







文章目录
- [置顶]spring常识
- -18
- -19 shared nothing、shared disk、shared storage
- -18 structured semi-structured unstructured
- -17 如何抓包并分析
- -16 dns映射的ip变化了,java应用会报错吗
- -15 jedis和lettuce对连接的处理有何不同?
- -14 redis cluster 扩容影响服务吗?
- -13 redis与一致性hash
- -12 微服务中如何传递两个服务间的异常?
- -11 正排索引、倒排索引
- -10 子网和掩码
- -9 subnet ipv4
- -8 websocket协议、SSE协议
- -7.Kafka重要细节
- -6. Kafka V.S. Rocketmq
- -5. zk的重要概念一览
- -4.zk 的一致性(顺序一致性)
- -3. CAP
- -2.位操作
- -1.上游和下游
- 0.Jdk新特性
- 1.包依赖
- 2.slf4j如何找到 logback 包
- 3. 如何预热一个项目的所有类?
- 4. KafkaAppender
- 5. 设计一个公共的Log模块
- 6. Java所有的对象都是在堆创建吗?
- 7. time_wait + close_wait
- 9. 为啥少见"写超时",而多见读超时?
- 10.@Test要求方法是public ?
- 11. 如何获取线程栈轨
- 12. 设计模式
- 13. MDC
- 14.Marker
- 15. netty pipeline 责任链和 tomcat filter chain等普通责任链有啥区别
- 16.什么样的数据放在堆内/堆外
- 17. 什么情况下会发生死锁
- 18. 为啥overrdie equals()方法 后一定要override hashCode
- 19. http `reponse.write()` work ?
- 20. 注解可以继承吗?
- 21. filter interceptor aop
- 22. `jcl-over-slf4j`
- 23. 如何对多对多的关系建模
- 24. 如何动态调整`logback` logger level
- 25. `ch.qos.logback.classic.pattern.ClassicConverter`
- 26. java动态表达式
- 27. 代理
- 28. 重试时间退避算法
- 29. mongo V.S. ES (TODO)
- 30. server-sent event(sse)
- 31. swap
- 32. xss\csrf
[置顶]spring常识
-18
- 修改docker挂载出来的文件,需要重启Docker?
- 代码逻辑要10s,但是锁租期5s
- springboot优雅停机?
- 两条线程交替打印
- hashmap默认大小、扩容
- 多数据源切换
- 简单和抽象工厂模式?
- spring里多线程的事务
-19 shared nothing、shared disk、shared storage
这三是说 分布式系统中的存储策略.
- shared nothing : 存算一体,比如ck doris
- shared disk: 存算分离,比如基于NFS; 侧重于共享物理磁盘
- shared storage: 也有人把它和 shared disk当一个概念,不过更多是基于OSS S3 存储(逻辑概念)
-18 structured semi-structured unstructured
- structured : 有严格的schema ,典型就是MySQL table
- semi-structured : 不严格的schema ,典型就是Json;仍然有tag来作为schema
- unstructured : email txt video, etc 这样的数据类型
-17 如何抓包并分析
[root@localhost nginx]# tcpdump -i ens9f0 port 8070
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on ens9f0, link-type EN10MB (Ethernet), capture size 262144 bytes
19:52:41.077266 IP 10.34.xxx.2.46710 > localhost.localdomain.8070: Flags [S], seq 3072285830, win 29200, options [mss 1460,sackOK,TS val 3696228912 ecr 0,nop,wscale 7], length 0
19:52:41.077420 IP localhost.localdomain.8070 > 10.34.xxx.2.46710: Flags [S.], seq 489360408, ack 3072285831, win 28960, options [mss 1460,sackOK,TS val 3696199987 ecr 3696228912,nop,wscale 7], length 0
19:52:41.077564 IP 10.34.xxx.2.46710 > localhost.localdomain.8070: Flags [.], ack 1, win 229, options [nop,nop,TS val 3696228912 ecr 3696199987], length 0
-- 这三行是 “三次握手”
19:52:41.077620 IP 10.34.xxx.2.46710 > localhost.localdomain.8070: Flags [P.], seq 1:1074, ack 1, win 229, options [nop,nop,TS val 3696228912 ecr 3696199987], length 1073
19:52:41.077648 IP localhost.localdomain.8070 > 10.34.xxx.2.46710: Flags [.], ack 1074, win 244, options [nop,nop,TS val 3696199987 ecr 3696228912], length 0
-- 这两行是“请求-响应“
19:52:41.105680 IP localhost.localdomain.8070 > 10.34.xxx.2.46710: Flags [P.], seq 1:2700, ack 1074, win 244, options [nop,nop,TS val 3696200015 ecr 3696228912], length 2699
19:52:41.105873 IP 10.34.xxx.2.46710 > localhost.localdomain.8070: Flags [.], ack 1449, win 251, options [nop,nop,TS val 3696228940 ecr 3696200015], length 0
19:52:41.105919 IP 10.34.xxx.2.46710 > localhost.localdomain.8070: Flags [.], ack 2700, win 274, options [nop,nop,TS val 3696228940 ecr 3696200015], length 0
-- 这三行是 一个请求,二个ack (二个ack是因为有拆包的过程)
19:52:41.107456 IP localhost.localdomain.8070 > 10.34.xxx.2.46710: Flags [F.], seq 2700, ack 1074, win 244, options [nop,nop,TS val 3696200017 ecr 3696228940], length 0
-- 服务端(执行tcpdump的机器)发出FIN包,请求结束连接; 同时应答 (ack),所以是 `[F.]` (注意这里有个 . )
-- 注意: 这里是 服务端(执行tcpdump的机器) 提出来要 关闭连接的!!!(注意和http协议结合起来理解)
[F.]: The server (localhost.localdomain) sends a packet with the FIN flag set, indicating its intention to close the connection. It also includes an acknowledgment (ACK) for the data it received from the client.
