







介绍:
通过灵活的内存管理和共享机制,减少KV cache的浪费,提高大模型处理的吞吐量。
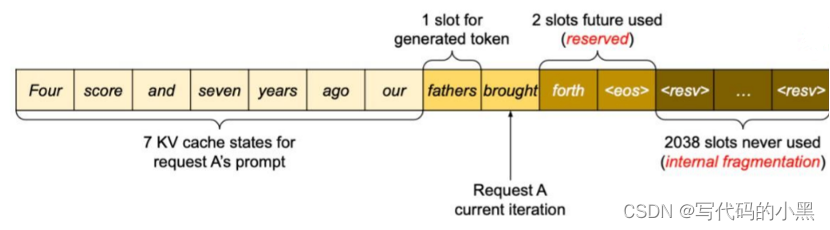
- 传统的LLM serving
传统的serving system为了保险起见,就会预留非常大的空间,比如模型支持的最大输出2048个token,它就会预留这么大的空间,那么如果我产生的输出仅有10个token,剩下的2038的slots就会作为内部碎片被浪费,而且所有生成的token只限定给当前request使用。
传统的serving缺点:
1. 传统的serving system,会申请2048个连续的内存块,来保存将要生成的token,如果只使用10个的话,那就会造成2038个内存块的浪费
2. 传统的serving system,生成的所有token没有共享,造成了LLM的重复工作
- Vllm优点:
vLLM采用了虚拟内存和分页的思想,允许在非连续的内存空间内存储token,内存的利用率接近于最优,仅浪费不到4%的内存
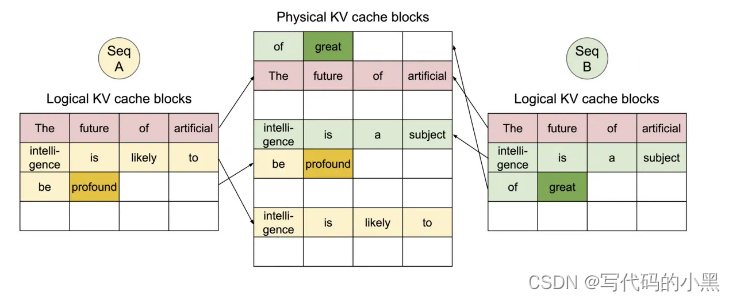
- vLLM还支持内存共享,进一步减少了内存开销
Vllm
Kv cache 连续逻辑内存存储

以NVIDIA A100 40GB 运行13B参数的LLM为例,13B参数占内存26GB,KV Cache 占用>12GB:
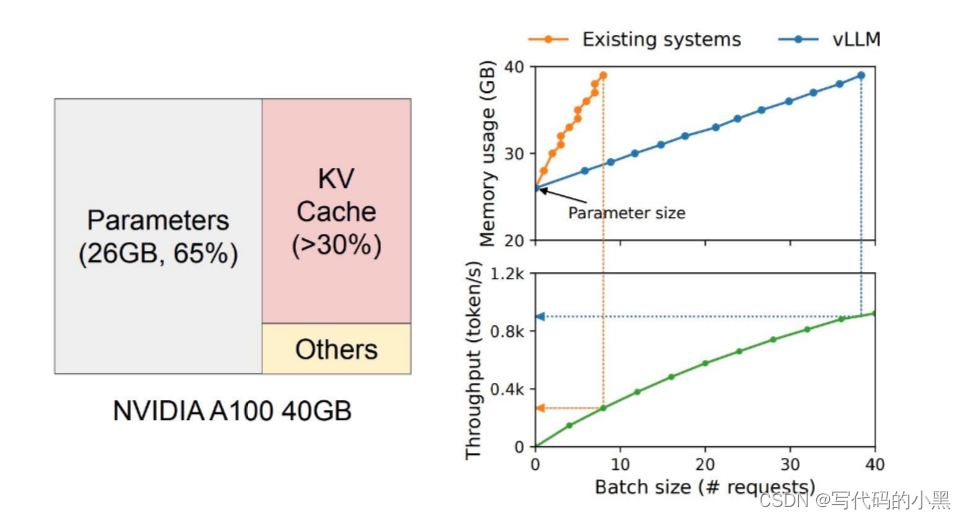
传统的LLM serving :
7.5个请求,就会沾满40g内存
每秒只能吞吐0.3k的token
vllM:
处理40个请求,才会占满40g内存
每秒能吞吐1k的token
一个token = KV cache = 800K
一个request = 2048 * kV cache = 1638400K = 1600MB = 1.6g
12g/ 1.6g = 7.5 个request


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









