







环境:ubuntn 14.04
1:将hadoop的目录加入环境变量中
gedit .bashrc
export JAVA_HOME=/usr/local/java
export PATH=$PATH:$JAVA_HOME/bin
export HADOOP_HOME=/home/willian/programing/hadoop-2.7.3
export PATH=$PATH:$HADOOP_HOME/bin保存
2:在job提交的类中配置本地属性
public class FlowDriver {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
//本地调试模式
// conf.set("mapreduce.framework.name","local");
// conf.set("fs.defaultFS","file:///");
Job job = Job.getInstance();3:在run中配置启动参数
点开idea的中run->Edit COnfigurations 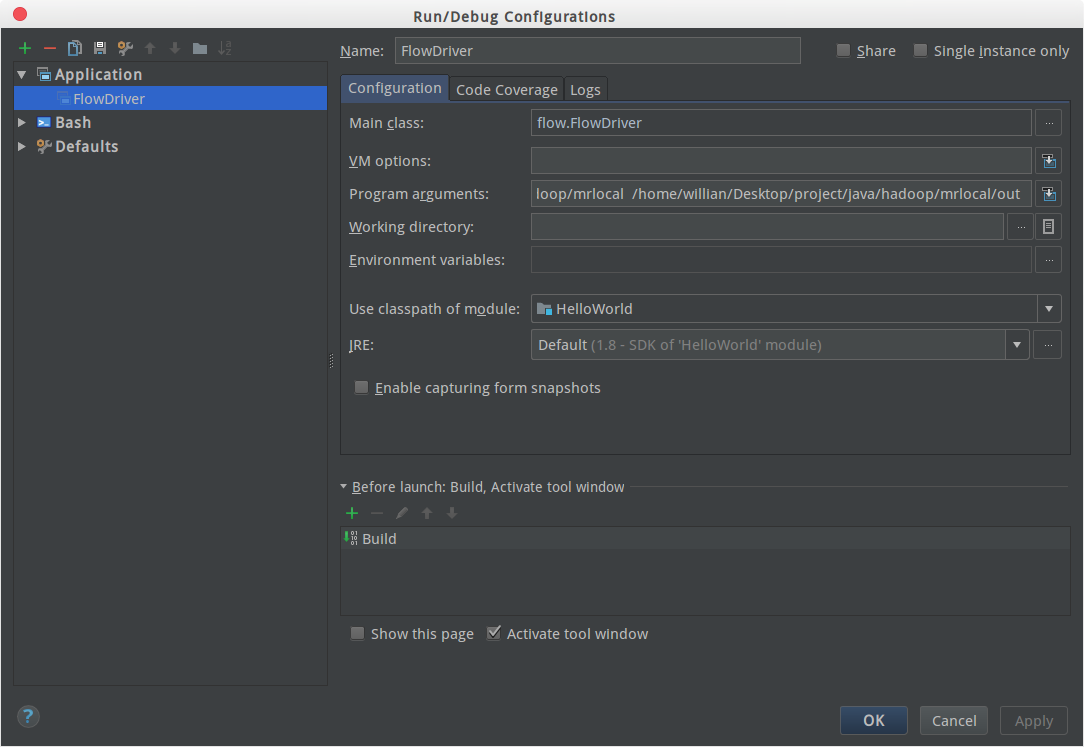
在program arguments中配置你的启动参数,目录最好都是本地的
二:本地提交模式
1:当本地debug通过后,可以直接本地提交,不需要打成jar上传
将本地模式的job提交改:
// //本地调试模式
// conf.set("mapreduce.framework.name","local");
// conf.set("fs.defaultFS","file:///");
//本地提交模式
conf.set("mapreduce.framework.name","local");
conf.set("fs.defaultFS","hdfs://master:9000"); //指定本程序的jar包所在的本地路径
// job.setJarByClass(DataJoin.class);
job.setJar("/home/willian/Desktop/project/java/hadoop/out/jar/word.jar");直接写本地jar包的绝对路径,用来构建jobsummiter
2:然后是启动参数:
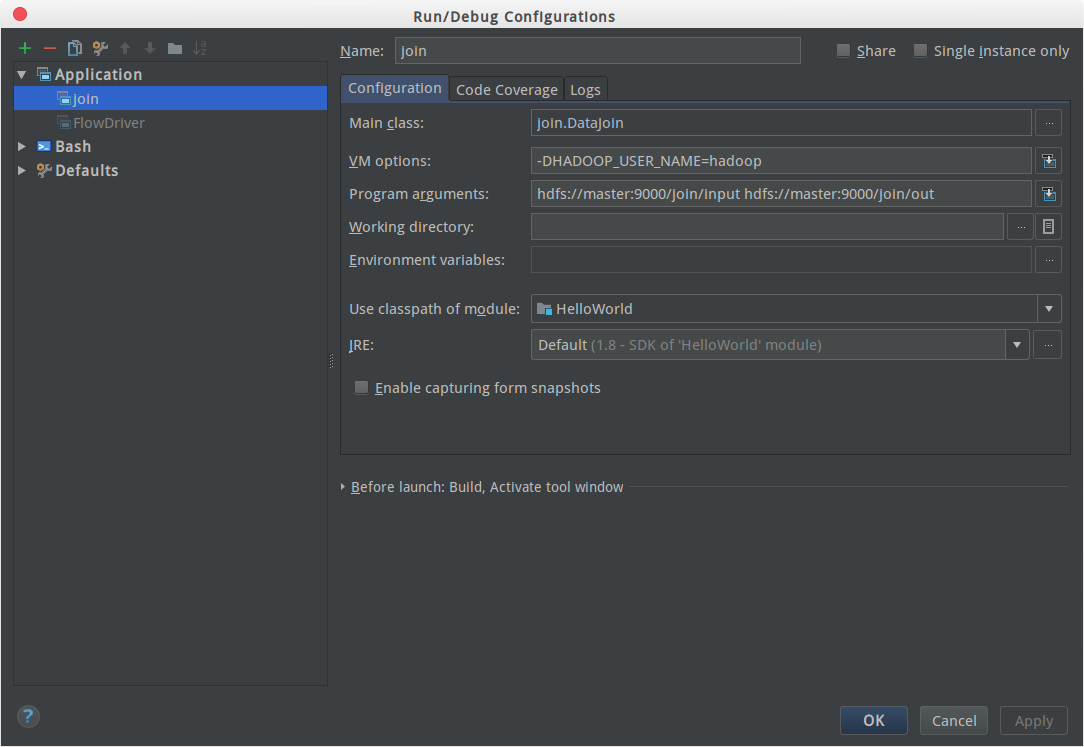
启动参数写hdfs的绝对路径
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









