







文章目录
介绍
Linux GCC
头文件为pthread.h
C++
头文件
pthread
简单使用
#include<iostream>
#include<thread>
using namespace std;
void thread1() {
for(int i=0;i<20;++i)
cout << "thread1..." << endl;
}
void thread2() {
for (int i = 0; i<20; ++i)
cout << "thread2..." << endl;
}
int main(int argc, char* argv[]) {
thread th1(thread1); //实例化一个线程对象th1,该线程开始执行
thread th2(thread2);
cout << "main..." << endl;
return 0;
}
结果报错如下(平台vs2019):
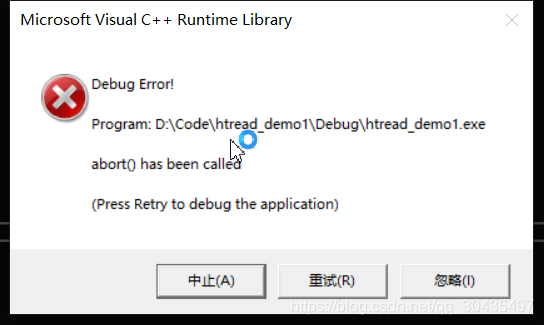
结果分析:上例是有问题的,因为在创建了线程后线程开始执行,但是主线程main()并没有停止脚步,仍然继续执行然后退出,此时线程对象还是joinable(可结合的),线程仍然存在但指向它的线程对象已经销毁,所以会中断。
解决方法
方案一:thread::join()
使用join接口可以解决上述问题,join的作用是让主线程等待直到该子线程执行结束。
#include <iostream>
#include <thread>
void A()
{
for(int i=0;i<100;i++)
std::cout << "thread 1111111111111" << std::endl;
}
void B()
{
for (int i = 0; i < 100; i++)
std::cout << "thread 222222222222" << std::endl;
}
int main()
{
std::thread th1(A);
std::thread th2(B);
th1.join();
th2.join();
return 0;
}
运行结果如下:
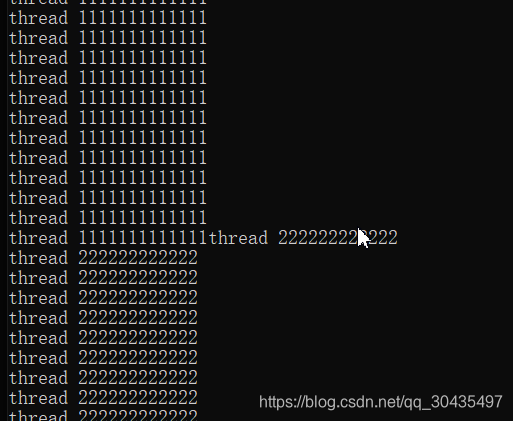
运行结果中,可以看到打印结果交叉出现。表示程序在并行运行。看到程序中一个完整的打印为“thread xxxxxxxx” 后面为换行然后接着运行,但在上述打印中出现多处不预期的打印情况,如上缺少换行符,原因在于线程1在运行中途,线程2运行,同时抢用同一个打印输出终端,在其中一个程序终端未运行打印完成输出语句时,另外一个线程占用了打印终端,并接着打印输出,故出现不预期的打印状况。这种情况及时常见的共享资源竞争,当多个线程程序在运行时,对同一个内存或资源在多个运行线程中同时被使用,这会出现资源的抢占。也因为此种情况,故在编程中出现了锁,通过互斥锁等操作锁定某个资源或者内存在某个时间只能由某一个指定线程访问,而其他线程不能访问。另外及原子操作也引申而出,具体说明请看后面章节。
在C/C++编程中,总所周知,程序永远都是顺序执行的,在同一时间同一个CPU内只能执行同一个操作,由于这样的特性,导致最开始出现的程序如下图
init()//初始化配置系统、时钟等操作
//完成配置后,进入死循环
while(1)
{
//TODO:轮训检测外界状态,更具某个触发条件,执行某个相应的操作
//而对于不需要操作时,则等待、延时、或者一直轮循
}
上述操作是很多在没有操作系统的CPU,单片机、ARM等芯片里的运行情况。由于这种情况会导致CPU处于一直暂用的情况,但没有触发状态时,CPU一直处于等待延时中,故导致芯片的利用率比价低,且程序运行的风险比较大。故为提高CPU的使用率,以及中断处理系统的出现。导致许多小型系统的出现,而出现的这些系统大多基于抢占式和时间片法,这样的使用使得CPU的率用率大大提高,也一定程度提高了程序的安全性,降低了风险,虽然由于额外代码的添加导致CPU额外的工作增加,但这缺点远小于多任务处理带来的好处。也因为中断的使用,使得程序的while(1)轮循方式变为了软触发方式,进而可以在运行其他的任务同时通过某种中断触发该事件的发生,而不会出现轮循其他任务而不响应该事件(这是一种极大的风险,例如USB检测,U盘挂载)。而随着这种小系统的不断健壮,以及安全性的提高,而出现了多任务。同时由于多核架构的出现,使得多任务程序可以并行运行(多核之前的多任务其实还是顺序执行的)。随着多线程和安全性不断发展,也牺牲了CPU的实时性以及需要更高性能的CPU来支持当前系统负荷。这种利弊也导致了小型系统没有消失的原因,这些小型系统安全性等不如windos、Linux,但他们的实时性更高(这对于实时性要求高的系统很重要,如vxworks,ucos),且对于廉价的CPU(如单片机,51,PowerPC)有更好兼容性。
