







数据预处理
Binarizer: 二值化
用于将数值特征二值化。它将特征值与给定的阈值进行比较,并将特征值转换为布尔值(0 或 1),取决于特征值是否超过阈值
Binarizer(*, threshold=0.0, copy=True)
参数:
- threshold:指定阈值,默认为 0.0。特征值大于阈值的将被置为 1,小于或等于阈值的将被置为 0。
- copy:是否创建输入数据的副本,默认为 True。
from sklearn.preprocessing import Binarizer
import numpy as np
# 创建带有数值特征的数据
X = np.array([[1.5], [2.7], [0.3]])
# 创建 Binarizer 对象
binarizer = Binarizer(threshold=1.0)
# 使用阈值对特征进行二值化
binary_data = binarizer.transform(X)
print(binary_data)
输出结果

MaxAbsScaler: 最大绝对值缩放
用于通过除以每个特征的最大绝对值来缩放数据,将数据的范围限制在 [-1, 1] 之间。它是一种无中心化的缩放方法,保留了数据的原始分布形状。
MaxAbsScaler 的特点是它保留了数据的原始分布形状,并将每个特征的值映射到 [-1, 1] 的范围内。这在某些情况下对于特征缩放非常有用,例如在稀疏数据或特征值有较大差异的情况下。
from sklearn.preprocessing import MaxAbsScaler
import numpy as np
# 创建带有数值特征的数据
X = np.array([[1, 5], [3, 4], [5, -6]])
# 创建 MaxAbsScaler 对象
scaler = MaxAbsScaler()
# 使用最大绝对值进行缩放
scaled_data = scaler.fit_transform(X)
print(scaled_data)
输出结果

MinMaxScaler: 最小-最大缩放
通过缩放数据将每个特征的值限定在给定的范围内,默认为 [0, 1]。它将每个特征的值映射到指定的范围内,保留了数据的原始分布形状
MinMaxScaler 的特点是它将数据的值映射到指定的范围内,并保留了数据的原始分布形状。这种缩放方法常用于需要将特征值限定在一定范围内的情况,例如神经网络训练或特征工程中的数据标准化处理
MinMaxScaler(feature_range=(0, 1), *, copy=True, clip=False)
参数介绍
- feature_range:指定特征值的范围,默认为 [0, 1]
from sklearn.preprocessing import MinMaxScaler
import numpy as np
# 创建带有数值特征的数据
X = np.array([[1, 2], [3, 4], [5, 6]])
# 创建 MinMaxScaler 对象
scaler = MinMaxScaler(feature_range=(0, 1))
# 使用最小值和最大值进行缩放
scaled_data = scaler.fit_transform(X)
print(scaled_data)
结果

Normalizer: 归一化
它的作用是将每个样本的特征向量转换为具有相同单位长度的向量。这意味着归一化后的每个样本都位于一个共同的单位球上,其欧几里得范数(L2范数)为1。
