






Linux pid,tgid关系
USER VIEW
<-- PID 43 --> <----------------- PID 42 ----------------->
+---------+
| process |
_| pid=42 |_
_/ | tgid=42 | \_ (new thread) _
_ (fork) _/ +---------+ \
/ +---------+
+---------+ | process |
| process | | pid=44 |
| pid=43 | | tgid=42 |
| tgid=43 | +---------+
+---------+
<-- PID 43 --> <--------- PID 42 --------> <--- PID 44 --->
KERNEL VIEW
上图很好地描述了用户视角(user view)和内核视角(kernel view)看到线程的差别:
- 从用户视角出发,在pid 42中产生的tid 44线程,属于tgid(线程组leader的进程ID) 42。甚至用ps和top的默认参数,你都无法看到tid 44线程。
- 从内核视角出发,tid 42和tid 44是独立的调度单元,可以把他们视为"pid 42"和"pid 44"。(内核只有task的概念)
举个栗子,本地pid(1832)下的进程树,由pstree生成。{}表示线程。/proc/pid/task仅包含线程。
dockerd(1832)─┬─docker-proxy(26423)─┬─{docker-proxy}(26424)
tgid = 1832 │ tgid = 26423 ├─{docker-proxy}(26425)
│ ├─{docker-proxy}(26426)
│ ├─{docker-proxy}(26427)
│ ├─{docker-proxy}(26428)
│ tgid = 1832 ├─{docker-proxy}(26429)
│ task Dir ├─{docker-proxy}(26430)
|——│—————————————————| └─{docker-proxy}(9413)
│ ├─{dockerd}(1894) |
│ ├─{dockerd}(1896) |
│ ├─{dockerd}(1897) |
│ ├─{dockerd}(1898) |
│ ├─{dockerd}(1900) |
│ ├─{dockerd}(1907) |
│ ├─{dockerd}(1909) |
│ ├─{dockerd}(1942) |
│ ├─{dockerd}(1947) |
│ ├─{dockerd}(1948) |
│ ├─{dockerd}(1950) |
│ ├─{dockerd}(2142) |
│ └─{dockerd}(26431)|
|————————————————————|
进程优先级
PRI:进程优先权,代表这个进程可被执行的优先级,其值越小,优先级就越高,越早被执行;
NI:进程Nice值,代表这个进程的优先值;
PRI是比较好理解的,即进程的优先级,或者通俗点说就是程序被CPU执行的先后顺序,此值越小进程的优先级别越高。那NI呢?就是我们所要说的nice值了,其表示进程可被执行的优先级的修正数值。PRI值越小越快被执行,那么加入nice值后,将会使得PRI变为:PRI(new)=PRI(old)+nice。由此看出,规则是NICE越小,其进程优先级会变高,则其越快被执行。进程nice值和进程优先级不是一个概念,但是进程nice值会影响到进程的优先级变化。
源码结构解析
├── iotop
│ ├── data.py
│ ├── genetlink.py
│ ├── __init__.py(无内容,不涉及)
│ ├── ioprio.py
│ ├── netlink.py
│ ├── ui.py(用户交互部分,不涉及)
│ ├── version.py(无内容,不涉及)
│ └── vmstat.py
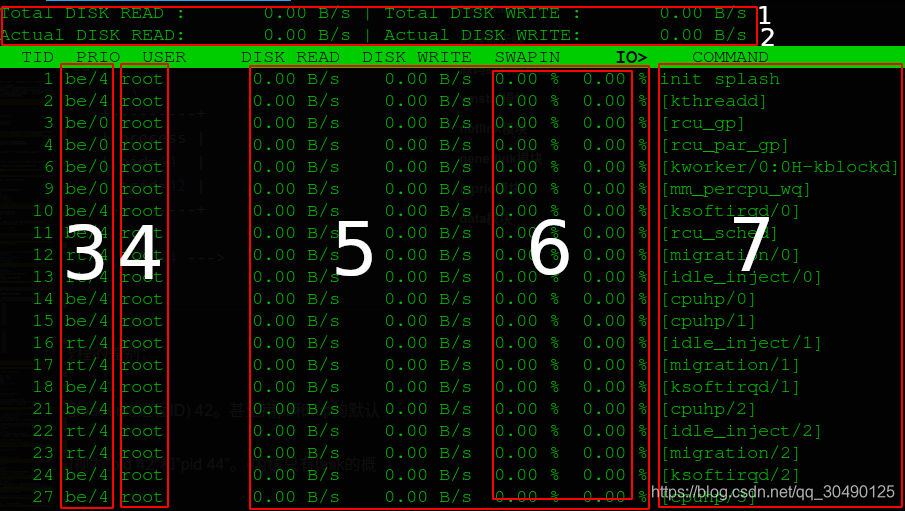
- 数据由taskstats获取,累加所有task得到。
- 数据由vmstat中读取。
- 由ioprio模块提供
- 由data模块,根据pid获取对应的uid
- 通过taskstats获取的task读写信息,其实读写信息通过procfs也能获取,但iodelay的获取过程已经附带了读写信息(个人向)
- 通过taskstats获取的iodelay,如果iodelay为一直0,这里显示为unaviable
- 通过cmdline信息或者status中的name信息提供
vmstat模块
