









今日,因为公司有一个大型的分布式项目,用到不少中间件,还有讨厌的k8s,节点及服务器很多,日志的统一处理与查询成为了一个难点,于是让我设计个日志架构,那肯定优选ElasticStack也就是经典的 ELFK(Elasticsearch+Logstash+Filebeat+Kibana) 。由于当初已经指定了ES版本,用的是7.12.1,所以其他的也都统一了版本。
文档资料
具体的下载地址如下,大家可以选择要下载的产品及版本号:
https://www.elastic.co/cn/downloads/past-releasesw
我所使用的:
Elasticsearch:Elasticsearch 7.12.1 | Elastic
Logstash:Logstash 7.12.1 | Elastic
Filebeat:Filebeat 7.12.1 | Elastic
Kibana:Kibana 7.12.1 | Elastic
ELK这种全套的日志处理技术也不是什么新技术了,最早期的就是单纯的ELK三个框架技术,到后面逐渐演变成ELFK等等,架构也逐渐复杂一些,但无非都是加一些缓存队列做一些更优化的处理效果。
下面是我自己绘制的一套真实生产环境的架构图
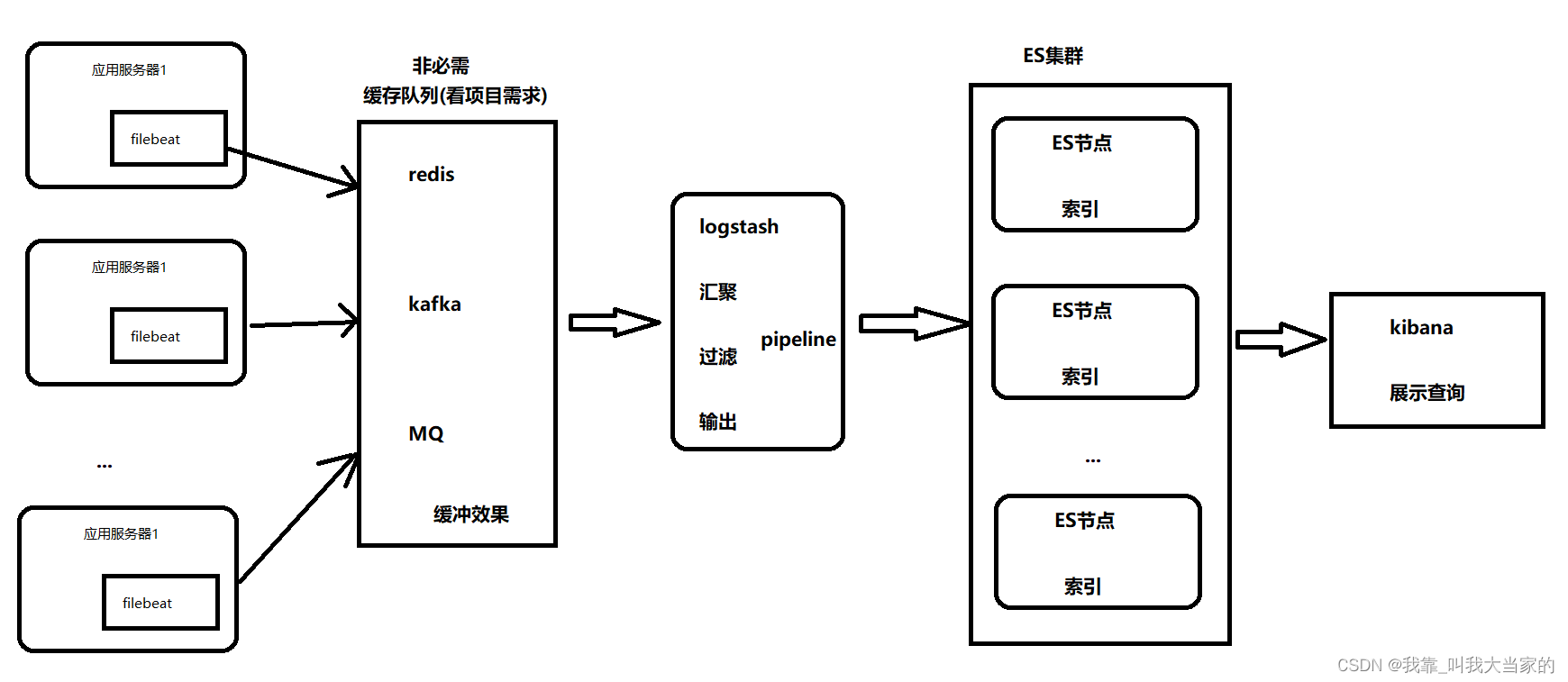
filebeat是依据logstash设计出来的,功能配置类似,虽然没有logstash强大,但是非常小巧,运行速度快,适合用于采集。如果应用服务器以及要采集的服务器比较多,此时如果直接输出到logstash,自然压力大,可以用一些MQ等一些消息队列缓冲一下再输出给logstash,经过logstash的过滤处理等再输出给ES集群,最后使用kibana来查看展示,这就是整个过程,好了,下面开始搞!
