










目录
3. AOP 底层原理是如何实现的?(Spring 角度? JDK动态代理?CGLIB 动态代理?)
4. 两个动态代理的区别?两个代理的性能和扩展性哪个好? 为什么?为什么这么判断
8. AOP什么时候用JDK动态代理,什么时候用cglib动态代理
17. hashMap 和 courrentHashmap 的底层实现
本篇文章纯手打
1. 讲一下反射
反射是 Java 的核心机制
运行程序在运行时动态的分析操作类,方法,字段等元信息
首先是获取 Class 类
每个引用数据类型都可以通过 Class 类提取出来
常见的方法有三种
第一种直接通过.class
第二种是 Object 超类里面的 getObject 方法
第三种是 Class.forName()方法 通过全类名获取
我们通过 class 类
接着是而来的是三个类
构造方法类 Constructer 动态创建对象 类似于破坏 spring 中的单例模式
方法类 Method 类 可以动态调用类中的方法
字段类 Fiele 类 可以动态修改字段成员变量 的数值 如设置方法属性
用途
Spring 用反射实现依赖注入和动态代理
单元测试用反射可以访问字段和方法
缺点
反射很慢! 慢个几十倍
容易回调地狱
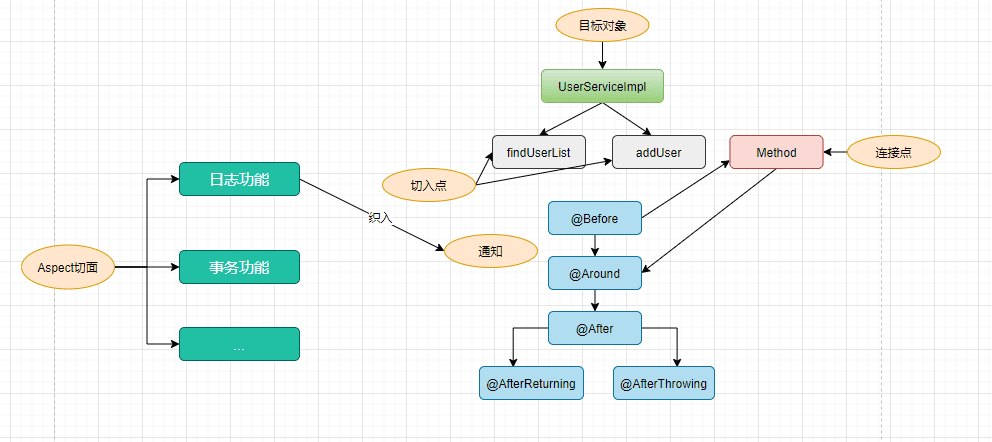
2. 介绍一下 AOP,讲一下 AOP使用的流程?
AOP 是面向切面编程
规定的是一套规范 指的是用预编译和运行期间动态代理的方式实现程序的统一维护
在 Java 中我将这个概念理解成将分散在各个业务逻辑代码中相同的代码通过横向切割的方式抽取到一个公共的模块中
AOP 中有一些术语
首先是连接点 代表的程序哪些部分要去做 AOP 处理 可能是字段处理 字段调用 类初始化 异常
连接点集合到一起是切入点 表示 AOP 在哪里进行操作 Spring 中使用的 AspectJ 就是如此实现
接下来是通知 这个概念就是我们在切入点的具体操作 比如说前置通知 后置通知 环绕通知
连接点 切入点 通知在一起组成一个切面
然后是目标对象 这是一个代理对象
最后织入 将切入点放到目标对象上进行操作
AOP 配置原始方法是通过 XML 的方式
我们需要声明一个切面类 在切面类里面定义方法 这些方法就是通知
在 XML 里引用配置即可
另外就是 AspectJ 注解提供的一系列注解 用于解决 XML 繁琐问题
包括@ AspectJ 定义切面 @ Before 注解 定义通知等
具体实现
首先切面类先打上 @ Component (声明给 spring 管理的 bean) @ AspectJ (定义切面类)
@ Pointcut 注解 定义的是切入点的表达式
我们用类名 找到要切入的地方
之后用一系列通知相关的注解就行 @ Before @ Around @ After 注解
这边要提到 JoinPoint 类 这个对象在通知的时候是作为方法参数传入的
是可以看做 AOP 中 动态代理的 一系列 衍生物
在 AspectJ 中通过 JoinPoint 可以获取到所有的 目标方法 目标对象 方法参数以及运行时期的上下文信息
下面是我手写的一个示例
import org.aspectj.lang.*;
import org.aspectj.lang.annotation.*;
import org.springframework.stereotype.Component;
import java.util.Arrays;
@Component
@Aspect
public class LogAspect {
@Pointcut("execution(public int com.dc.esb.CalculatorImpl.*(..))")
