







我们所开发的App在进行会话聊天时,有一些非常明显的性能劣化。比如:
- 打开会话速度慢;
- 在同一个会话有较多的历史消息下,各种查询,更新,删除等操作,速度明显下降;
- 在会话内有较大量历史消息情况下,进入速度/刷新速度明显降低。
这些问题都是老生常谈,但一直存在的。团队里的成员各个脑洞大开,江郎才尽也想不出更好的方法。于是我们打算去参考IM届大佬——微信是如何提高IM性能的。

如果你也想知道,那就跟我一起逆向吧~
逆向策略
准备
- Root 手机
- Frida 配置(或者任意 Xposed 手机)
- SqlLiteStudio
参考资料
步骤
- 获取打开 DB 的秘钥(by Frida)
- 获取 DB(需要 Root 手机)
- 打开 DB (SqlLiteStudio)
微信表设计
这里有一个有意思的信息,微信双端设计是不一样的。
我们这里只看Android的设计。
单表存储,百万行,索引效率低。主要是字符串索引占用空间大,需要遍历节点过多,解决方案是用整型代替字符串作为索引,减少I/O。
消息表
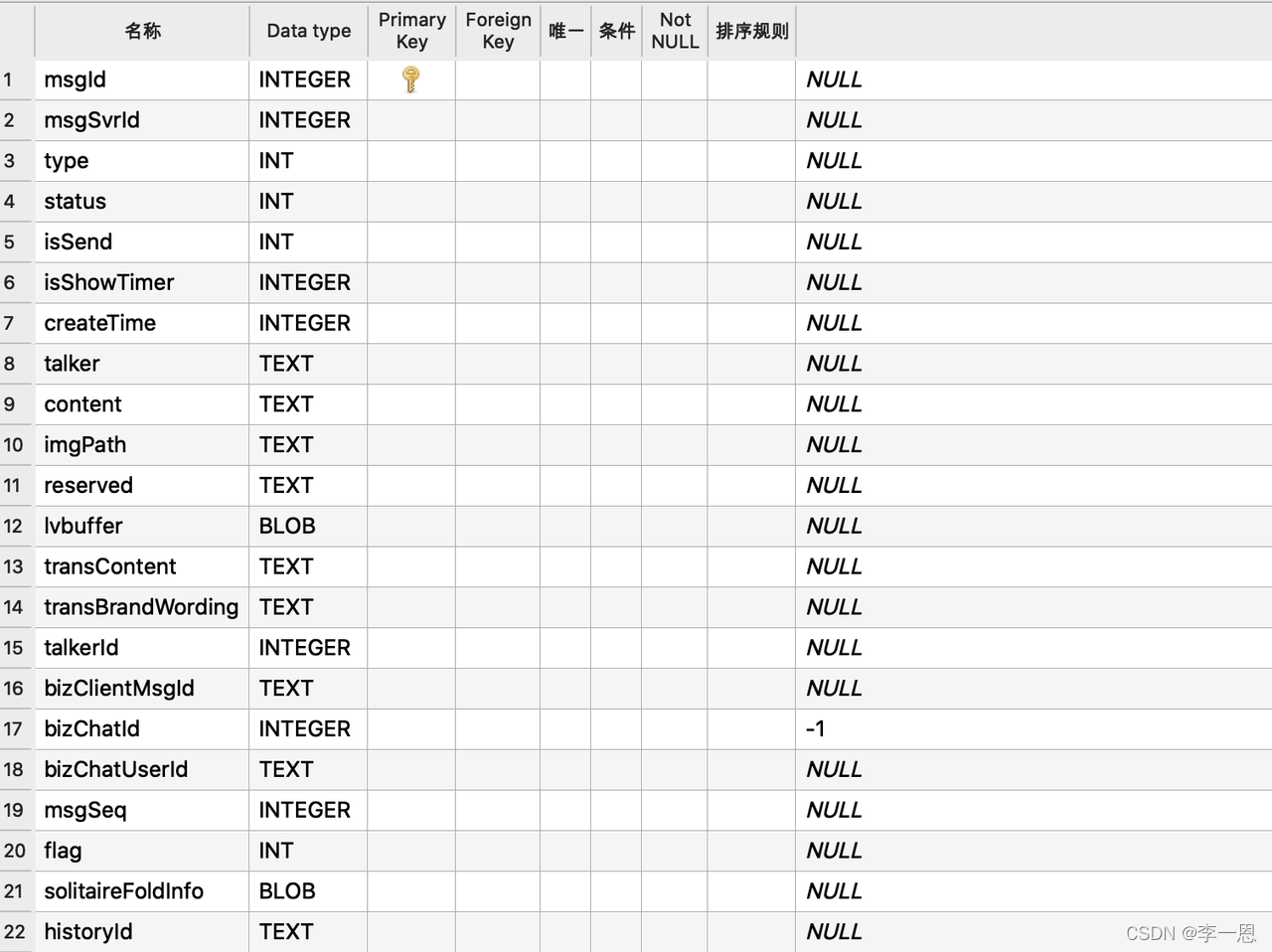
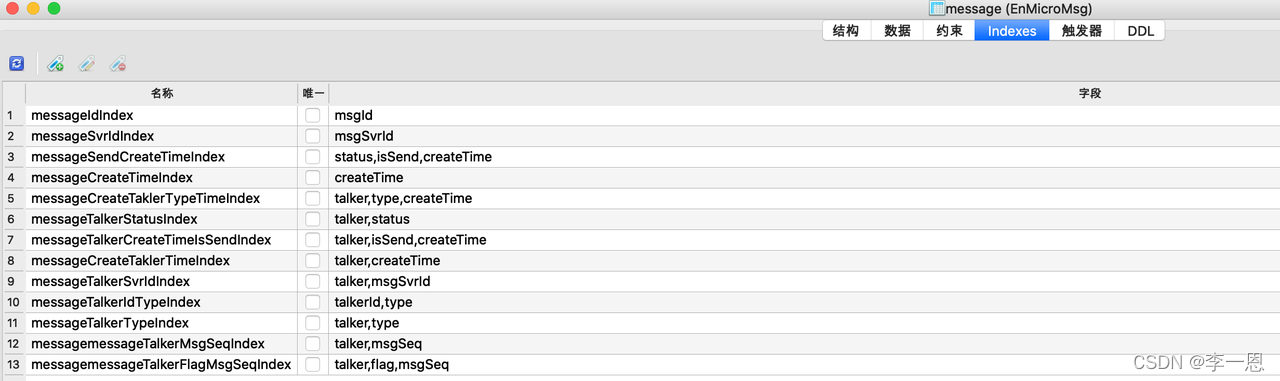

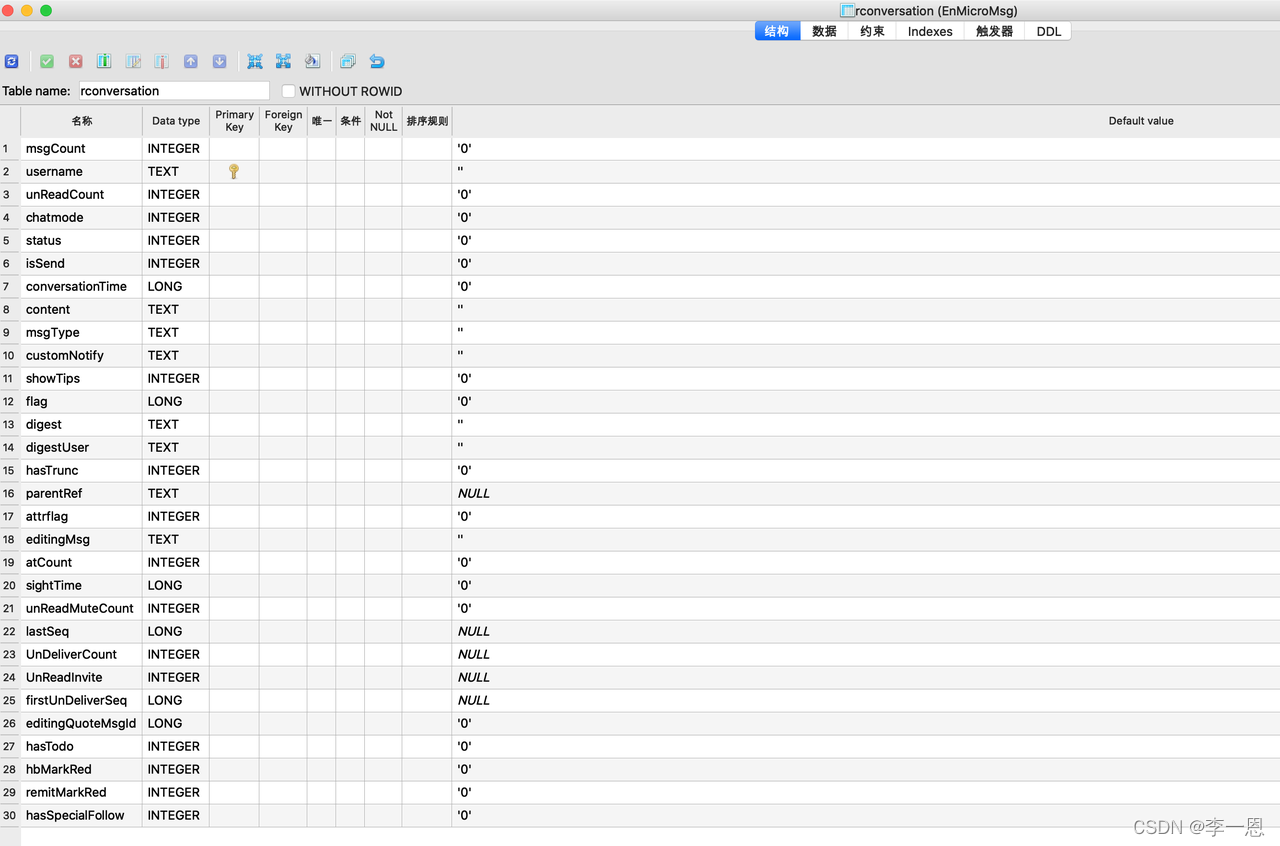
会话表


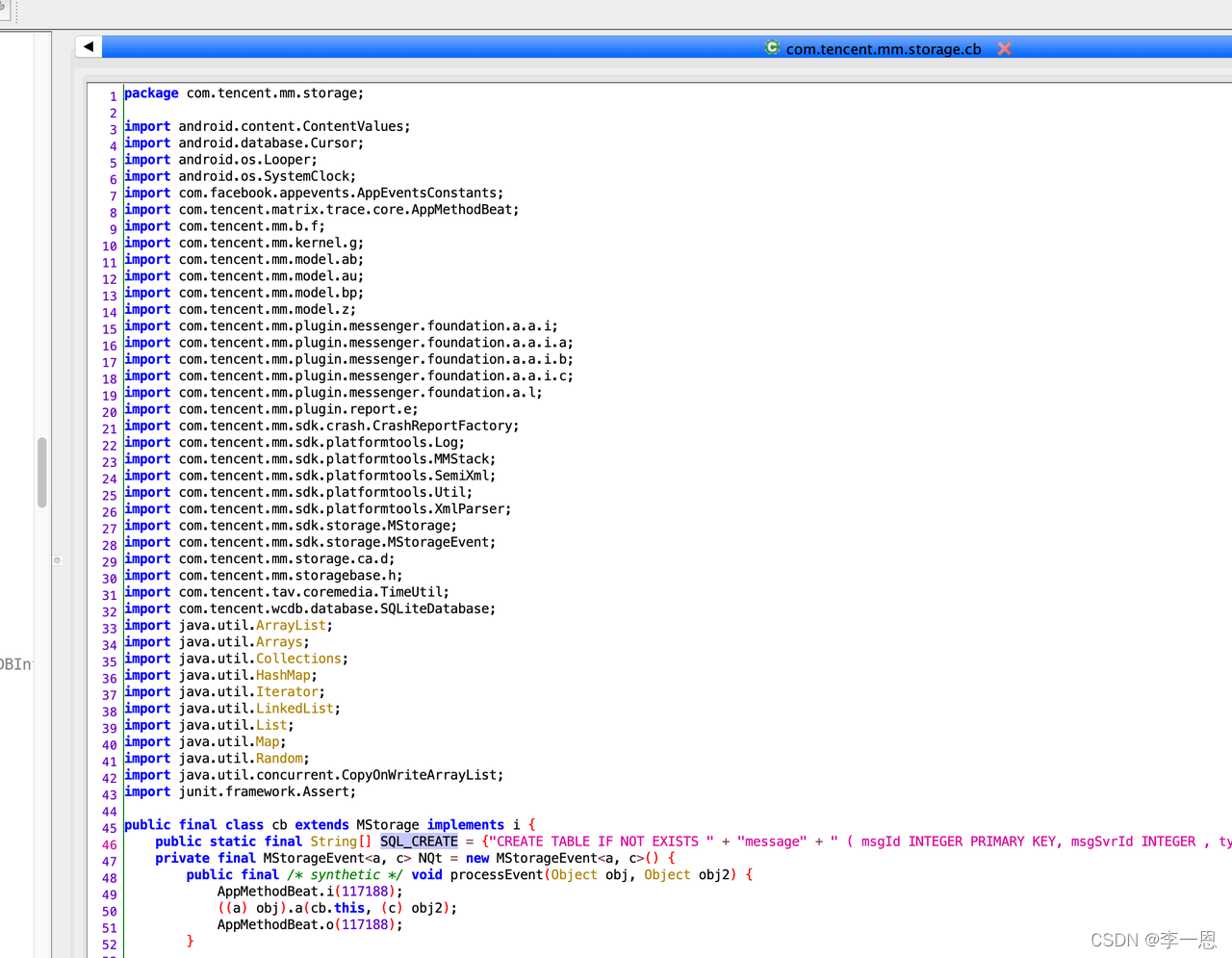
代码逆向笔记
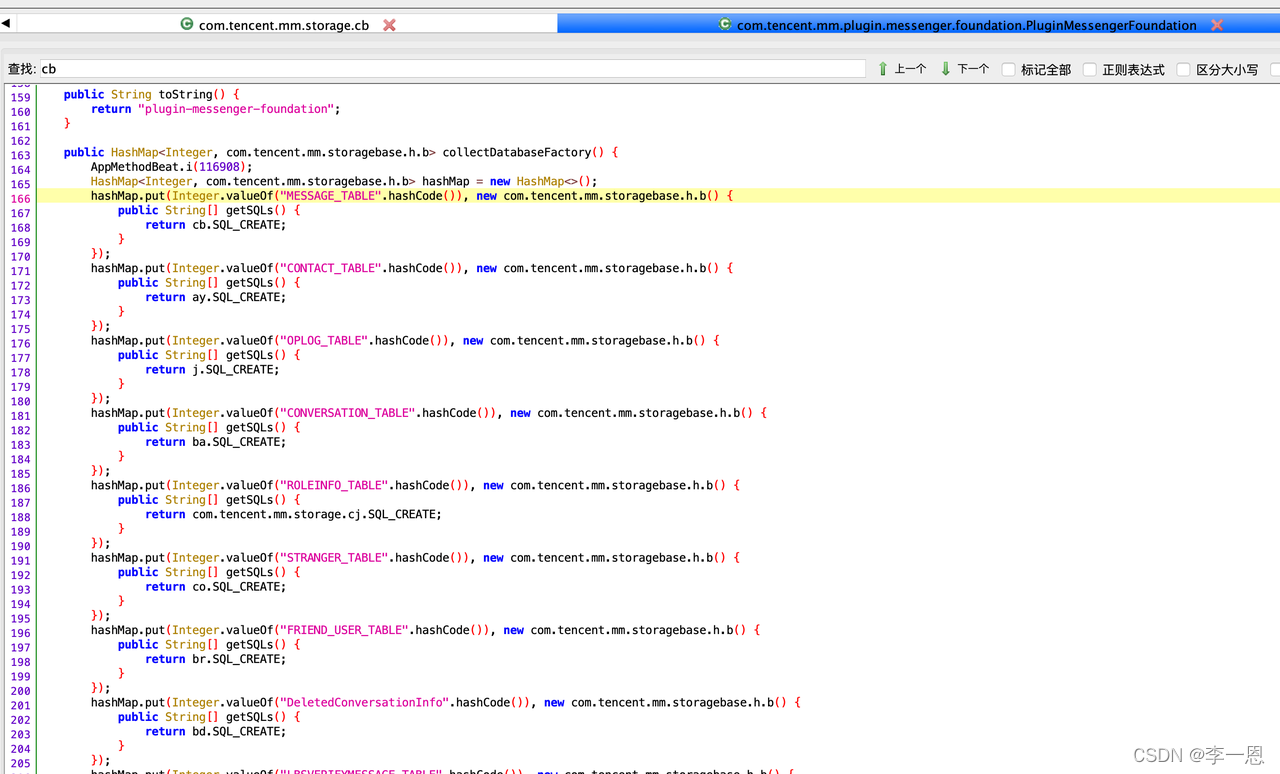
