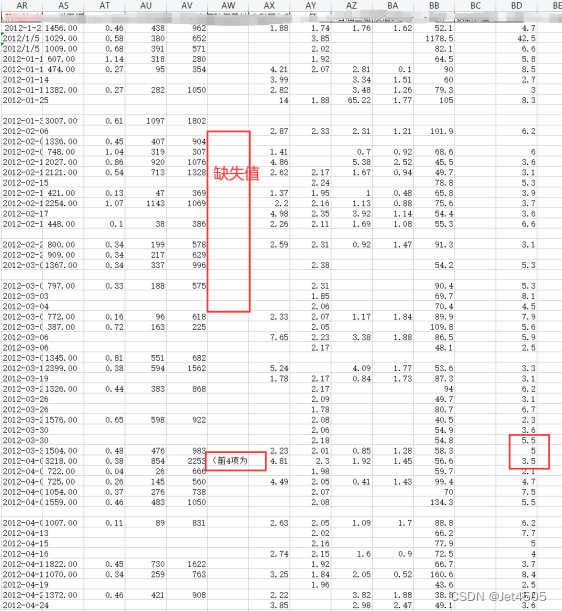
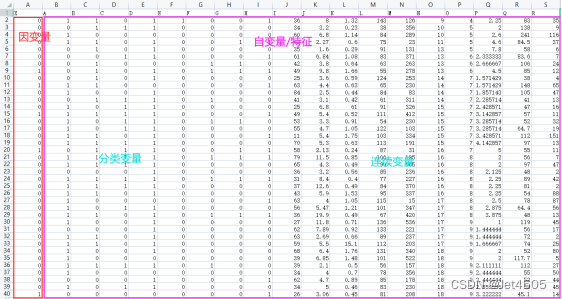
文章目录 前言 一、类型与格式 保姆级操作演示 二、缺失值 三、重复值 四、异常值 总结 前言 数据收集好了,接下来需要进行数据清理,也就是过滤和“修改”数据(注意,这个修改不是那个修改),使其更易于探索、理解和建模。 其中,过滤是指去掉不想要或不需要的部分,这样就不需要查看或处理它们。 这个“修改”是指数据的格式不是我们需要的,需要修正。 举个栗子,一般导出来的数据可能是这样的: 这个太惨了,列都没有分好。 或者这样的: 这个其实也还好,那种惨不忍睹的找不到了。 最后,来看看,模型认的数据是哪种(这个案例数据是我乱编的):








 超级会员免费看
超级会员免费看
 文章介绍了数据清理的重要性,包括数据的类型与格式规范,如将分类变量转换为数字编码,处理缺失值的策略,如根据比例选择填充方法,以及如何检测和删除重复值。此外,还讨论了异常值的识别与处理,提供了一些Python代码示例,如使用boxplot进行异常值检测。
文章介绍了数据清理的重要性,包括数据的类型与格式规范,如将分类变量转换为数字编码,处理缺失值的策略,如根据比例选择填充方法,以及如何检测和删除重复值。此外,还讨论了异常值的识别与处理,提供了一些Python代码示例,如使用boxplot进行异常值检测。


 订阅专栏 解锁全文
订阅专栏 解锁全文



















 1519
1519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


 被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言
被折叠的 条评论
为什么被折叠?
到【灌水乐园】发言