一、ES单点部署
1. 解压缩
我是直接下载的压缩版本的es,直接解压缩即可
tar -zxvf elasticsearch-7.12.1-linux-x86_64.tar.gz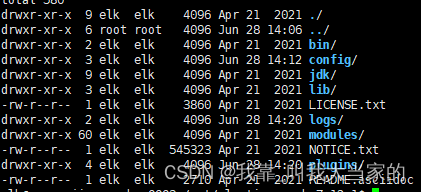
可以看到里面有几个比较重要的目录:bin下面是es的可执行程序命令,config里存放的是配置文件。细心的话可以发现es自带了jdk。
2. 修改配置文件
先来到config目录,使用vim打开elasticsearch.yml,进行配置修改
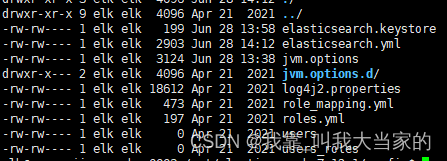
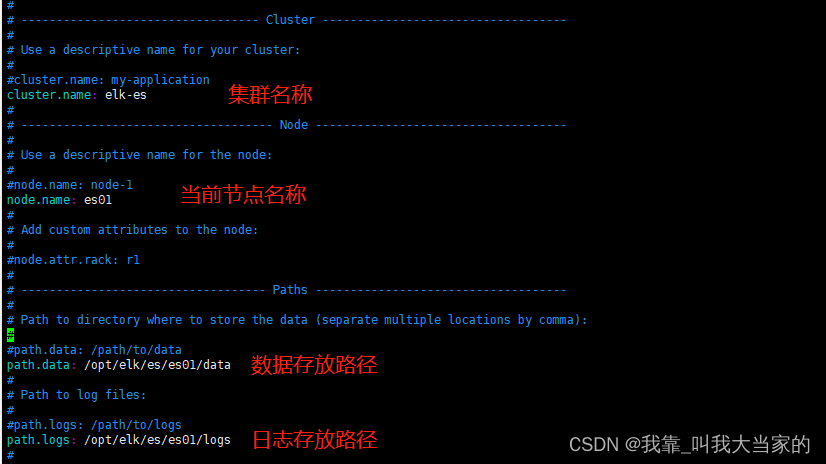
当前节点对外暴露的网络地址,可设置为0.0.0.
