







说明:
text字段类型用于全文内容,例如电子邮件正文或产品说明,并且es会通过分析器对字符串进行分词,可以在全文检索中搜索单独的单词。文本字段最适合非结构化但可读的内容并且不用于排序,也很少用于聚合
keyword主要用于结构化内容的字段,并且总是会有相同值的字段。因为通常需要用于聚合、排序和术语级查询(如
term),所以避免参与全文检索
如果需要使用text字段类型进行聚合和排序,则需要在建立mapping映射时在fields字段中增加一个keyword类型的数据。
示例:
"publisherName": {
"analyzer": "standard",
"type": "text",
"fields": {
"raw": { //此字段用于在聚合和排序场景时使用
"type": "keyword",
"ignore_above": 8190
}
}
},
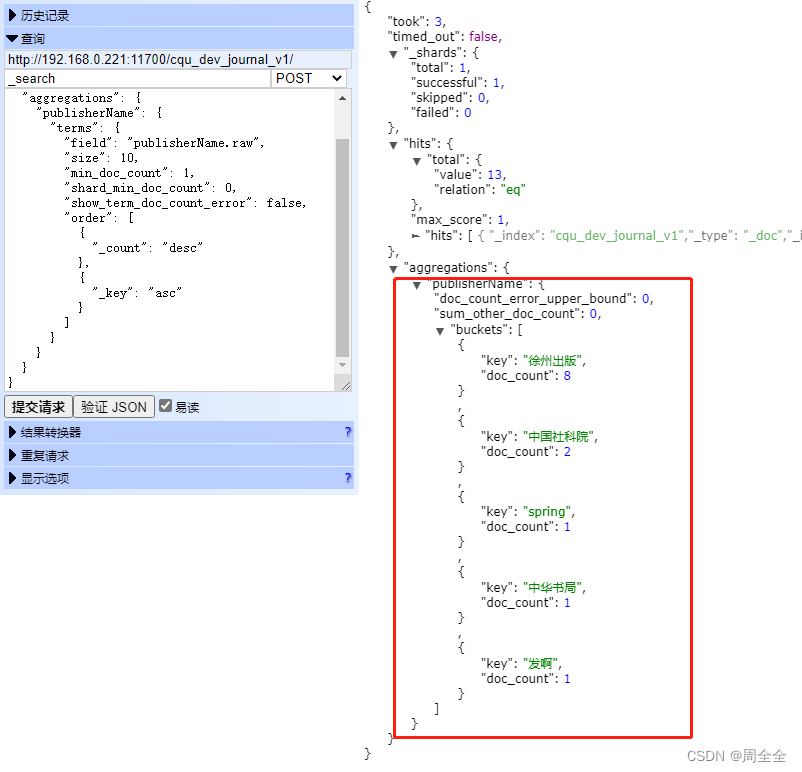
聚合
{
"from": 0,
"size": 10,
"aggregations": {
"publisherName": {
"terms": {
"field": "publisherName.raw", //如果使用publisherName全文字段检索时,会有下列报错
"size": 10,
"min_doc_count": 1,
"shard_min_doc_count": 0,
"show_term_doc_count_error": false,
"order": [
{
"_count": "desc"
},
{
"_key": "asc"
}
]
}
}
}
}
报错信息:
Text fields are not optimised for operations that require per-document field data like aggregations and sorting, so these operations are disabled by default. Please use a keyword field instead. Alternatively, set fielddata=true on [publisherName] in order to load field data by uninverting the inverted index. Note that this can use significant memory.
查询成功:

















 3195
3195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











