







 本文详细介绍了MapReduce在处理数据时的分区、分组和排序过程,特别是二次排序的概念。通过一个实际案例,展示了如何在Reducer端使用MapReduce实现数据的Join操作,从而满足特定业务需求。在分区过程中,根据IMEI进行分区;分组时,确保相同IMEI的数据分到同一组;通过自定义分组和分区比较器,实现了数据的正确处理和排序。
本文详细介绍了MapReduce在处理数据时的分区、分组和排序过程,特别是二次排序的概念。通过一个实际案例,展示了如何在Reducer端使用MapReduce实现数据的Join操作,从而满足特定业务需求。在分区过程中,根据IMEI进行分区;分组时,确保相同IMEI的数据分到同一组;通过自定义分组和分区比较器,实现了数据的正确处理和排序。
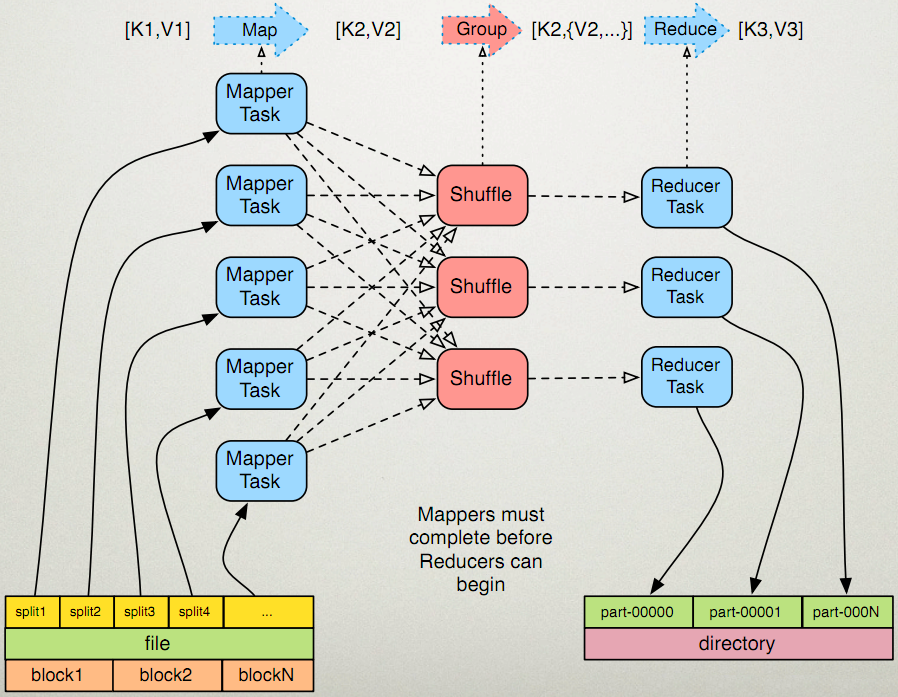
我们还是看下这个图,mapper处理后的中间数据经过shuffle阶段再由reducer处理。在shuffle阶段会进行分区,分组,排序,二次排序。这是个比较复杂的过程,但是我们理解以下这些东西对于工作中常见业务的开发就够用了:
- 分区 就是mapper数据处理完分成若干个partition交给reducer处理,也是利用多个reducer task并发处理来提高效率,但有些业务比如要求得出数据的全局排序结果,那没办法只能用由mapper产生1个partition交由一个reducer来处理。在代码中分区是怎么控制的呢?就像上文所说重写Partitioner类中的getPartition方法。
- 分组 我们知道reducer的reduce方法处理的数据结构式(key,Iterable)这个key-value值得value是个列表,就是map中key经过分组(group)后相同的key对应的值形成的列表,默认分组就是根据key的值来分组,hive中的分组操作:
select class,count(student) from tablename group by class最终就是翻译成了这里要说的分组,而tablename表中总的数据就可以理解成这个partition的数据。可以说分区是为了并发处理提高效率,分组则是为了服务业务的开发。 - 排序 mapreduce排序是对key值进行排序,默认按字典顺序排序,当然可以自定义排序。但有时候需要数据在reducer的reduce的要处理的数据(key,Iterable)这个value的列表Iterable进行排序,这就是二次排序。因为mapreduce只能对key进行排序,我们可以把value的值放到key里面来影响排序,具体下面的到例子来看。
具体应用
我在新浪处理微博数据的时候有个需求很简单:
两个数据来源:
- 全量的imei值,路径:/sinadata/all_imei/20161126
- 当天活跃的imei值,路径:/sinadata/active_imei/20161126
需要得到在全量imei中存在的当天活跃imei
如果用hive很简单:select a.imei from all_imei a join active_imei b where a.imei=b,imei就是一个join操作,下面说下用mapreduce(reducer端join)来实现:
两个数据来源需要对每个来源做个标记,所以key值不能单单是imei,需要是imei+标记,定义他们的封装类:
public class TextPair implements WritableComparable<TextPair>
{
private Text first;
private Text second;
public TextPair()
{
set(new Text(), new Text());
}
public TextPair(String first, String second)
{
this.set 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