public void pointCut() {
}
@Before("pointCut()")
public void beforeMethod(JoinPoint joinPoint) {
String methodName = joinPoint.getSignature().getName();
String args = Arrays.toString(joinPoint.getArgs());
System.out.println("Logger-->前置通知,方法名:" + methodName + ",参数:" + args);
}
@After("execution(public int com.dc.esb.CalculatorImpl.*(..))")
public void afterMethod(JoinPoint joinPoint) {
String methodName = joinPoint.getSignature().getName();
System.out.println("Logger-->后置通知,方法名:" + methodName);
}
@AfterReturning(value = "execution(public int com.dc.esb.CalculatorImpl.*(..))", returning = "result")
public void afterReturningMethod(JoinPoint joinPoint, Object result) {
String methodName = joinPoint.getSignature().getName();
System.out.println("Logger-->返回通知,方法名:" + methodName + ",结果:" + result);
}
@AfterThrowing(value = "execution(public int com.dc.esb.CalculatorImpl.*(..))", throwing = "ex")
public void afterThrowingMethod(JoinPoint joinPoint, Throwable ex) {
String methodName = joinPoint.getSignature().getName();
System.out.println("Logger-->异常通知,方法名:" + methodName + ",异常:" + ex);
}
@Around("execution(public int com.dc.esb.CalculatorImpl.*(..))")
public Object aroundMethod(ProceedingJoinPoint joinPoint) {
String methodName = joinPoint.getSignature().getName();
String args = Arrays.toString(joinPoint.getArgs());
Object result = null;
try {
System.out.println("环绕通知-->目标对象方法执行之前");
//目标对象(连接点)方法的执行
result = joinPoint.proceed();
System.out.println("环绕通知-->目标对象方法返回值之后");
} catch (Throwable throwable) {
throwable.printStackTrace();
System.out.println("环绕通知-->目标对象方法出现异常时");
} finally {
System.out.println("环绕通知-->目标对象方法执行完毕");
}
return result;
}
}3. AOP 底层原理是如何实现的?(Spring 角度? JDK动态代理?CGLIB 动态代理?)
