






MapReduce:
hadoop1.x MR1(计算+资源作业调度) 没有yarn
hadoop2.x MR2(计算)
MR1进程: (过时了,但是面试官最喜欢问的)
JobTracker
TaskTracker: map task 、reduce task
MR2: 写代码打成jar包提交给yarn运行即可
1.不需要部署
2.架构设计 (面试题*****+背)
-->MR Job提交到Yarn的工作流程-->Yarn架构设计、Yarn工作流程
Yarn:
ResourceManager:
Application Manager:应用程序管理
Scheduler: 调度器
NodeManger:
Container: 容器(*****) Yarn的资源抽象的概念,封装了某个NM的多维度资源:memory+cpu
容器里运行map task、reduce task
MR Application Master:每个MR的作业只有一个,且是运行在NM的container中
3.词频统计:wordcount
[hadoop@rzdatahadoop002 hadoop]$ vi 1.log
bbb 123 1 2 2
aaa bbb ccc
bbb 123 1 2 2
aaa
123
bbb
ccc
xxxxx
www.ruozedata.com
[hadoop@rzdatahadoop002 hadoop]$ hdfs dfs -mkdir -p /wordcount/input
[hadoop@rzdatahadoop002 hadoop]$ hdfs dfs -put 1.log /wordcount/input
[hadoop@rzdatahadoop002 hadoop]$ hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.1.jar \
> wordcount /wordcount/input /wordcount/output1
17/12/19 22:44:32 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
17/12/19 22:44:34 INFO input.FileInputFormat: Total input files to process : 1
17/12/19 22:44:34 WARN hdfs.DataStreamer: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1245)
at java.lang.Thread.join(Thread.java:1319)
at org.apache.hadoop.hdfs.DataStreamer.closeResponder(DataStreamer.java:927)
at org.apache.hadoop.hdfs.DataStreamer.endBlock(DataStreamer.java:578)
at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:755)
17/12/19 22:44:34 WARN hdfs.DataStreamer: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1245)
at java.lang.Thread.join(Thread.java:1319)
at org.apache.hadoop.hdfs.DataStreamer.closeResponder(DataStreamer.java:927)
at org.apache.hadoop.hdfs.DataStreamer.endBlock(DataStreamer.java:578)
at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:755)
17/12/19 22:44:34 INFO mapreduce.JobSubmitter: number of splits:1
17/12/19 22:44:34 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1513689033755_0001
17/12/19 22:44:35 INFO impl.YarnClientImpl: Submitted application application_1513689033755_0001
17/12/19 22:44:35 INFO mapreduce.Job: The url to track the job: http://rzdatahadoop002:8088/proxy/application_1513689033755_0001/
17/12/19 22:44:35 INFO mapreduce.Job: Running job: job_1513689033755_0001
17/12/19 22:44:54 INFO mapreduce.Job: Job job_1513689033755_0001 running in uber mode : false
17/12/19 22:44:54 INFO mapreduce.Job: map 0% reduce 0%
17/12/19 22:45:03 INFO mapreduce.Job: map 100% reduce 0%
17/12/19 22:45:12 INFO mapreduce.Job: map 100% reduce 100%
17/12/19 22:45:13 INFO mapreduce.Job: Job job_1513689033755_0001 completed successfully
17/12/19 22:45:13 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=98
FILE: Number of bytes written=272817
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=181
HDFS: Number of bytes written=60
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=6958
Total time spent by all reduces in occupied slots (ms)=6334
Total time spent by all map tasks (ms)=6958
Total time spent by all reduce tasks (ms)=6334
Total vcore-milliseconds taken by all map tasks=6958
Total vcore-milliseconds taken by all reduce tasks=6334
Total megabyte-milliseconds taken by all map tasks=7124992
Total megabyte-milliseconds taken by all reduce tasks=6486016
Map-Reduce Framework
