






1)核心概念:
./kafka-topics.sh --create \
--zookeeper 192.168.137.141:2181,192.168.137.142:2181,192.168.137.143:2181/kafka \
--replication-factor 3 --partitions 3 --topic ruozedata
topic:ruozedata 主题,不同的主题不同的业务线 1----10
partitions:3个分区 下标是从0开始的 物理上的分区,数据落在磁盘上,是最稳定最安全的
replication:3个副本 指的是一个分区被复制3份
3台机器:
hadoop001 hadoop002 hadoop003
0分区: ruozedata-0 ruozedata-0 ruozedata-0
1分区: ruozedata-1 ruozedata-1 ruozedata-1
2分区: ruozedata-2 ruozedata-2 ruozedata-2
如:HDFS 一个文件比如130M BLOCKSIZE:128M 两个块,每个块复制3份
./kafka-topics.sh --describe \
--zookeeper 192.168.137.141:2181,192.168.137.142:2181,192.168.137.143:2181 \kafka
--topic ruozedata
a) Topic:ruozedata PartitionCount:3 ReplicationFactor:3 Configs:
Topic:ruozedata Partition: 0 Leader: 1 Replicas: 1,3,2 Isr: 1,3,2
Topic:ruozedata Partition: 1 Leader: 2 Replicas: 2,1,3 Isr: 2,1,3
Topic:ruozedata Partition: 2 Leader: 3 Replicas: 3,2,1 Isr: 3,2,1
kill hadoop003的kafka
b) Topic: ruozedata Partition: 0 Leader: 1 Replicas: 1,3,2 Isr: 1,2
Topic: ruozedata Partition: 1 Leader: 2 Replicas: 2,1,3 Isr: 2,1
Topic: ruozedata Partition: 2 Leader: 2 Replicas: 3,2,1 Isr: 2,1
说明: 第一行列举这个topic的名称,分区数,副本数
Partition:0,1,2 三个分区
Leader:1 指的是broker.id=1 只有leader才可以读写。生产上的读,在从节点做的
Replicas(副本):复制该分区数据的节点列表,第一位代表leader 静态表述
Isr:in-sync Replicas 正在复制的副本节点列表 动态表述,理解为真正做复制副本的分区(对比上面a和b的Isr)
当leader挂了,会从这个列表选举出新的leader,保证读写
broker:代表每台机器上运行Kafka实例的节点 (也就是kafka进程)
2)核心概念 -- 生产案例
producer: 生产者 flume/maxwell
consumer: 消费者 spark streaming/flink
producer ---> broker ---> consumer
一般生产上:
--replication-factor 3 --partitions 3
--partitions的数量取决于broker数量(也就是装了多少台kafka)
--replication-factor 3 --partitions 8
It provides simple parallelism, 1:1 correspondence between Kafka partitions,and Spark partitions, and access to offsets and metadata. (Kafka提供了简单的并行,1:1针对kafka和spark的分区)
即kafka机器8个,8个分区,spark也8个分区,通过direct方式读取,并行度就高了。
虽然我们增加了分区数,提高kafka的写和读的吞吐量,但是假如一个集群多个topic,多个分区,必然一台机器上有多个 ruozedata-0 test-0 jepson-0,就需要更多的文件数(进程数),那就要调优
*****:从集群观点来考虑,集群里不要有过多的topic,尽可能把业务线合用
3) 核心概念 -- 疑问
Q:分区是有序的吗?多个分区是有序的吗?
A:分区是有序的(队列,先进先出),多个分区是无序的
比如:0: 1,2,3
1: 7,8,9
3: 4,5,6 spark stream拿到的数据是123789456,那可以解决排序吗?