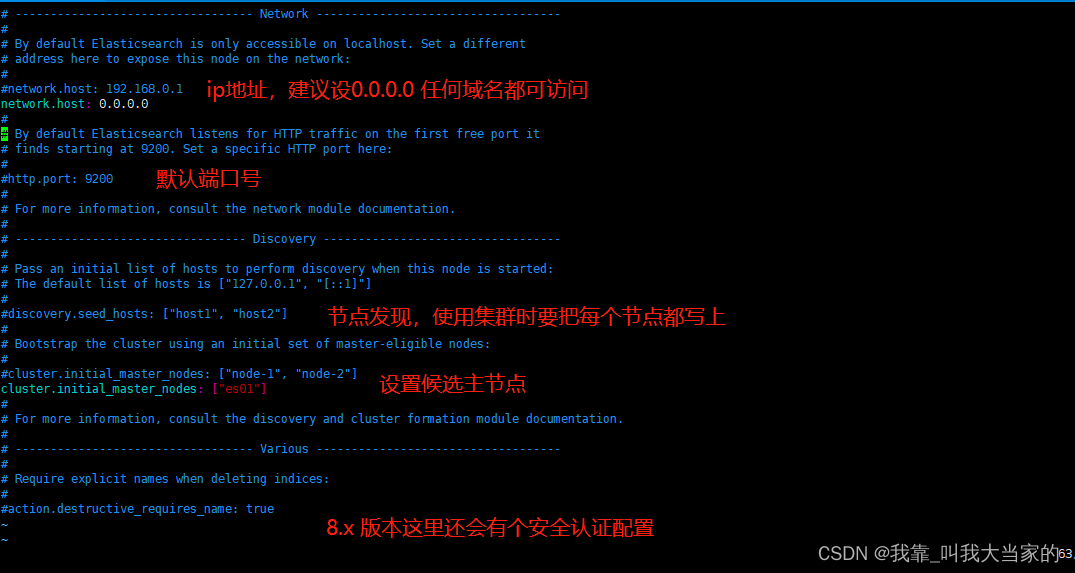
配置完毕后,就后台运行起来
3. 创建使用用户
还有注意一点,elasticsearch是不能用root来启动的,还需要配置一个用户来启动,我这里配置的是es,然后把那个文件目录的权限给足它
adduser es
passwd es
chown -R es:es elasticsearch-7.12.1/4. 开始启动
nohup ./elasticsearch/bin/elasticsearch &如果你想重定向到日志文件,可以这样做
nohup ./elasticsearch/elasticsearch/bin/elasticsearch > /opt/elk/es/es01/elasticsearch.log 2>&1 &5. 测试运行
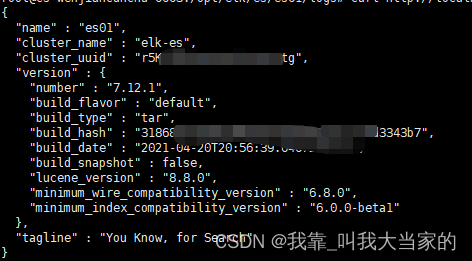
运行起来后,如果想看自己运行有没有问题,有没有成功,也可以使用如下命令查看
curl http://localhost:9200看到如下图所示,就代表成功了
二、kibana的部署运行
1. 解压缩
tar -zxvf kibana-7.12.1-linux-x86_64.tar.gz2. 修改配置
kibana的配置修改就简单的多了,在config目录下,有个kibana.yml,使用vim打开即可
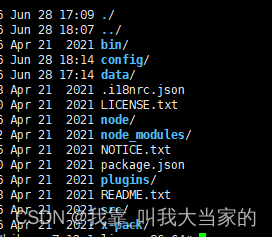

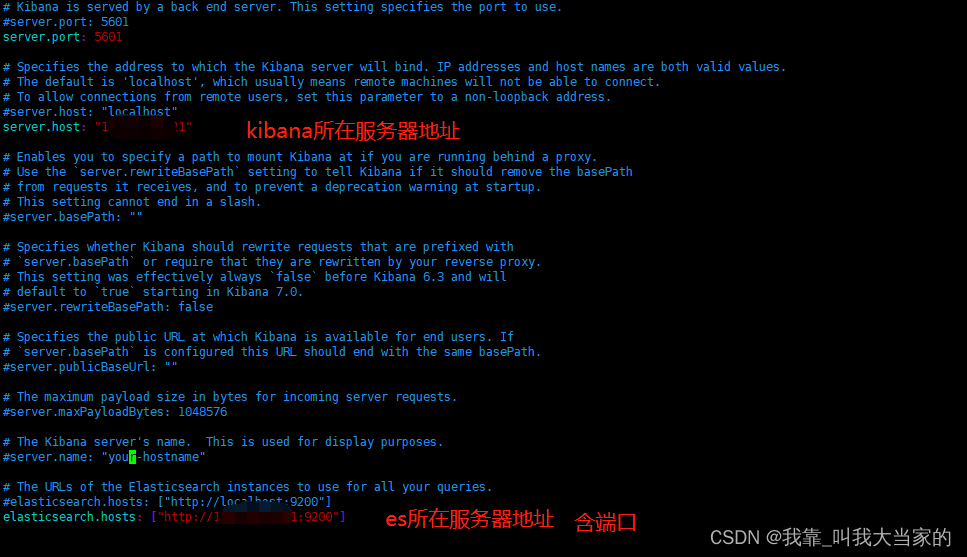
最底下还有个中英文的配置,母亲还是很强大的哈哈

3. 后台运行
nohup ./kibana &这里的nohup命令可以防止在你退出终端后进程被终止,&符号将进程放到后台运行。如果你希望将输出重定向到文件,可以这样做:
nohup ./kibana > /path/to/kibana.log 2>&1 &4. 开始访问
这里我把我得kibana所在的服务器端口暴露出来了,所以在我得电脑上就可以直接输入
http://xxxxxxx:5601 就可以访问了
三、filebeat的部署运行
官方使用文档说明:Filebeat Reference [7.12] | Elastic
1. 解压缩
tar -zxvf filebeat-7.12.1-linux-x86_64.tar.gz解压后就是这样的一个层级目录,可以看到filebeat.yml配置文件,但是vim打开后,你会发现非常多,还有些不知道什么意思。所以我打算自己重写个yml配置,把之前的文件改下名字即可。
2. 修改配置文件或创建自己的配置文件
因为自带的配置文件属性设置太多,比较麻烦,我是自己创建了个简单的配置文件
//把之前的filebeat.yml配置文件改成filebeat.yml-test
mv filebeat.yml filebeat.yml-test//自己新建个filebeat.yml
vim filebeat.yml先把输入输出都变成控制台的输入输出,这样方便测试下是否没有问题,然后wq保存退出
#指定filebeat的输入配置
filebeat.inputs:
#指定输入的类型
- type: stdin
#指定filebeat的输出配置
output.console:
#打印漂亮的格式
pretty: true
3. 启动运行
启动就可以实现在控制台输入,在控制台查看了
//前台启动filebeat
./filebeat -e -c filebeat.yml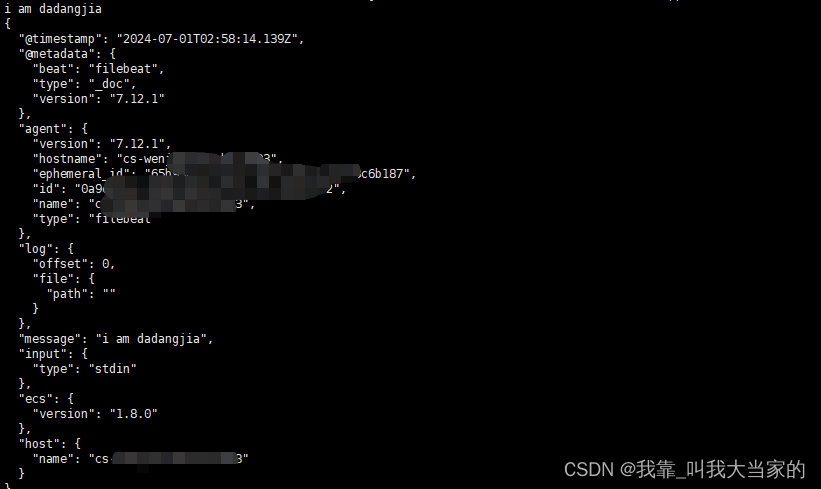
4. 采集读取原理
其次在运行日志里注意这么一段话

