







其实这篇文章应该是上周末来写的,但是苦逼啊。别人都抱怨工作996,我特么直接9117了,连轴转12天,完全没有个人时间,苦逼啊!

本来周末计划看完龙珠Z(日语)布欧篇 呢,给自己一个过儿童节的仪式感,结果也只看了一点,时间太紧张了。
要写的代码、要总结的东西太多了。至于ResultSet这个,从梳理思路、验证逻辑、查阅资料、理解原理、总结记录,又花了我小一天时间,搞到半夜。
一、背景
我五一的时候,写脚本通过代理爬取osm的栅格瓦片数据(即PNG图片),来将我之前写的wkt在线绘制展示_EPSG4326_致敬开源实现瓦片本地化。
对于瓦片数据来说,整个世界都是正方形的,如下图。
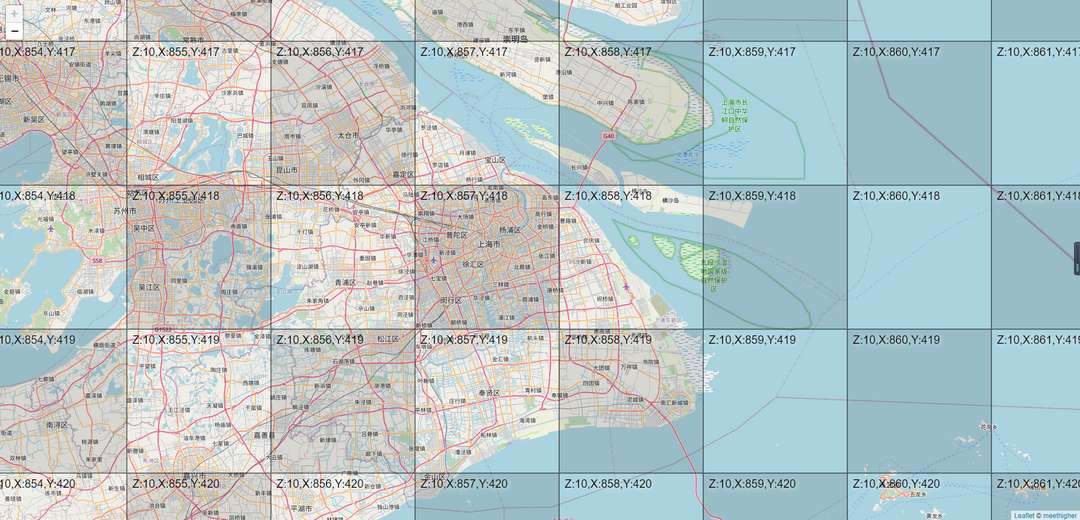
瓦片数据按层级划分如下
| zoom level | edge length | number of tiles |
|---|---|---|
| 0 | 1 | 1*1 |
| 1 | 2 | 2*2 |
| 2 | 4 | 4*4 |
| 3 | 8 | 8*8 |
| 4 | 16 | 16*16 |
| 5 | 32 | 32*32 |
| 6 | 64 | 64*64 |
| 7 | 128 | 128*128 |
| 8 | 256 | 256*256 |
| 9 | 512 | 512*512 |
| 10 | 1024 | 1024*1024 |
| 11 | 2048 | 2048*2048 |
| 12 | 4096 | 4096*4096 |
| 13 | 8192 | 8192*8192 |
| 14 | 16384 | 16384*16384 |
| 15 | 32768 | 32768*32768 |
| 16 | 65536 | 65536*65536 |
| 17 | 131072 | 131072*131072 |
| 18 | 262144 | 262144*262144 |
| 19 | 524288 | 524288*524288 |
想要爬取所有层级的栅格瓦片,数据量还是很大的。我从0层级一直爬取到19层级,需要存储14_3165_5765个瓦片,我存入了PostgreSQL。数据库肯定要有对应的可视化工具才好使呀,对于咱们这种面向SQL编程的码农来说,最常见的数据库可视化工具就两种
在结合这两个工具进行操作时,偶然发现,navicat和dbeaver中执行相同的SQL语句 select * from tiles 时,navicat会出现卡死无响应的情况,而dbeaver不仅不会卡、还会快速的查出前200条数据来。
怎么会出现这种情况呢,按理来说,navicat是闭源付费的,应该做的比dbeaver更好才对啊。
针对这个问题,我从原生的JDBC展开了探索。
二、ResultSet查询调优
以下调优只针对于PostgreSQL数据库。并不适用其他数据库。
通过自己手撕原生的JDBC查询ResultSet、以及查阅pgJDBC官方文档发现有两种查询方式。
- 默认参数结果集,驱动程序会一次性收集查询的所有结果行,通俗说是多量少次。这也是我们最常使用的方式了,但是数据量大时,会卡爆程序内存和网络带宽。
- 参数调优结果集,需要关闭查询时的事务,通俗说是少量多次。对于pg来说,查询时的事务也是默认开启的。这个方式对程序来说是性能最优之选。
pgJDBC文档描述如下图

