






目录
摘要
本周阅读了一篇将RAG和网安领域相结合的论文:Vul-RAG。Vul-RAG的核心目标是通过结合大语言模型(LLM)和知识检索增强生成(RAG)技术,解决现有漏洞检测方法在区分具有高相似性的漏洞代码和正确代码时的局限性。论文的工作流程分为三个阶段:第一阶段,先对离线漏洞知识库进行构建。从现有的CVE(通用漏洞披露)实例中提取多维度的漏洞知识,包括功能语义、漏洞原因和修复方案。这些知识通过LLM生成并抽象化,形成一个结构化的知识库。第二阶段,对在线漏洞知识进行检索。对于给定的代码片段,基于功能语义从知识库中检索相关的漏洞知识。检索过程采用BM25算法和重排序策略,确保返回的知识与目标代码高度相关。第三阶段,进行知识增强的漏洞检测。利用LLM结合检索到的知识,通过推理判断目标代码是否存在漏洞。简单来说,LLM会检查代码是否表现出与检索知识相同的漏洞原因或缺失相应的修复方案。实验结果表明,Vul-RAG在PairVul基准测试中显著优于现有技术,准确率和配对准确率分别提升了12.96%和110%。此外,用户研究表明,Vul-RAG生成的漏洞知识能够有效帮助开发者理解代码漏洞,将人工检测的准确率从0.60提升到0.77。
Abstract
This week I studied Vul-RAG, an innovative paper that integrates Retrieval-Augmented Generation (RAG) with cybersecurity for vulnerability detection. The framework addresses critical limitations in existing methods by combining large language models (LLMs) with knowledge-level RAG to effectively distinguish between highly similar vulnerable and correct code segments. Its three-phase approach begins with constructing an offline knowledge base where multidimensional vulnerability knowledge (functional semantics, root causes, and fixes) is extracted from CVEs and abstracted using LLMs. The system then performs online retrieval of relevant vulnerability knowledge for target code using BM25 algorithm and re-ranking strategies based on functional semantics. Finally, it conducts knowledge-augmented detection by having LLMs analyze whether the code exhibits retrieved vulnerability patterns or lacks