#include <iostream>
#include <thread>
void A()
{
for(int i=0;i<100;i++)
std::cout << "thread 1111111111111" << std::endl;
}
void B()
{
for (int i = 0; i < 100; i++)
std::cout << "thread 222222222222" << std::endl;
}
int main()
{
std::thread th1(A);
std::thread th2(B);
th1.join();
std::cout << "thread main" << std::endl;
th2.join();
std::cout << "thread main1" << std::endl;
for (int i = 0; i < 10; i++)
std::cout << "thread 3333333" << std::endl;
return 0;
}
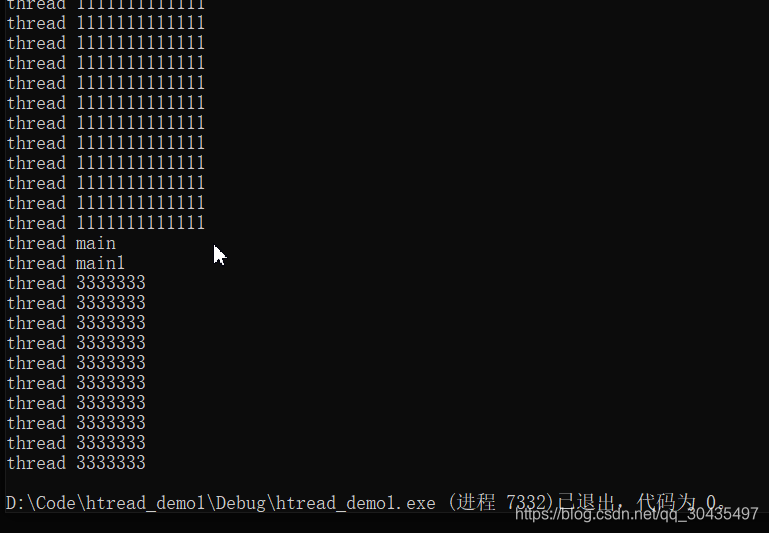
该方案中使用了std::thread.join()来运行多线程任务。该函数的特点就是当子线程没有运行完成时,主线程不会提前结束。只有当子线程执行完成后main主线程才会继续向下运行。
结果分析:此时就可以正常地执行子线程了,同时注意最后一个输出,说明了main是等待子线程结束才继续执行的。
需要注意的是线程对象执行了join后就不再joinable(判断线程是否可以加入等待)了,所以只能调用join一次。
joinable: 检查线程是否可被 join。检查当前的线程对象是否表示了一个活动的执行线程,由默认构造函数创建的线程是不能被 join 的。另外,如果某个线程已经执行完任务,但是没有被 join 的话,该线程依然会被认为是一个活动的执行线程,因此也是可以被 join 的。
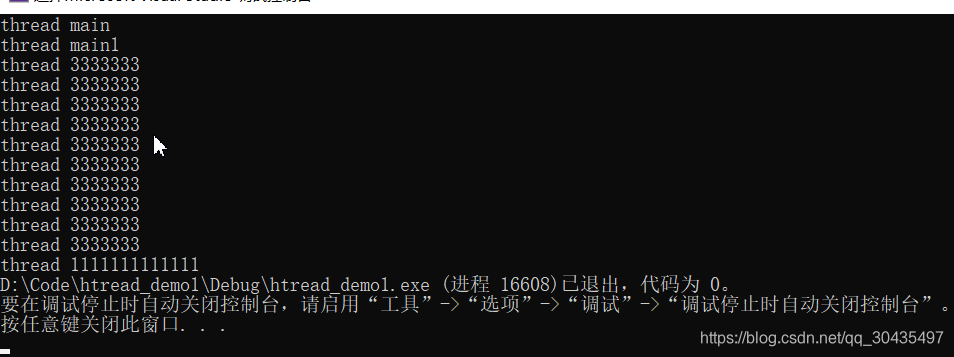
方案二:thread::detach()
将当前线程对象所代表的执行实例与该线程对象分离,使得线程的执行可以单独进行。一旦线程执行完毕,它所分配的资源将会被释放。
detach是用来分离线程,这样线程可以独立地执行,不过这样由于没有thread对象指向该线程而失去了对它的控制,当对象析构时线程会继续在后台执行,但是当主程序退出时并不能保证线程能执行完。如果没有良好的控制机制或者这种后台线程比较重要,最好不用detach而应该使用join。
#include <iostream>
#include <thread>
void A()
{
for (int i = 0; i < 20; i++)
std::cout << "thread 1111111111111" << std::endl;
}
void B()
{
for (int i = 0; i < 20; i++)
std::cout << "thread 222222222222" << std::endl;
}
int main()
{
std::thread th1(A);
std::thread th2(B);
th1.detach();
std::cout << "thread main" << std::endl;
th2.detach();
std::cout << "thread main1" << std::endl;
for (int i = 0; i < 10; i++)
std::cout << "thread 3333333" << std::endl;
return 0;
}
参数
返回值
#if 0
#include <iostream> // std::cout
#include <functional> // std::ref
#include <thread> // std::thread
#include <future> // std::promise, std::future
#include <chrono>
void print_int(std::future<int>& fut) {
//for (int i = 0; i < 10; i++)
{
int x = fut.get(); // 获取共享状态的值.
std::cout << "value: " << x << '\n'; // 打印 value: 10.
}
}