19:52:41.107819 IP 10.34.xxx.2.46710 > localhost.localdomain.8070: Flags [F.], seq 1074, ack 2701, win 274, options [nop,nop,TS val 3696228942 ecr 3696200017], length 0
-- 客户端(浏览器端)回 FIN
[F.]: The client (10.34.xxx.2) responds with its own FIN packet, indicating its intention to close the connection. It also includes an acknowledgment (ACK) for the data it received from the server.
19:52:41.107952 IP localhost.localdomain.8070 > 10.34.xxx.2.46710: Flags [.], ack 1075, win 244, options [nop,nop,TS val 3696200017 ecr 3696228942], length 0
-- 服务端(执行tcpdump的机器)ACK,连接关闭
11 packets captured
26 packets received by filter
0 packets dropped by kernel
-16 dns映射的ip变化了,java应用会报错吗
- 根据JVM的实现不同,dns ttl会持续30s - 2min的时间(
java -Dsun.net.inetaddr.ttl=30 app.jar),因此已经建立的连接如果dns映射的IP地址变化了,应用可能会有异常;但如果是ip变化之后,才建立的连接,那倒是没事。 - 有的框架自己也可能缓存 dns映射的ip,这个就说不好影响了
-15 jedis和lettuce对连接的处理有何不同?
Jedis:
- 同步阻塞库
- Jedis connection 是线程不安全的
- 一般使用jedis pool
lettuce:
- 基于netty,可以异步非阻塞、事件驱动
- lettuce连接线程安全
- 也支持池化连接对象,但执行简单命令的场景下,不需要创建连接池,性能也不差,但在类似redis事务这样的特殊场景下,可以考虑连接池
-14 redis cluster 扩容影响服务吗?
如题,答案是不影响。
redis cluster增加节点,会resharding:部分数据会从现存节点 迁移(move)到新节点。
由于集群内部的通讯机制(gossip),所有节点都会告知到新节点;
同时有客户端的路由机制在,客户端会根据节点返回的moved指令重定向到正确的节点
-13 redis与一致性hash
参考文献
redis集群 并没有使用一致性hash环的数据结构,而是使用 槽(slot,即逻辑分区) 。集群把所有的“物理节点”映射到[0-16383]槽上(不一定是平均分配),cluster 负责维护 node<->slot<->value。槽(slot) 的计算方法CRC16(key) % 16384。
Q: 什么是一致性hash环?
解决:分布式场景下,数据如何均匀分布在存储节点,并在增删节点时,使受待迁移的数据量最小。可用于分布式缓存的场景。
为了保证“均匀性”,还可以增加虚拟节点映射(缓存数据 ➜ 虚拟节点 ➜ 真实节点)
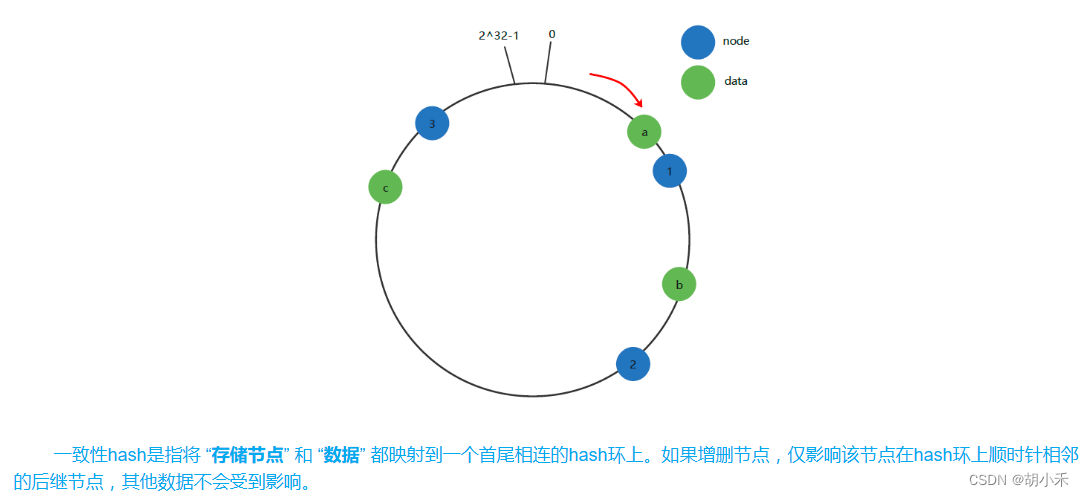
Q: 为啥不使用一致性hash环?