模块中仅包含一个类VmStat,这个类主要负责跟/proc/vmstat文件的交互。
提供/proc/vmstat的信息
def read():
pgpgin 以KB表示系统从磁盘读入到内存的数据量大小
pgpgout 以KB表示系统从内存写出到磁盘的数据量大小
返回(pgpgin, pgpgout)
def delta():
返回新获取的(pgpgin, pgpgout) - 之前保存的(pgpgin, pgpgout)差值
netlink模块
netlink是一种介于在内核空间与用户空间之间进行数据传输的特殊的通信方式。它通过为为用户程序提供了一组标准的socket 接口,并为内核模块提供一组特殊的API的方式,实现了全双工的通讯连接。类似于TCP/IP使用AF_INET地址族,netlink socket使用另一种地址族AF_NETLINK。
模块中主要包含类Connection和类Message,为用户态和内核态的数据传输交互提供基础服务。
上层通过Message发送数据,基础服务返回一个Message给上层接口。
netlink 16字节的协议头
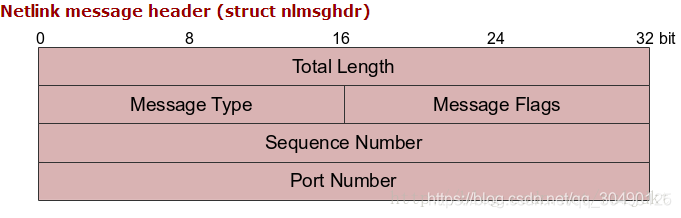
class Message:
用msg_type, flags, seq, contents 创建Message
self.type = msg_type
self.flags = flags
self.seq = seq
self.pid = -1
self.payload = 将contents处理成字符串的形式
def send(conn):
if self.seq == -1:
self.seq = conn.seq()
构造netlink协议头-header
conn.send(header + contents)
def __repr__():#定义Message的打印格式
return '<netlink.Message type=%d, pid=%d, seq=%d, flags=0x%x "%s">'
class Connection:
使用协议族AF_NETLINK建立socket连接
self.pid, self.groups = 解构socket
def send(msg):
通过socket发送msg
def receive():
msglen, msg_type, flags, seq, pid = 解析返回数据的前16个字节
初始化一个Message(msg_type, flags, seq, 16个字节以后的数据) + pid
return Message
def seq(self):#相当于发送信息的编号
self._seq += 1
return self._seq
genetlink模块
模块中主要包含类GeNlMessage和类Controller,用于获取一组特定的数据(协议族信息)。
class GeNlMessage(Message)#继承于Message
self.cmd = cmd
self.attrs = attrs
self.family = family
利用传入的family, flags, contents初始化一个Message,
注意seq信息会在Message得到更新
@staticmethod
def recv(conn)#静态函数,独立于对象存在
msg = connecttion.receive()
return 初始化的一个GelMessage
class Controller
接受一个外部传入的connection
def get_family_id(self, family):
构建获取family_id的命令:CTRL_CMD_GETFAMILY
初始化一个GeNlMessage
调用GeNlMessage父类Message的send函数
re = GeNlMessage.recv()
return re.attrs[CTRL_ATTR_FAMILY_ID]
ioprio模块
这部分比较粗暴,主要使用就是根据用户输入的pid显示这个task的任务优先级,也可用来设置任务优先级(不常用)。
模块中需要给出不同系统中系统调用号表的编号。
注意,这里面是没有aarch64的,CentOS提供的iotop rpm源码包中有相关patch
IOPRIO_GET_ARCH_SYSCALL = [
('alpha', '*', 443),
('arm*', '*', 315),
('i*86', '*', 290),
('ia64*', '*', 1275),
('parisc*', '*', 268),
('powerpc*', '*', 274),
('s390*', '*', 283),