消息表创建:
统一SQL组装:
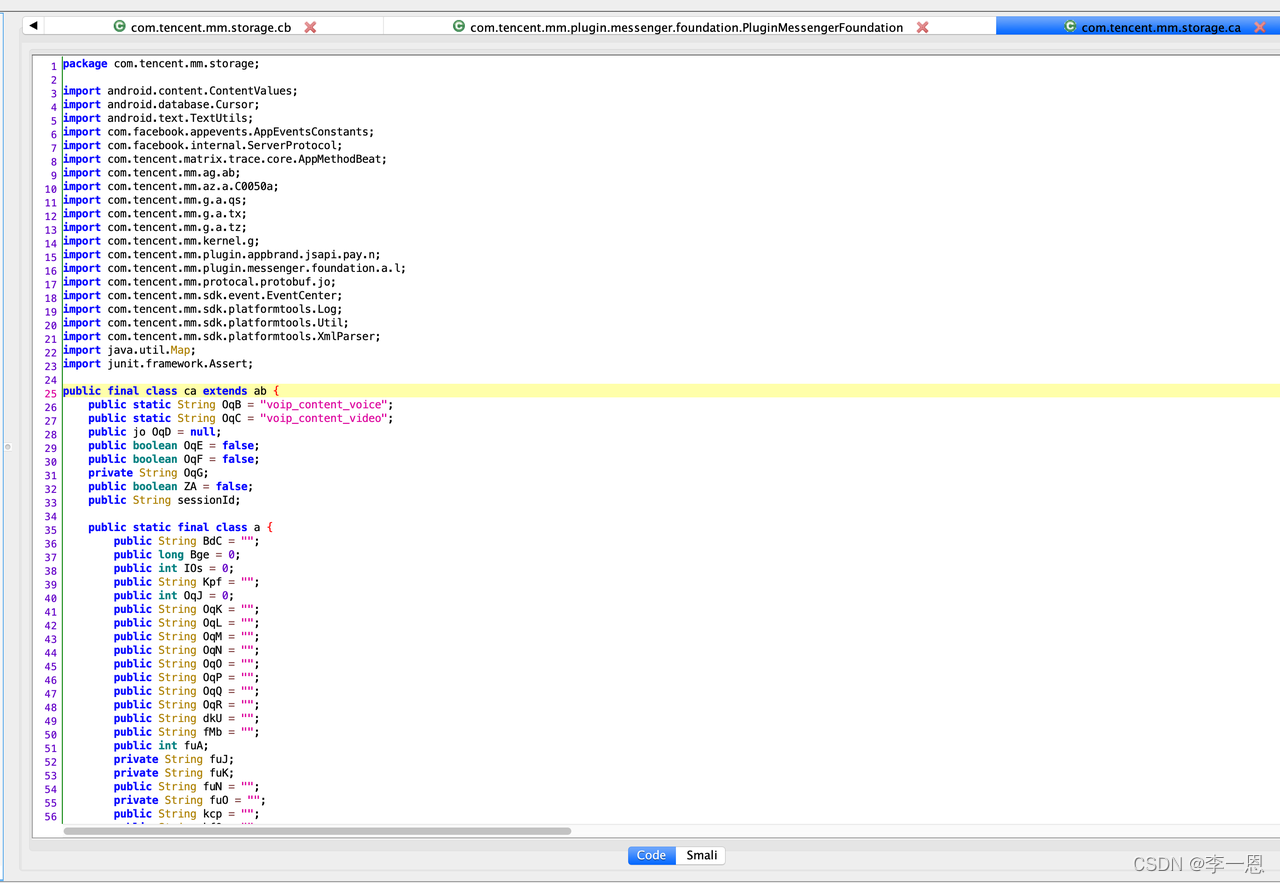
会话详情页使用的对象:
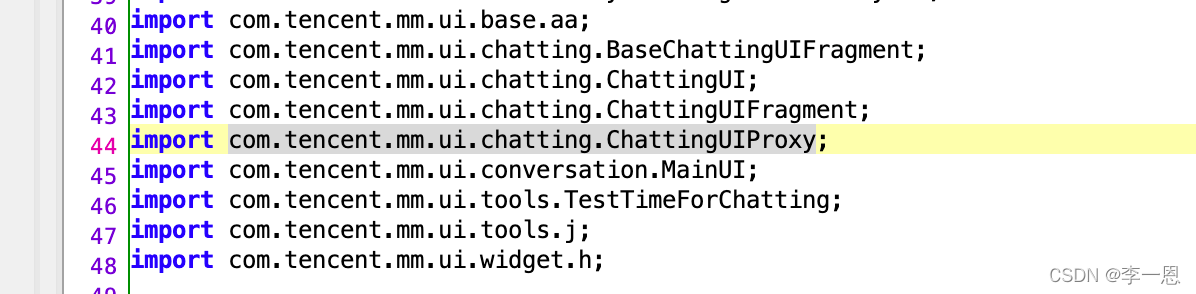
会话详情页相关UI组件:
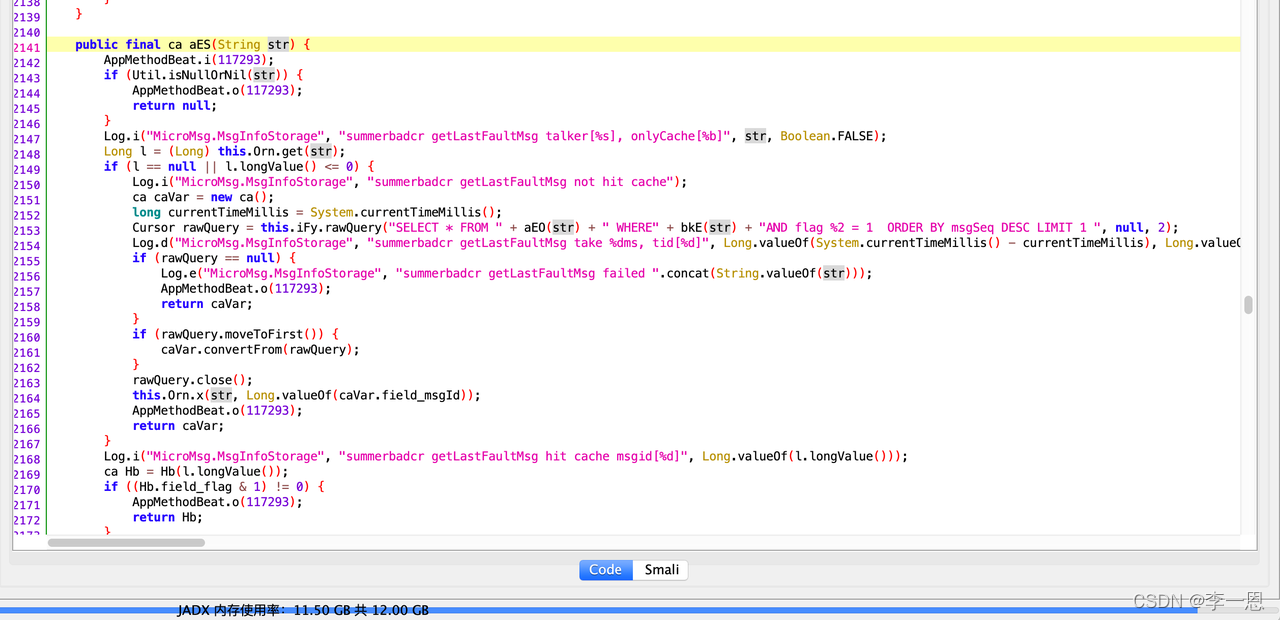
talkerId 补偿:

lastMsg:
学习部分总结
微信 Android 版本为了优化 SQL 性能,两种方案:
- 将消息表进行会话维度上的拆分
- sqlite所有的表是通过B+树进行存储,当整个message表数据量较大的时候,因该表所在的B+树的深度较大,所有的查询或更新操作都会因此而多走很多的磁盘I/O流程。 而把message表按照talker(联系人)为单位分表,一个联系人一个表。则整个消息的存储就在物理空间上被分成了多个区间,同一个联系人的消息,在空间上被内聚到临近的磁盘块,这样的话,整个消息模块所在的B+树的深度就降低了,读取时候也会因磁盘的临近性(连续4k,磁盘一次读取最小的单位,大小根据不同磁盘的实际设定而定)而减少不少的磁盘I/O,上面的查询慢的问题也就解决了。
- 数据库索引进行优化
- 整个优化效应链是:单条索引记录占用降低 —> 用于存储索引的Page数量降低 —> 用于查询加载的Page量降低 —> 整个查询时间降低。
你学废了吗?



















 378
378

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