A: 一致性哈希的节点分布基于圆环,无法很好的手动控制数据分布;有的节点可能硬件性能差,需要少存数据,这种场景下用一致性hash环不好操作。
-12 微服务中如何传递两个服务间的异常?
很简单,以springcloud 那套为例,就是包装下异常,加上状态码 返回就行
-11 正排索引、倒排索引
正排索引:文档到单词的映射
倒排索引:单词到文档的映射
倒排索引核心数据结构:
- 词典(Dictionary):存储的是文档中包含的所有单词或关键词;有一个指针指向 倒排列表
- 倒排列表(Posting List)
-10 子网和掩码
在计算机网络中,子网掩码(Subnet Mask)用于将一个 IP 地址划分为网络部分和主机部分。这样做的目的是将一个大的 IP 地址空间划分为多个小的子网,以便更有效地管理网络资源和提高网络安全性。
子网(Subnet):子网是一个逻辑上的概念,表示在网络中划分出的一个子网络。每个子网包含一组特定的 IP 地址,这些 IP 地址共享相同的网络前缀。子网可以根据网络规模和需求的不同,划分成不同大小的子网。
掩码(Mask):子网掩码是一个用于掩盖 IP 地址的一部分,用于指示 IP 地址中哪些位是网络部分,哪些位是主机部分。掩码中的“1”位表示网络部分,而“0”位表示主机部分。掩码的长度(即“1”位的数量)决定了网络的大小和可用主机数量。
例如,对于 IPv4 地址 192.168.1.100,如果子网掩码为 255.255.255.0,那么网络部分是前三个字节 192.168.1,而主机部分是最后一个字节 100。这意味着该 IP 地址属于一个子网中的某个主机,而这个子网的网络地址是 192.168.1.0,可以容纳 256 个主机(其中两个地址保留为网络地址和广播地址,因此实际可用主机数量为 254)。
注:192.168.1.100 是 “192.168.1.0” to "192.168.1.255"网段 (也记为 192.168.1.0/24 )的其中一个IP
-9 subnet ipv4
(from chatgpt)
-
子网掩码:IPv4中的子网掩码用于将IP地址划分为网络部分和主机部分。子网掩码以“/”符号后跟一串数字表示,例如,/24表示前24位用于网络标识,剩余的8位用于主机标识。
-
私有地址:IPv4保留了一些地址用于私有网络,例如以10.0.0.0/8、172.16.0.0/12和192.168.0.0/16开头的地址范围。这些地址通常在内部网络中使用,并且不能直接从Internet上路由。
-
地址转换:由于IPv4地址空间有限,网络地址转换(NAT)被广泛用于将私有地址映射到公共地址,从而允许内部网络上的多个设备共享单个公共IP地址。
-
动态主机配置协议(DHCP):IPv4中使用DHCP来自动分配IP地址和其他网络配置给主机。DHCP服务器负责为连接到网络的设备分配唯一的IP地址,并为它们提供其他必要的网络信息。
-8 websocket协议、SSE协议
-7.Kafka重要细节
-
kafka的特殊topic
- __cluster_metadata
- __consumer_group_offsets
- __transaction_state
- mm2: __m2-offsets
- 自定义的内部topic
-
kraft mode的角色
- controller
- broker
- both(in dev deployments)
- zk mode:任何节点可以是controller,kraft mde:只从有controller role中的选
-
kraft:quorum controller
- 大量分区(百万级)下可以快速选举
- There are two properties that determine the number of partitions an Kafka cluster can support:
the per-node partition count limit and cluster-wide partition limit. Previously, 【metadata management
with ZooKeeper was the main bottleneck】 for the cluster-wide limitation. KRaft mode is designed to
handle a much larger number of partitions per cluster, however Kafka’s scalability still primarily
depends on adding nodes to get more capacity, so the cluster-wide limit still defines the upper bounds
of scalability within the system - With the concept of a metadata log, brokers use offsets to keep track of the 【latest metadata stored
in the KRaft controllers】, which results in more efficient propagation of metadata and faster recovery
from controller failover
-
kafka在存储方面的新特性
- Tiered Storage(分层存储,early feature)
- local(store the log segments)
- remote(use hdfs,s3,etc to store completed segments)
- 公有云
- Ckafka使用connector同步
- 实时数据(热数据,实时消费)
- 离线数据(冷数据,周期性消费)
- Ckafka使用connector同步
- Tiered Storage(分层存储,early feature)
-
kafka服务端性能高
- 磁盘顺序读写
- pageCache
- zerocopy(sendfile,数据从磁盘直接到网卡buffer)
-
大厂如何做好kafka运维
- 扩容(副本迁移)
- 分区量大的zk容易成为瓶颈
- 上云(存储计算分离)
- AutoMQ(章文嵩)
- 使用EBS(S3)公共存储(存储是服务,不是软件;存储自带多副本、高可用)
- 将"状态"分离
- 弹性伸缩
-
kafka ack=-1, 2~3KB的消息,单机写入5W,64G/24C ,能达到70、80MiB的带宽
-
min.insync.replicas
When a producer sets acks to “all” (or “-1”),min.insync.replicasspecifies the minimum number of replicas that must acknowledge a write for the write to be considered successful. If this minimum cannot be met, then the producer will raise an exception (eitherNotEnoughReplicasorNotEnoughReplicasAfterAppend).
