







Hadoop 可以处理许多不同类型的数据格式,从纯文本文件到数据库。Hadoop InputFormat 检查作业的输入规范。InputFormat 将 Input 文件拆分为 InputSplit 并分配给单个 Mapper。InputFormat 定义了如何在 Hadoop 中拆分和读取输入文件。
Hadoop InputFormat 是 Map-Reduce 的第一个组件,它负责创建输入拆分并将它们划分为记录。最初,MapReduce 任务的数据存储在输入文件中,而输入文件通常驻留在HDFS 中。尽管这些文件格式是任意的,但可以使用基于行的日志文件和二进制格式。我们使用 InputFormat 定义如何拆分和读取这些输入文件。
InputFormat 类是 Hadoop MapReduce 框架中的基本类之一,它提供以下功能:
应该用于输入的文件或其他对象由 InputFormat 选择。
InputFormat 定义了数据拆分,它定义了单个 Map 任务的大小及其潜在的执行服务器。
InputFormat 定义了 RecordReader,它负责从输入文件中读取实际记录。
我们如何将数据获取到映射器?
我们有两种方法可以在 MapReduce 中将数据获取到映射器:getsplits() 和 createRecordReader(),如下所示
public abstract class InputFormat<K, V> {
public abstract List<InputSplit> getSplits(JobContext context) throws IOException, InterruptedException;
public abstract RecordReader<K, V> createRecordReader(InputSplit split, TaskAttemptContext context) throws IOException, InterruptedException;
}
输入格式
Hadoop 可以处理许多不同类型的数据格式,从纯文本文件到数据库。Hadoop InputFormat 检查作业的输入规范。InputFormat 将 Input 文件拆分为 InputSplit 并分配给单个 Mapper。InputFormat 定义了如何在 Hadoop 中拆分和读取输入文件。
Hadoop InputFormat 是 Map-Reduce 的第一个组件,它负责创建输入拆分并将它们划分为记录。最初,MapReduce 任务的数据存储在输入文件中,而输入文件通常驻留在HDFS 中。尽管这些文件格式是任意的,但可以使用基于行的日志文件和二进制格式。我们使用 InputFormat 定义如何拆分和读取这些输入文件。
InputFormat 类是 Hadoop MapReduce 框架中的基本类之一,它提供以下功能:
应该用于输入的文件或其他对象由 InputFormat 选择。
InputFormat 定义了数据拆分,它定义了单个 Map 任务的大小及其潜在的执行服务器。
InputFormat 定义了 RecordReader,它负责从输入文件中读取实际记录。
我们如何将数据获取到映射器?
我们有两种方法可以在 MapReduce 中将数据获取到映射器:getsplits() 和 createRecordReader(),如下所示
MapReduce 中 InputFormat 的类型
1.文件输入格式
FileInputFormat 是所有使用文件作为数据源的 InputFormat 实现的基类(见下图)

FileInputFormat 提供了两件事:定义哪些文件作为作业的输入包含的位置,以及为输入文件生成拆分的实现。
FileInputFormat 的输入路径
作业的输入被指定为路径集合,这在限制输入方面提供了极大的灵活性。FileInputFormat 提供四种静态方便的方法来设置作业的输入路径
public static void addInputPath(Job job, Path path)
public static void addInputPaths(Job job, String commaSeparatedPaths)
public static void setInputPaths(Job job, Path... inputPaths)
public static void setInputPaths(Job job, String commaSeparatedPaths)
addInputPath() 和 addInputPaths() 方法向输入列表添加一个或多个路径。
setInputPaths() 方法一次性设置整个路径列表。
路径可以代表一个文件、一个目录,或者,通过使用 glob,可以代表文件和目录的集合。表示目录的路径包括目录中的所有文件作为作业的输入。add 和 set 方法只允许通过包含来指定文件。要从输入中排除某些文件,您可以使用 FileInputFormat 上的 setInputPathFilter() 方法设置过滤器。即使您没有设置过滤器,FileInputFormat 也会使用默认过滤器来排除隐藏文件(名称以点或下划线开头的文件)。如果您通过调用 setInputPathFilter() 设置过滤器,它会作为默认过滤器的补充。换句话说,只有过滤器接受的非隐藏文件才能通过。
FileInputFormat 输入拆分
FileInputFormat 只分割大文件——这里,“大”意味着比 HDFS 块大。拆分大小通常是 HDFS 块的大小,适用于大多数应用程序;但是,可以通过设置各种 Hadoop 属性来控制此值,如下表所示。

