







简单型
你平时在公司主要做什么?
日常监控维护业务
服务器巡检,调优
写一些日常使用的脚本,日常工作形成文档化
服务优化:nginx优化,tomcat 优化,系统优化
你们原来公司的网站架构是怎么样的?
搭的 LNWP 架构,Nginx做了集群,做了反向代理负载均衡,
mycat读写分离,数据库做的一主两从,并且做了 MHA 高可用
你对哪一块比较熟练或者精通?
对企业自动化交付CICD 方面做得比较熟练,
缓存服务 memcached,squid,zedis这种缓存服务器,
还有 lvs, keepalived这种负载均衡集群软件
容器 docker,k8s 方面
mysql数据库
根据图片中的内容,以下是提取的文字并整理后的格式:
介绍一下负载均衡?
负载均衡我用过 lvs 和 nginx 和阿里云 SLB
- nginx 负载均衡:工作在网络第 7 层,支持 http 应用进行分流
- lvs:抗负载能力很强,工作 4 层,配置简单,很稳定,不产生流量
LVS 内部原理?
LVS(Linux Virtual Server)的内部原理涉及以下几个主要组件和步骤:
-
调度器(Scheduler):调度器是 LVS 的核心组件,负责根据一定的调度算法(如轮询、加权轮询、最小连接数等)选择合适的后端服务器来处理传入的请求。调度器根据客户端请求的 IP 地址和端口号,将流量分发到后端服务器上。
-
IPVS 模块:IPVS(IP Virtual Server)是 Linux 内核中的模块,实现了 LVS 的核心功能。它拦截传入的网络流量,根据预先配置的规则将请求分发给不同的后端服务器。
-
后端服务器池:后端服务器池是一组提供相同服务的服务器,它们由负载均衡器统一管理。负载均衡器将请求分发给这些服务器,以实现负载均衡和高可用性。
-
监控与健康检查:LVS 可以定期检查后端服务器的健康状态,以确保只将流量分发给正常工作的服务器。如果某个服务器出现故障或不可用,负载均衡器会自动将其排除在服务范围之外,确保客户端请求不会被发送到有问题的服务器上。
-
网络地址转换(NAT):LVS 通常使用 NAT 技术修改传入和传出流量的 IP 地址,以隐藏后端服务器的真实 IP 地址。这有助于保护服务器的安全性并简化网络配置。
总体来说,LVS 的内部原理涵盖了负载均衡调度、IPVS 内核模块、后端服务器管理、健康检查和网络地址转换等关键方面。通过这些机制,LVS 能够实现高效的负载均衡和故障恢复,为网络服务提供更高的可靠性和性能。注意,LVS 的具体实现和配置可能会因版本和使用情况而有所不同。
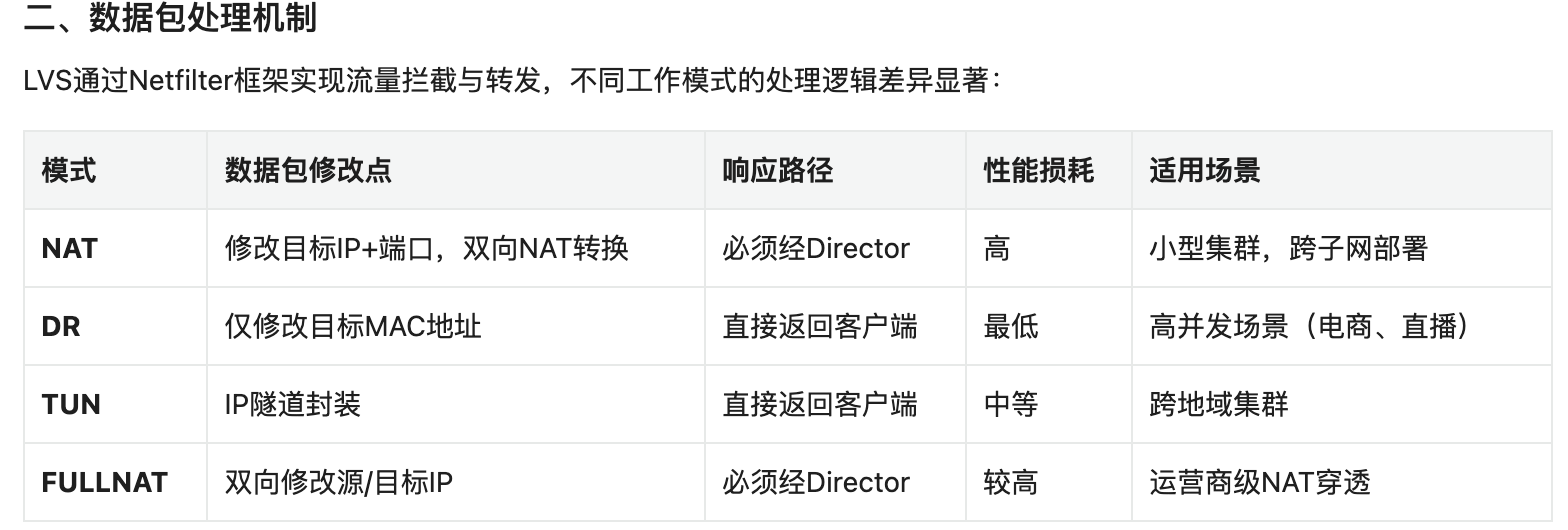
LVS 四种工作模式详解
1. NAT 模式 (NAT)
原理:
就是把客户端发来的数据包的 IP 头的目的地址,在负载均衡器上换成其中一台 RS 的 IP 地址,并发至此 RS 来处理。RS 处理完成后把数据交给负载均衡器,负载均衡器再把数据包的原 IP 地址改为自己的 IP,将目的地址改为客户端 IP 地址即可。负载均衡器再返回给客户端。期间,无论是进来的流量,还是出去的流量,都必须经过负载均衡器。
优点:
集群中的物理服务器可以使用任何支持 TCP/IP 操作系统,只有负载均衡器需要一个合法的 IP 地址。
缺点:
扩展性有限。当服务器节点(普通 PC 服务器)增长过多时,负载均衡器将成为整个系统的瓶颈,因为所有的请求包和应答包的流向都经过负载均衡器。当服务器节点过多时,大量的数据包都交汇在负载均衡器那,速度就会变慢!