corresponding fixes. Experimental results demonstrate Vul-RAG’s superiority, achieving 12.96% higher accuracy and 110% improved pairwise accuracy on the PairVul benchmark, while user studies show its generated knowledge boosts developers’ manual detection accuracy from 0.60 to 0.77 by providing explainable insights into code vulnerabilities.
Vul-RAG:通过知识级 RAG 增强基于 LLM 的漏洞检测
Title: Vul-RAG: Enhancing LLM-based Vulnerability Detection via Knowledge-level RAG
Author: Xueying Du, Geng Zheng, Kaixin Wang, Jiayi Feng, Wentai Deng, Mingwei Liu, Bihuan Chen, Xin Peng, Tao Ma, Yiling Lou
Source: Arxiv
Arxiv: https://arxiv.org/abs/2406.11147
研究背景
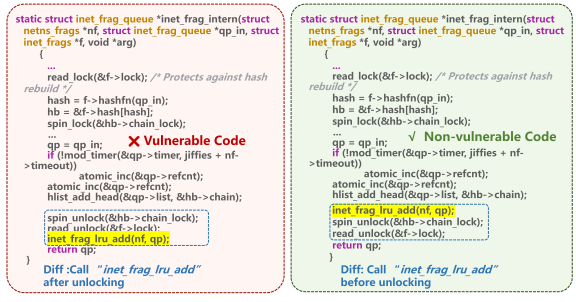
软件漏洞是安全领域的重要问题,传统漏洞检测方法主要依赖静态分析和动态分析技术。近年来,深度学习技术(尤其是大语言模型)在漏洞检测中展现出潜力。然而,现有方法存在以下问题:
- 语义理解不足:大多数学习型漏洞检测技术将问题建模为二分类任务,模型仅输出“漏洞”或“非漏洞”标签,缺乏对代码语义的深入理解。论文通过初步研究发现,现有模型在区分高相似性的漏洞代码(如上图所示)和正确代码时表现不佳(准确率仅为0.50~0.54)。
- 解释性差:深度学习模型的“黑盒”特性使得开发者难以理解其检测逻辑,降低了结果的可靠性。
RAG是一种通过检索外部知识增强LLM生成能力的技术,已在代码生成等任务中取得成功。论文的创新点在于将RAG应用于漏洞检测领域,通过构建和检索高层次的漏洞知识(而非具体代码),提升模型的语义理解和推理能力。
方法论
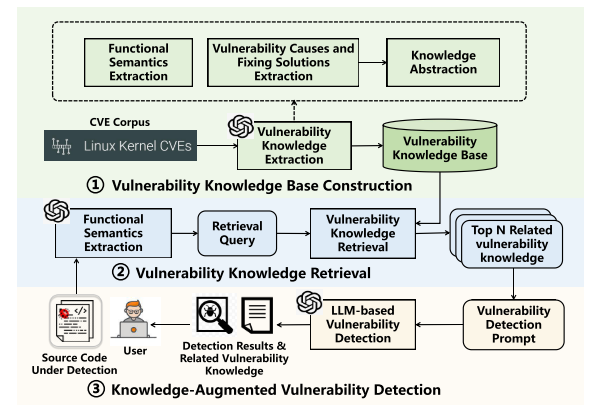
Vul-RAG的方法论围绕知识库构建、知识检索和漏洞检测三个核心阶段展开。
1.漏洞知识库构建
知识库的构建是Vul-RAG的基础,其核心在于从CVE实例中提取多维度的漏洞知识:
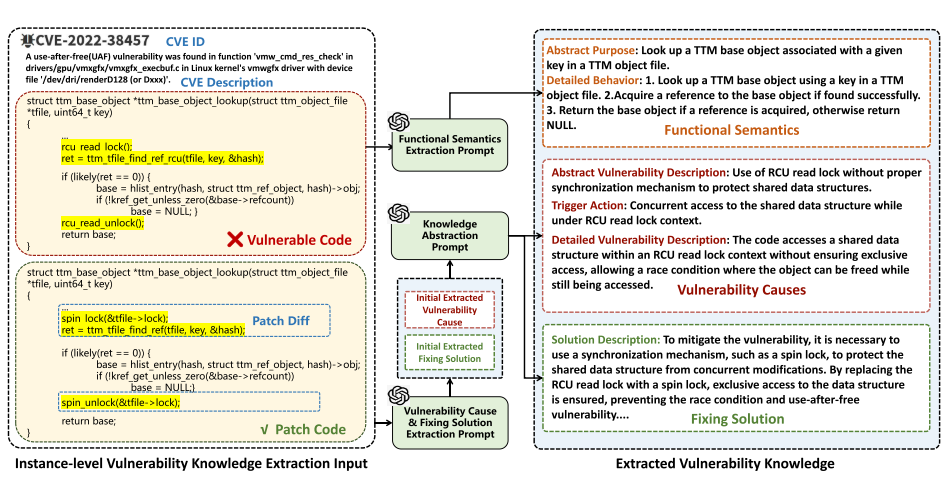
输入阶段
左侧提供原始数据:漏洞代码片段(含未受保护的共享数据结构访问)、补丁代码(添加了spin_lock保护)以及CVE描述文本(说明这是RCU锁上下文中的竞态条件漏洞)。
LLM知识提取
中间层显示LLM通过两轮提示工程生成结构化输出:
- 功能语义:先提取代码的抽象目的(如"处理IO工作进程")和详细行为(如"访问共享数据结构");
- 漏洞原因:通过对比漏洞/补丁代码,总结出具体根因(如"缺少同步机制导致use-after-free")和触发动作(如"并发访问共享数据");