来到这个位置可以看到这么两个文件

其中meta.json里面存的是版本号,而log.json里面是存储的每次读取的记录数据,其中offset是记录每次读取的位置,是为了标记filebeat下次读取变化的时候,从哪个位置开始读取。比如,如果我们是从文件中读取日志信息,一开始输入了3个字符到文件中,那么offset会记录这个位置,下次有日志追加到文件里的时候,就会从上次读取的位置开始往后读取。
另外有个很重要的知识点,filebeat是按行读取,这个可以自行测试下,如果只往日志里追加内容,但是不追加换行符,会发现没有读取到新内容,一旦输入换行符,就会读取到新追加的内容了。
知道了这个知识点,我们就可以利用修改offset,甚至直接删除log.json文件来实现filebeat从指定位置或者从头开始读取数据了。

5. 读取log日志文件
如果输入源改成日志文件形式,修改配置如下
#指定filebeat的输入配置
filebeat.inputs:
#指定输入的类型
- type: log
paths:
- /tmp/elktest.log
#指定filebeat的输出配置
output.console:
#打印漂亮的格式
pretty: true
写个测试日志

这边就可以在message字段中看到日志的内容了
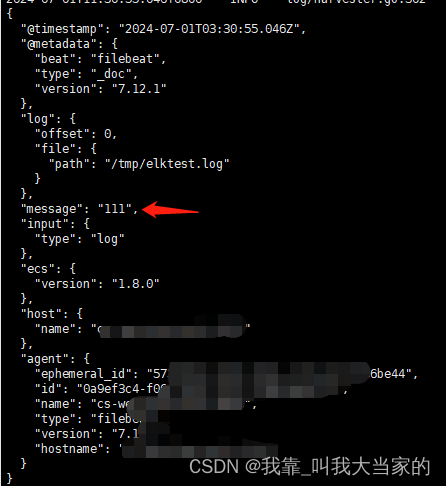
这里的type:log path配置支持多个,也只是通配符 * ,如下,向你用到了docker, docker目录下面都是各个中间件的文件目录,那用起来就非常方便了。
#指定filebeat的输入配置
filebeat.inputs:
#指定输入的类型
- type: log
paths:
- /tmp/elktest.log
- /tmp/*.txt
- type: log