When used together, min.insync.replicas and acks allow you to enforce greater durability guarantees. A typical scenario would be to create a topic with a replication factor of 3, set min.insync.replicas to 2, and produce with acks of “all”. This will ensure that the producer raises an exception if a majority of replicas do not receive a write.
但这里要补充说下 ack=-1的真实语义: acks=-1 并不是指所有副本都收到了某条消息,而是指isr中的所有副本都收到了消息。比如producer ack=-1 ,topic relicas= 2,但挂了一个replica,此时acks=-1,只有尚在isr中的node收到消息即可ack。 -
delivery sematics
- 对kafka streams,或者在kakfa不同topic之间传递和处理数据的场景,能实现’exactly-once’语义
- 如果是基于其余的存储系统,那需要别的系统配合才能实现 'exactly-once’语义
- 其余场景中,默认情况下kafka是‘at-least-once’语义;用户可修改producer、consumer配置试下’at-most-once’
-
isolation.level
-
kafka如何保证所有副本的数据是完全一致的?
see also -
leader选举
- AR 中第一个存活的、ISR中的副本
- The most similar academic publication we are aware of to Kafka’s actual implementation is PacificA from Microsoft.
Instead of majority vote, Kafka dynamically maintains a set of in-sync replicas (ISR) that are caught-up to the leader. Only members of this set are eligible for election as leader. A write to a Kafka partition is not considered committed until all in-sync replicas have received the write. This ISR set is persisted to ZooKeeper whenever it changes. Because of this, any replica in the ISR is eligible to be elected leader. This is an important factor for Kafka’s usage model where there are many partitions and ensuring leadership balance is important. With this ISR model and f+1 replicas, a Kafka topic can tolerate f failures without losing committed messages
-
kafka的struct/schema 设计
-
kafak高低水位
- 低水位表示 AR中的每个副本的最小logStartOffset
- 高水位 (HighWaterMark ,HW)是 ISR中每个副本 LEO(log end offset,近似等于最大offset)的最小值,consumer只能拉到位点比HW低的消息
- deleteRecords会抬高低水位。注意:deleteRecords 不是删除某一条消息,而是删除小于某个offset的所有消息
-
preferred Leader
它就是AR中的第一个Node。正常情况下,一个分区的AR是不变的。如果有node上下线,就会造成AR顺序改变,可能有leader不均衡的问题。 -
kafka consumer 如何找到自己要连的 coordinator
- FIND_COORDINATOR 请求,根据 hashCode(consumer_group)%50的分区号,这个分区对应的leader Node
-
Byzantine将军问题
-
Kafka不丢消息的语义:
The guarantee that Kafka offers is that a committed message will not be lost, as long as there is at least one in sync replica alive, at all times. -
网络分区 (分区会导致集群不可用)
Kafka will remain available in the presence of node failures after a short fail-over period, but may not remain available in the presence of network partitions. -
log compaction 的实现
- 针对带key的消息
- 会compact多次,并且合并segment,所以segment数量会减少
- compaction不针对active segment
see also
-6. Kafka V.S. Rocketmq
-
nameserver管理元数据,最终一致性;而不是zk,顺序一致性 -
存储结构:物理
commitlog+messageQ索引文件实际是二级索引
V.S. 物理partition -
rocket mq 部署,节点级别的异步主机/同步主机/从机,
kafka 没那么多花样,多个broker是对等的。leader是在partition粒度。 -
rocketmq:可以在消息里设置Keys(业务关键字)方便作索引,keys最终会成broker上的index file内容。rokctet实际是对业务keys建立了索引
-
rocketmq batch要手动设置,kafka只能是batch
-
rocket ttl 是节点维度,不能细化到topic
为啥呢? 消息存储优势权衡:Apache RocketMQ 基于【统一的物理日志队列和轻量化逻辑队列的二级组织方式】,管理物理数据。
这种机制可以带来顺序读写、高吞吐、高性能等优势,但缺点是不支持按主题和队列单独管理。 -
rocketmq5.0 存储和计算分离
-
消息轨迹原理
消息轨迹数据是发到指定的轨迹topic上,原始msgId和消息KEYS作为轨迹消息的KEYS(业务关键字索引),所以可以用目标消息的消息ID作为轨迹消息的key从轨迹topic上查出来相关消息,对查出来的消息体解析,如果解析出来的消息体数据的消息ID字段与目标消息ID匹配,就是我们想要的消息轨迹数据 -
Broker 角色分为 ASYNC_MASTER(异步主机)、SYNC_MASTER(同步主机)以及SLAVE(从机)。如果对消息的可靠性要求比较严格,可以采用 SYNC_MASTER加SLAVE的部署方式。如果对消息可靠性要求不高,可以采用ASYNC_MASTER加SLAVE的部署方式。如果只是测试方便,则可以选择仅ASYNC_MASTER或仅SYNC_MASTER的部署方式。
-
name server上线下线
-
节点怎么心跳检测?consumer怎么检测心跳?
