







这个东西用途不广,因为少有网站会把管理员登陆界面和普通可浏览页面放在同个文件夹下,但是,对于一些挂马的网站,其网站管理员很有可能会这么干(我导师告诉我的,当时忘了问为啥。。有没有大神告诉我一下,万分感谢)
权当练个手吧2333
————————————————分割线———————————————
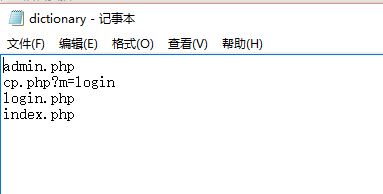
其实原理很简单,用urllib构造request请求,发送到指定的url,如果能够连上,说明该url存在,然后再遍历一个字典文件,将里面存储的可能用于登陆的页面添加/替换到指定url的后面,我的字典是这样的:
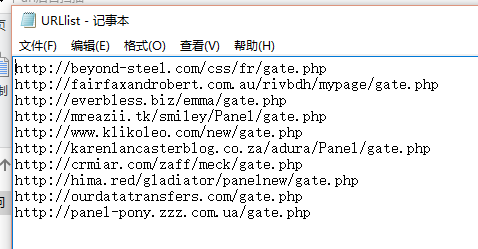
导师给了我一个可能是挂马网站的urllist文件,是这样的(亲测有一个是老毛子的网站23333):
具体过程是这样,先遍历urllist文件,向里面的url发送请求,如果成功连接,就把该url记录在一个新的文本文件里(我的文件名写urlok)
全遍历完之后,再遍历urlout里的url,遍历之前把字典中的页面替换到url里面,如果成功,则记录到一个新的文本文件(我的是urlresult)
最后得到的urlresult就是挂马网站的管理员页面了
贴个代码:
import urllib
import urllib2
import re
agent = "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:48.0) Gecko/20100101 Firefox/48.0"
headers = {"user-Agent":agent}
fpout = open("urlok.txt","w+")
fpres = open("result.txt","w")
def urlSend(url):
try:
req = urllib2.Request(url = url,headers = headers)
res = urllib2.urlopen(req)
print "[+] Success"
fpout.write(url)
return 1
except urllib2.HTTPError,e:
print "[-] " + str(e.code)
return 0
except urllib2.URLError,e:
print "[-] " + str(e.reason)
return 0
def main():
fpurl = open("URLlist.txt","r")
fpdic = open("dictionary.txt","r")
for line in fpurl.readlines():
print "[*] Linking " + line.strip("\n") + " now..."
urlSend(line)
print "--------------------------Scan Start--------------------------------------"
fpurl.close()
fpout.seek(0,0)
pattern = re.compile("<title>(.*?)</title>")
for line in fpout.readlines():
for item in fpdic.readlines():
newurl = re.sub("/\w+\.php","/"+item,line)
if urlSend(newurl):
print "[+] " + newurl.strip("\n") + " OPEN"
req = urllib2.Request(url = newurl,headers = headers)
res = urllib2.urlopen(req)
f = pattern.search(res.read())
if f:
fpres.write(newurl.strip("\n") +" title:"+ f.group(1) + "\n")
print "[+] title is:" + f.group(1) + "\n"
else:
print "[-] No title \n"
fpres.write(newurl + "\n")
else:
print "[-] "+ newurl.strip("\n") + " CLOSE\n"
fpdic.seek(0,0)
if __name__ == "__main__":
main()
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