('sparc*', '*', 218),
('sh*', '*', 289),
('x86_64*', '32bit', 290),
('x86_64*', '64bit', 252),
]
IOPRIO_SET_ARCH_SYSCALL = [
('alpha', '*', 442),
('arm*', '*', 314),
('i*86', '*', 289),
('ia64*', '*', 1274),
('parisc*', '*', 267),
('powerpc*', '*', 273),
('s390*', '*', 282),
('sparc*', '*', 196),
('sh*', '*', 288),
('x86_64*', '32bit', 289),
('x86_64*', '64bit', 251),
]
def get(pid):
return ioprio
def set(pid, ioprio):
data模块
向UI提供数据,这里对Stats需要一下说明:
swapin_delay_total: 从发生page fault开始,到完成swapin结束的耗时
blkio_delay_total: 从提交同步IO开始,到同步IO返回结束的耗时;blkio_delay_total相关代码如下。
path: linux/kernel/delayacct.c
int __delayacct_add_tsk(struct taskstats *d, struct task_struct *tsk)
{
...
tmp = d->blkio_delay_total + tsk->delays->blkio_delay;
d->blkio_delay_total = (tmp < d->blkio_delay_total) ? 0 : tmp;
...
return 0;
}
path: linux/kernel/core.c(blkio_delay的更新)
/*
* This task is about to go to sleep on IO. Increment rq->nr_iowait so
* that process accounting knows that this is a task in IO wait state.
*/
long __sched io_schedule_timeout(long timeout)
{
int old_iowait = current->in_iowait;
struct rq *rq;
long ret;
current->in_iowait = 1;
blk_schedule_flush_plug(current);
delayacct_blkio_start();
rq = raw_rq();
atomic_inc(&rq->nr_iowait);
ret = schedule_timeout(timeout);
current->in_iowait = old_iowait;
atomic_dec(&rq->nr_iowait);
delayacct_blkio_end();
return ret;
}
EXPORT_SYMBOL(io_schedule_timeout);
cancelled_write_bytes: 这里的数据由truncate引发,截短了cache中的文件,事实上就减少了原本要发生的写I/O
read_bytes: 进程读取的物理I/O字节数,包括mmap pagein,在submit_bio()中统计的
write_bytes: 进程写出的物理I/O字节数,包括mmap pageout,在submit_bio()中统计的
现在来看下Stats代码。
class Stats:
#Stats主要负责从内核中不断获取以下的5个值
members_offsets = [
('blkio_delay_total', 40),
('swapin_delay_total', 56),
('read_bytes', 248),
('write_bytes', 256),
('cancelled_write_bytes', 264)
]
#类变量,独立于实例外
has_blkio_delay_total = False
def __init__(self, task_stats_buffer):
#数据被写入到实例内置的字典中
sd = self.__dict__
for name, offset in Stats.members_offsets:
data = task_stats_buffer[offset:offset + 8]
sd[name] = struct.unpack('Q', data)[0]