-
为什么 rocketmq 可以“定时”投递的(延时固定等级好实现,但是“定时”任意时间还是有难度的)
-
rocketmq key
- 支持对 key (业务含义) 进行索引; kafka做不到,因为它只有timeIdx 和 offsetIdx
- 支持基于业务含义的tag进行过滤;kafka原生做不到。对Kafka来说,消息是纯byte array,不支持服务端过滤。但是可以扩展消费端来过滤
- 支持发送消息指定q (基于message group);这点和kafka partitionKey类似
-
事务消息
保证分布式场景下保障消息生产和本地事务的最终一致性
-5. zk的重要概念一览
- 顺序一致性
- 节点类型: (顺序)持久节点、(顺序)临时节点
- 适用于读多写少场景
- 本质是分布式的小文件存储系统
- 基础数据模型:节点树结构(dataNode)
- leader/ follower /observer
- 事务(zxId) / 事务日志 / 数据快照
- 过半写和二阶段提交
- 羊群效应
- 用途:分布式锁、选举、命名服务、注册中心(watch机制)
- 缺点:选举慢、对网络延时敏感、leader容易成为写瓶颈
-4.zk 的一致性(顺序一致性)
ZK的写是强一致性,读不是强一致性。事实上,官方给出的说法是顺序一致性。
写:集群里三个节点node1 node2 node3,还有两个客户端c1 c2 并发写 key1 ,c1 希望更新值为 value1 , c2希望更新值为 value2。c1 c2可以任选node1~3中的一个节点去写。
ZK的写保证是:
node1~3 中任一节点看到的key1的更新都是相同的,要么是value1 -> value2 ,要么是value2 -> value1 ,不会有不同的情况。
读:
由于存在多个节点,而网络延时客观存在,因此总是存在某一个时刻节点数据不一致的情况。客户端有可能读取的不是最新数据。所以读不是强一致的。
但是zk提供了 sync()的方法,读之前调用下,就能从Leader读到最新数据。
-3. CAP
CAP中的C 其实全称是【linearizable consistency,线性一致性,也叫linearizability】,基本可以和【强一致性】作相同的理解。
这个C 不太好理解,一个比较可信的说法是:
对于一个分布式存储系统来说,线性一致性的含义可以用一个具体的描述来取代:对于任何一个数据对象来说,系统表现得就像它只有一个副本一样[1]。“表现得像只有一个副本”。
假如每个数据对象真的只存一个副本,那么肯定是满足线性一致性的。但是单一副本不具有容错性,所以分布式存储系统一般都会对数据进行复制(replication),也就是保存多个副本。
网上关于 一致性 分两种:
1)一致性是指:【在分布式系统完成某写操作后的任何读操作,都应该获取到该写操作写入的那个最新的值】。显然,如果系统“表现得像只有一个副本”一样,这个描述是成立的。不过这只是描述了线性一致性的一个特例而已,有以偏概全的嫌疑。
2)一致性是指:【保持所有节点在同一个时刻具有相同的、逻辑一致的数据】。显然这种解释并不是从观察者的角度来描述的,而是试图从系统内部的行为(内部实现)来描述的。
「所有节点」,可能指的是「所有副本」;至于“在同一个时刻具有相同的、逻辑一致的数据”这个说法,则似乎离线性一致性的本来含义偏离太远了。从逻辑上说,“表现得像只有一个副本”,并不一定需要系统“在同一个时刻具有相同的、逻辑一致的数据”。线性一致性可能有很多种实现方式,而这种解释规定了一种具体的系统实现,同样有以偏概全的嫌疑。
线性一致性,也被称为强一致性。之所以这么说,大概是因为线性一致性要求多个副本上的数据必须保持如此之「强」的一致性,以至于“让系统表现得就像只有一个副本”。
另外,网上的资料提到强一致性的时候,还有可能会关联到分布式事务上面,比如2PC/3PC这些原子提交协议。但把它们关联到一起的说法,其深层次含义到底是什么,只能靠猜测。【分布式事务处理的并不是同一个数据对象的多个副本的问题,而指的是将针对多个数据对象的各种操作组合起来,提供ACID的特性】。将分布式事务看成是强一致性的保证,猜测可能实际上指的就是ACID的原子性。总之,「强一致性」这个词很容易产生误解,所以建议谨慎使用。
-2.位操作
部分框架逼格很高,会用位操作。先记住一点,左移 1 位 = 乘以2 , 右移 1 位相当于除以2 。(不甚准确但基本能用)
-1.上游和下游
上游/下游 : 下游依赖上游 . A调用B,也就是A依赖了B, A是下游,B是上游 , 简单说就是: 下游调用上游
上游,有发源的意思
故上游服务器指的产生内容的服务器。
如nginx+tomcat tomcat是上游服务器。
在nginx中有配置upstream,就是配置上游服务器集群,如应用服务器tomcat
这是Kong打印的错误日志:上游指应用服务器集群
2018/12/03 15:24:30 [error] 57#0: *8554776 connect() failed (111: Connection refused) while connecting to upstream, client: 10.255.0.2, server:
kong, request: "GET /api/health HTTP/1.1", upstream:
"http://10.0.1.43:18082/api/health", host: "skyline-webapi"
以上这种定义上游下游的方式,和我们的思维习惯正好相反。它将一个请求,视为由下向上的过程(冒泡一样); 我们更倾向认为这是 从上向下的过程。
0.Jdk新特性
-
