







list接口中ArrayList、LinkedList都不是线程安全,Vector是线程安全
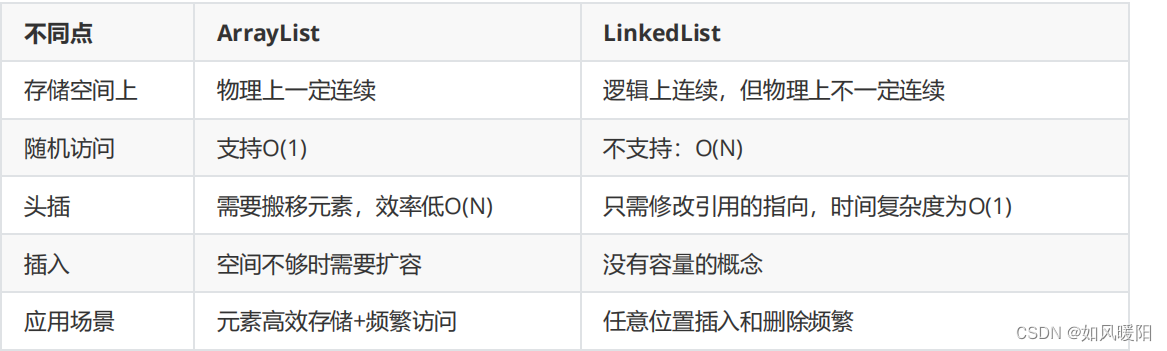
1、数据结构不同
ArrayList是Array(动态数组)的数据结构,LinkedList是Link(链表)双向链表的数据结构。
2、空间灵活性
ArrayList最好指定初始容量
LinkedList是比ArrayList灵活的,是根本不需要指定初始容量的
3、效率不同
当随机访问List(get和set操作)时,ArrayList比LinkedList的效率更高,因为LinkedList是线性的数据存储方式,所以需要移动指针从前往后依次查找。ArrayList对于数据查询非常快,但是插入与删除元素比较慢;
当对数据进行增加和删除的操作(add和remove操作)时,LinkedList速度非常快。
4、主要控件开销不同
ArrayList主要控件开销在于需要在List列表预留一定空间;
而LinkList主要控件开销在于需要存储节点信息以及节点指针。
其他
ArrayList是实现了基于动态数组的数据结构,LinkedList基于链表的数据结构。
对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
ArrayList:内部使用数组的形式实现了存储,实现了RandomAccess接口,利用数组的下面进行元素的访问,因此对元素的随机访问速度非常快。
因为是数组,所以ArrayList在初始化的时候,有初始大小10,插入新元素的时候,会判断是否需要扩容,扩容的步长是0.5倍原容量,扩容方式是利用数组的复制,因此有一定的开销;

另外,ArrayList在进行元素插入的时候,需要移动插入位置之后的所有元素,位置越靠前,需要位移的元素越多,开销越大,相反,插入位置越靠后的话,开销就越小了,如果在最后面进行插入,那就不需要进行位移。