SpringAOP 的核心实现依赖于 BeanPostProcessor 接口
BeanPostProcessor 是 Spring 容器的拓展点
是在 Bean 生命周期实现中 在 bean 配置属性 + 实现 aware 接口后进行的
BeanPostProcessor 先调用前置方法
然后初始化属性后
BeanPostProcessor 调用后置方法
允许在 Bean 初始化 前后插入自定义的逻辑
SpringAOP 通过实现这个接口 在 Bean 初始化后创建代理对象
Spring 在启动时 通过三步实现 AOP 动态代理
首先 注册自动代理创建起 在启用 AOP(如通过@EnableAspectJAutoProxy注解)时,Spring 会自动注册AnnotationAwareAspectJAutoProxyCreator。
其次 扫描所有切面和增强逻辑(注解) Spring 会扫描所有 Bean,识别带有@Aspect注解的切面类,并解析其中的@Before、@After等增强注解。
最后在 Bean 初始化后完成代理 初始化后调用BeanPostProcessor 的后置方法
示例代码
public class AnnotationAwareAspectJAutoProxyCreator
extends AbstractAutoProxyCreator {
@Override
protected Object wrapIfNecessary(Object bean, String beanName, Object cacheKey) {
// 1. 检查当前Bean是否是切面类
if (isInfrastructureClass(bean.getClass()) || shouldSkip(bean.getClass(), beanName)) {
return bean;
}
// 2. 获取匹配的增强器(Advice)
Object[] specificInterceptors = getAdvicesAndAdvisorsForBean(bean.getClass(), beanName, null);
// 3. 如果有增强器,创建代理
if (specificInterceptors != DO_NOT_PROXY) {
this.advisedBeans.put(cacheKey, Boolean.TRUE);
// 创建代理对象(JDK或CGLIB)
Object proxy = createProxy(
bean.getClass(), beanName, specificInterceptors, new SingletonTargetSource(bean));
this.proxyTypes.put(cacheKey, proxy.getClass());
return proxy;
}
this.advisedBeans.put(cacheKey, Boolean.FALSE);
return bean;
}
}4. 两个动态代理的区别?两个代理的性能和扩展性哪个好? 为什么?为什么这么判断
JDK 动态代理基于接口 面向接口
Spring通过Java的反射机制生产被代理接口的新的匿名实现类,重写了其中AOP的增强方法。
CGLib动态代理是通过字节码底层继承要代理类来实现(如果被代理类被final关键字所修饰,那么抱歉会失败)。
这个问题我查过资料 包括书上和博客园都有小结:
- CGLib 动态代理所创建的动态代理对象在实际运行时候的性能要比JDK动态代理高不少,有研究表明,大概要高10倍;