- 修复方案:分析补丁差异,抽象出通用修复模式(如"采用类似mutex_lock的锁机制")。
知识抽象化
右侧展示最终知识表示,其中具体代码元素(如函数名io_worker_handle_work、变量&davdev->mutex)被替换为通用描述,形成与实现无关的漏洞模式。这种抽象使知识能跨不同代码库复用,是RAG检索有效性的关键。
整个流程体现了Vul-RAG将原始代码→具体分析→通用知识的转化逻辑,为后续的语义检索提供标准化输入。
2.漏洞知识检索
检索阶段的目标是为目标代码找到最相关的漏洞知识。检索过程分为三步:
- 查询生成:提取目标代码的功能语义(抽象目的和详细行为),与代码本身共同构成多维查询。不同于传统方法仅依赖代码文本,Vul-RAG额外提取目标代码的功能语义(包括抽象目的和详细行为),形成多维度查询。例如,给定一段网络数据包处理代码,LLM可能生成抽象目的(如“解析网络协议头部”)和详细行为(如“检查数据包长度并提取字段”),这些信息与代码本身共同构成检索依据。
- 候选知识检索:采用BM25算法(一种基于词频和逆文档频率的检索模型)分别计算代码、抽象目的和详细行为与知识库条目的相似度。每个查询维度(代码、抽象目的、详细行为)独立检索Top-10候选知识,合并后得到10~30条候选(可能重复)。
- 重排序:使用Reciprocal Rank Fusion (RRF)策略对候选知识重新排序,综合考虑其在各查询维度下的排名。最终选择Top-10知识条目,确保覆盖功能相似且漏洞模式相关的案例。
3.知识增强的漏洞检测
在检索到相关漏洞知识后,Vul-RAG通过迭代推理判断目标代码是否存在漏洞,具体流程如下:
因果匹配(Cause-Solution Checking)
对每条检索到的知识,LLM依次检查目标代码是否满足两个条件:
- 存在相同的漏洞原因(如“未同步访问共享资源”);
- 缺乏对应的修复方案(如“未添加锁机制”)。
若同时满足,则判定为漏洞;否则继续检查下一条知识。
迭代终止条件
- 提前终止:若某条知识匹配成功,立即返回“漏洞”结论;
- 全量遍历:若所有知识均不匹配,最终判定为“非漏洞”。
提示设计(Prompt Engineering)
检测阶段使用两类专用提示模板:
- 漏洞原因检测提示:要求LLM对比目标代码与知识中的漏洞模式;
- 修复方案检测提示:验证代码是否已应用修复措施。
例如,针对CWE-416(Use-After-Free),提示会要求模型检查“异步事件处理中是否存在未保护的资源释放”。
与传统方法的对比
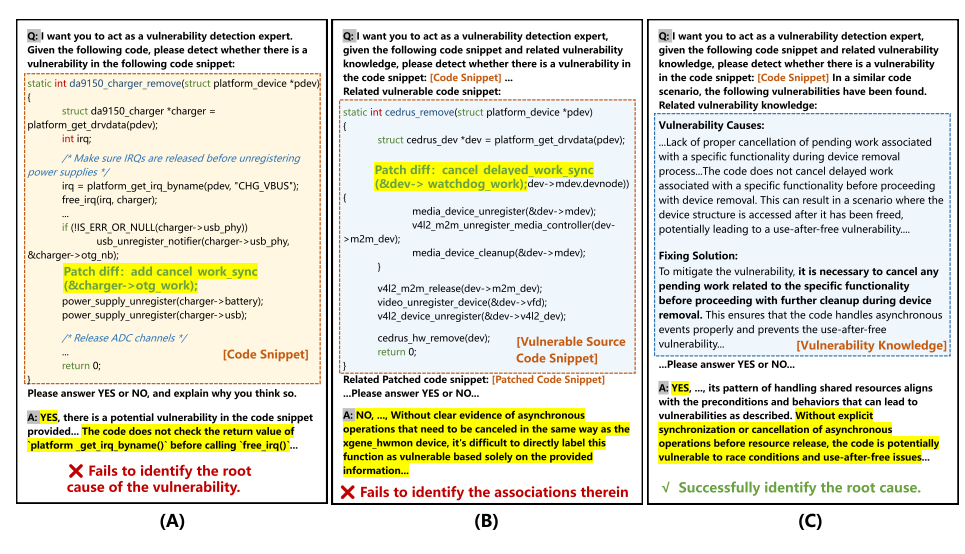
- Basic GPT-4(图A):直接使用GPT-4检测时,模型错误地将漏洞归因于"未检查函数返回值"(实际应为"异步事件导致的竞态条件"),说明纯LLM缺乏领域知识易产生误判。
- Code-based RAG(图B):虽然检索到功能相似的代码片段(含相同漏洞),但GPT-4仍无法关联具体漏洞模式,证明仅靠代码相似性不足以触发正确推理。
- Vul-RAG(图C):提供结构化知识(如"异步事件处理中未同步导致use-after-free")后,GPT-4准确识别出漏洞根因和修复方案,验证了知识表示的核心价值。