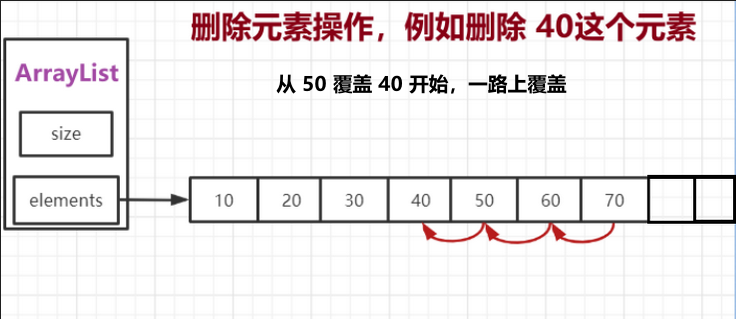
LinkedList:内部使用双向链表的结构实现存储,每一个节点有两个指针域,一个指向下一个节点,一个指向上一个节点。,LinkedList有一个内部类作为存放元素的单元Node,里面有三个属性,用来存放元素本身以及前后2个单元的引用,另外LinkedList内部还有一个header属性,用来标识起始位置,LinkedList的第一个单元和最后一个单元都会指向header,因此形成了一个双向的链表结构,如下:注:这个是旧版本的
private transient Entry<E> header = new Entry<E>(null, null, null);
public LinkedList() {
header.next = header.previous = header;
}
public E getFirst() {
if (size==0)
throw new NoSuchElementException();
return header.next.element;
}
public E getLast() {
if (size==0)
throw new NoSuchElementException();
return header.previous.element;
}
public E removeFirst() {
return remove(header.next);
}LinkedList是采用双向链表实现的。所以它也具有链表的特点,每一个元素(结点)的地址不连续,通过引用找到当前节点的上一个节点和下一个节点,即插入和删除效率较高,只需要常数时间,而get和set则较为低效。
LinkedList的方法和使用和ArrayList大致相同,由于LinkedList是链表实现的,所以额外提供了在头部和尾部添加/删除元素的方法,也没有ArrayList扩容的问题了。另外,ArrayList和LinkedList都可以实现栈、队列等数据结构,但LinkedList本身实现了队列的接口,所以更推荐用LinkedList来实现队列和栈。
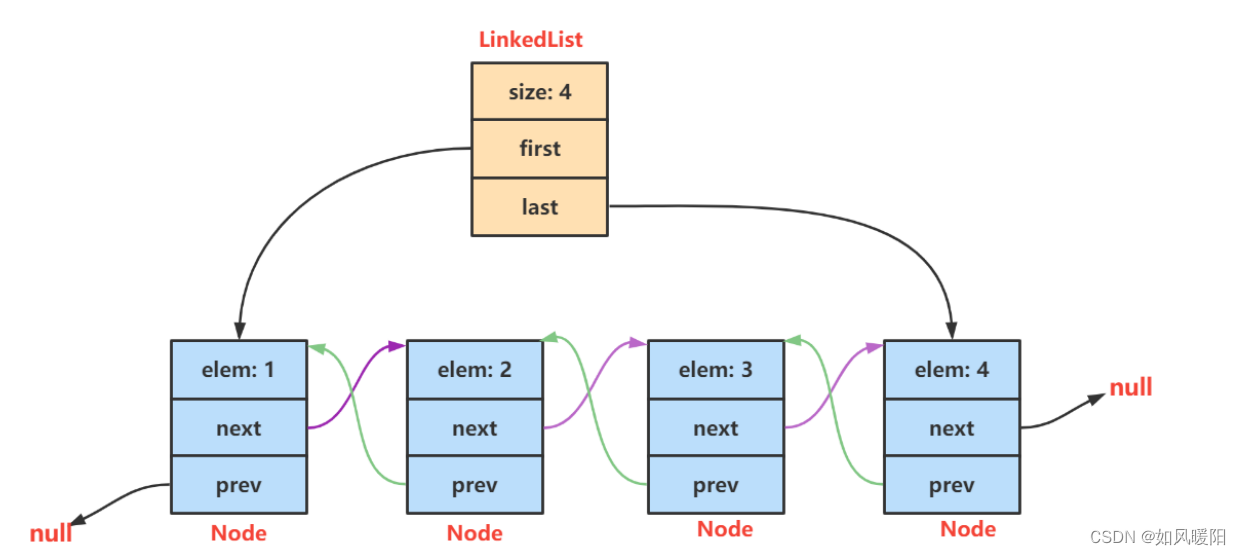
下面简单看一下linkedlist add 方法的源码,方便理解,注:这个是新版本java,已经没有header
public cTass LinkedList<E> extendsimpTements...{
transient int size = 0; // 链表长度
transient Node<E> first; // 指向链表第一个节点
transient Node<E> last; // 指向链表最后一个节点
...
public boolean add(E e) { // 添加元素
linkLast(e); // 向链表末尾添加元素e
return true;
}
...
}
void linkLast(E e) { // 向链表未尾添加元素
fina1 Node<E> 1 = last; // 暂时保存最后一个元素的指针
fina1 Node<E> newNode = new Node<>(1, e, nu11);
last = newNode; // newNode 作为最后一个节点
if (1 == nu11) // 当前链表为空
first = newNode; // 第一个添加的节点,即为 first
else // 链表不空
1.next = newNode; // 当前链表的最后一个节点next 指向newNode
size++;
modCount++;
}
// LinkedList 底层是一个双向链表
private static class Node<E> { // LinkedList 的节点静态内部类 Node
E item;
Node<E> next; // 后继
Node<E> prev; // 前驱
Node(Node<E> prev,E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}