void tt()//std::packaged_task<int()>& fun)
{
for (int i = 0; i < 10; i++)
{
std::cout << i << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(1));
}
}
int main()
{
//std::packaged_task<int()>
//int (*ta)()= ([]() {std::this_thread::sleep_for(std::chrono::seconds(5)); return 10; });
//std::thread th2(std::move(ta));
//th2.join();
//int x = ta.get_future().get();
//std::cout<<ta() << std::endl;
std::packaged_task<int()> ta([]() {std::this_thread::sleep_for(std::chrono::seconds(1)); return 10; });
std::future<int> fu = ta.get_future();
std::thread th2(std::move(ta));
th2.join();
//int x = ta.get_future().get();errorxxxxxxxxxxxxxxxxxxxxxxxxxx
int x = fu.get();
std::cout << x << std::endl;
std::promise<int> prom; // 生成一个 std::promise<int> 对象.
std::future<int> fut = prom.get_future(); // 和 future 关联.
std::thread t(print_int, std::ref(fut)); // 将 future 交给另外一个线程t.
prom.set_value(10); // 设置共享状态的值, 此处和线程t保持同步.
t.join();
return 0;
}
#elif 0
#include <iostream>
#include <stdio.h>
#include <fstream>
using namespace std;
#define fin "1.txt"
class Sort
{
public:
Sort();
~Sort();
private:
int* buf;
int* cnt;
ofstream ofile;
ifstream ifile;
};
Sort::Sort()
{
ifile.open(fin, ios::in);
ofile.open("2.txt", ios::hex | ios::out);
buf = (int*)malloc(128 * 4);
cnt = 0;
}
Sort::Sort()
{
ifile.close();
ofile.close();
}
int main(void)
{
}
#elif 0
#include <memory>
#include <iostream>
#include "ThreadPool.h"
using namespace std;
struct B;
struct A { shared_ptr<B> b; };
struct B { weak_ptr<A> a; };
class Person
{
public:
Person(int val);
~Person();
private:
int v;
};
Person::Person(int val)
{
cout << "initial..............." << val << endl;
v = val;
}
Person::~Person()
{
cout << "destory................."<<v << endl;
}
int main()
{
shared_ptr<A> x(new A);
//x->b = new B; // wrong
//x->b = shared_ptr<B>(new B);
x->b = make_shared<B>();
x->b->a = x;
cout << x.use_count() << endl;
cout << x->b.use_count() << endl;
// Ref count of 'x' is 1.
// Ref count of 'x->b' is 1.
// When 'x' leaves the scope, its ref count will drop to 0.