小文件和 CombineFileInputFormat
小文件和 CombineFileInputFormat
Hadoop 处理少量大文件比处理大量小文件效果更好。一个原因是 FileInputFormat 以这样一种方式生成拆分,即每个拆分都是单个文件的全部或一部分。如果文件非常小(“小”意味着明显小于 HDFS 块)并且有很多文件,那么每个 map 任务将处理很少的输入,并且会有很多(每个文件一个),每个其中强加了额外的簿记开销。将分成 8 个 128 MB 块的 1 GB 文件与 10,000 个左右的 100 KB 文件进行比较。10,000 个文件每个使用一张地图,作业时间可能比具有单个输入文件和八个地图任务的等效文件慢数十或数百倍。
这种情况通过 CombineFileInputFormat 有所缓解,它旨在很好地处理小文件。FileInputFormat 为每个文件创建一个拆分,CombineFileInputFormat 将许多文件打包到每个拆分中,以便每个映射器处理更多文件。至关重要的是,CombineFileInputFormat 在决定将哪些块放置在同一拆分中时会考虑节点和机架的位置,因此它不会影响在典型 MapReduce 作业中处理输入的速度。
当然,如果可能的话,避免很多小文件的情况仍然是一个好主意,因为MapReduce在可以以集群中磁盘的传输速率运行时效果最好,并且处理很多小文件会增加寻道次数需要运行作业。此外,在 HDFS 中存储大量小文件会浪费 NameNode 的内存。
CombineFileInputFormat 不仅仅适用于小文件。它也可以在处理大文件时带来好处,因为它会为每个节点生成一个拆分,该拆分可能由多个块组成。本质上,CombineFileInputFormat 将映射器消耗的数据量与 HDFS 中文件的块大小分离。
防止拆分 某些应用程序不希望拆分文件,因为这允许单个映射器完整地处理每个输入文件。例如,检查文件中所有记录是否已排序的一种简单方法是按顺序遍历记录,检查每条记录是否不小于前一条记录。作为映射任务实现,该算法仅在一个映射处理整个文件时才起作用。
有几种方法可以确保现有文件不被拆分。第一种(快速而肮脏的)方法是将最小分割大小增加到大于系统中最大文件的大小。将其设置为最大值 Long.MAX_VALUE 具有此效果。第二个是子类化您要使用的 FileInputFormat 的具体子类,以覆盖 isSplitable() 方法 3 以返回 false。例如,这是一个不可拆分的 TextInputFormat
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.mapreduce.JobContext;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
/**
*
*
*/
public class NonSplittableTextInputFormat extends TextInputFormat {
@Override
protected boolean isSplitable(JobContext context, Path file) {
return false;
}
}
输入格式
Hadoop 可以处理许多不同类型的数据格式,从纯文本文件到数据库。Hadoop InputFormat 检查作业的输入规范。InputFormat 将 Input 文件拆分为 InputSplit 并分配给单个 Mapper。InputFormat 定义了如何在 Hadoop 中拆分和读取输入文件。
Hadoop InputFormat 是 Map-Reduce 的第一个组件,它负责创建输入拆分并将它们划分为记录。最初,MapReduce 任务的数据存储在输入文件中,而输入文件通常驻留在HDFS 中。尽管这些文件格式是任意的,但可以使用基于行的日志文件和二进制格式。我们使用 InputFormat 定义如何拆分和读取这些输入文件。
InputFormat 类是 Hadoop MapReduce 框架中的基本类之一,它提供以下功能:
应该用于输入的文件或其他对象由 InputFormat 选择。
InputFormat 定义了数据拆分,它定义了单个 Map 任务的大小及其潜在的执行服务器。
InputFormat 定义了 RecordReader,它负责从输入文件中读取实际记录。
我们如何将数据获取到映射器?
我们有两种方法可以在 MapReduce 中将数据获取到映射器:getsplits() 和 createRecordReader(),如下所示
MapReduce 中 InputFormat 的类型
1.文件输入格式
FileInputFormat 是所有使用文件作为数据源的 InputFormat 实现的基类(见下图)。