虚拟线程 java-virtual-threads
- 线程池 (在虚拟线程的场景下,线程池不再有必要)
synchronized(acquiring an intrinsic lock (synchronized) currently pins a virtual thread to its carrier)synchronized修饰的块,没法yield,carrier线程会被阻塞,可使用ReentrantLock来避免
ThreadLocal:虚拟线程支持threadlocal,但是虚拟线程非常多(百万数量级),造成threadlocal持有的对象非常多,或影响gc
-
虚拟线程的调度
- java thread是 操作系统级别的,由OS调度;java virtual thread 是JVM内部实现,JVM内部可调度
- java virtual thread更为轻量,创建、切换上下文、销毁的开销都更小(只在用户,不在OS内核切换);JVM可大量创建虚拟线程,支持更高并发度
- java virtual thread 需要
mount到操作系统线程(carrier), 同一组虚拟线程基于一个操作系统线程执行,没法跨核调度,可以说当前操作系统线程运行所在CPU核心就是虚拟线程所在核心;go routine没这个限制,同一组goroutine可能跑在不同的核心上。 - 定性:java virtual thread是基于操作系统线程的优化而非革命
-
虚拟线程的实现
Continuation(任务要挂起时, 调Continuation.yield()来阻塞,虚拟线程从平台线程unmount; 解除阻塞继续执行时,Continuation.run())Scheduler(核心操作mountunmount)Runnable
-
虚拟线程的实现(核心)
- java virtual thread的调度器是一个java实现的协作式调度器(
Cooperative Scheduler),通过多个虚拟线程的执行上下文存储在一个线程的栈中,然后在合适的时机进行上下文的切换。
- java virtual thread的调度器是一个java实现的协作式调度器(
-
虚拟线程的“竞争方案 ”
- springboot+ tomcat (普通线程池)
- springboot+webflux(不为每个请求分配一条线程,使用事件循环模型,通过非阻塞IO同时处理多个请求,这样有限线程可处理大量线程)
- webflux面临问题:mysql IO库不支持NIO;threadLocal问题
- tomcat+虚拟线程池
-
Foreign Function and Memory API
-
Record Patterns : 语法糖,
recordPerson(String name) --> 自动生成构造函数、hashCode、equal、getter,etc.,但没setter
1.包依赖
-
一个项目A 依赖了B jar , c jar, b 依赖了 d1 ,c依赖了d2 ,然后d1 d2会冲突,也就是有方法签名不兼容.如何解决?
- classloader ,比如saturn;
- shade掉其中一个jar
2.slf4j如何找到 logback 包
【这是典型的 桥接模式】以1.7.25 版本为例:
当执行LoggerFactory.getLogger(MyClass.class)的时候,i.e., LoggerFactory初始化的时候,会有一个bind的过程, 即ILoggerFactory和LoggerFactory绑定.
类加载器会在尝试找到org/slf4j/impl/StaticLoggerBinder.class的实现类, 一般来说可能是 Logback ,或 log4j2.如果找到了多个实现就会从标准输出流打印出警告信息.
这里要注意 类加载器获取到实现类是不稳定的.在Logback ,log4j2 的实现类同时存在的情况下, 有时可能是前者,有时是后者; 线下是前者,线上又是后者.
StaticLoggerBinder继续后续初始化,主要是查找config file
3. 如何预热一个项目的所有类?
- 线程池的预热,可调用
prestartAllCoreThreads()方法,看java doc,Starts all core threads, causing them to idly wait for work. This overrides the default policy of starting core threads only when new tasks are executed. - Netty的线程池预热
void warmup(DefaultEventExecutorGroup eventExecutorGroup) {
for (int i = 0; i < eventExecutorGroup.executorCount(); i++) {
int index = i;
//不是直接调用 eventExecutorGroup.execute()
eventExecutorGroup.next().execute(() -> {
logger.info("Warmup done-{}", index);
});
}
}
-
虚拟机有JIT机制,当需要加载的类比较多时可能耗时比较久,
当在静态代码块有耗时逻辑时尤其如此,易导致线上初次调用超时.【注意 区分类的加载和类的初始化】一种简易而有效的实现思路是在项目启动的时候,开启一条线程(可选)将所有依赖的jar 和类路径下的类都加载一遍, 当然更好的方法是使用包路径名过滤一层.预热是个常见需求,最好放在框架层来做.