Map input records=8
Map output records=14
Map output bytes=122
Map output materialized bytes=98
Input split bytes=114
Combine input records=14
Combine output records=8
Reduce input groups=8
Reduce shuffle bytes=98
Reduce input records=8
Reduce output records=8
Spilled Records=16
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=187
CPU time spent (ms)=1740
Physical memory (bytes) snapshot=329904128
Virtual memory (bytes) snapshot=4130594816
Total committed heap usage (bytes)=202379264
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=67
File Output Format Counters
Bytes Written=60
[hadoop@rzdatahadoop002 hadoop]$ hdfs dfs -ls /wordcount/output1
Found 2 items
-rw-r--r-- 1 hadoop supergroup 0 2017-12-19 22:45 /wordcount/output1/_SUCCESS
-rw-r--r-- 1 hadoop supergroup 60 2017-12-19 22:45 /wordcount/output1/part-r-00000
-rw-r--r-- 1 hadoop supergroup 60 2017-12-19 22:45 /wordcount/output1/part-r-00001
[hadoop@rzdatahadoop002 hadoop]$ hdfs dfs -cat /wordcount/output1/part-r-00000
1 1
123 2
2 2
aaa 2
bbb 3
ccc 2
www.ruozedata.com 1
xxxxx 1
[hadoop@rzdatahadoop002 hadoop]$
http://blog.itpub.net/30089851/viewspace-2015610/
4.shuffle 洗牌(工作:*****) 调优点 hive+spark
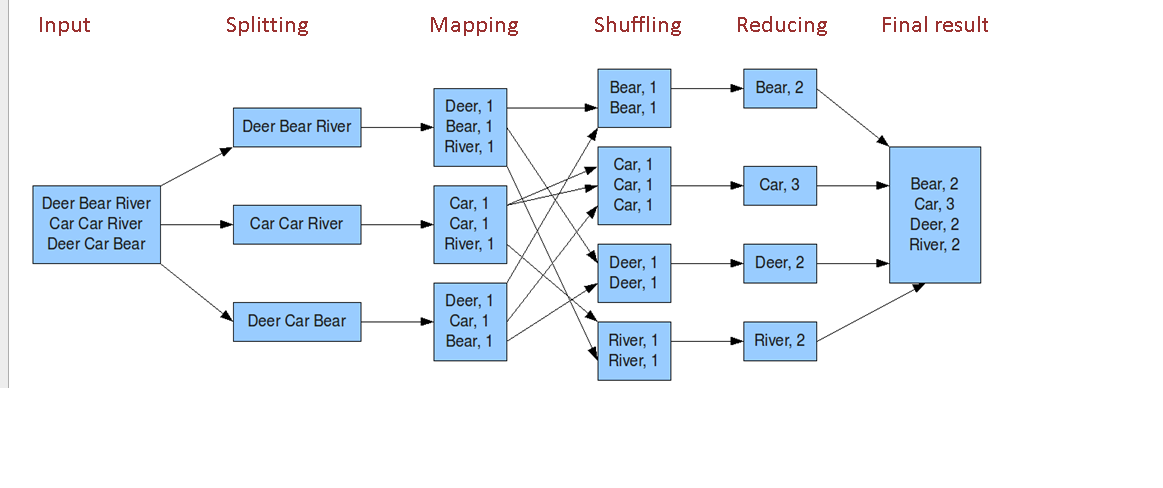
2个小时:
http://blog.itpub.net/30089851/viewspace-2095837/
Map: 映射
Reduce: 归约
http://blog.itpub.net/30089851/viewspace-2095837/
http://hadoop.apache.org/docs/r2.8.3/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html
作业20171219:
1.hadoop高级命令
2.MR提交流程(面试*****)
3.WordCount案例+理解图+shuffle(******)
scala :腾讯课堂上 若泽数据
RPC是什么?
java面向对象
hadoop1.x MR1(计算+资源作业调度) 没有yarn
hadoop2.x MR2(计算)
MR1进程: (过时了,但是面试官最喜欢问的)
JobTracker
TaskTracker: map task 、reduce task
MR2: 写代码打成jar包提交给yarn运行即可
1.不需要部署
2.架构设计 (面试题*****+背)
-->MR Job提交到Yarn的工作流程-->Yarn架构设计、Yarn工作流程
Yarn:
ResourceManager:
Application Manager:应用程序管理
Scheduler: 调度器
NodeManger:
Container: 容器(*****) Yarn的资源抽象的概念,封装了某个NM的多维度资源:memory+cpu
容器里运行map task、reduce task
MR Application Master:每个MR的作业只有一个,且是运行在NM的container中
3.词频统计:wordcount
[hadoop@rzdatahadoop002 hadoop]$ vi 1.log
bbb 123 1 2 2
aaa bbb ccc
bbb 123 1 2 2
aaa
123
bbb
ccc
xxxxx
www.ruozedata.com
[hadoop@rzdatahadoop002 hadoop]$ hdfs dfs -mkdir -p /wordcount/input
[hadoop@rzdatahadoop002 hadoop]$ hdfs dfs -put 1.log /wordcount/input
[hadoop@rzdatahadoop002 hadoop]$ hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.1.jar \
> wordcount /wordcount/input /wordcount/output1
17/12/19 22:44:32 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
17/12/19 22:44:34 INFO input.FileInputFormat: Total input files to process : 1
17/12/19 22:44:34 WARN hdfs.DataStreamer: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1245)
at java.lang.Thread.join(Thread.java:1319)
at org.apache.hadoop.hdfs.DataStreamer.closeResponder(DataStreamer.java:927)
at org.apache.hadoop.hdfs.DataStreamer.endBlock(DataStreamer.java:578)
at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:755)
17/12/19 22:44:34 WARN hdfs.DataStreamer: Caught exception
java.lang.InterruptedException
at java.lang.Object.wait(Native Method)
at java.lang.Thread.join(Thread.java:1245)
at java.lang.Thread.join(Thread.java:1319)
at org.apache.hadoop.hdfs.DataStreamer.closeResponder(DataStreamer.java:927)
