







1. 使用正则表达式去除html标签
/**
* 去除Html标签
*
* @param html
* html内容
* @return 去除标签后的文本
*/
public static String dislodgeHtmlLabel(String html) {
if (Objects.isNull(html)) {
return "";
}
// 过滤script标签
Pattern pscript = Pattern.compile("<script[^>]*?>[\\s\\S]*?<\\/script>", Pattern.CASE_INSENSITIVE);
// 过滤style的正则
Pattern pstyle = Pattern.compile("<style[^>]*?>[\\s\\S]*?<\\/style>", Pattern.CASE_INSENSITIVE);
// 过滤html标签的正则
Pattern phtml = Pattern.compile("<[^>]+>", Pattern.CASE_INSENSITIVE);
// 执行过滤script标签
Matcher mscript = pscript.matcher(html);
html = mscript.replaceAll("");
// 执行过滤style标签
Matcher mstyle = pstyle.matcher(html);
html = mstyle.replaceAll("");
// 执行过滤html标签
Matcher mHtml = phtml.matcher(html);
html = mHtml.replaceAll("");
// 返回文本字符串
return html.trim();
}
2. 使用Jsoup组件去除html标签
pom文件:
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.12.1</version>
</dependency>
/**
* 去除Html标签
*
* @param html
* html内容
* @return 去除标签后的文本
*/
public static String wipeOffHtmlLabel(String html) {
// null则返回空字符串
if (Objects.isNull(html)) {
return "";
}
// 异常返回自身
try {
return Jsoup.parse(html).text();
} catch (Exception e) {
return html;
}
}
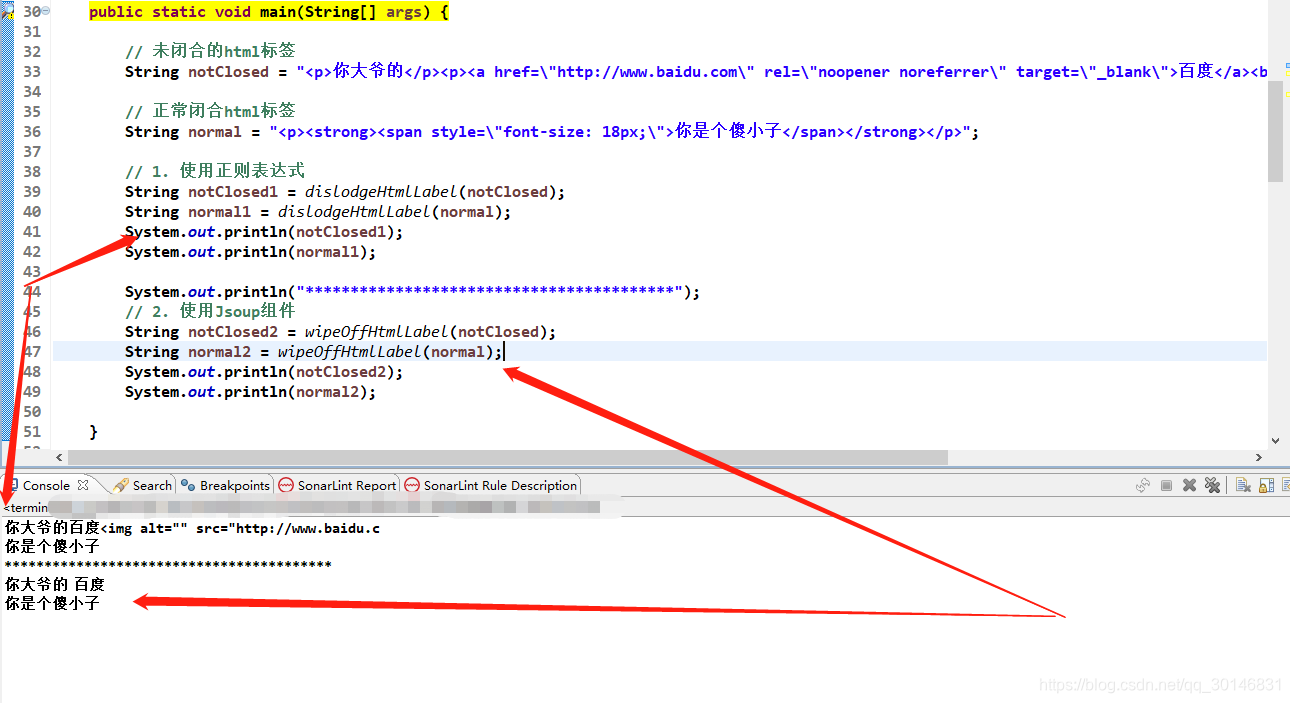
3. 运行情况
public static void main(String[] args) {
// 未闭合的html标签
String notClosed = "<p>你大爷的</p><p><a href=\"http://www.baidu.com\" rel=\"noopener noreferrer\" target=\"_blank\">百度</a><br><br><img alt=\"\" src=\"http://www.baidu.c";
// 正常闭合html标签
String normal = "<p><strong><span style=\"font-size: 18px;\">你是个傻小子</span></strong></p>";
// 1. 使用正则表达式
String notClosed1 = dislodgeHtmlLabel(notClosed);
String normal1 = dislodgeHtmlLabel(normal);
System.out.println(notClosed1);
System.out.println(normal1);
System.out.println("*****************************************");
// 2. 使用Jsoup组件
String notClosed2 = wipeOffHtmlLabel(notClosed);
String normal2 = wipeOffHtmlLabel(normal);
System.out.println(notClosed2);
System.out.println(normal2);
}
结果:
4. 结论
- 完全闭合的标签推荐使用正则表达式,因为是轻量级的。
- 如果是从数据库中查出截断的html文本,最好使用Jsoup组件,支持去除未闭合的标签。














 2380
2380











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









