






文章目录
分布式id生成方案
UUID
UUID的优点是性能极高,有多种实现方式,缺点是位数长,在mysql中不适合作为主键,并且基于MAC地址生产的UUID可能造成MAC地址泄露。
UUID的结构
UUID占用128bit,通常由32个16进制数表示,并且按照8-4-4-4-12的顺序进行分割排序。
UUID的结构由三部分组成,分别是Timestamp、Clock Sequence时钟序列、node节点信息(和MAC地址有关)。
- Timestamp
timestamp字段一共有60bit位,time_low占用32bit,time_mid_占用16bit,time_hi_and_version中time_hi部分占用12bit,version占用4bit,因此最多有31个版本. - Clock Sequence
如果计算UUID的机器进行了时间调整,或者是nodeID变化,和其x机器冲突。那么此时需要由原先的Clock Sequence变量来保证再次生成UUID的唯一性。
当时间调整时或者nodeid变化时,会直接使用一个随机数字或者在原先的值上加1。
Clock Sequence 一共有14bit,clock_seq_low 8bit、clock_seq_hi_and_reserved hi部分6bit,reserved 2bit一般设置为10 - node
node 这个变量因子由MAC地址组成,通常是IP地址。它有48bit大小。其中的 0-15填入node(0-1)的位置,16-47填入node(2-5)的位置。
snowflake
这种方案大致来说是一种以划分命名空间(UUID也算,由于比较常见,所以单独分析)来生成ID的一种算法,这种方案把64-bit分别划分成多段,分开来标示机器、时间等,比如在snowflake中的64-bit分别表示如下图(图片来自网络)所示:
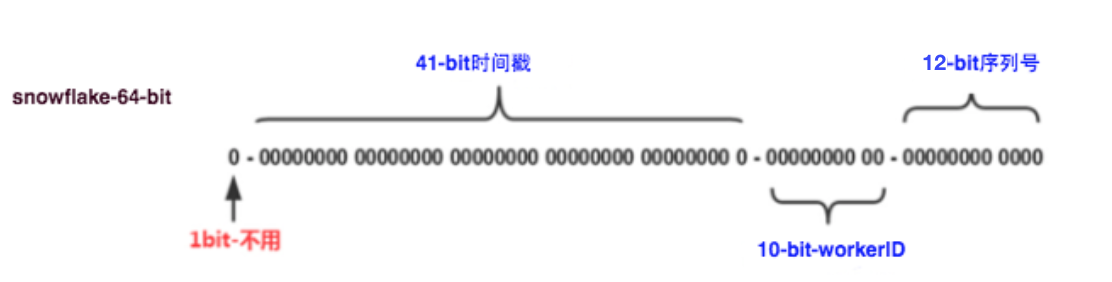
41-bit的时间可以表示(1L<<41)/(1000L360024*365)=69年的时间,10-bit机器可以分别表示1024台机器。如果我们对IDC划分有需求,还可以将10-bit分5-bit给IDC,分5-bit给工作机器。这样就可以表示32个IDC,每个IDC下可以有32台机器,可以根据自身需求定义。12个自增序列号可以表示2^12个ID,理论上snowflake方案的QPS约为409.6w/s,这种分配方式可以保证在任何一个IDC的任何一台机器在任意毫秒内生成的ID都是不同的。
优点:
- 毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
- 不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
- 可以根据自身业务特性分配bit位,非常灵活。
缺点:
- 强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
数据库主键id
以MySQL举例,利用给字段设置auto_increment_increment和auto_increment_offset来保证ID自增,每次业务使用下列SQL读写MySQL得到ID号。
优点:
- 非常简单,利用现有数据库系统的功能实现,成本小,有DBA专业维护。
- ID号单调自增,可以实现一些对ID有特殊要求的业务。
缺点:
- 强依赖DB,当DB异常时整个系统不可用,属于致命问题。配置主从复制可以尽可能的增加可用性,但是数据一致性在特殊情况下难以保证。主从切换时的不一致可能会导致重复发号。
- ID发号性能瓶颈限制在单台MySQL的读写性能。
对于MySQL性能问题,可用如下方案解决:在分布式系统中我们可以多部署几台机器,每台机器设置不同的初始值,且步长和机器数相等。
比如有两台机器。设置步长step为2,TicketServer1的初始值为1(1,3,5,7,9,11…)、TicketServer2的初始值为2(2,4,6,8,10…)。这是Flickr团队在2010年撰文介绍的一种主键生成策略(Ticket Servers: Distributed Unique Primary Keys on the Cheap )。如下所示,为了实现上述方案分别设置两台机器对应的参数,TicketServer1从1开始发号,TicketServer2从2开始发号,两台机器每次发号之后都递增2。
这种架构貌似能够满足性能的需求,但有以下几个缺点:
- 系统水平扩展比较困难,比如定义好了步长和机器台数之后,如果要添加机器该怎么做?假设现在只有一台机器发号是1,2,3,4,5(步长是1),这个时候需要扩容机器一台。可以这样做:把第二台机器的初始值设置得比第一台超过很多,比如14(假设在扩容时间之内第一台不可能发到14),同时设置步长为2,那么这台机器下发的号码都是14以后的偶数。然后摘掉第一台,把ID值保留为奇数,比如7,然后修改第一台的步长为2。让它符合我们定义的号段标准,对于这个例子来说就是让第一台以后只能产生奇数。扩容方案看起来复杂吗?貌似还好,现在想象一下如果我们线上有100台机器,这个时候要扩容该怎么做?简直是噩梦。所以系统水平扩展方案复杂难以实现。
- ID没有了单调递增的特性,只能趋势递增,这个缺点对于一般业务需求不是很重要,可以容忍。
- 数据库压力还是很大,每次获取ID都得读写一次数据库,只能靠堆机器来提高性能。
美团的解决方案
Leaf-segment(数据库优化)
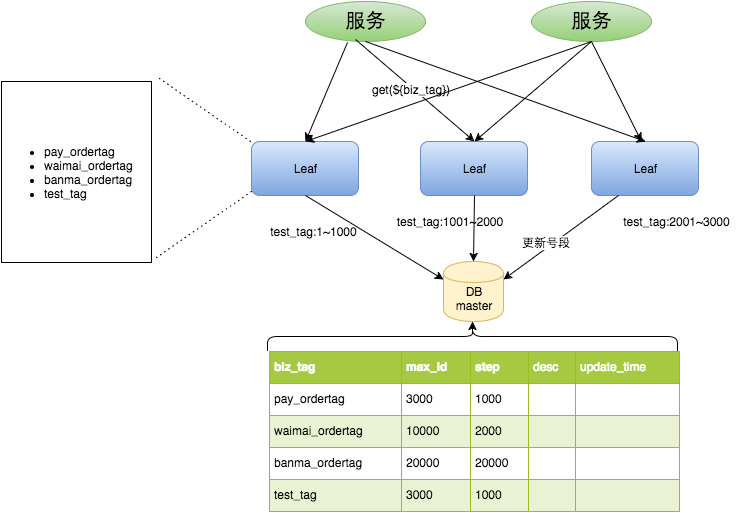
数据库表设计如下:
+-------------+--------------+------+-----+-------------------+-----------------------------+
| Field | Type | Null | Key | Default | Extra |
+-------------+--------------+------+-----+-------------------+-----------------------------+
| biz_tag | varchar(128) | NO | PRI | | |
| max_id | bigint(20) | NO | | 1 | |
| step | int(11) | NO | | NULL | |
| desc | varchar(256) | YES | | NULL | |
| update_time | timestamp | NO | | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP |
+-------------+--------------+------+-----+-------------------+-----------------------------+
设计后的主要改动点:
1、可以批量获取一批次的id
2、业务之间的id号可以相互隔离
缺点:
1、ID号码不够随机,安全性欠佳
2、性能上可能偶尔出现数据库瓶颈
3、db需要高可用
优化数据库更新性能(上面的缺点2)
Leaf 取号段的时机是在号段消耗完的时候进行的,也就意味着号段临界点的ID下发时间取决于下一次从DB取回号段的时间,如果出现网络不稳定将导致阻塞。
双buffer优化方案:

采用双buffer的方式,Leaf服务内部有两个号段缓存区segment。当前号段已下发10%时,如果下一个号段未更新,则另启一个更新线程去更新下一个号段。当前号段全部下发完后,如果下个号段准备好了则切换到下个号段为当前segment接着下发,循环往复。
-
每个biz-tag都有消费速度监控,通常推荐segment长度设置为服务高峰期发号QPS的600倍(10分钟),这样即使DB宕机,Leaf仍能持续发号10-20分钟不受影响。
-
每次请求来临时都会判断下个号段的状态,从而更新此号段,所以偶尔的网络抖动不会影响下个号段的更新。
高可用容灾
解决的是第三点数据库宕机的情况
对于第三点“DB可用性”问题,我们目前采用一主两从的方式,同时分机房部署,Master和Slave之间采用半同步方式同步数据。同时使用公司Atlas数据库中间件(已开源,改名为DBProxy)做主从切换。当然这种方案在一些情况会退化成异步模式,甚至在非常极端情况下仍然会造成数据不一致的情况,但是出现的概率非常小。如果你的系统要保证100%的数据强一致,可以选择使用“类Paxos算法”实现的强一致MySQL方案(即二步提交),如MySQL 5.7前段时间刚刚GA的MySQL Group Replication。但是运维成本和精力都会相应的增加,根据实际情况选型即可。
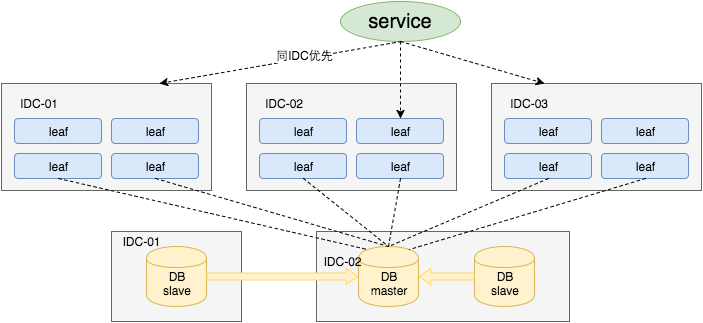
同时Leaf服务分IDC部署,内部的服务化框架是“MTthriftRPC”。服务调用的时候,根据负载均衡算法会优先调用同机房的Leaf服务。在该IDC内Leaf服务不可用的时候才会选择其他机房的Leaf服务。
Left-snowflake(雪花优化)
使用了snowflake+zookeeper+zookeeper缓存的设计,zookeeper主要是存储workID工作号,在新服务启动时使用顺序号作为workID。
解决时钟回拨问题
因为这种方案依赖时间,如果机器的时钟发生了回拨,那么就会有可能生成重复的ID号,需要解决时钟回退的问题。
处理核心:启动服务后需要周期性的上传机械时间,启动服务的时候需要判断以前周期性上传的机械时间是否大于现在启动时的时间,如果相差5秒内,等待两倍时间,否则返回并且报警。














 524
524











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