at org.apache.hadoop.hdfs.DataStreamer.endBlock(DataStreamer.java:578)
at org.apache.hadoop.hdfs.DataStreamer.run(DataStreamer.java:755)
17/12/19 22:44:34 INFO mapreduce.JobSubmitter: number of splits:1
17/12/19 22:44:34 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1513689033755_0001
17/12/19 22:44:35 INFO impl.YarnClientImpl: Submitted application application_1513689033755_0001
17/12/19 22:44:35 INFO mapreduce.Job: The url to track the job: http://rzdatahadoop002:8088/proxy/application_1513689033755_0001/
17/12/19 22:44:35 INFO mapreduce.Job: Running job: job_1513689033755_0001
17/12/19 22:44:54 INFO mapreduce.Job: Job job_1513689033755_0001 running in uber mode : false
17/12/19 22:44:54 INFO mapreduce.Job: map 0% reduce 0%
17/12/19 22:45:03 INFO mapreduce.Job: map 100% reduce 0%
17/12/19 22:45:12 INFO mapreduce.Job: map 100% reduce 100%
17/12/19 22:45:13 INFO mapreduce.Job: Job job_1513689033755_0001 completed successfully
17/12/19 22:45:13 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=98
FILE: Number of bytes written=272817
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=181
HDFS: Number of bytes written=60
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=6958
Total time spent by all reduces in occupied slots (ms)=6334
Total time spent by all map tasks (ms)=6958
Total time spent by all reduce tasks (ms)=6334
Total vcore-milliseconds taken by all map tasks=6958
Total vcore-milliseconds taken by all reduce tasks=6334
Total megabyte-milliseconds taken by all map tasks=7124992
Total megabyte-milliseconds taken by all reduce tasks=6486016
Map-Reduce Framework
Map input records=8
Map output records=14
Map output bytes=122
Map output materialized bytes=98
Input split bytes=114
Combine input records=14
Combine output records=8
Reduce input groups=8
Reduce shuffle bytes=98
Reduce input records=8
Reduce output records=8
Spilled Records=16
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=187
CPU time spent (ms)=1740
Physical memory (bytes) snapshot=329904128
Virtual memory (bytes) snapshot=4130594816
Total committed heap usage (bytes)=202379264
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=67
File Output Format Counters
Bytes Written=60
[hadoop@rzdatahadoop002 hadoop]$ hdfs dfs -ls /wordcount/output1
Found 2 items
-rw-r--r-- 1 hadoop supergroup 0 2017-12-19 22:45 /wordcount/output1/_SUCCESS
-rw-r--r-- 1 hadoop supergroup 60 2017-12-19 22:45 /wordcount/output1/part-r-00000
-rw-r--r-- 1 hadoop supergroup 60 2017-12-19 22:45 /wordcount/output1/part-r-00001
[hadoop@rzdatahadoop002 hadoop]$ hdfs dfs -cat /wordcount/output1/part-r-00000
1 1
123 2
2 2
aaa 2
bbb 3
ccc 2
www.ruozedata.com 1
xxxxx 1
[hadoop@rzdatahadoop002 hadoop]$
http://blog.itpub.net/30089851/viewspace-2015610/
4.shuffle 洗牌(工作:*****) 调优点 hive+spark
2个小时:
http://blog.itpub.net/30089851/viewspace-2095837/
Map: 映射
Reduce: 归约
http://blog.itpub.net/30089851/viewspace-2095837/
http://hadoop.apache.org/docs/r2.8.3/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html
作业20171219:
1.hadoop高级命令
2.MR提交流程(面试*****)
3.WordCount案例+理解图+shuffle(******)
scala :腾讯课堂上 若泽数据
RPC是什么?
java面向对象














 2169
2169











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