- 但是CGLib动态代理在创建对象的时候所花费的时间却比JDK动态代理要多很多,有研究表明,大概有8倍的差距;
- 因此,对于singleton的代理对象或者具有实例池的代理,因为无需频繁的创建代理对象,所以比较适合采用CGLib动态代理,反正,则比较适用JDK动态代理。
需要注意的是 在 Java1.6和 Java1.7的时候,JDK动态代理的速度要比CGLib动态代理的速度要慢,但是并没有教科书上的10倍差距,在JDK1.8的时候,JDK动态代理的速度已经比CGLib动态代理的速度快很多了。
因此可能的答案是 CGLib 动态代理适合代理单个对象 JDK 动态代理适合方法高频使用的场景
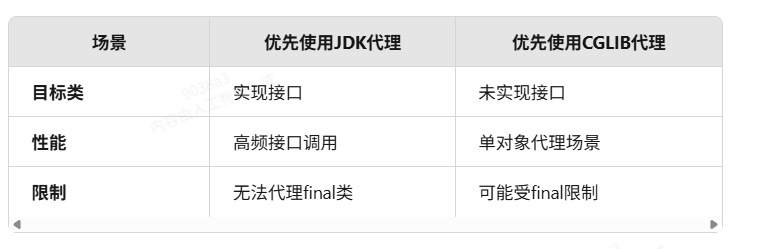
我们其实可以看这两种代理的优化 未来发展
就像 SpringAOP 存在默认行为一样
Spring3 +的版本会自动判断被代理的类是否实现接口 如果实现了接口就使用 JDK 动态代理 否则 则使用 CGLIB 动态代理
但是 Springboot2 默认策略却是 CGLIB 动态代理
之后我又思考了一下
JDK 动态代理 通过实现InvocationHandler接口创建自己的调用处理器 适用于创建对象频繁的情况。
CGLIB 动态代理创建代理对象更加耗时。
创建代理对象频率低的情况:对于单例(singleton)的代理对象或者具有实例池的代理,因为不用频繁地创建代理对象,CGLIB创建的动态代理对象性能比JDK动态代理高,所以比较适合用CGLIB动态代理技术3。
创建代理对象频率高的情况:如果需要频繁创建代理对象,由于CGLIB创建代理对象所耗费的时间比JDK动态代理多,此时适合采用JDK动态代理技术。
印证了我的想法
(参考文章:Spring AOP中JDK和CGLib动态代理哪个更快? - 问题大白 - 博客园)
5. 如何实现Bean的生命周期?详细讲讲
整体上分为四步操作
实例化 -> 属性赋值 -> 初始化 -> 销毁
详细的话 10 步
首先是 AbstractAutowireCapableBeanFactory 类
1、调用构造方法实例化Bean对象
2、设置Bean属性(调用Bean的set方法)配置属性
3、如果Bean实现各种Aware接口,则会注入Bean对容器基础设施层面的依赖。Aware接口具体包括BeanNameAware、BeanFactoryAware、ApplicationContextAware,分别注入Bean ID、Bean Factory或者ApplicationContext
4、如果定义了一个类实现了BeanPostProcessor,调用重写BeanPostProcessor的前置初始化方法postProcessBeforeInitialization( )
如果我们希望容器中创建的每一个bean,在创建的过程中可以执行一些自定义的逻辑,那么我们就可以编写一个类,并让他实现BeanPostProcessor接口,然后将这个类注册到一个容器中。容器在创建bean的过程中,会优先创建实现了BeanPostProcessor接口的bean,然后,在创建其他bean的时候,会将创建的每一个bean作为参数,调用BeanPostProcessor的方法。而BeanPostProcessor接口的方法,即是由我们自己实现的。下面就来具体介绍一下BeanPostProcessor的使用。
5、如果Bean实现InitializingBean接口,则会调用afterPropertiesSet方法
6、调用Bean自身的init方法(配置init-method)初始化