FileInputFormat 提供了两件事:定义哪些文件作为作业的输入包含的位置,以及为输入文件生成拆分的实现。
FileInputFormat 的输入路径
作业的输入被指定为路径集合,这在限制输入方面提供了极大的灵活性。FileInputFormat 提供四种静态方便的方法来设置作业的输入路径
addInputPath() 和 addInputPaths() 方法向输入列表添加一个或多个路径。
setInputPaths() 方法一次性设置整个路径列表。
路径可以代表一个文件、一个目录,或者,通过使用 glob,可以代表文件和目录的集合。表示目录的路径包括目录中的所有文件作为作业的输入。add 和 set 方法只允许通过包含来指定文件。要从输入中排除某些文件,您可以使用 FileInputFormat 上的 setInputPathFilter() 方法设置过滤器。即使您没有设置过滤器,FileInputFormat 也会使用默认过滤器来排除隐藏文件(名称以点或下划线开头的文件)。如果您通过调用 setInputPathFilter() 设置过滤器,它会作为默认过滤器的补充。换句话说,只有过滤器接受的非隐藏文件才能通过。
FileInputFormat 输入拆分
给定一组文件,FileInputFormat 如何将它们变成拆分?
FileInputFormat 只分割大文件——这里,“大”意味着比 HDFS 块大。拆分大小通常是 HDFS 块的大小,适用于大多数应用程序;但是,可以通过设置各种 Hadoop 属性来控制此值,如下表所示。
小文件和 CombineFileInputFormat
Hadoop 处理少量大文件比处理大量小文件效果更好。一个原因是 FileInputFormat 以这样一种方式生成拆分,即每个拆分都是单个文件的全部或一部分。如果文件非常小(“小”意味着明显小于 HDFS 块)并且有很多文件,那么每个 map 任务将处理很少的输入,并且会有很多(每个文件一个),每个其中强加了额外的簿记开销。将分成 8 个 128 MB 块的 1 GB 文件与 10,000 个左右的 100 KB 文件进行比较。10,000 个文件每个使用一张地图,作业时间可能比具有单个输入文件和八个地图任务的等效文件慢数十或数百倍。
这种情况通过 CombineFileInputFormat 有所缓解,它旨在很好地处理小文件。FileInputFormat 为每个文件创建一个拆分,CombineFileInputFormat 将许多文件打包到每个拆分中,以便每个映射器处理更多文件。至关重要的是,CombineFileInputFormat 在决定将哪些块放置在同一拆分中时会考虑节点和机架的位置,因此它不会影响在典型 MapReduce 作业中处理输入的速度。
当然,如果可能的话,避免很多小文件的情况仍然是一个好主意,因为MapReduce在可以以集群中磁盘的传输速率运行时效果最好,并且处理很多小文件会增加寻道次数需要运行作业。此外,在 HDFS 中存储大量小文件会浪费 NameNode 的内存。
CombineFileInputFormat 不仅仅适用于小文件。它也可以在处理大文件时带来好处,因为它会为每个节点生成一个拆分,该拆分可能由多个块组成。本质上,CombineFileInputFormat 将映射器消耗的数据量与 HDFS 中文件的块大小分离。
防止拆分 某些应用程序不希望拆分文件,因为这允许单个映射器完整地处理每个输入文件。例如,检查文件中所有记录是否已排序的一种简单方法是按顺序遍历记录,检查每条记录是否不小于前一条记录。作为映射任务实现,该算法仅在一个映射处理整个文件时才起作用。
有几种方法可以确保现有文件不被拆分。第一种(快速而肮脏的)方法是将最小分割大小增加到大于系统中最大文件的大小。将其设置为最大值 Long.MAX_VALUE 具有此效果。第二个是子类化您要使用的 FileInputFormat 的具体子类,以覆盖 isSplitable() 方法 3 以返回 false。例如,这是一个不可拆分的 TextInputFormat
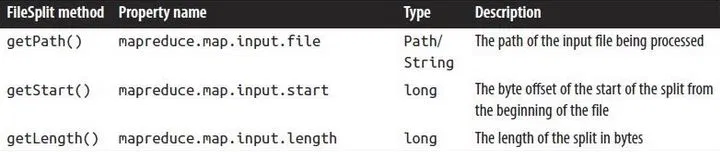
映射器中的文件信息
处理文件输入拆分的映射器可以通过调用 Mapper 的 Context 对象上的 getInputSplit() 方法来查找有关拆分的信息。当输入格式派生自 FileInputFormat 时,此方法返回的 InputSplit 可以强制转换为 FileSplit 以访问下面列出的文件信息,















 2090
2090











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









