







MapReduce是Hadoop的核心组件,它通过将工作划分为一组独立的任务来并行处理大量数据。在 MapReduce 中,数据是一步一步从 Mapper 流向 Reducer。
本教程详细介绍了 MapReduce 作业执行的各个阶段, Input Files, InputFormat in Hadoop, InputSplits, RecordReader, Mapper, Combiner, Partitioner, Shuffling and Sorting, Reducer, RecordWriter and OutputFormat
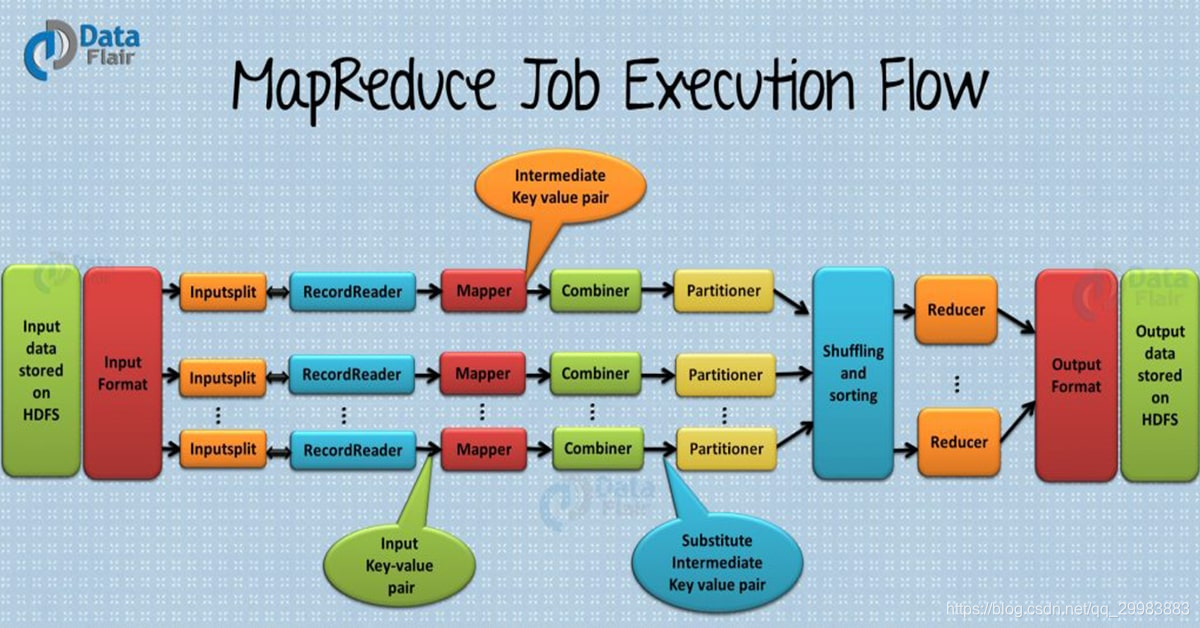
什么是MapReduce
MapReduce是 Hadoop 的数据处理层。它是一个软件框架,用于轻松编写处理存储在Hadoop 分布式文件系统 (HDFS)中的大量结构化和非结构化数据的应用程序。它通过将作业(提交的作业)划分为一组独立的任务(子作业)来并行处理大量数据。通过这种并行处理速度和集群的可靠性得到提高。我们只需要按照 map reduce 工作的方式放置自定义代码(业务逻辑),其余的事情将由引擎处理。
MapReduce 是如何工作的
Hadoop 中,MapReduce 的工作原理是将数据处理分为两个阶段:Map 阶段和 Reduce 阶段。映射是处理的第一阶段,我们指定所有复杂的逻辑/业务规则/昂贵的代码。Reduce 是处理的第二阶段,我们指定轻量级处理,如聚合/求和
Input Files
MapReduce 任务处理的数据通常存储在文件中,输入文件通常位于HDFS 中。这些文件的格式是任意的,也可以使用基于行的日志文件和二进制格式。
InputFormat
InputFormat定义了如何拆分和读取这些输入文件。它选择用于输入的文件或其他对象。
InputSplits
InputSplits由InputFormat创建,代表每个Mapper逻辑处理的数据,每个Map任务处理一个split。map任务数代表InputSplits的数量。
RecordReader
与InputSplit通信,将数据转化为key-value形式,用于mapper处理。一般来说, 使用TextInputFormat 来将数据转换为key-value。。RecordReader 与 InputSplit 通信,直到文件读取完。它为文件中存在的每一行分配字节偏移量(唯一编号)。此外,这些键值对被发送到映射器进行进一步处理。
Mapper
它处理每条输入记录(来自 RecordReader)并生成新的键值对,而 Mapper 生成的这个键值对与输入对完全不同。Mapper 的输出也称为中间输出,写入本地磁盘。Mapper 的输出不存储在 HDFS 上,因为这是临时数据,在 HDFS 上写入会创建不必要的副本(HDFS 也是一个高延迟系统)。映射器的输出传递给组合器进行进一步处理
Combiner
Combiner被称为Mini-reducer。MapReduce的Combiner主要作用在本地合并,他会减小mapper和reducer之间的数据传输。一旦combiner被执行,他的输出将通过partitioner进一步执行。
Partitioner
如果我们正在处理多个 reducer(因为一个 reducer partitioner 没有被使用) Partitioner就会出现。Partitioner从Combiner中获取输出并执行分区。输出的分区基于键进行,然后进行排序。通过哈希函数,密钥(或密钥的子集)用于派生分区。根据MapReduce中的key值,对每个combiner输出进行分区,具有相同key值的记录进入同一个partition,然后每个partition发送给reducer。
Shuffling and Sorting
一旦所有的Mapper完成,他们的输出就会被shuffled到各个Reduce节点上,这是通过网络的数据物理移动。这些移动的数据都是局部合并和排序好的。mapper的输出作为reduce的输入。
Reducer
Reducer主要是让mapper产生的中间数据作为输入数据,并调用reducer函数对每对键值对进行处理。并且Reducer的输出是最后的输出。存储在HDFS中。
RecordWriter
用于将Reducer产生的key-value写入到输出文件中。
OutputFormat
RecordWriter 将这些输出键值对写入输出文件的方式由 OutputFormat 决定。Hadoop 提供的OutputFormat 实例用于在HDFS或本地磁盘上写入文件。














 1949
1949











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