7、如果定义了一个类实现了BeanPostProcessor,调用重写BeanPostProcessor的后置方法postProcessAfterInitialization( )
8、使用Bean
9、如果Bean实现DisposableBean,则会调用destroy()方法 ,销毁
10、调用Bean自身的destroy方法(配置destroy-method)
6. 循环依赖如何解决?
@ Lazy 注解 延迟启动... 可以解决
参考 Spring 三级缓存
一级缓存 单例 bean 对象 初始化并且实例化 进行了自动配置
二级缓存 初始化但是没有进行自动配置的 bean
三级缓存单例 bean 工厂
通过反射创建 bean
往下找到后再往上抛 注意会有一个移除的过程

7. 为什么用三级缓存,不可以用二级缓存吗?
二级缓存完全能解决循环依赖的问题
三级缓存是为了解决其他问题 比如说 AOP
如果早期暴露的 Bean 直接放入二级缓存,那么在循环依赖发生时,Bean 的代理对象必须提前创建(即使没有循环依赖也会创建)。这会破坏 Spring 的设计原则:代理对象应该在需要时才创建(例如,当 Bean 被 AOP 增强时)。
二级缓存方案会将早期暴露和代理创建两个独立的功能强制绑定在一起,导致代码可维护性降低。
- A 的创建过程:
-
- A 实例化后,将
ObjectFactory(用于生成 A 或 A 的代理)放入三级缓存。 - A 开始属性注入,发现需要 B。
- A 实例化后,将
- B 的创建过程:
-
- B 实例化后,将
ObjectFactory放入三级缓存。 - B 注入 A 时,从三级缓存获取 A 的
ObjectFactory,生成早期 A(可能是代理),放入二级缓存。 - B 完成初始化,放入一级缓存。
- B 实例化后,将
- A 继续创建:
-
- A 从一级缓存获取 B,完成属性注入和初始化,最终放入一级缓存。
假设使用二级缓存(直接存储早期暴露的 Bean):
- 场景 1:无循环依赖但有 AOP
Bean 会在实例化后立即创建代理对象(即使没有循环依赖),这违背了 Spring 的延迟代理原则。 - 场景 2:有循环依赖且有 AOP
多个循环依赖可能导致多次创建代理对象,破坏单例性。
8. AOP什么时候用JDK动态代理,什么时候用cglib动态代理
当被代理的目标对象实现了至少一个接口时,Spring AOP默认会使用JDK动态代理。JDK动态代理基于接口生成代理类,通过反射机制调用目标对象的方法。
JDK 动态代理是通过实现 InvocationHandler 接口创建了自己的调用处理器
目标对象未实现接口:当被代理的目标对象没有实现任何接口时,Spring AOP会选择使用CGLIB动态代理。CGLIB动态代理通过继承目标对象创建代理类,并重写目标对象的方法来实现代理功能1。
Spring3 +的版本会自动判断被代理的类是否实现接口 如果实现了接口就使用 JDK 动态代理 否则 则使用 CGLIB 动态代理
但是 Springboot2 默认策略却是 CGLIB 动态代理
对 final 关键字修饰的类和方法 只能使用 JDK 动态代理
同样的 被 static 修饰的方法同理
9. 讲讲索引的原理
索引是一种高效的数据结构
类似于将数据进行目录化的存储 类似于书籍的目录
索引的数据结构 有 hash 二叉搜索树 b 树 b+树等
10. 索引失效的场景
首先想一下 索引存储的是列的具体值
那么对索引进行运算的 或者是模糊值都会失效
比如说对字段进行运算查询
比如对字段进行模糊查询
