






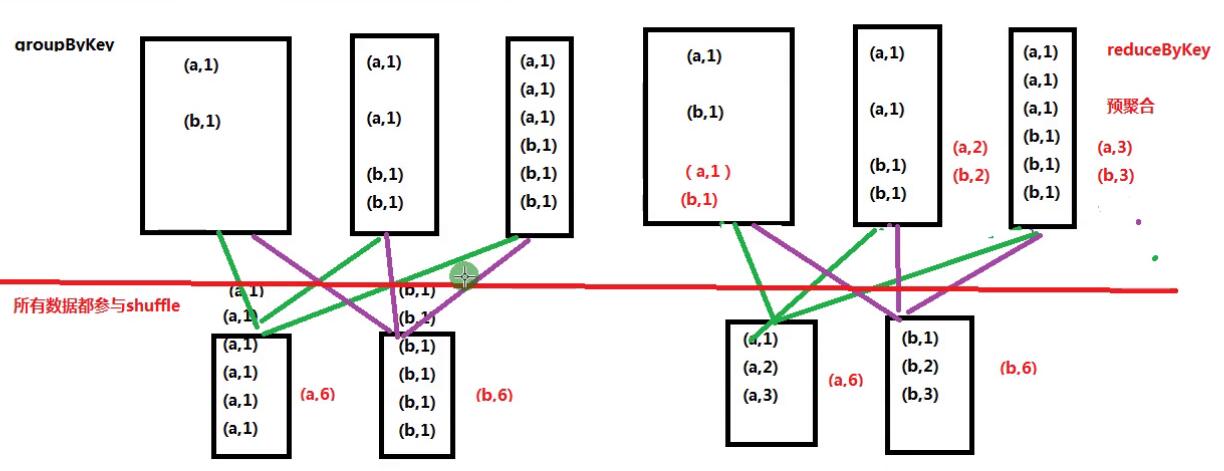
sc.textFile("file:///home/hadoop/data/ruozeinput.txt").flatMap(_.split("\t")).map((_,1)).reduceByKey(_+_).collect
sc.textFile("file:///home/hadoop/data/ruozeinput.txt").flatMap(_.split("\t")).map((_,1)).groupByKey().map(x => (x._1, x._2.sum)).collect
Array[(String, Iterable[Int])]
(String, Int)
def map[U: ClassTag](f: T => U) //对map每一个元素都作用一个函数 每个函数执行一次
def mapPartitions[U: ClassTag]( //作用在partition,每个partition执行一次
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false)
mapPartitions vs map
foreachPartitions vs foreach
DB: Partitions //处理数据库,优先选择partition
Java MEMORY_ONLY
./bin/spark-submit \
--class com.ruozedata.core.SerializerApp1 \
--master local[2] \
--name SerializerApp1 \
/home/hadoop/lib/train-scala-1.0.jar
import scala.collection.mutable.ArrayBuffer
case class Person(name:String, age:Int, gender:String, address:String)
val persons = new ArrayBuffer[Person]()
for(i <-1 to 1000000) {
persons += (Person("name"+i, 10+i, "male", "beijing"))
}
val rdd = sc.parallelize(persons)
rdd.persist(StorageLevel.MEMORY_ONLY_SER)
rdd.count()
rdd.unpersist()
MEMORY_ONLY: 95.3 MB
MEMORY_ONLY_SER: 39.8 MB
------------------------------
MEMORY_ONLY: 95.3 MB
MEMORY_ONLY_SER: 119.1 MB
MEMORY_ONLY_SER: 27.5 MB
emp.txt
入职时间
core:按照时间(年)分区(目录)输出
1) 输出第一步
emp
year=1981
1-1981.txt
year=1987
1-1987.txt
...
2) cp emp.txt ==> emp1.txt append
9999 dove1 ANALYST 7566 2000-12-3 3000.00 20
9998 dove2 CLERK 7782 2001-1-23 1300.00 10
9997 dove3 PROGRAM 7839 2002-1-23 10300.00
使用第一步开发完的程序处理第二步的数据
emp
year=1981
1-1981.txt
2-1981.txt
year=1987
1-1987.txt
2-1987.txt
...
year=2000
2-2000.txt
year=2001
2-2001.txt
year=2002
2-2002.txt
3) 重跑第一步
删除1-xxx的文件,再写入
4) 重跑第二步
删除2-xxx的文件,再写入
清明节回来第一次课抽查
4人 <= random()
....
50红包==> 微信
Spark Core + Hadoop
sc.textFile("file:///home/hadoop/data/ruozeinput.txt").flatMap(_.split("\t")).map((_,1)).groupByKey().map(x => (x._1, x._2.sum)).collect
Array[(String, Iterable[Int])]
(String, Int)
def map[U: ClassTag](f: T => U) //对map每一个元素都作用一个函数 每个函数执行一次
def mapPartitions[U: ClassTag]( //作用在partition,每个partition执行一次
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false)
mapPartitions vs map
foreachPartitions vs foreach
DB: Partitions //处理数据库,优先选择partition
Java MEMORY_ONLY
./bin/spark-submit \
--class com.ruozedata.core.SerializerApp1 \
--master local[2] \
--name SerializerApp1 \
/home/hadoop/lib/train-scala-1.0.jar
import scala.collection.mutable.ArrayBuffer
case class Person(name:String, age:Int, gender:String, address:String)
val persons = new ArrayBuffer[Person]()
for(i <-1 to 1000000) {
persons += (Person("name"+i, 10+i, "male", "beijing"))
}
val rdd = sc.parallelize(persons)
rdd.persist(StorageLevel.MEMORY_ONLY_SER)
rdd.count()
rdd.unpersist()
MEMORY_ONLY: 95.3 MB
MEMORY_ONLY_SER: 39.8 MB
------------------------------
MEMORY_ONLY: 95.3 MB
MEMORY_ONLY_SER: 119.1 MB
MEMORY_ONLY_SER: 27.5 MB
emp.txt
入职时间
core:按照时间(年)分区(目录)输出
1) 输出第一步
emp
year=1981
1-1981.txt
year=1987
1-1987.txt
...
2) cp emp.txt ==> emp1.txt append
9999 dove1 ANALYST 7566 2000-12-3 3000.00 20
9998 dove2 CLERK 7782 2001-1-23 1300.00 10
9997 dove3 PROGRAM 7839 2002-1-23 10300.00
使用第一步开发完的程序处理第二步的数据
emp
year=1981
1-1981.txt
2-1981.txt
year=1987
1-1987.txt
2-1987.txt
...
year=2000
2-2000.txt
year=2001
2-2001.txt
year=2002
2-2002.txt
3) 重跑第一步
删除1-xxx的文件,再写入
4) 重跑第二步
删除2-xxx的文件,再写入
清明节回来第一次课抽查
4人 <= random()
....
50红包==> 微信
Spark Core + Hadoop














 5097
5097











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









