









关于ES数据库的和核心倒排索引的介绍
一、Elasticsearch概述
简介
Elasticsearch是一个基于lucene、分布式、通过Restful方式进行交互的近实时搜索平台框架。
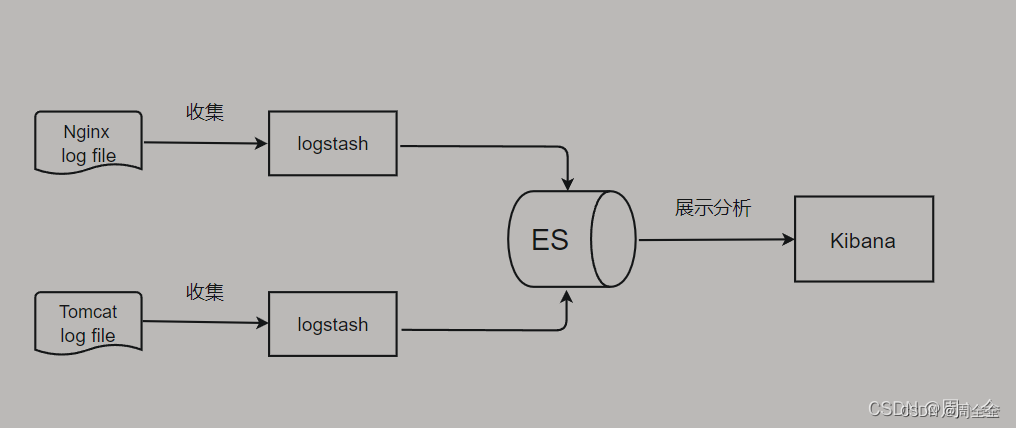
ELK技术栈是Elasticsearch、Logstash、Kibana三大开元框架首字母大写简称。
而Elasticsearch 是一个开源的高扩展的分布式全文搜索引擎, 是整个 ELK技术栈的核心。
- Elasticsearch是一个基于lucene、分布式、通过Restful方式进行交互的近实时搜索平台框架。
- Logstash是中央数据流引擎,用于从不同目标(文件/数据存储/mq)收集不同格式的数据,经过过滤后支持输出到不同目的地
- Kibana可以将es的数据通过友好的页面展示出来,提供实时分析的功能
模型图
关于全文检索引擎
这里说到的全文搜索引擎指的是目前广泛应用的主流搜索引擎。它的工作原理是计算机索引程序通过扫描文章中的每一个词,对每一个词建立一个索引,指明该词在文章中出现的次数和位置,当用户查询时,检索程序就根据事先建立的索引进行查找,并将查找的结果反馈给用户的检索方式。这个过程类似于通过字典中的检索字表查字的过程。
关系型数据库的全文检索功能缺点
首先就mysql而言,数据库用来存储文本字段本身就与关系型的思想相悖,而且全文检索时需要全表扫描,大数据量下即使对sql语句进行优化,响应时间也很难以满足需求。即使建立索引,而且是可能大量的建立索引来优化,反而维护更麻烦,insert和update每次又都会重新构建索引,反而增加了数据库的压力。
全文检索的应用场景
- 检索的数据对应是大量的非结构化的文本型数据
- 文件的记录量至少是十万以上级别
- 支持交互式文本的全文检索查询
- 对于检索结果的相关性具有较高的要求,且检索的实时性要求很高
Elasticsearch 应用案例
GitHub: 2013 年初,抛弃了 Solr,采取 Elasticsearch 来做 PB 级的搜索。 “GitHub 使用Elasticsearch 搜索 20TB 的数据,包括 13 亿文件和 1300 亿行代码”。
维基百科:启动以 Elasticsearch 为基础的核心搜索架构
百度:目前广泛使用 Elasticsearch 作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部 20 多个业务线(包括云分析、网盟、预测、文库、直达号、钱包、 风控等),单集群最大 100 台机器, 200 个 ES 节点,每天导入 30TB+数据。
新浪:使用 Elasticsearch 分析处理 32 亿条实时日志。
阿里:使用 Elasticsearch 构建日志采集和分析体系。
二、Elasticsearch学习准备
安装下载
es安装参考:ElasticSearch下载安装和环境配置(Linux和Windows环境)
kibana安装参考:Kibana的下载与安装配置以及连接ElasticSearch测试
关于es检索的核心-倒排索引
在搜索引擎中每个文件都对应一个文件ID,文件内容被表示为一系列关键词的集合(实际上在搜索引擎索引库中,关键词也已经转换为关键词ID)。例如“文档1”经过分词,提取了20个关键词,每个关键词都会记录它在文档中的出现次数和出现位置。
正向索引(forward index)
得到正向索引的结构如下:通过key,去找value。
“文档1”的ID > 单词1:出现次数,出现位置列表;单词2:出现次数,出现位置列表;…………。
“文档2”的ID > 此文档出现的关键词列表。
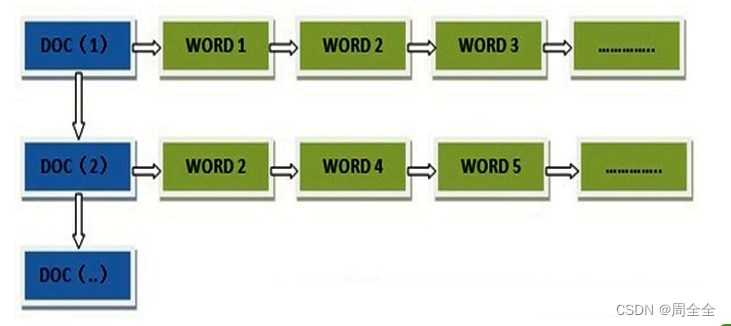
正向索引的弊端:假设使用正向索引检索关键词"索引测试",那么需要扫描全库索引检索,然后根据某个权重策略进行排序返回给用户。问题就在于数据量十分庞大时的全库扫描无法满足实时的检索需求
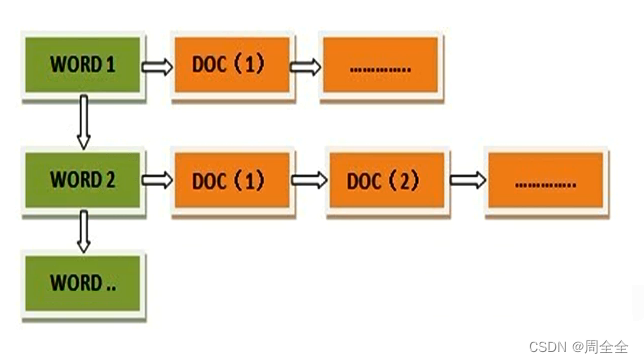
倒排索引(inverted index)
搜索引擎会将正向索引重新建为倒排索引,即把文件ID对应到关键词的映射转换为关键词到文件ID的映射,每个关键词都对应着一系列的文件,这些文件中都出现这个关键词。
得到倒排索引的结构如下:从词的关键字,去找文档ID。
“关键词1”:“文档1”的ID,“文档2”的ID,…………。
“关键词2”:带有此关键词的文档ID列表。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