2. IP 隧道模式 (TUN)
原理:
首先要知道,互联网上的大多 Internet 服务的请求包很短小,而应答包通常很大。那么隧道模式就是,把客户端发来的数据包,封装一个新的 IP 头标记(仅目的 IP)发给 RS。RS 收到后,先把数据包的头解开,还原数据包,处理后,直接返回给客户端,不需要再经过负载均衡器。注意,由于 RS 需要对负载均衡器发过来的数据包进行还原,所以说必须支持 IPTUNNEL 协议。所以,在 RS 的内核中,必须编译支持 IPTUNNEL 这个选项。
优点:
负载均衡器只负责将请求包分发给后端节点服务器,而 RS 将应答包直接发给用户。所以,减少了负载均衡器的大量数据流动,负载均衡器不再是系统的瓶颈,就能处理很巨大的请求量。这种方式,一台负载均衡器能够为很多 RS 进行分发。而且跑在公网就能进行不同地域的分发。
缺点:
隧道模式的 RS 节点需要合法 IP,这种方式需要所有的服务器支持“IP Tunneling”(IP Encapsulation)协议,服务器可能只局限在部分 Linux 系统上。
3. 直接路由模式 (DR)
原理:
负载均衡器和 RS 都使用同一个 IP 对外服务。但只有 DR 对 ARP 请求进行响应,所有 RS 对本身这个 IP 的 ARP 请求保持静默。也就是说,网关会把这个服务 IP 的请求全部定向给 DR,也就是客户端发送请求给 lvs 的 DR 模式,而 DR 收到数据包后根据调度算法,找出对应的 RS,把目的 MAC 地址改为 RS 的 MAC(因为 IP 一致)并将请求分发给这台 RS。这时 RS 收到这个数据包,处理完成之后,由于 IP 一致,可以直接将数据返给客户,则等于直接从客户端收到这个数据包无异,处理后直接返回给客户端。由于负载均衡器要对二层包头进行改换,所以负载均衡器和 RS 之间必须在一个广播域,也可以简单的理解为在同一台交换机上。
优点:
和 TUN(隧道模式)一样,负载均衡器也只是分发请求,应答包通过单独的路由方法返回给客户端。与 VS-TUN 相比,VS-DR 这种实现方式不需要隧道结构,因此可以使用大多数操作系统做为物理服务器。
缺点:
要求负载均衡器的网卡必须与物理网卡在一个物理段上。
4. FULLNAT 模式(双向地址转换)
工作原理
同时修改请求的 源 IP(SNAT) 和 目标 IP(DNAT):
- 入向:CIP → VIP 转换为 DIP → RIP
- 出向:RIP → DIP 转换为 VIP → CIP
核心特性
- 支持 RS 与 LVS 跨 VLAN 部署
- 可穿透复杂网络拓扑
- 需内核补丁支持(非原生功能)
- 性能较 NAT 下降约 15%
典型场景
云环境多租户隔离、大规模跨 VPC 服务集群
模式对比与选型指南
| 维度 | NAT | DR | TUN | FULLNAT |
|---|---|---|---|---|
| 网络要求 | 同私网 | 同物理网络 | 支持跨公网 | 跨 VLAN/子网 |
| 性能 | 低(双向流量) | 极高(单路径) | 高(隧道开销) | 中等 |
| RS 配置复杂度 | 简单 | 复杂(ARP 抑制) | 中等(隧道配置) | 简单 |
| 扩展性 | 差(≤20 节点) | 优(≤100 节点) | 优(地理分布) | 优(大规模集群) |
| 典型应用 | 小型内网服务 | 高并发 Web | CDN/跨机房 | 云平台/混合云 |
技术选型建议
- 性能优先:选择 DR 模式(90% 生产场景首选)
- 跨网络需求:公有云选 FULLNAT,专线环境选 TUN
- 协议兼容性:非 HTTP 服务优先考虑 NAT/FULLNAT
- 运维成本:简单架构用 NAT,专业团队可用 DR/TUN
实际部署中常采用 分层架构:LVS DR 模式作前端四层负载,配合 Nginx/Haproxy 实现七层业务路由。
nginx lvs haproxy 三个有什么区别
- lvs 优势:
- 工作在传输层(四层)
- 抗负载能力很强
- 工作稳定
- 不占什么流量
- pv 超过 1000 万可用 lvs
- 资源消耗CPU/内存占用最低
- nginx:
- nginx 工作第 7 层,支持 http 应用本身分流,lvs 没有这个功能
- nginx 对网络依赖很小,nginx 安装简单也稳定
- 流量日 pv <=1000 万 nginx 足以能撑住,一般不是特别大的公司都达不到 lvs 使用级别
- 官方说并发 50000 都没什么问题,测试过并发 1-2 万根本没什么问题
- 资源消耗中等(需维护连接状态)
- haproxy:
- haproxy 是支持虚拟主机的,可以工作在 4、7 层(支持多网段)