比如说对字段进行类型转化查询
比如对字段进行或者查询where 字段 1 or 字段 2 字段 2 没有索引的话索引会失效
其次是联合索引的情况
不满足最左前缀匹配原则
联合索引是查询时仅使用索引的前缀部分
从左往右匹配 遇到 > ,< 会停止
11. 什么时候需要建立索引?为什么要建立索引?
多查询的字段建议要建立索引
用来的排序的字段建议要建立索引
多考虑建立联合索引
避免索引失效的情况
索引字段不能为 nul
12. 有一个骑手表,订单表,商户表,你该怎么设计索引?
( 不愧是全国最大的外卖平台)
Deepseek 的解释
- 订单表索引设计(核心优化对象)
- WHERE高频字段:user_id(用户查历史订单)、merchant_id(商户查订单)、rider_id(骑手查订单)、status(状态筛选)
- 组合索引:(merchant_id, status, create_time) 商户看不同状态订单的时效性
- 时间索引:create_time(时间范围查询)或 (status, create_time) 处理时效性订单
- 主键:order_id(自增主键,自动聚集索引)
- 覆盖索引:对报表查询建立(status, payment_time) INCLUDE(total_amount)
- 骑手表索引设计
- 地理位置索引:使用GEOHASH或PostGIS的GIST索引(如果需范围查询)
- 状态索引:is_online + last_active_time(筛选在线骑手)(我感觉不需要 查询全表数据超过 50% 不如不加索引)
- 组合索引:(current_area_code, load_status) 区域调度查询
- 唯一索引:phone_number(登录校验)
- 商户表索引设计
- 地理位置索引:GEO索引(附近商户推荐)
- 分类索引:category_id + average_rating(分类筛选)
- 组合索引:(city_id, is_open) 城市运营状态查询
- 前缀索引:对merchant_name字段前20字符建索引
13. 缓存穿透
缓存穿透是指 数据既不在缓存 也不在数据库
通常造成的原因是误删数据库 或者是 黑客进行访问不存在的数据
大量高并发请求会立刻到达 redis 导致数据库崩溃
对此我们可以限制访问
请求参数是否合理 是否包含非法数值 空值等
接着我们可以设置在缓存里提前设置数据的默认值
这样请求就不会在第一次就全到达数据库
另外 就是布隆过滤器
用布隆过滤器可以快速查看数据库是否存在数据
14. 缓存雪崩 与 缓存击穿
缓存雪崩是指大量缓存数据同时过期
如果数据大规模过期 用户请求就会全去 mysql mysql 承受不了就会宕机 进而导致整个系统崩溃
所以我们通常会给 redis 里面的数据随机化过期时间 当缓存数据过期后 用户请求数据 数据不在缓存里 就会重新生成缓存 后续的请求就能直接访问缓存
redis 故障也会导致缓存雪崩
对此我们可以设置 redis 集群
或者限流访问 redis 故障直接返回 error 但这样会让业务无法工作
更高级的做法是互斥锁的写法
当多线程去缓存里面拿数据 我们只让一个线程去数据库拿数据返回后更新缓存 我们通过只让一个线程去构建缓存的方式 防止大量请求到达 mysql 重构缓存后 释放锁 其他线程拿到缓存里的数据
同样我们也可以在业务上线前进行缓存预热 提前准备好缓存 防止项目已上线就宕机
我再想想
我们可以 异步处理 在设置定时任务 定期更新缓存 或者是缓存过期了通知发到消息队列 通知后台缓存更新缓存
我一直把缓存击穿看做是缓存雪崩的子集