# This is a heuristic to detect
# if CONFIG_TASK_DELAY_ACCT is enabled in
# the kernel.
#注意这里的只要有一次收到的blkio_delay_total非0
#has_blkio_delay_total就会被置为true
if not Stats.has_blkio_delay_total:
Stats.has_blkio_delay_total = self.blkio_delay_total != 0
def accumulate(self, other_stats, destination, coeff=1):
"""Update destination from operator(self, other_stats)"""
dd = destination.__dict__
sd = self.__dict__
od = other_stats.__dict__
for member, offset in Stats.members_offsets:
dd[member] = sd[member] + coeff * od[member]
def delta(self, other_stats, destination):
"""Update destination with self - other_stats"""
return self.accumulate(other_stats, destination, coeff=-1)
def is_all_zero():
#判断内置字典中的5个变量全部为0
@staticmethod
def build_all_zero():
#创建一个5个变量全0的Stat实例,并返回
class TaskStatsNetlink(object):
def __init__(self, options):
self.options = options
self.connection = Connection(NETLINK_GENERIC)
controller = Controller(self.connection)
self.family_id = controller.get_family_id('TASKSTATS')
#组装命令获取内核中taskstats的数据
def build_request(self, tid):
return GeNlMessage(self.family_id, cmd=TASKSTATS_CMD_GET,
attrs=[U32Attr(TASKSTATS_CMD_ATTR_PID, tid)],
flags=NLM_F_REQUEST)
def get_single_task_stats(self, thread):
#提交组装的命令
#根据获取某个tid对应的taskstats数据组装一个Stats,并返回
ThreadInfo类提供线程优先级和线程级Stats的delta
class ThreadInfo:
"""Stats for a single thread"""
def __init__(self, tid, taskstats_connection):
self.tid = tid
self.mark = True
self.stats_total = None
self.stats_delta = Stats.__new__(Stats)
self.task_stats_request = taskstats_connection.build_request(tid)
def get_ioprio():
#返回当前线程tid的任务优先级
def set_ioprio():
#设置当恰县城tid的任务优先级
#self.stats_delta保存新获取的stats - 老的stats(self.stats_total)
def update_stats(self, stats):
if not self.stats_total:
self.stats_total = stats
stats.delta(self.stats_total, self.stats_delta)
self.stats_total = stats
既然这个类被命名为ProessInfo,很容易猜到里面会包含类threads成员。
class ProcessInfo:
#Stats for a single process (a single line in the output):
#if options.processes is set, it is a collection of threads,
#otherwise a singlethread.
def __init__(self, pid):
self.pid = pid
self.uid = None
self.user = None
self.threads = {} # {tid: ThreadInfo}
#这里可以看到Process和Thread都有stats_delta
self.stats_delta = Stats.build_all_zero()
#这里的accum实际上就是delta的不断累计
self.stats_accum = Stats.build_all_zero()
self.stats_accum_timestamp = time.time()
def is_monitored(self, options):
#通过option的参数判断是后要显示当前进程
def get_uid:
#通过pid获取这个task的用户ID
def get_user:
#通过uid获取用户名
def get_cmdline:
#这个函数很明显,是为了获取进程的cmdline,
#注意内核线程是找不到cmdline的,转而会获取status中的name
def did_some_io(self, accumulated):
#如果delta为0或者accum为0 return false
def get_ioprio:
#获取所有孩子threads的ioprio,取set
#如果发现set的size大于1,表明ioprio异常
def set_ioprio:
#同thread的set_ioprio
def get_thread(self, tid, taskstats_connection):
#通过tid返回threadInfo,
#如果不存在这个thread,通过tid和taskstats_conn
#创建一个threadInfo
def update_stats:
#累计所有的threads的stats_delta到临时tmp_stats中,
tmp.blkio_delay_total /= nr_threads
tmp.swapin_delay_total /= nr_threads
self.stats_delta = tmp
#累计stats_delta到stats_accum中
这个类很明显是为了维护process列表
class ProcessList:
def __init__(self, taskstats_connection, options):
# {pid: ProcessInfo}
self.processes = {}
self.taskstats_connection = taskstats_connection
self.options = options
self.timestamp = time.time()
self.vmstat = vmstat.VmStat()
# A first time as we are interested in the delta
self.update_process_counts()
def get_process(self, pid):
#根据pid从processes中获取processInfo
#如果不存在这个processInfo,通过pid创建一个
if process.is_monitored(self.options):
return process
def list_tgids:
#如果option中已经指定了pids,直接返回pids
#如果oprion中指定process,返回/proc下的所有pid
#如果option中未指定process,返回所有的task中的pid
def list_tids(tgids):
#如果option中已经指定了process,直接返回pids
#tids = 获取指定tgids下的task列表
#如果option中指定了pids,合并tids和pids
def update_process_counts:
#保存该函数调用的时间
new_timestamp = time.time()
self.duration = new_timestamp - self.timestamp
self.timestamp = new_timestamp
foreach 进程列表:
foreach 线程列表:
获取thread对应的stats
thread.update_stats(stats)
delta = thread.stats_delta
total_read += delta.read_bytes
total_write += delta.write_bytes
thread.mark = False
return (total_read, total_write), self.vmstat.delta()
def refresh_processes:
foreach 进程列表:
foreach 线程列表:
thread.mark = True
return total_read_and_write = self.update_process_counts()

















 815
815

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