// While destroying it, ref count of 'x->b' will drop to 0.
// So both A and B will be deallocated. cout << x->b.use_count() <<endl;
unique_ptr<Person> p1(new Person(13));
shared_ptr<Person> p2(new Person(12));
unique_ptr<Person> pu = make_unique<Person>(0);
shared_ptr<Person> ps1= make_shared<Person>(1);
shared_ptr<Person> ps11 = ps1;
shared_ptr<Person> ps12 = ps11;
cout << ps1.use_count() << endl;
weak_ptr<Person> pw = ps12;
cout << ps1.use_count() << endl;
ps1.reset(new Person(2));
ps1.swap(ps11);
cout << ps11.use_count() << endl;
cout << ps1.use_count() << endl;
shared_ptr<string>p3 = make_shared<string>("93224");//传递的参数必须与string的某个构造函数相匹配
cout << *p3 << endl;
//cout << ps1.use_count() << endl;
//ps1.reset();
//cout << ps11.use_count() << endl;
/*
auto dr = p1.get();
cout << typeid(dr).name() << endl;
*/
return 0;
}
#else
#include "ThreadPool.h"
#include <iostream>
#include <stdio.h>
void fun1(int slp)
{
printf(" hello, fun1 ! %d\n", std::this_thread::get_id());
if (slp > 0) {
printf(" ======= fun1 sleep %d ========= %d\n", slp, std::this_thread::get_id());
std::this_thread::sleep_for(std::chrono::milliseconds(slp));
}
}
struct gfun {
int operator()(int n) {
printf("%d hello, gfun ! %d\n", n, std::this_thread::get_id());
return 42;
}
};
class A {
public:
static int Afun(int n = 0) { //函数必须是 static 的才能直接使用线程池
std::cout << n << " hello, Afun ! " << std::this_thread::get_id() << std::endl;
return n;
}
static std::string Bfun(int n, std::string str, char c) {
std::cout << n << " hello, Bfun ! " << str.c_str() << " " << (int)c << " " << std::this_thread::get_id() << std::endl;
return str;
}
};
int main()
try {
std::ThreadPool executor{ 50 };
A a;
std::future<void> ff = executor.addTask(fun1, 0);
std::future<int> fg = executor.addTask(gfun{}, 0);
std::future<int> gg = executor.addTask(gfun{}, 0);// a.Afun, 9999); //IDE提示错误,但可以编译运行
std::future<std::string> gh = executor.addTask(A::Bfun, 9998, "mult args", 123);
std::future<std::string> fh = executor.addTask([]()->std::string { std::cout << "hello, fh ! " << std::this_thread::get_id() << std::endl; return "hello,fh ret !"; });
std::cout << " ======= sleep ========= " << std::this_thread::get_id() << std::endl;
std::this_thread::sleep_for(std::chrono::microseconds(900));
for (int i = 0; i < 50; i++) {
executor.addTask(fun1, i * 100);
}
std::cout << " ======= addTask all ========= " << std::this_thread::get_id() << " idlsize=" << executor.getIdlThrNum() << std::endl;
std::cout << " ======= sleep ========= " << std::this_thread::get_id() << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(3));
ff.get(); //调用.get()获取返回值会等待线程执行完,获取返回值
std::cout << fg.get() << " " << fh.get().c_str() << " " << std::this_thread::get_id() << std::endl;
std::cout << " ======= sleep ========= " << std::this_thread::get_id() << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(3));
std::cout << " ======= fun1,55 ========= " << std::this_thread::get_id() << std::endl;
executor.addTask(fun1, 55).get(); //调用.get()获取返回值会等待线程执行完
std::cout << "end... " << std::this_thread::get_id() << std::endl;