因此由上图可知,高层次的漏洞知识(而非原始代码)能有效引导LLM的推理方向。
检索策略的优化效果
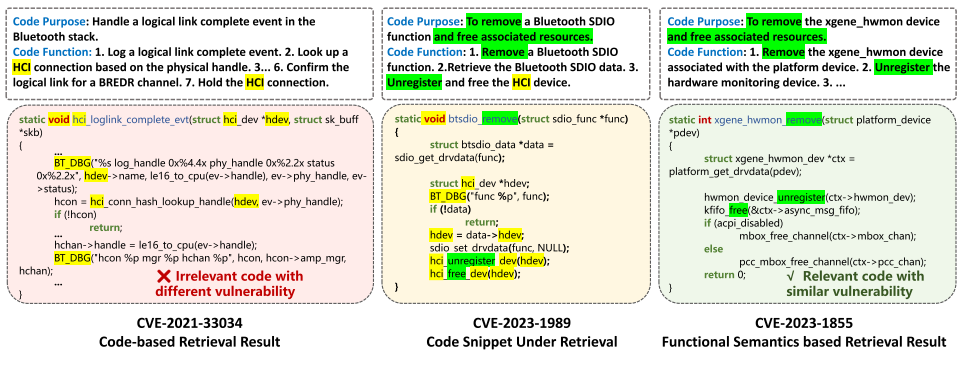
- 代码级检索(Code-based Retrieval)检索到CVE-2021-33034的代码,虽共享部分变量名(黄色高亮),但功能语义不同(一个是设备移除处理,一个是内存分配),导致漏洞原因不匹配。
- 语义级检索(Vul-RAG Retrieval)检索到CVE-2023-1855的代码,功能语义高度匹配(绿色高亮,均涉及"异步设备移除"),且漏洞原因一致(未处理异步事件)。
由上图可知,结合功能语义的检索策略能更精准匹配漏洞模式,避免代码表面相似性的干扰。
创新性
Vul-RAG的创新性主要体现在以下方面:
多维漏洞知识表示:首次提出从功能语义、漏洞原因和修复方案三个维度表示漏洞知识,超越了传统基于代码相似性的方法。
知识级RAG框架:与常见的代码级RAG不同,Vul-RAG通过检索高层次的漏洞知识(而非具体代码)增强LLM的推理能力,解决了代码相似性不足以反映语义相似性的问题。
PairVul基准测试:论文构建了首个专注于高相似性漏洞/非漏洞代码对的基准测试,揭示了现有技术的局限性,为未来研究提供了新的评估标准。
实验结果
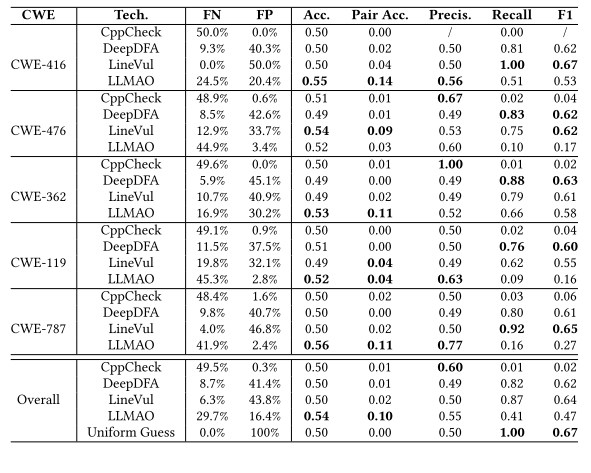
优于现有技术:在PairVul测试集上,Vul-RAG的准确率(0.61)和配对准确率(0.21)显著高于LLMAO、LineVul等基线方法。尤其是配对准确率的提升(110%)表明其在区分相似代码对方面的优势。
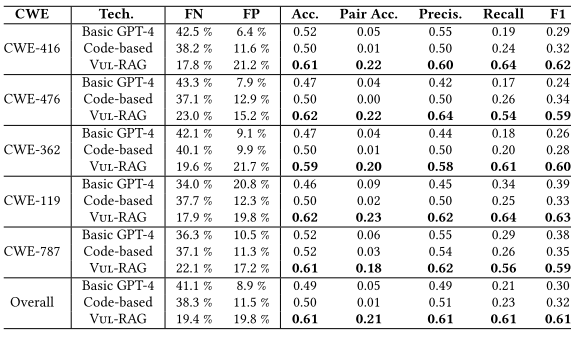
优于GPT-4基线:与直接使用GPT-4或代码级RAG增强的GPT-4相比,Vul-RAG的准确率更高。例如,在CWE-416类别中,Vul-RAG的准确率为0.61,而GPT-4仅为0.52。
局限性
知识库覆盖范围:Vul-RAG的性能依赖于知识库的完整性。若目标代码的漏洞类型未包含在知识库中,则无法有效检测。
领域通用性:当前实验集中于Linux内核CVEs,在其他系统(如Web应用)中的效果需进一步验证。
计算成本:知识库构建和LLM推理需要较高的计算资源,可能限制其在实际中的部署。
总结
这篇论文提出的Vul-RAG框架通过创新性地将知识级检索增强生成(RAG)技术应用于漏洞检测领域,有效解决了现有深度学习方法在区分高相似性漏洞/非漏洞代码时表现不佳的问题。其核心贡献在于构建了包含功能语义、漏洞原因和修复方案的多维知识库,并通过语义检索和迭代推理机制,使大语言模型能够基于通用漏洞模式而非具体代码特征进行判断。实验证明,该方法在PairVul基准测试中显著优于现有技术(准确率提升12.96%),同时生成的解释性知识能将人工检测准确率提高28%。尽管存在知识库覆盖范围的局限性,Vul-RAG仍为提升漏洞检测的准确性和可解释性提供了重要思路,展现了知识增强方法在软件安全领域的应用潜力。未来工作可以围绕扩展知识库、优化检索策略以及降低计算成本展开。总体而言,Vul-RAG为漏洞检测的自动化和可解释性提供了重要参考,是LLM在软件安全领域的一次成功应用。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