- haproxy 的优点能够补充 nginx 的一些缺点,比如支持 session 的保持,Cookie 的引导;同时支持通过获取指定的 url 来检测后端服务器的状态。
- haproxy 跟 lvs 类似,本身就只是一款负载均衡软件;单纯从效率上来讲 haproxy 会比 nginx 有更出色的负载均衡速度,在并发处理上也是优于 Nginx 的。
- haproxy 支持 TCP 协议的负载均衡转发,可以对 MySQL 读进行负载均衡,对后端的 MySQL 节点进行检测和负载均衡。
- 支持深度协议解析,如MySQL读写分离
- 资源消耗较高(复杂策略计算)
总结建议:
- 性能优先:选择LVS(金融交易、CDN边缘节点)
- 功能全面:选择HAProxy(微服务API网关、数据库集群)
- 生态整合:选择Nginx(Web全栈场景、Kubernetes Ingress)
- 混合部署:LVS作前端四层负载 + Nginx/HAProxy作七层业务路由
HAProxy在吞吐量、响应速度等负载均衡性能上表现优异,为什么感觉Nginx更普及呢?
尽管 HAProxy 在负载均衡性能上表现优异,但 Nginx 更普及的主要原因在于功能多样性与生态整合能力:
- 多角色集成
Nginx 不仅是负载均衡器,还是全功能 Web 服务器,支持静态资源服务、反向代理、缓存加速、SSL 终止等,减少了架构复杂度。例如:
- 可直接托管前端静态文件,无需额外部署 Apache 或 Tomcat;
- 通过 FastCGI 模块无缝对接 PHP/Python 等后端语言。
- 开发者友好性
- 配置简洁:层级化配置文件结构(类似编程语言)比 HAProxy 的命令式配置更易理解;
- 模块化扩展:支持 Lua 脚本、第三方模块(如 WAF、GeoIP),而 HAProxy 扩展依赖代码修改;
- 社区生态:拥有更活跃的开发者社区和丰富的文档资源。
- 云原生适配
Nginx 是 Kubernetes Ingress 控制器的首选方案,因其支持:
- 动态配置热加载;
- 自动服务发现;
- 与 Prometheus 等监控工具深度集成。
根据图片中的内容,以下是提取的文字并整理后的格式:
LVS 算法、工作模式?
lvs:
实现负载均衡集群部署的软件,有一台或多台调度器组成,通过加载 lvs 内核模块并且生成虚拟 ip,通过虚拟 ip 接收客户端的请求,再根据自身配置的调度算法,实现对请求的转发。
算法:大概有 10 种,主要的有下面几种:
- 静态算法:只是根据算法进行调度并不考虑后端 REALSERVER 的实际连接情况。
- rr:轮询算法。按照节点顺序一个一个来,均等地对待每一台服务器,不管服务器上的实际连接数和系统负载。
- wrr:加权轮询算法。根据节点权重以及节点顺序分发请求,调度器可以自动询问真实服务器的负载情况,并动态调整权值。
- sh:源地址散列调度算法。匹配客户端最近一次访问的服务节点,并将请求交给这个服务节点,根据源地址散列算法进行静态分配固定的服务器资源。主要目标是实现会话保持(Session粘滞,会话保持需求)
或者说:负载均衡器选择响应时间最短的后端服务器来处理请求。这可以确保请求被发送到响应速度最快的服务器上。(这看起来不对,忽略) - dh:目标地址散列算法。根据请求的目标IP地址进行哈希计算,生成固定散列值,将同一目标IP的请求始终分配给同一台真实服务器(RS)。首次请求时建立目标IP与RS的映射关系,后续请求直接沿用该映射。主要目标提高缓存命中率/资源分类。
动态算法:
- lc:最少连接数算法。动态地将网络请求调度到已建立的连接数最少的服务器上。
- wlc:加权最少连接数算法。调度器可以自动询问真实服务器的负载情况,并动态调整权值。
- lblc:基于局部的最少连接数调度算法。先根据请求的目标 ip 地址寻找最近的该目标 ip 地址所有使用的服务器,如果这台服务器依然可用,并有能力处理该请求,调度器会尽量选择相同的服务器,否则会继续选择其他可行的服务器,即:如果服务节点因为自身故障暂时无法接收请求,则调度器在服务器集群中找出一台连接量最少的节点来处理请求。
- lblcr:带复制的基于局部的最少连接算法。记录的不是要给目标 ip 与一台服务器之间的连接记录,它会维护一个目标 ip 到一组服务器之间的影射关系,防止单点服务器负载过高。
根据图片中的内容,以下是提取的文字并整理后的格式:
MySQL 用的哪个版本,你们的数据库怎么备份,什么时间备份,备份数据量多大
- 使用的版本:5.7
- 备份方式:逻辑备份
- 备份频率:每天全量备份
- 备份数据量:500G
- 后续改用:xbk 备份