paths:
- /tmp/test/*/*.log
#指定filebeat的输出配置
output.console:
#打印漂亮的格式
pretty: true
四、logstash的部署运行
官方使用文档说明:Logstash Reference [7.12] | Elastic
1.解压缩
tar -zxvf logstash-7.12.1-linux-x86_64.tar.gz2.修改配置
配置在config目录下
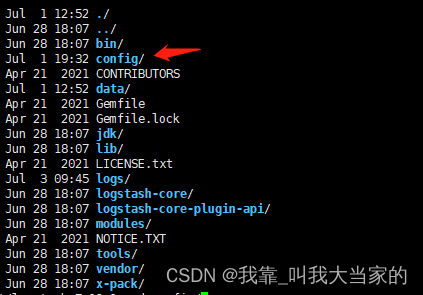
这里要注意:我们要修改的配置文件是logstash-sample.conf ,conf结尾的这个文件,你也可以自己创建哈

3、与filebeat进行对接
3.1、修改filebeat输出到logstash
#指定filebeat的输入配置
filebeat.inputs:
#指定输入的类型
- type: log
paths:
- /tmp/elktest.log
#指定filebeat的输出配置
output.logstash:
hosts: ["127.0.0.1:5044"]3.2、修改logstash输入为filebeat
input {
beats {
port => 5044
}
}
output {
stdout {}
}
4. 运行演示
运行起来,当然这个启动肯定是比较慢的了,一个是因为它是java写的,需要起jvm,此外你也可以看到logstash的包大小在300M左右,filebeat只有30,filebeat是go语言写的,速度很快。这也是为什么用filebeat来收集。
./bin/logstash -f config/logstash-sample.conf 演示效果图:

可以在logstash上看到如下效果