核心的代码大概长这样:
public void warmup() throws Exception {
String file = Component.class.getProtectionDomain().getCodeSource().getLocation().getFile();
JarFile jarFile = new JarFile(file); // /D:/repository/org/springframework/spring-context/5.3.14/spring-context-5.3.14.jar
ClassLoader classLoader = Component.class.getClassLoader();
Enumeration<JarEntry> entries = jarFile.entries();
while (entries.hasMoreElements()) {
JarEntry jarEntry = entries.nextElement();
String entryName = jarEntry.getName();
System.out.println(entryName);
if (!entryName.contains(".class")) {
continue;
}
String className = entryName.replaceAll("/", ".");
className = className.substring(0, className.length() - ".class".length());
try {
classLoader.loadClass(className);
} catch (NoClassDefFoundError e) {
// ignore
e.printStackTrace();
}
}
}
4. KafkaAppender
5. 设计一个公共的Log模块
6. Java所有的对象都是在堆创建吗?
不是, Java还可以分配堆外内存.
此外, 还有一种栈上分配对象的虚拟机优化技术, 能大量减少堆上分配的对象.
参考链接
栈上分配内存是要基于逃逸分析和标量替换实现的. 一般其实不需要特别关注,只是写代码可以尽量控制变量的范围, 给予JVM优化空间.
7. time_wait + close_wait
9. 为啥少见"写超时",而多见读超时?
网络通信时 ,客户端向服务端发送请求,本质是向本地TCP缓冲区写入数据, 然后TCP协议栈根据窗口发送数据 . “写入本地” 是不会超时的, 除非说 TCP缓冲区已满, 客户端等待导致超时.
10.@Test要求方法是public ?
设计如此,JUnit 会构建runner对象,构建过程会validate @Test标记的方法必须是 public的, 方便后续能反射调用这个方法. 个人觉得,并不需要如此严格.
11. 如何获取线程栈轨
Thread.dumpStack(),但这个方法适应于debugging, 或,当框架代码处在某种不稳定状态时保留线程现场.
12. 设计模式
除了模板方法设计模式是减少重复代码的一把好手,观察者模式也常用于减少代码重复(并且是松耦合方式)。
Spring 也提供了类似工具(TODO:更多场景)
13. MDC
本质就是个ThreadLocal, 因此要注意:
- 子线程不会拿到主线程中的
MDC值,线程池中的线程亦然 - 线程池中的线程是复用的,提交的任务执行完之前要
clear
如何解决线程池中线程拿不到MDC?
private final ExecutorService executorService = Executors.newFixedThreadPool(10, new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
// 这里还是 http-nio-8080-exec-1 (tomcat线程)
Map<String, String> copyOfContextMap = MDC.getCopyOfContextMap();
Runnable runnable = new Runnable() {
@Override
public void run() {
try {
MDC.setContextMap(copyOfContextMap);
r.run();
} catch (Throwable throwable) {
log.error("Failed to run my task", throwable);
} finally {
MDC.clear();
}
}
};
Thread thread = new Thread(runnable, "my-thread");
thread.setDaemon(true);
return thread;
}
});
14.Marker
logback给日志行增加的标签,多用于过滤日志,配合Filter使用,还能达到日志分类的效果.
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<layout class="ch.qos.logback.classic.PatternLayout">
<pattern>[%d{yyyy-MM-dd HH:mm:ss.SSS}] [%thread] [%-5level] [%logger{40}:%line] - %msg%n</pattern>
</layout>
<filter class="ch.qos.logback.core.filter.EvaluatorFilter">
<evaluator class="ch.qos.logback.classic.boolex.OnMarkerEvaluator">
<marker>time</marker>
</evaluator>
<onMismatch>DENY</onMismatch>
<onMatch>ACCEPT</onMatch>
</filter>
</appender>
15. netty pipeline 责任链和 tomcat filter chain等普通责任链有啥区别
【这个题水平很高】
netty pipeline中有个Handler可以有状态, 配合Netty eventloop能够避免锁竞争,性能好
16.什么样的数据放在堆内/堆外
【这个题水平很高】
- 数据放在堆外有个(反)序列化的要求
- 定长数据, 固定结构的对象比较适合放在堆外
- 有些RPC框架会把 那个熔断计数器 什么放在了堆外
17. 什么情况下会发生死锁
两个线程两个事务
- A事务:先获取行 10 的锁,等着拿行 11 的锁;
- B事务:先获取行 11 的锁,等着拿行10 的锁;
- A 拿到行10 锁的同时, B 拿到了 行11的锁,A、B 互相等对方锁,就死锁了
- see also
- https://juejin.cn/post/6944615453700390919
- https://www.51cto.com/article/596261.html
- https://www.51cto.com/article/618089.html
18. 为啥overrdie equals()方法 后一定要override hashCode
equals:实现业务含义的对象比较,否则是java对象 == 比较hashCode: to maintain the general contract for the hashCode method, which states that equal objects must have equal hash codes (from java doc)- 对象作为hashMap key,hashset元素时,如果不重写
hashCode(),就会出现equals=true,但在集合中依然被当做二个对象来对待的情况
19. http reponse.write() work ?
http的基础规则就是一个请求,一个响应,reponse.write()会报错
20. 注解可以继承吗?