使用场景:
(1)如果应用程序对数据有较多的随机访问,ArrayList对象要优于LinkedList对象;
( 2 ) 如果应用程序有更多的插入或者删除操作,较少的随机访问,LinkedList对象要优于ArrayList对象;
(3)不过ArrayList的插入,删除操作也不一定比LinkedList慢,如果在List靠近末尾的地方插入,那么ArrayList只需要移动较少的数据,而LinkedList则需要一直查找到列表尾部,反而耗费较多时间,这时ArrayList就比LinkedList要快。
2.链表
2.1 链表的概念及结构
链表是一种物理存储结构上非连续存储结构,数据元素的逻辑顺序是通过链表中的引用链接次序实现的 。
实际存储图:

理解逻辑图:

实际中链表的结构非常多样,以下情况组合起来就有8种链表结构:
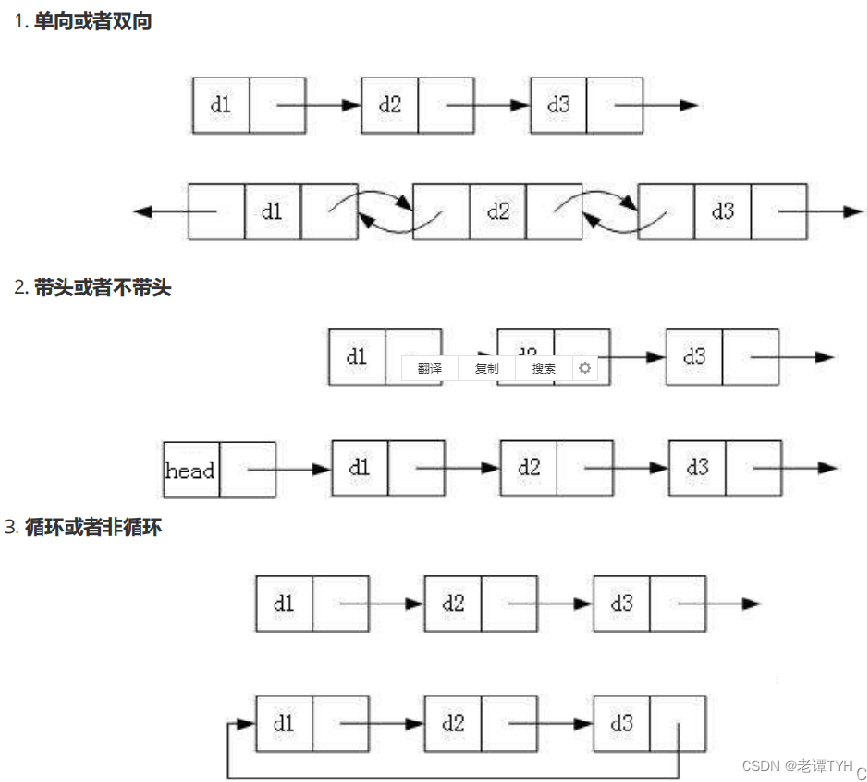
虽然有这么多的链表的结构,但是我们重点掌握两种:
无头单向非循环链表(就是我们常说的单链表):结构简单,一般不会单独用来存数据。实际中更多是作为其他数据结构的子结构,如 哈希桶、图的邻接表等等。另外这种结构在笔试面试中出现很多。
无头双向链表:在Java的集合框架库中LinkedList底层实现就是无头双向循环链表。
参考:














 1500
1500











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