五、整合ELFK(elasticsearch+logstash+filebeat+kibana)
实现由log日志文件读取数据,到filebeat,然后filebeat输出到logstash,然后logstash输出到es中
1. 修改filebeat的配置文件
#指定filebeat的输入配置
filebeat.inputs:
#指定输入的类型
- type: log
paths:
- /tmp/elktest.log
#指定filebeat的输出配置
output.logstash:
hosts: ["127.0.0.1:5044"]2. 修改logstash配置文件
input {
beats {
port => 5044
}
}
output {
stdout {}
elasticsearch {
hosts => ["127.0.0.1:9200"]
index => "elk-logstash-%{+YYYY.MM.dd}"
}
}
3. 测试演示
然后把elasticseach,kibana,filebeat,logstash都运行起来,往log日志里追加内容

可以看到logstash控制台已经输出内容了
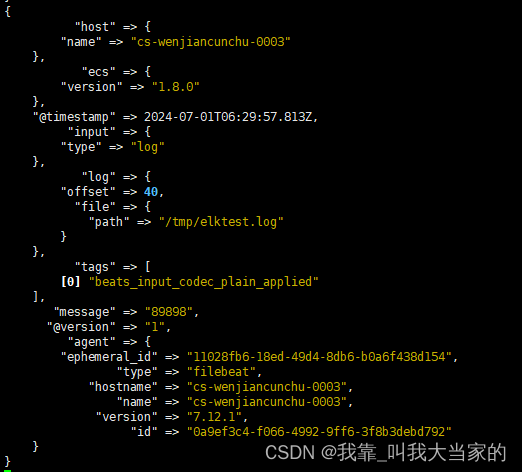
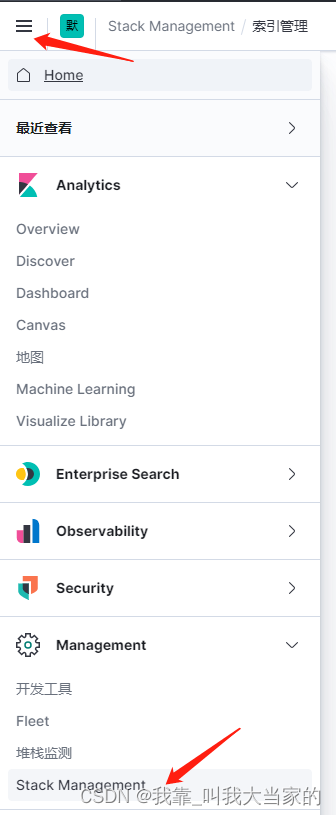
4. kibana重载索引
这个时候就可以在kibana重载索引,去查看了,先来到kibana视图页面,选择菜单栏中的最后一个Stack Management
在索引管理,索引tab页面就能看到索引了,但是由于我es没有部署集群,副本分片不能在当前节点创建访问,所以就变成了yellow,这块知识可以到es中去了解。
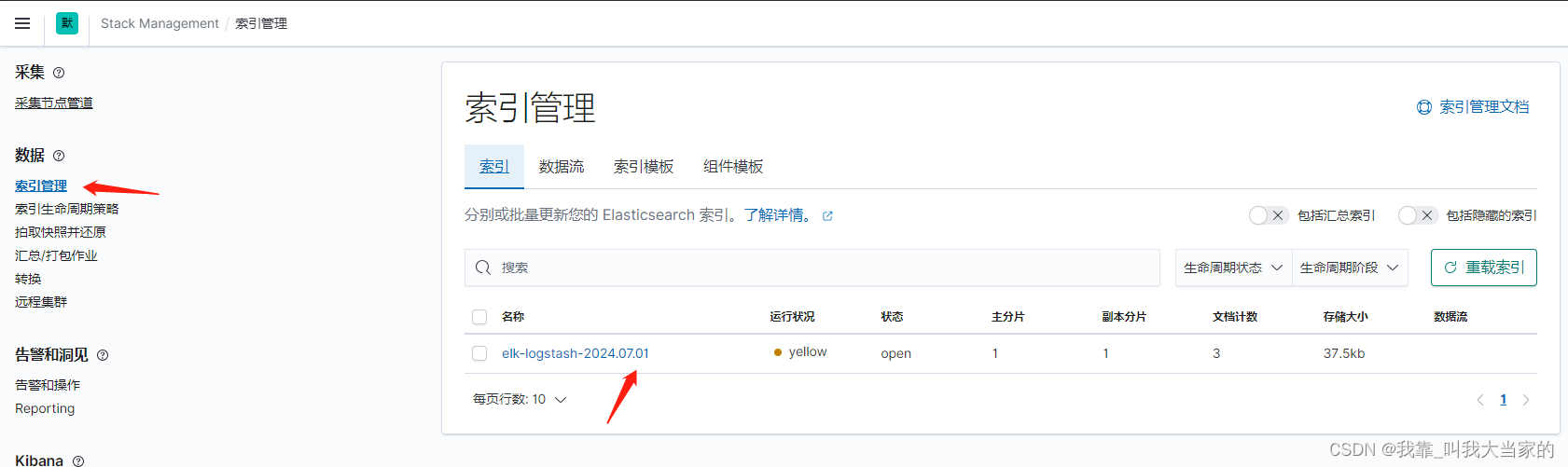