std::ThreadPool pool(4);
std::vector< std::future<int> > results;
for (int i = 0; i < 8; ++i) {
results.emplace_back(
pool.addTask([i] {
std::cout << "hello " << i << std::endl;
std::this_thread::sleep_for(std::chrono::seconds(1));
std::cout << "world " << i << std::endl;
return i * i;
})
);
}
std::cout << " ======= addTask all2 ========= " << std::this_thread::get_id() << std::endl;
for (auto&& result : results)
std::cout << result.get() << ' ';
std::cout << std::endl;
return 0;
}
catch (std::exception & e) {
std::cout << "some unhappy happened... " << std::this_thread::get_id() << e.what() << std::endl;
}
#endif
原子操作
原子操作即是对于编程最小操作,如同原子般不可分割。这里的最小是指可操作性最小,并非代码最小。正如先前多线程提到,在无锁的多线程程序中,一个线程中途会被其他线程所中断,而出现不预期后果。而原子操作针对其他线程是一个整体,中间不可分割,即原子性。这种原子性人为可定义,但定义需要考量,这也是多线程的难点。
个人的多线程,原子性编程最大的难点就在于如何定义这个原子以及锁的区域,如果定义范围过小,极有可能会导致提到过的资源抢占而出现不预期错误。如果定义过大,程序就会变得如同串行程序一样,无法充分发挥并行编程的优点,故具体如何定义,需要个人长期的锻炼和判断。
锁
mutex
C++中互斥锁的头文件为mutex
mutex:互斥锁锁定某个资源仅为该线程所有,而不能被其他线程所使用。mutex通常成对存在,必须在使用lock()后面的某个位置使用unlock()。
lock :锁定该资源:
当互斥量未被锁定时,当前线程锁定互斥量,指导调用lock,解锁该线程。
当互斥量被其他线程锁定时,当前线程阻塞,直到其他线程释放该互斥量。
当互斥量被当前线程锁定,发生死锁
unlock:解锁该线程
try_lock:尝试锁该线程
当资源被其他线程锁定时,返回false,且线程不住塞。
当资源未被锁定时,返回true。锁定该线程。
当资源被当前线程锁定时,产生死锁。
std::lock_guard
来源于RAII模板,创建函数中自动加锁,解析函数中自动解锁。故该锁从定义开始到当前块结束的整个生命周期都存在。源于对mutex优化,只要使用该函数,就可执行解锁,从而避免了mutex使用lock()后而忘记使用unlock()问题。
std::unique_lock
锁
自旋锁
spinlock_t
spin_lock_init
spin_lock
spin_unlock
死锁
信号量
内核信号量
void sema_init(struct semaphore *sem, int val);
void init_MUTEX(struct semaphore *sem); //初始值1
void init_MUTEX_LOCKED(struct semaphore *sem); //初始值0
void down(struct semaphore *sem); //可睡眠
int down_interruptible(struct semaphore *sem); //可中断
int down_trylock(struct semaphore *sem); //m非阻塞
void up(struct semaphore *sem);
进程通信:SYSTEMV信号量
#include "sys/sem.h"
int semget(key_t key, int nsems, int oflag);
int semop(int semid, struct sembuf *opsptr, size_t nops);
int semctl(int semid, int semum, int cmd,...);
无名信号量
用于线程通信和fork下的进程通信
sem_t sem;
int sem_init(sem_t *sem, int pshared, unsigned int val); //pshared为0则线程间共享,pshared为1则父子进程共享
int sem_wait(sem_t *sem); //阻塞
int sem_timedwait(sem_t *sem, const struct timespec *abs_timeout);
int sem_trywait(sem_t *sem); //非阻塞
int sem_post(sem_t *sem);
int sem_destroy(sem_t *sem);
进程间共享则sem必须放在共享内存区域(mmap, shm_open, shmget),父进程的全局变量、堆、栈中存储是不行的
sem_wait()会等待信号,当没有信号发过来时,阻塞等待,当有信号时立即返回并且执行。
sem_trywait()会检测信号,如果信号没有发过来,则返回EAGAIN=11,如果有收到信号,返回0。
int sem_timedwait_millsecs(sem_t *sem, long msecs)
{
struct timespec ts;
clock_gettime(CLOCK_REALTIME, &ts);
long secs = msecs/1000;
msecs = msecs%1000;
long add = 0;
msecs = msecs*1000*1000 + ts.tv_nsec;
add = msecs / (1000*1000*1000);
ts.tv_sec += (add + secs);
ts.tv_nsec = msecs%(1000*1000*1000);
return sem_timedwait(sem, &ts);
#include "semaphore.h"
#include "time.h"
#include "unistd.h"
#include "stdio.h"
#include "pthread.h"
sem_t sem;
struct timespec tm;
void read(void *a)
{
int *pArr=(int *)a;
while (1)
{
if(sem_timedwait(&sem,&tm)!=0)
{
printf("time out\r\n");
}
else
{