Memcached 工作原理(内存管理机制)
Memcached是一种高性能分布式内存缓存系统,主要用于通过内存存储热点数据来减轻数据库压力、提升动态Web应用的响应速度。Memcached在简单缓存场景(数据类型仅支持String和整数)中仍具有性能优势,而Redis(数据类型支持String、List、Hash、Set等复杂结构,也可持久化)凭借功能丰富性成为更通用的数据层解决方案。
Memcached 是一种内存缓存软件,在工作中经常用来缓存数据库的查询数据。数据被缓存在事先预分配的 memcached 管理的内存中,可以通过 API 或命令的方式存取内存中缓存的这些数据。memcached 服务内存中缓存的数据就像一张巨大的 HASH 表,每条数据都是以 key-value 对的形式存在。每个被缓存的对象或数据都有唯一的标识符 key,存取操作通过这个 key 进行。保存到 Memcached 中的对象或数据放置在内存中,并不会作为文件存储在磁盘上,所以存取速度非常快。由于没有对这些对象进行持久性存储,因此在服务器端的服务重启之后存储在内存中的这些数据就会消失。而且当存储的容量达到启动时设定的值时,就自动使用 LRU 算法删除不用的缓存。
Nginx 状态码 499、401、404、400 是什么意思
- 499:服务端处理时间过长,客户端主动关闭了连接。
- 401:权限验证错误,一般是用户名和密码错误等。
- 404:访问文件不存在,另外如果浏览器发送的请求头和服务端要求的请求头不一致,也是报404
- 400:HTTP 标准状态码,表示服务器因客户端请求不合法而拒绝处理。web 服务器遇到不完整的 HTTP 请求头,一般是请求头或 cookie 信息过大,调整 nginx 相关参数调大即可。请求参数错误,比如get方法,服务端可以限制必须填一个username参数,如果浏览器没填就是400。
- 405: 请求方法错误,服务端让用post方法,但是浏览器用了get方法,就是405
Nginx 状态码 500、502、504、503 错误可能的原因有哪些?
- 500:大多数是代码问题或者 SQL 报错或连接不上数据库、磁盘空间不够、系统文件设置句柄数太少。
- 502:一般就是后端问题,服务挂了或者进程不够用了大并发时候处理不过来,增加后台服务器。
- 504:网关超时,nginx 里配置了超时时间,在配置的时间内服务端没有处理完成,导致超时,后台服务不一定是挂了。
- 503:服务临时不可用,一般是临时服务器维护或者过载,临时的,过段时间会恢复。
Nginx 状态码 301、302、304、200 分别表示什么意思
- 301 状态:永久重定向
- 302 状态:临时重定向
- 304 状态:客户端有缓存情况下服务端的一种响应,访问的文件还没过期
- 200 状态:访问正常
维护网站过程中遇到的问题,处理过什么故障?(状态码:413、504 的意思)
根据自己实际情况,找一下大的故障、有技术难度的故障来说。
-
413 错误:
- web 服务报错 413,查阅后发现是客户端请求的数据量太大,超过了配置的最大值。
- 我没有指定 http 请求最大大小,配置文件修改增大了
client_max_body_size的值完全解决(如果上传文件大小超过client_max_body_size时,会报 413 entity too large 的错误)。
-
504 错误:
- 请求后端服务的时候,后端服务很长时间才响应。
- 查看错误日志后修改增大了
proxy_read_timeout和proxy_read_time的值后完美解决。
FTP 主动和被动的区别(指的是服务器端的主动和被动)?
主动模式:
- FTP 客户端向服务器的 FTP 控制端口(默认是 21)发送连接请求,服务器接受连接,建立一条命令链路。
- 当需要传送数据时,客户端告诉服务器我开放了某个大于 1024 的大端口,你过来连接我。
- 于是服务器从 20 端口向客户端的大端口发送连接请求,建立一条数据链路来传送数据。
- 在数据链路建立过程中是服务器主动请求,所以称为主动模式。
被动模式:
- FTP 客户端向服务器的 FTP 控制端口(默认 21)发送连接请求,服务器接受连接,建立一条命令链路。
- 当需要传送数据时,服务器告诉客户端,我打开了某个端口(大于 1024 的大端口),你过来连我。
- 于是客户端从大于 1024 的大端口向服务器的该大端口发送连接请求,建立一条数据链路来传送数据。
- 在数据链路建立的过程中是服务器被动等待客户机的请求,所以称为被动模式。
根据图片中的内容,以下是提取的文字并整理后的格式:
Apache 三种工作模式区别及优化?