5. 查找数据
再选择菜单栏,选择discover
选择自己的创建的索引模式
默认显示出来的日志如下图所示,这样是比较乱的,我们可以在左侧勾选,我们想要显示的字段内容。
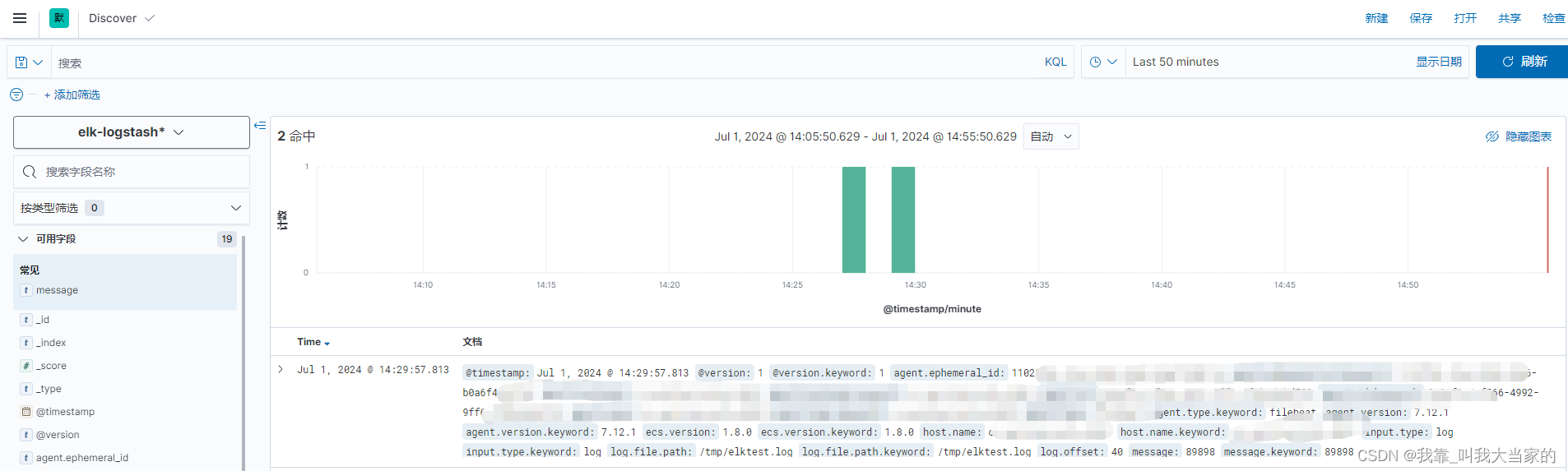
比如在左侧可用字段中看到了message,右边会有加号,点击即可添加该字段
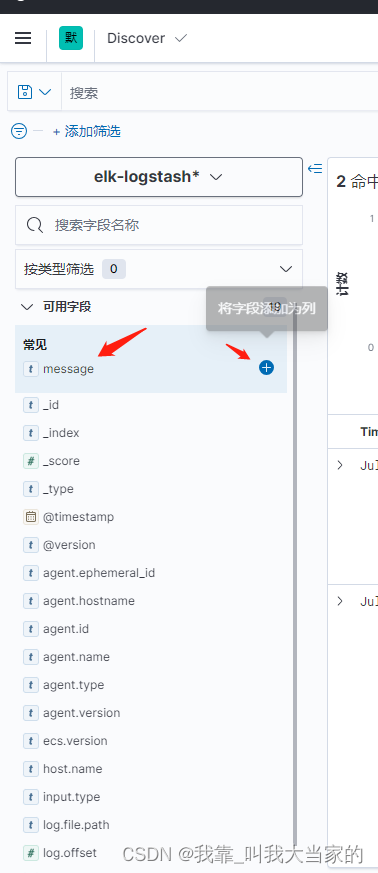
像我勾选了几个之后,就会变成如下显示
 鼠标放在字段上面,还会出现删除,左移右移进行调整,大家可以根据需要来设置
鼠标放在字段上面,还会出现删除,左移右移进行调整,大家可以根据需要来设置

我也换了个我本地的一个springboot项目,字段我就只显示message,如下:
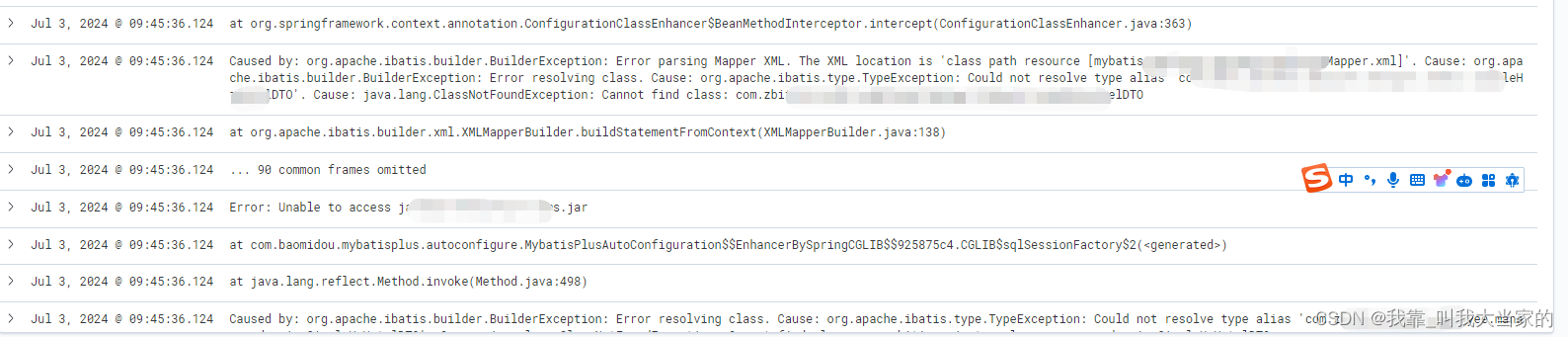
像报错也可以明显看到。
好了,自此为止,一个ELFK就搭建完毕了。根据实际项目需要,在对应服务器下使用filebeat采集日志,汇聚到logstash,然后输出到elasticsearch,最后使用kibana去查看的过程就完成了。当然如果想要更加直观,便捷的使用它,还要结合项目需要,设计一些如上图的报错,需要多行日志合并匹配啊,以及一些日志打tag或者做一些过滤处理等,需要更深的一点设计使用,这个留到后续有时间再更新吧。。。。都写在一个里面,大家也没耐心看(主要我也没耐心写了。。)
本人个人原创,如有雷同,纯属巧合,或者与本人联系,做改动。请转载或者CV组合标明出处,谢谢!(如有疑问或错误欢迎指出,本人QQ:752231513)


















 3423
3423

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