printf("%d %d %d %d %d %d %d %d",pArr[0],pArr[1],pArr[2],pArr[3],pArr[4],pArr[5]);
}
sleep(2);
}
}
void write(void *a)
{
int i=0;
int *pArr=(void *)a;
while (1)
{
for ( i = 0; i < 10; i++)
{
pArr[i]=pArr[i]+1;
}
sem_post(&sem);
sleep(4);
}
}
void testSem()
{
int i=0;
int arr[10]={0};
// for(;i<100;i++)
// {
// arr[i]=i;
// }
tm.tv_nsec=10;
tm.tv_sec=10;
sem_init(&sem,0,0);
// sem_open
pthread_t rId;
pthread_t wId;
if(pthread_create(&rid,NULL,read,(void *)arr)<0)
{
// error
}
if(pthread_create(&wid,NULL,write,(void *)arr)<0)
{
// error
}
pthread_join(rId,NULL);
pthread_join(wId,NULL);
}
无名信号量只能存在于内存中,要求使用信号量的进程必须能访问信号量所在内存,所以无名信号量只能应用在同一进程内的线程之间(共享进程的内存),或者不同进程中已经映射相同内存内容到它们的地址空间中的线程(即信号量所在内存被通信的进程共享)。无名信号量只能通过共享内存访问。相反,有名信号量可以通过名字访问,因此可以被任何知道它们名字的进程中的线程使用。单个进程中使用 POSIX 信号量时,无名信号量更简单。多个进程间使用 POSIX 信号量时,有名信号量更简单。
有名信号量
sem_t *sem_open(const char *name, int oflag, mode_t mode, int val);
int sem_wait(sem_t *sem);
int sem_trywait(sem_t *sem);
int sem_post(sem_t *sem);
int sem_close(sem_t *sem);
int sem_unlink(const char *name);
每个open的位置都要close和unlink,但只有最后执行的unlink生效
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
#include <sys/sem.h>
//union semun
//{
// int val;
// struct semid_ds *buf;
// unsigned short *arry;
//};
static int sem_id = 0;
static int set_semvalue();
static void del_semvalue();
static int semaphore_p();
static int semaphore_v();
int main(int argc, char *argv[])
{
char message = 'X';
int i = 0;
// 创建信号量
sem_id = semget((key_t) 1234, 1, 0666 | IPC_CREAT);
if (argc > 1)
{
// 程序第一次被调用,初始化信号量
if (!set_semvalue())
{
fprintf(stderr, "Failed to initialize semaphore\n");
exit(EXIT_FAILURE);
}
// 设置要输出到屏幕中的信息,即其参数的第一个字符
message = argv[1][0];
sleep(2);
}
for (i = 0; i < 10; ++i)
{
// 进入临界区
if (!semaphore_p())
{
exit(EXIT_FAILURE);
}
// 向屏幕中输出数据
printf("%c", message);
// 清理缓冲区,然后休眠随机时间
fflush(stdout);
sleep(rand() % 3);
// 离开临界区前再一次向屏幕输出数据
printf("%c", message);
fflush(stdout);
// 离开临界区,休眠随机时间后继续循环
if (!semaphore_v())
{
exit(EXIT_FAILURE);
}
sleep(rand() % 2);
}
sleep(10);
printf("\n%d - finished\n", getpid());
if (argc > 1)
{
// 如果程序是第一次被调用,则在退出前删除信号量
sleep(3);
del_semvalue();
}
exit(EXIT_SUCCESS);
}
static int set_semvalue()
{
// 用于初始化信号量,在使用信号量前必须这样做
union semun sem_union;
sem_union.val = 1;
if (semctl(sem_id, 0, SETVAL, sem_union) == -1)
{
return 0;
}
return 1;
}
static void del_semvalue()
{
// 删除信号量
union semun sem_union;
if (semctl(sem_id, 0, IPC_RMID, sem_union) == -1)
{
fprintf(stderr, "Failed to delete semaphore\n");
}
}
static int semaphore_p()
{
// 对信号量做减1操作,即等待P(sv)
struct sembuf sem_b;
sem_b.sem_num = 0;
sem_b.sem_op = -1;//P()
sem_b.sem_flg = SEM_UNDO;
if (semop(sem_id, &sem_b, 1) == -1)
{
fprintf(stderr, "semaphore_p failed\n");
return 0;
}
return 1;
}
static int semaphore_v()
{
// 这是一个释放操作,它使信号量变为可用,即发送信号V(sv)
struct sembuf sem_b;
sem_b.sem_num = 0;
sem_b.sem_op = 1; // V()
sem_b.sem_flg = SEM_UNDO;
if (semop(sem_id, &sem_b, 1) == -1)
{
fprintf(stderr, "semaphore_v failed\n");
return 0;
}
return 1;
}














 3157
3157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