record:key、 value(业务数据creatime字段)、 timestamp(生产者向broker的插入时间) ,offset json格式
1. 按timestamp(生产者向broker的插入时间) 排序
2. 业务数据creatime字段排序
但是spark不支持排序,DF排序会丢失一些信息offset,会导致一连串的无法做到 断点还原
4)consumer group 消费组
-- 生产用的并不多
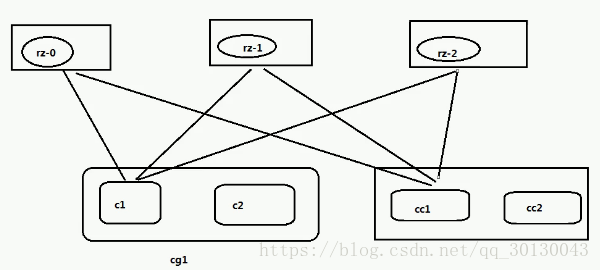
-- 一个消费组可以包含一个或多个消费者,分区只能被一个消费组的其中一个消费者去消费
-- 正常在企业开发使用多分区方式去提高计算的能力
-- offset:偏移量
消费时读取一个分区的文件的数据,数据所在的下标
5)常用命令
-- 5.1 创建
bin/kafka-topics.sh --create \
--zookeeper 192.168.137.141:2181,192.168.137.142:2181,192.168.137.143:2181/kafka \
--replication-factor 3 --partitions 3 --topic test
-- 5.2 查看
bin/kafka-topics.sh --list \
--zookeeper 192.168.137.141:2181,192.168.137.142:2181,192.168.137.143:2181/kafka
-- 5.3 查看某个具体的topic
bin/kafka-topics.sh --describe \
--zookeeper 192.168.137.141:2181,192.168.137.142:2181,192.168.137.143:2181/kafka \
--topic test
-- 5.4 假删除topic
bin/kafka-topics.sh --delete \
--zookeeper 192.168.137.141:2181,192.168.137.142:2181,192.168.137.143:2181/kafka \
--topic ruozedata
Topic ruozedata is marked for deletion.
Note: This will have no impact if delete.topic.enable is not set to true.
delete.topic.enable=true,生产不设置该参数。
Q:这样删除了topic后,发送和接受数据的实验是否成功?
A:可以的,因为这只是假删除,数据依然还在
-- 5.5 真删除 彻底删除:
kafka元数据在哪? zk
rmr /config/topics/ruozedata
rmr /brokers/topics/ruozedata
rmr /admin/delete_topics/ruozedata
kafka数据在哪? 磁盘
rm -rf $KAFKA_HOME/logs/ruozedata-*
Q:删除了topic之后,重新新增这个topic,为什么没看到分区文件夹?
A:找个空余时间重启一下kafka进程,分区文件夹便会出来
-- 5.6 调大
bin/kafka-topics.sh --alter \
--zookeeper 192.168.137.141:2181,192.168.137.142:2181,192.168.137.143:2181/kafka \
--partitions 2 --topic zp (*****只能增长,不可以调小,这个是错的)
bin/kafka-topics.sh --alter \
--zookeeper 192.168.137.141:2181,192.168.137.142:2181,192.168.137.143:2181/kafka \
--partitions 4 --topic zp (调大了)
kafka-topics.sh --describe \
--zookeeper 192.168.137.141:2181,192.168.137.142:2181,192.168.137.143:2181/kafka \
--topic zp (查看调整结果)
6)kafka监控
1. kafka eagle
https://github.com/smartloli/kafka-eagle
Version 1.2.1
*******************************************************************
* Kafka Eagle Service has started success!
* Welcome, Now you can visit 'http://<your_host_or_ip>:port/ke'
* Account:admin ,Password:123456
*******************************************************************
* <Usage> ke.sh [start|status|stop|restart|stats] </Usage>
* <Usage> http://ke.smartloli.org/ </Usage>
*******************************************************************
2.Grafana kafka0.10不成功的 kafka0.8
prometheus + kafka kubernetes
采集--》存储--》可视化
ES/INFLUXDB
数据采集: Metricbeat
数据存储: ES/INFLUXDB
数据可视化 Grafana: web dashborad
3.CDH kafka
语法: TQS
*****SELECT
total_kafka_bytes_received_rate_across_kafka_broker_topics,
total_kafka_bytes_fetched_rate_across_kafka_broker_topics
WHERE entityName = "kafka:onlinelogs" AND category = KAFKA_TOPIC
total_kafka_bytes_received_rate_across_kafka_broker_topics 蓝色 写数据
total_kafka_bytes_fetched_rate_across_kafka_broker_topics 绿色 读数据
--Q:写和读的趋势是否一样?
A:是一样
--Q:写和读的趋势是否在同一时间是吻合的,假如是吻合的,为什么读的曲线图比写的曲线图高呢?
A:吻合,1点写了100条数据,1点消费者100条,而不是1点05去消费
消费及时,没有延时
--Q:为什么读的数据比写的数据多?
A:如以下例子
写:"123" 3B
读:timestamp offset key value 拼接成一条json数据 20B
*****所以只要看图的趋势是不是及时消费的就行














 298
298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