Apache 的三种工作模式
-
prefork:
- 预派生多进程:当 Apache 启动时,启动一个主进程,并根据配置由该主进程派生多个子进程。
- 这些子进程等待客户端发送来的请求并处理。由于已经有预先派生好的进程,所以在处理客户端请求时效率比较高。
- 如果客户端的请求数量超过预派生的进程数量,则该主机会派生新的进程来处理后来的请求。
- 支持的并发量低,就是说不能同时处理客户端发来的请求,但是稳定。
-
worker:
- 预派生多线程:当 Apache 启动时,启动一个主进程,并根据配置由该主进程派生多个子进程。
- 每个子进程又派生出多个线程,这些线程等待客户端发送来的请求并处理。
- 由于已经有预先派生好的线程,所以在处理客户端的请求时效率比较高。
- 如果客户端的请求数量超过预派生的线程,则每个子进程会派生出新的线程来处理后来的请求。
- 支持的并发量相较于 prefork 模式要多,但是没有 prefork 模式稳定。
- 但是在长链接的模式下,线程在连接时间范围内会一直等待客户端发来的请求,线程利用率不高。
-
event:
- worker 的升级版,通过管理线程,可以对处理长连接请求的线程进行调度。
- 当客户端暂时没有请求发来时,则该处理长连接的线程可以接受别的请求,提高了线程的利用率。
优化
- 控制
maxclients最大连接数的设置,避免服务器产生太多子进程而发生交换。 - 选择更好的 CPU、内存和硬盘。
HostnameLookups设置为off,尽量减少 DNS 查询的次数。- 修改 Apache 最大并发连接数。
MySQL 主从原理?如果主库不同步报错了怎么恢复?
原理:
-
主库:
- 需要开启二进制日志文件,并且对数据库进行授权,允许从库访问。
- 例如主库使用的二进制文件名是
Mysql-bin.01,授权的用户密码分别是slave,123.com。
-
从库:
- 需要指定自己的主库是谁,一个从库只能有一个主库,一个主库可以有多个从库。
- 指定主库时需要的信息是:
master_host:主库的主机地址。master_user:访问主库时使用的用户。master_log_file:同步主库哪个二进制日志文件的操作。master_log_pos:从二进制日志哪个位置的操作开始同步。
- 从库还需要开启中继日志来记录从主库获取的日志信息。
-
当主从部署完成之后,从节点会派生出两个线程分别是 I/O 线程(用来连接主库并将主库二进制日志获取到的信息写入到中继日志),SQL 线程(从中继日志中提取 SQL 语句并执行,实现从节点与主节点的数据同步)。
-
主节点会派生 DUMP 线程,当主库数据更新时,主节点的 DUMP 线程会通知从节点的 I/O 线程。
-
I/O 线程通过
slave用户和密码123.com连接到主节点之后会告诉 DUMP 线程自己要从二进制日志文件Mysql-bin.01中指定的位置读取数据,获取到数据之后写入到自己的中继日志中。 -
I/O 线程任务完成,SQL 线程检测到中继日志更新之后会从中继日志中提取 SQL 语句并执行这些语句完成数据同步。

主库不同步的原因有很多:
- 网络的延迟?
- 主从两台机器负载不一致?
- max_allowed_packet 设置不一致?
- 自增键不一致?