下面就直接进行实战,源码地址为meethigher/result-set-test: this is a postgresql result-set demo
/**
* 方案一:
* 使用select * from table where order by 进行查询,但是使用默认方式
*/
private void plan1(String startTime, String endTime) {
StringBuilder queryBuilder = new StringBuilder("select * from ")
.append(jdbcUtils.getTableName())
.append(" where ")
.append(jdbcUtils.getFieldArray()[2]).append(" >= ? and ").append(jdbcUtils.getFieldArray()[2])
.append(" <= ? order by ").append(jdbcUtils.getFieldArray()[2]).append(" asc");
long start = System.currentTimeMillis();
long startUsedMemory = memoryMonitor.getUsedMemory();
try (Connection connection = jdbcUtils.getJdbcTemplate().getDataSource().getConnection()) {
PreparedStatement ps = connection.prepareStatement(queryBuilder.toString());
ps.setObject(1, startTime);
ps.setObject(2, endTime);
ResultSet rs = ps.executeQuery();
log.info("plan1 consumed {}, {}", TimeUtils.humanizedFormat(System.currentTimeMillis(), start),
memoryMonitor.convertBytes(memoryMonitor.getUsedMemory() - startUsedMemory));
} catch (Exception ignore) {
}
}
/**
* 方案二:
* 使用select * from table where order by 进行查询,但是使用参数调优
*/
private void plan2(String startTime, String endTime) {
StringBuilder queryBuilder = new StringBuilder("select * from ")
.append(jdbcUtils.getTableName())
.append(" where ")
.append(jdbcUtils.getFieldArray()[2]).append(" >= ? and ").append(jdbcUtils.getFieldArray()[2])
.append(" <= ? order by ").append(jdbcUtils.getFieldArray()[2]).append(" asc");
long start = System.currentTimeMillis();
long startUsedMemory = memoryMonitor.getUsedMemory();
try (Connection connection = jdbcUtils.getJdbcTemplate().getDataSource().getConnection()) {
//对于postgresql,只有关闭事务,setFetchSize才会生效
connection.setAutoCommit(false);
//对于postgresql,后面的两个参数其实也就是默认值时使用的
PreparedStatement ps = connection.prepareStatement(queryBuilder.toString(), ResultSet.TYPE_FORWARD_ONLY, ResultSet.CONCUR_READ_ONLY);
ps.setFetchSize(1000);
ps.setFetchDirection(ResultSet.FETCH_FORWARD);
ps.setObject(1, startTime);
ps.setObject(2, endTime);
ResultSet rs = ps.executeQuery();
log.info("plan2 consumed {}, {}", TimeUtils.humanizedFormat(System.currentTimeMillis(), start),
memoryMonitor.convertBytes(memoryMonitor.getUsedMemory() - startUsedMemory));
} catch (Exception ignore) {
}
}
运行结果如下图

综上可知,其实对于这种大数据量来说少量多次的查询远比多量少次的查询要好的多,至少对程序和数据库来说,都是上上只选。这应该也就是navicat会卡死、而dbeaver不仅不会卡死而且查得还很快的原因了吧!
三、参考致谢
How to calculate number of tiles in a bounding box for OpenStreetMaps | by Abhi | Medium
Tiles à la Google Maps: Coordinates, Tile Bounds and Projection | No code | MapTiler
Issuing a Query and Processing the Result | pgJDBC
PostgreSQL: Documentation: 7.4: Issuing a Query and Processing the Result















 1583
1583

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