@Inherited元注解是一个标记注解,@Inherited阐述了某个被标注的类型是被继承的。
如果一个使用了@Inherited修饰的annotation类型被用于一个class,则这个annotation将被用于该class的子类。- 但是一个注解不能继承另一个注解,java语言层面不支持。然而借助spring
AnnotationUtils等工具可以达到类似继承的效果。下面的案例,@FormatterType实际就有了@Qualifier的语义(本质是spring的设计才有这样的效果,参看spring-autowire )
@Qualifier
@Target({ ElementType.FIELD, ElementType.METHOD, ElementType.TYPE, ElementType.PARAMETER })
@Retention(RetentionPolicy.RUNTIME)
public @interface FormatterType {
String value();
}
21. filter interceptor aop
filter:作用于【servlet容器】;但只操作请求/响应,不能控制controller方法interceptor- 作用于【spring框架】,只作用于后端。
- preHandle + afterCompletion + postHandle,可以获取执行的方法的名称,请求(HttpServletRequest)
- 可以控制请求的控制器和方法,但控制不了请求方法里的参数(只能获取参数的名称,不能获取到参数的值?)
aop- 只能拦截Spring管理Bean的访问
- AOP可进行【方法】的横向的拦截(Spring的事务管理),而且可获取执行方法的参数
ProceedingJoinPoint.getArgs(),对方法进行统一的处理 - AOP可以自定义切入的点,有方法的参数,但是不能直接拿到http请求,可以通过其他方式如
RequestContextHolder
- click here to see more
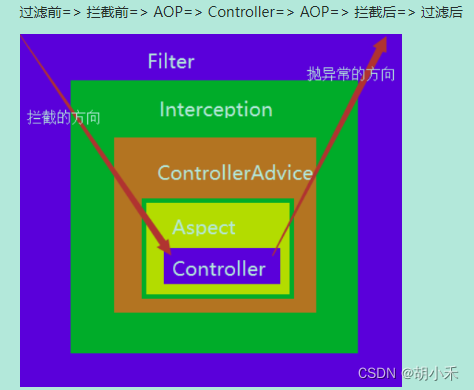

22. jcl-over-slf4j
和前面的第二个问题相关联,jcl-over-slf4j 也是利用【桥接模式】将 jcl 代理(delegate)到slf4j。jcl-over-slf4j jar有StaticLoggerBinder的实现,当去除了commons-logging的jar,并代之以jcl-over-slf4j之后,commons-logging的Log会被redirect到Slf4j的Logger。
23. 如何对多对多的关系建模
- scientists and the papers that they write
- webpages and hyperlinks
- kafka topics and consumer groups
这三个案例都是多对多的模型,jdk现有的集合类型是不能表示,但guava graphs可以。
graphvalue graphnetwork
24. 如何动态调整logback logger level
【logback还真是小而美的框架,值得读一读源码】
ch.qos.logback.classic.Logger#setLevel()预留了修改了logger level的接口,通过LoggerFactory(LoggerContext)获取到Logger后,再调用此接口即可改变level。
优秀的框架设计时常会考虑动态下发这个feature,另一个典型例子是java的线程池,可以动态修改size
25. ch.qos.logback.classic.pattern.ClassicConverter
logback提供了拓展点钩子,可将:
[%d{yyyy-MM-dd HH:mm:ss.SSS}] [%level] [%thread] [%logger{50}] >>> [%eventName] msg=%msg%n 中[%eventName]替换掉(和[%thread]类似)
类似的扩展点在logback中还有很多,提供扩展点是一个优秀框架的必要设计
26. java动态表达式
当我们需要动态执行一些表达式时,可以使用 Groovy 动态语言实现:new 出一个 GroovyShell 类,然后调用 evaluate 方法动态执行脚本。
这种方式的问题是,会重复产生大量的类,增加 Metaspace 区的 GC 负担,有可能会引起 OOM。你知道如何避免这个问题吗?
TODO:补充场景描述
27. 代理
-
proxy
-
delegate 【委派】
-
broker
-
agent
-
从设计模式的角度看,
proxy是一种经典模式:org.springframework.security.web.FilterChainProxy -
delegate不算一种设计模式,算是一种技巧; -
broker在分布式系统中,不如直翻为节点,比如kafka broker -
agent在java中不如翻译成外挂,也程探针
28. 重试时间退避算法
exponential backoff重试等待时间以指数方式增长,重试次数达到最大值- 典型场景是熔断之后,使用该算法计算重试的时间
29. mongo V.S. ES (TODO)
文档数据库 MongoDB,也是一种常用的 NoSQL。你觉得 MongoDB 的优势和劣势是什么呢?它适合用在什么场景下呢?
问题解答, 有了ES ,mango为啥还需要?
30. server-sent event(sse)
(it laoqi 237 )
31. swap
内存不够用,就拿硬盘空间当内存用(通俗的说法)。swap 会导致CPU频繁内存交换;导致CPU限流。
禁用swap,或swap后内存还是不够,OS可能kill掉一些用户进程。
32. xss\csrf
- xss: 跨站脚本攻击,是代码注入攻击的一种
- csrf:















 104
104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