最大的问题就是 IO 线程和 SQL 线程不同步。
IO 线程不同步:
- 一般是网络问题或授权不正确,确认主从网络联通情况和授权。
SQL 线程不同步:
- 一般是主从表结构不一致,可以先进主库锁表,再数据备份,把备份文件传到从库,在停止从库的主从状态,从库在导入书数据备份,设置从库同步,重新开启从同步即可。
mysql备份原理与策略
MySQL的备份方案设计需综合考虑数据类型、业务连续性要求及恢复效率,以下是基于行业实践的备份策略分类与实施要点:
一、核心备份类型与适用场景
-
逻辑备份
- 原理:通过SQL语句导出数据库结构(CREATE)和数据(INSERT),生成可执行脚本。 500G左右可选
- 工具:
mysqldump:MySQL官方工具,适合中小型数据库,支持单库/全库备份,生成.sql文件。mydumper:开源工具,支持多线程加速与表级备份,适合TB级数据。
- 优势:跨版本兼容性强,可编辑备份内容。
- 局限:备份/恢复速度较慢,大库可能耗时数小时。
-
物理备份
- 原理:直接复制数据库物理文件(如.ibd、.frm),保留完整存储结构。
- 工具:
Percona XtraBackup:开源热备工具,支持InnoDB在线备份与增量备份,不锁表。MySQL Enterprise Backup:官方商业工具,提供压缩与加密功能。
- 优势:速度快(TB级数据分钟级完成),支持快速恢复。
- 局限:依赖MySQL版本,需与原环境配置一致。
-
二进制日志备份
- 原理:持续备份binlog文件,记录所有数据变更操作,用于增量恢复。
- 配置:
[mysqld] log-bin=mysql-bin # 启用binlog expire_logs_days=7 # 保留7天日志 - 恢复流程:全量备份 + 增量binlog应用,实现精确到秒的数据恢复。
二、备份策略设计
-
全量+增量组合策略
- 全量备份:每周日凌晨执行,使用XtraBackup备份整个数据集。
- 增量备份:每日夜间备份当日变化的binlog或差异数据块。
- 示例恢复:
# 合并增量到全量 xtrabackup --prepare --apply-log-only --target-dir=/backup/full xtrabackup --prepare --apply-log-only --target-dir=/backup/full --incremental-dir=/backup/inc1 # 恢复数据文件 xtrabackup --copy-back --target-dir=/backup/full
-
多级存储策略
- 本地存储:保留3天内的热备份,用于快速恢复。
- 异地存储:加密后同步至云存储(如S3),保留30天历史版本。
- 磁带归档:合规性数据保留7年以上,采用WORM(一次写入多次读取)介质。
-
业务分级策略
业务等级 备份频率 RTO目标 RPO目标 核心交易 15分钟增量 <30分钟 <5分钟 一般服务 每日全量 <4小时 <1小时 归档数据 每周全量 <24小时 <6小时
三、灾难恢复演练流程
-
场景模拟
- 硬件故障:直接替换损坏磁盘,从备份恢复数据文件。
- 误删除:通过binlog定位误操作时间点,执行反向SQL恢复。
-
自动化脚本示例
# 逻辑备份验证脚本 mysqldump -uadmin -p$PASS --single-transaction db | gzip > backup.sql.gz if [ $? -eq 0 ]; then md5sum backup.sql.gz > backup.md5 aws s3 cp backup.* s3://bucket/$(date +%F)/ else alert "Backup failed!" fi
总结(关键决策矩阵)
| 场景 | 推荐方案 | 工具选择 | 恢复时效 |
|---|---|---|---|
