境和条件下实现完全自主驾驶,可以使用多种技术和架构,包括传统的模块化方法和端到端方法。
端到端自动驾驶,是一种实现自动驾驶的技术方法,可以应用于各种自动驾驶级别,包括L4级别。
17.大模型与自动驾驶:
大模型(Large Models)主要属于深度学习(Deep Learning)领域,它们通过在大规模数据上进行预训练,展示了强大的泛化能力和多任务处理能力。深度学习是机器学习的一个子领域,致力于通过多层神经网络进行特征提取和表示学习。大模型广泛应用于多个领域,包括但不限于自然语言处理、计算机视觉、语音识别、强化学习等。
18.世界模型:
世界模型(World Models)属于深度学习(Deep Learning)和强化学习(Reinforcement Learning)领域的交叉部分。这些模型利用深度学习技术来构建、表示和模拟复杂的环境动态和行为,特别是在强化学习、自动驾驶、机器人控制等应用中。
(最后几个概念我是越写越迷糊)
几年前,做L4自动驾驶的厂家百花齐放,各种demo和ppt,非常受资本青睐。后来,大部分都倒闭了,剩下没倒闭的,都开始倒头做L2辅助驾驶。甚至开始卷起了AEB技术。高精地图,无图,BEV,OCC,时空联合,端到端,大模型,世界模型,各种概念层出不穷,不知道下一个被抛弃的概念是哪个,也不知道下一个出现的概念又是哪个。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