归一化是数据预处理的一种常见技术,特别适用于需要计算样本之间的相似性或距离的任务。通过归一化处理,可以消除特征之间的尺度差异,确保每个样本的特征向量具有相同的单位长度。这对于许多机器学习算法和模型是重要的,因为它可以改善算法的收敛性和性能。
归一化过程的原理是通过对特征向量的每个元素进行缩放,使得整个特征向量的范数等于1。在 Normalizer 中,有三种归一化的范数类型可供选择:L1范数归一化(norm=‘l1’)、L2范数归一化(norm=‘l2’)、Max范数归一化(norm=‘max’)
from sklearn.preprocessing import Normalizer
import numpy as np
# 创建带有数值特征的数据
X = np.array([[1, 2], [3, 4], [5, 6]])
# 创建 Normalizer 对象
normalizer = Normalizer(norm='l2')
# 对输入数据进行归一化处理
normalized_data = normalizer.transform(X)
print(normalized_data)
StandardScaler: 标准化
用于对数据进行标准化处理。标准化是一种常见的数据预处理技术,旨在消除特征之间的尺度差异,使得数据的分布符合标准正态分布(均值为0,标准差为1)
标准化的原理是将数据进行中心化(去均值)和缩放为单位方差的过程。具体而言,对于每个特征,标准化将其值减去均值,然后除以标准差。这使得特征的值在整个数据集上具有零均值和单位方差,将数据的分布调整为标准正态分布。标准化后的数据具有更好的可比性和可解释性,并且适用于许多机器学习算法和模型。
StandardScaler(*, copy=True, with_mean=True, with_std=True)
- with_mean:是否将数据中心化(去均值),默认为 True。
- with_std:是否将数据缩放为单位方差,即除以标准差,默认为 True
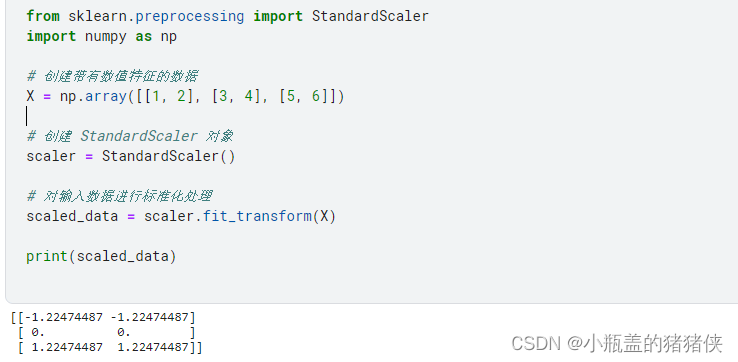
from sklearn.preprocessing import StandardScaler
import numpy as np
# 创建带有数值特征的数据
X = np.array([[1, 2], [3, 4], [5, 6]])
# 创建 StandardScaler 对象
scaler = StandardScaler()
# 对输入数据进行标准化处理
scaled_data = scaler.fit_transform(X)
print(scaled_data)
结果
QuantileTransformer: 分位数转换
RobustScaler: 鲁棒缩放
,用于对数据进行缩放和中心化处理。它通过对数据进行缩放和平移,使得数据在存在异常值的情况下能够更好地适应模型的训练
RobustScaler(
*,
with_centering=True,
with_scaling=True,
quantile_range=(25.0, 75.0),
copy=True,
unit_variance=False,
)
参数:
- with_centering:指定是否进行中心化处理,默认为 True。
- with_scaling:指定是否进行缩放处理,默认为 True。
- quantile_range:指定缩放范围的分位数范围,默认为 (25.0, 75.0)。