| 小型网站 | 每日逻辑全量 | mysqldump + binlog | <1小时 |
| 中型电商 | 全量+增量物理备份 | XtraBackup + binlog | <30分钟 |
| 金融核心系统 | 实时主从同步+异地容灾 | Percona Cluster + S3 | <5分钟 |
| 大数据分析平台 | 快照备份 + 分层存储 | LVM快照 + 对象存储 | <2小时 |
合理选择备份方案需平衡RTO/RPO要求、数据规模及运维成本。建议至少实施「本地物理全量+异地逻辑增量」的双重策略,并定期通过恢复测试验证有效性。
如何备份大数据 MySQL 数据文件,MySQL 都优化哪些?
xtrabackup 热备份
- xtrabackup 备份时是热备,不会锁表。
MySQL 优化
主要有两个主要方面:安全、性能、参数、架构、SQL 语句
-
安全方面:
- 可以把默认端口 3306 改为其他的。
- 对用户降权,以比普通用户运行 MySQL 即可。
- 开启二进制日志文件,最好在禁止一下 root 账户远程访问。
-
性能方面:
- 可以给主机选择合理的 CPU、内存调大、硬盘。
- 可以对 Linux 系统内核参数优化。
- 数据库优化的话可以对执行计划、索引、SQL 改写等等优化。
-
参数优化:
- InnoDB 的 buffer 参数调大。
- 连接数调大。
- 缓存的参数优化。
-
架构优化:
- 主从,读写分离,一主多从,架构调整。
-
SQL 语句优化:
- 协助开发优化。
- 开启慢查询 SQL,是否没有索引,是否需要借助 Redis 缓存、ES 等。
oceanbase主从同步
蚂蚁oceanbase部署方案:三地五中心
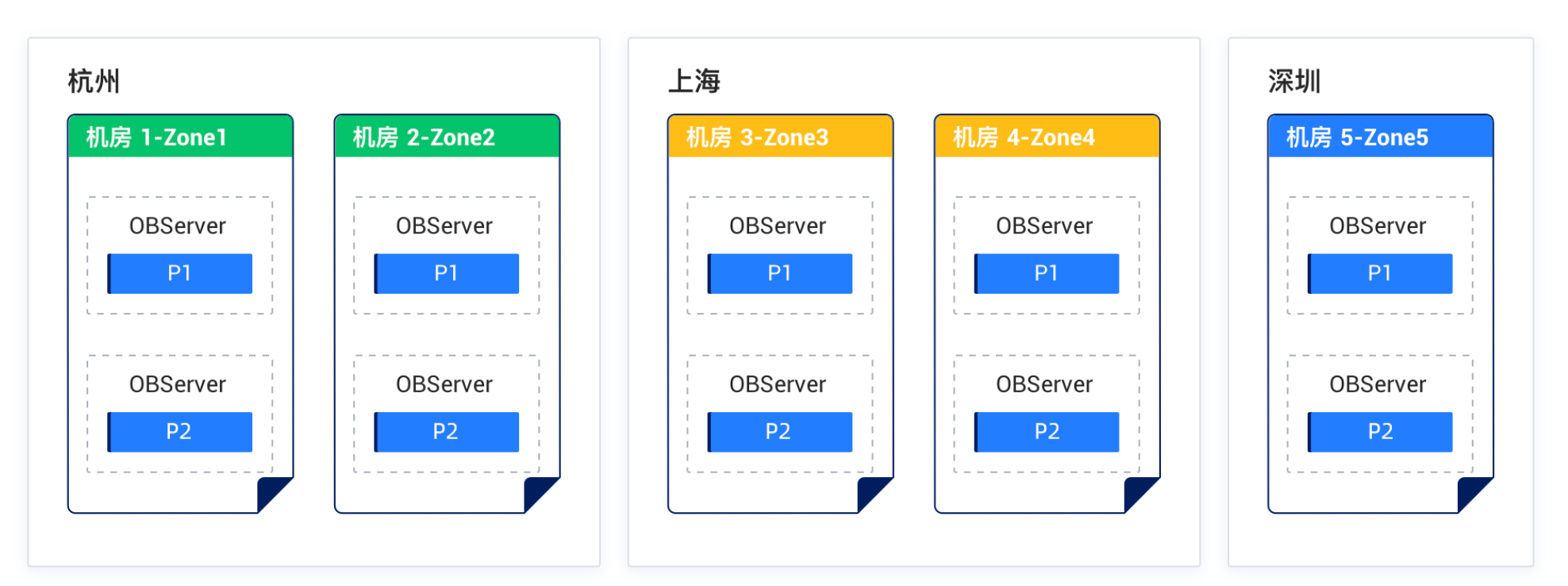
解释一下蚂蚁的三地五中心:
首先数据是分段的,比如00-99一共100个uid,会分成4段,每25个是一个数据分区,每个数据分区都会有自己的主副本和从副本。结合LDC架构,比如用户25在上海zone,那就设置对应的上海ob为主副本,其他为从副本(写必须主副本进行,读可以在从副本)。
- 全量副本会包含完整的数据库数据(日志 + 内存数据 + 磁盘数据);随时能变成主副本处理读写请求,就像备用手机可以立即开机使用。
- 日志副本(根据Redo-Log生成)仅包含事务变更日志(类似"用户A在14:03充值100元"的记录),不能直接处理业务请求,但能帮助其他副本恢复数据。
- 全量副本通关Paxos 协议,保证实时一致性,异地日志副本通关Redo-Log异步完成同步,保证最终一致性。
- Paxos 强同步基于 Multi-Paxos 协议实现,通过多副本实时共识确保数据零丢失。其核心流程如下:
-
提案阶段
- 主副本(Leader)接收写请求后生成 Redo 日志
- 向同城所有从副本(Follower)发送 Prepare 请求,携带唯一递增的提案编号
-
承诺阶段
- 从副本检查提案编号:
if(当前编号 < 收到编号) → 承诺不接收更小编号的提案 else → 拒绝提案 - 返回已接受的最高编号日志内容(用于数据修复)7
- 从副本检查提案编号:
-
提交阶段
- 主副本收到多数派(N/2+1)确认后,广播 Accept 请求
- 从副本持久化日志并返回 ACK
- 主副本确认提交后响应客户端
- 异地 Redo 日志流异步同步
- 日志抓取层:专用线程从主集群 OBServer 拉取 Redo 日志
- 日志解析层:将物理日志转换为逻辑变更记录(类似 Oracle Logical Standby)
- 传输通道:通过 Kafka/RocketMQ 等中间件实现削峰填谷
- 日志应用层:异地集群按事务顺序回放日志
- 一个写请求必须通过主写入,然后主从同步
- 一个读请求,可以从备读取。
你在上家公司用的什么监控软件(Zabbix)?都监控些什么?怎么增加模板?