15. 缓存击穿
缓存击穿是缓存雪崩的一种
可以采取相同的方法
也可以让缓存数据永不过期
数据库中的数据更新了的话 用消息队列异步通知缓存进行更新
16. 讲讲数据库和缓存的数据一致性
首先缓存与数据库的一致性
是指的在高并发情况下 用户在读操作写操作并发的情况下 会读到脏数据的情况
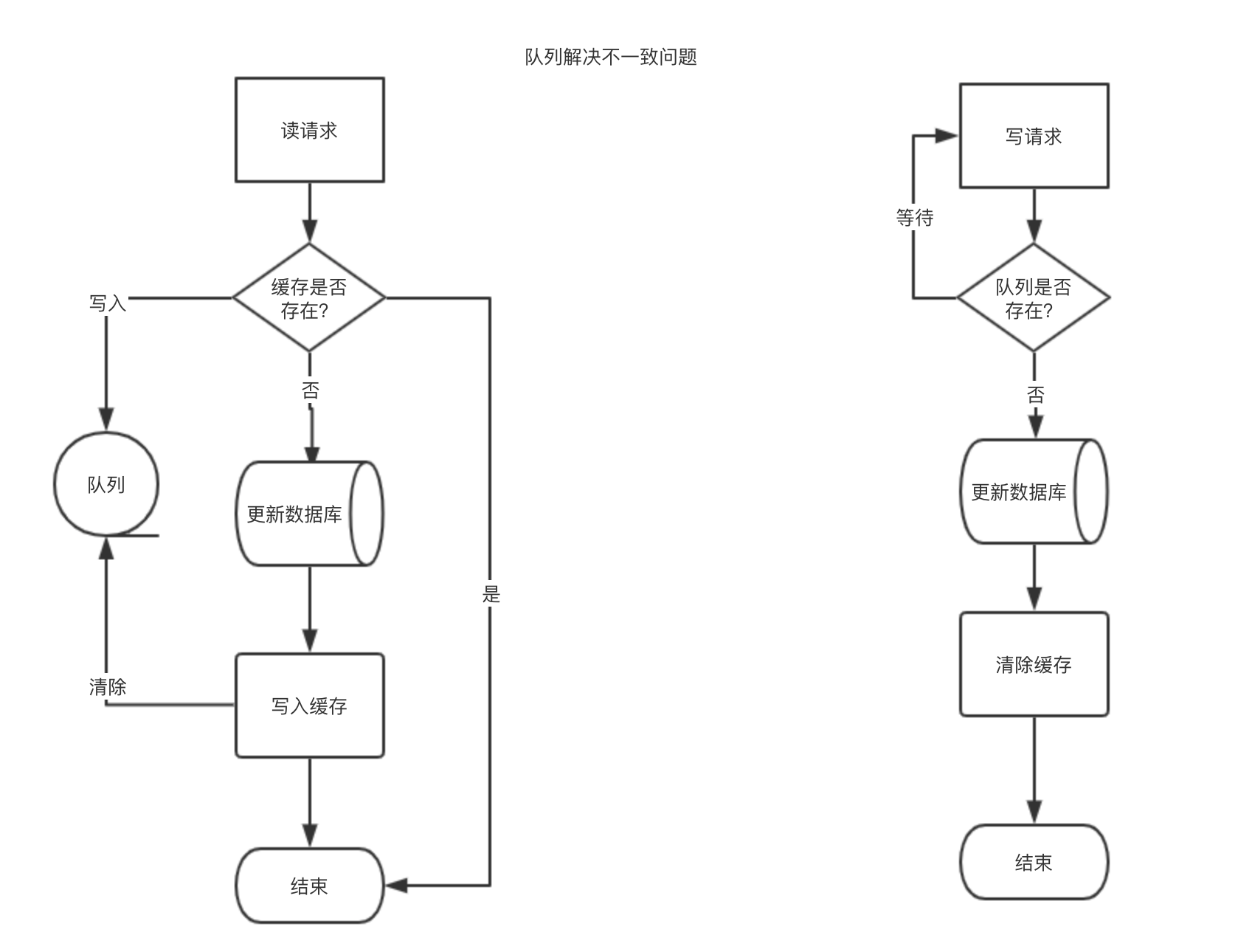
数据库跟缓存更新有两种大体上的逻辑方案
第一种写线程是先删除缓存 再更新数据库
在写线程更新数据完毕前 读线程进来了读取到了脏数据 并且更新了缓存
这样 缓存里是旧数据 数据库里是新数据
应为读线程读取数据 会先到缓存里面去读
那么在这之后都是读取到的脏数据
这种情况比较容易发生 因为数据库更新的时间实际上是比较长的
我们常见的解决方案是采用延迟双删的方式
在更新数据库后 再进行一次缓存的删除 这个是延迟删除 500 毫秒左右
即在数据库更新的前后 都进行一次缓存的删除操作
第二种是先更新数据库 再删除缓存
写线程先更新数据库 再去删除缓存
但是如果读线程在读取到脏数据后宕机了 在写线程更新完毕后 再去写入缓存 还是会出现缓存里放旧数据 数据库里放新数据的情况
但是这种情况不常见 因为读线程的速度理论上比写线程快的多 所以我们会采取先更新数据库 再删除缓存
读线程前一段时间读取到脏数据 后一段时间读取 缓存里没有数据
看起来可以 但是如果写线程删除缓存失败了
就有问题了
我们可以删除重试模式
或者我们可以用异步请求的方式,MQ消息队列,Canal 等去解决这种问题...
17. hashMap 和 courrentHashmap 的底层实现
首先是初始化哈希表 默认容量是 16
负载因子是 0,75 也就是说当哈希表里面的 key 达到容量的 0.75 时 哈希表容量就会扩充到原来的两倍
哈希表的键(key) 是唯一的
通过哈希算法算出一个=地址 这个叫哈希槽 槽再去映射节点
这个地址用来放数值(value)
如果算出的地址 重复 叫做哈希冲突 这时候哈希桶内部就要做一些处理
Java 做了处理 链路寻址法
当链表长度大于 8 的时候 链表树化 查询时间复杂度从 On 到 Ologn
再当红黑树的节点小于 6 的时候 树又会退化成链表
这个 8 和 6 是有科学依据的
8 是更具泊松算法算出来的最优解
6 是为了防止反复树化链表化
courrentHashmap 是线程安全的哈希表
处理了哈希表并发操作下的线程不安全问题
线程不安全就是多线程并发数据处理造成数据不一致的问题
courrentHashmap写操作
jdk8 之前是用的分段锁 区分于 hashtable 的整锁 粒度更加细
如果 hashmap 的 key 是 100 个 分段锁类似于分成 20 个 50 个 hashmap 加锁
jdk1.8 后 使用的是 CAS+槽位锁
CAS 是一种 dowhile()形式的无锁并发控制
主要 包含 内存位置 , 预期值 A , 新值 B
只要用的 java 原子数据类型类的 compareAndSet()方法
在 do{}语句体里面获取数值 然后进行操作
在 while()的函数表达式里面写compareAndSet
第一个参数是获取到的数值是不是预期值 第二个参数是理想值
通过不断获取原先值自旋比较 但是会存在 ABA 问题
courrentHashmap 读操作
jdk8 之前是分段锁+volitile 关键字
jdk1.8 之后是槽锁 粒度超级细




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