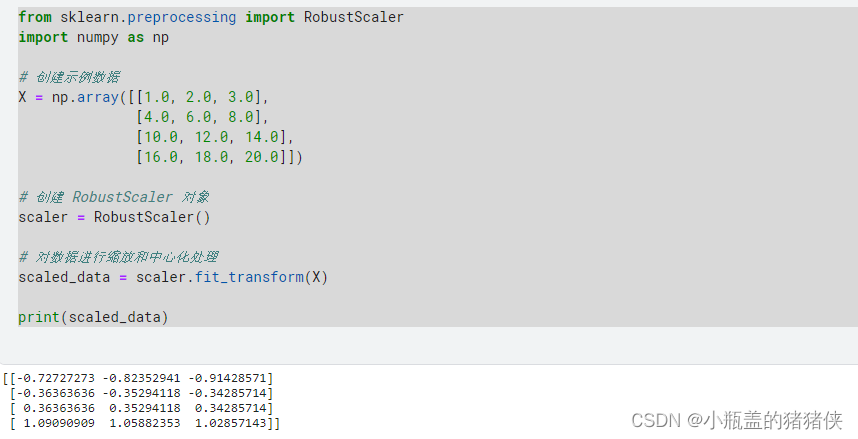
from sklearn.preprocessing import RobustScaler
import numpy as np
# 创建示例数据
X = np.array([[1.0, 2.0, 3.0],
[4.0, 6.0, 8.0],
[10.0, 12.0, 14.0],
[16.0, 18.0, 20.0]])
# 创建 RobustScaler 对象
scaler = RobustScaler()
# 对数据进行缩放和中心化处理
scaled_data = scaler.fit_transform(X)
print(scaled_data)
执行结果
PowerTransformer: 幂变换
KernelCenterer: 中心化数据
标签处理:
Binarizer: 标签二值化
同上
LabelBinarizer: 标签二进制化
用于将分类变量进行二进制编码。它将每个类别转换为一个二进制向量,其中只有一个元素为 1,表示该类别,其他元素为 0
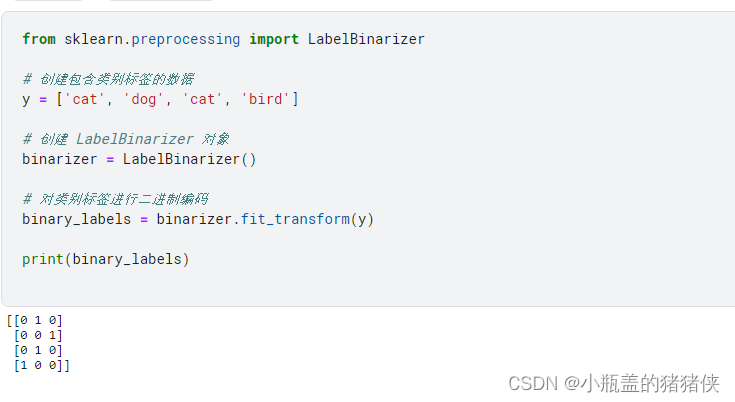
from sklearn.preprocessing import LabelBinarizer
# 创建包含类别标签的数据
y = ['cat', 'dog', 'cat', 'bird']
# 创建 LabelBinarizer 对象
binarizer = LabelBinarizer()
# 对类别标签进行二进制编码
binary_labels = binarizer.fit_transform(y)
print(binary_labels)
执行结果
LabelEncoder: 标签编码
用于对分类变量进行整数编码。它将每个类别标签映射到一个整数,从 0 开始递增
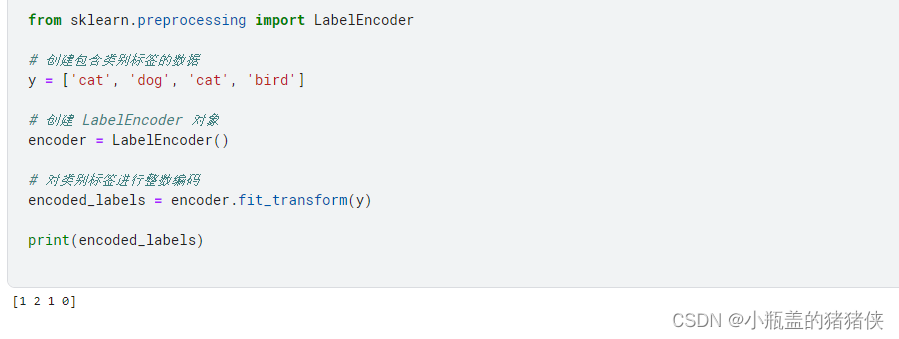
from sklearn.preprocessing import LabelEncoder
# 创建包含类别标签的数据
y = ['cat', 'dog', 'cat', 'bird']
# 创建 LabelEncoder 对象
encoder = LabelEncoder()
# 对类别标签进行整数编码
encoded_labels = encoder.fit_transform(y)
print(encoded_labels)
执行结果
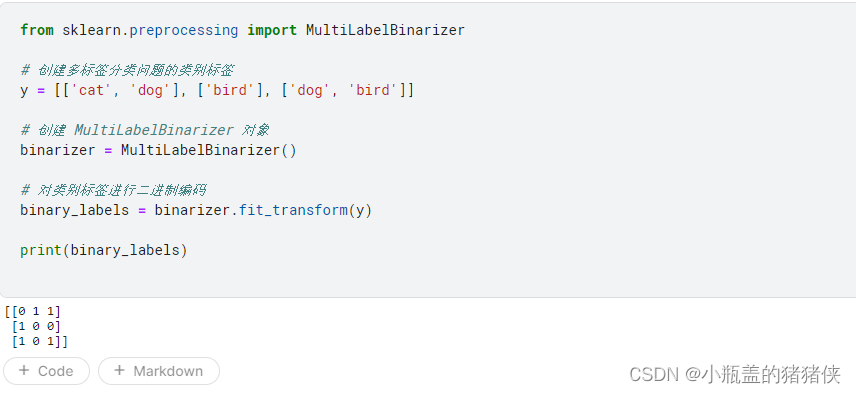
MultiLabelBinarizer: 多标签二进制化
,用于对多标签分类问题中的类别标签进行二进制编码。它将每个样本的类别标签转换为一个二进制向量,其中每个元素表示一个可能的类别,如果样本属于该类别,则对应元素为 1,否则为 0。
from sklearn.preprocessing import MultiLabelBinarizer
# 创建多标签分类问题的类别标签
y = [['cat', 'dog'], ['bird'], ['dog', 'bird']]
# 创建 MultiLabelBinarizer 对象
binarizer = MultiLabelBinarizer()
# 对类别标签进行二进制编码
binary_labels = binarizer.fit_transform(y)
print(binary_labels)
执行结果
数据变换:
FunctionTransformer: 自定义函数转换
KBinsDiscretizer: 定宽离散化
KernelPCA: 核主成分分析
LabelEncoder: 标签编码
MaxAbsScaler: 最大绝对值缩放
MinMaxScaler: 最小-最大缩放
Normalizer: 归一化
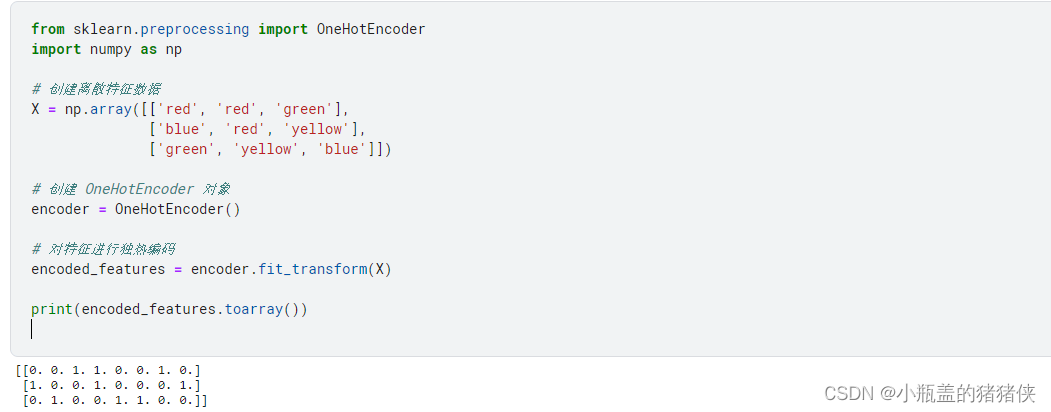
OneHotEncoder: 独热编码
用于对离散特征进行独热编码。它将每个离散特征的每个取值转换为一个二进制特征向量,其中只有一个元素为 1,表示该取值,其他元素为 0。
from sklearn.preprocessing import OneHotEncoder
import numpy as np
# 创建离散特征数据
X = np.array([['red', 'red', 'green'],
['blue', 'red', 'yellow'],
['green', 'yellow', 'blue']])
# 创建 OneHotEncoder 对象
encoder = OneHotEncoder()
# 对特征进行独热编码
encoded_features = encoder.fit_transform(X)
print(encoded_features.toarray())
执行结果
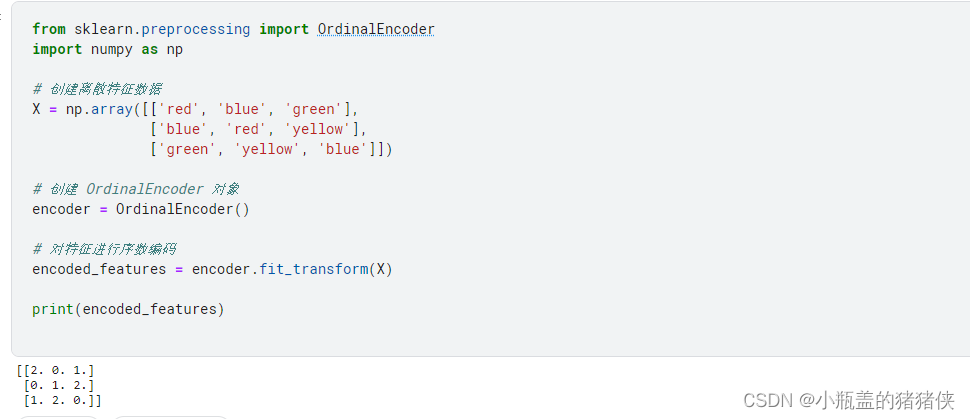
OrdinalEncoder: 有序编码
用于对离散特征进行序数编码。它将每个离散特征的每个取值映射为一个整数,从 0 开始递增。
from sklearn.preprocessing import OrdinalEncoder
import numpy as np
# 创建离散特征数据
X = np.array([['red', 'blue', 'green'],
['blue', 'red', 'yellow'],
['green', 'yellow', 'blue']])
# 创建 OrdinalEncoder 对象
encoder = OrdinalEncoder()
# 对特征进行序数编码
encoded_features = encoder.fit_transform(X)
print(encoded_features)
执行结果
ordinalEncoder与LabelEncoder区别
编码方式不同:
OrdinalEncoder 对每个特征的取值进行序数编码,将每个取值映射为一个整数。编码后的整数值的大小具有一定的顺序性,但不一定具有数值意义。
LabelEncoder 对每个类别标签进行整数编码,将每个类别标签映射为一个整数。编码后的整数值只是用来区分不同的类别,没有顺序或数值意义。
应用场景不同:
OrdinalEncoder 适用于处理多个离散特征的编码,每个特征的取值之间没有明确的类别关系,仅需将其映射为整数。
LabelEncoder 适用于处理单个分类变量的编码,其中类别之间没有明确的顺序关系。
处理方式不同:
OrdinalEncoder 适用于处理离散特征的编码,对于多个特征和多个类别标签,可以同时进行编码。
LabelEncoder 主要用于处理单个分类变量的编码,对于多个类别标签,需要对每个类别标签进行独立的编码。














 6311
6311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