Zabbix 监控内容
-
系统层:
- CPU
- 内存
- 硬盘
- 磁盘 I/O
- 流量
- 连接数
-
应用层:
- 进程
- MySQL 主从状态
- Tomcat 性能监控
- MySQL 性能监控
- 网站状态
Zabbix + Grafana 监控可视化
- 故障报警
- 预警
- 邮件或微信通知
自动化功能
- 自动注册
- 自动安装客户端
我司监控
以下是AntMonitor从SLuestions中获取基础设施元数据的完整链路解析,结合阿里云日志服务(SLS)与蚂蚁监控系统的集成机制:
一、数据采集与存储阶段
-
Logtail元数据注入
- 通过Kubernetes环境中的Logtail DaemonSet,自动采集Pod名称、命名空间、节点IP等元数据,并通过CRD配置(如
AliyunLogConfig)将业务标签(如app=java-demo)附加到日志中 - 示例CRD配置:
inputDetail: plugin: inputs: - type: file detail: DockerIncludeEnv: { "app": "java-demo"} IncludeK8sLabel: true # 启用K8s标签采集
- 通过Kubernetes环境中的Logtail DaemonSet,自动采集Pod名称、命名空间、节点IP等元数据,并通过CRD配置(如
-
SLS存储
- 采集的日志及附加的元数据统一存储在SLS的Logstore中,支持按Project/Logstore分类管理
- 数据存储格式示例:
{ "log_content": "Error occurred...", "__tag__:__pod_name__": "java-demo-abc123", "__tag__:__node_ip__": "192.168.1.100", "app": "java-demo" }
二、AntMonitor数据消费阶段
-
SLS数据接入
- API直读:AntMonitor通过SLS的SDK或REST API直接查询Logstore中的日志和元数据,支持SQL/PromQL混合查询实现跨数据源关联
- 定时任务:通过SLS的Scheduled SQL功能定时聚合元数据(如按Pod统计错误率),生成时序指标并推送至AntMonitor的时序存储
-
元数据关联与扩展
- ExternalStore动态关联:AntMonitor通过SLS的ExternalStore功能,将日志中的Pod名称与外部数据库(如CMDB)中的主机属性(如所属集群、责任人)动态关联,丰富元数据维度[43]。
示例查询:SELECT l.pod_name, u.owner FROM log l LEFT JOIN cmdb_metadata u ON l.pod_name = u.pod_name
- ExternalStore动态关联:AntMonitor通过SLS的ExternalStore功能,将日志中的Pod名称与外部数据库(如CMDB)中的主机属性(如所属集群、责任人)动态关联,丰富元数据维度[43]。
-
计算与存储
- 分布式计算引擎:AntMonitor的计算系统(如Spark集群)对原始日志进行清洗、聚合,生成带元数据的时序指标(如
k8s_pod_error_count{app="java-demo"}) - 时序存储:处理后的数据存入AntMonitor的时序数据库(如CeresDB),支持高并发查询与长期存储
- 分布式计算引擎:AntMonitor的计算系统(如Spark集群)对原始日志进行清洗、聚合,生成带元数据的时序指标(如
三、监控与可视化阶段
-
元数据驱动告警
- 基于Pod标签(如
app=java-demo)定义告警规则,例如:当该Pod的错误率超过5%时触发告警 - 动态阈值:通过机器学习分析历史数据,自动调整告警阈值以减少误报
- 基于Pod标签(如
-
拓扑关联
- 将Pod元数据与微服务依赖拓扑结合,实现故障定位(如某节点异常影响下游服务)
关于采样率和监控数据准确性的问题
关于AntMonitor监控系统中采样率配置与数据准确性的问题,其核心机制和应对策略可归纳如下:
一、采样率的作用与局限性
-
基本逻辑
当采样率设置为5%时,系统确实仅采集实际调用量的5%数据(如100次调用采集5次)。若直接通过采样数据推算总量(如5次 × 20倍),在均匀调用分布的场景下误差较小,但在突增/突降或调用分布不均时可能导致统计失真 -
总量统计的挑战
对于接口调用总量这类绝对值指标,固定采样率会直接导致数据缺失。例如,若某接口调用量突增到1000次/分钟,采样后仅记录50次,可能无法准确反映真实负载
二、AntMonitor的应对机制
-
分层采样策略
- 关键接口全采样:对核心业务接口(如支付交易)采用100%采样,确保关键指标准确性。
- 非关键接口动态采样:对低频或非核心接口按比例采样,降低资源消耗
-
智能动态采样
- 流量敏感调整:系统根据实时流量波动自动调整采样率。例如,当调用量超过阈值时临时提高采样率,确保异常时段数据完整性
-
统计补偿算法
- 无偏估计:通过统计学方法(如Horvitz-Thompson估计器)对采样数据进行加权计算,补偿采样率带来的误差。例如,5%采样数据乘以20倍系数推算总量,并结合历史分布模型修正偏差
-
异常检测兜底
- 离群值捕获:即使低采样率下,系统仍通过异常检测模型(如基于时序预测或突变点检测)识别突增/突降事件,触发全量数据采集
三、实际应用建议
-
业务分级配置
- 核心业务指标(如交易成功率)建议全量采集,非核心指标(如内部工具接口)可按需设置采样率
-
结合聚合指标
- 优先使用率值类指标(如错误率、平均耗时)替代总量指标,此类指标受采样率影响较小
-
监控策略验证
- 通过历史数据回放测试不同采样率下的统计误差,调整算法参数以平衡资源开销与准确性
总结
AntMonitor通过分层采样、动态调整和统计补偿机制,在保证资源效率的同时最大限度减少数据失真。对于总量敏感场景,建议结合业务优先级配置全量采集或采用加权补偿算法,并优先依赖率值类指标。实际应用中需根据业务容忍度进行策略调优
Nagios, Cacti 维护过吗,平时都监控什么?(可以不看,太老了)
系统层监控:
- 使用阿里云对 CPU、内存、硬盘、带宽、磁盘 I/O 进行监控。
应用层监控:
- 各种进程监控
- 应用性能监控
- MySQL 主从监控
- 并发连接监控
一台 Web 服务器应该监控哪些指标
- 系统层面
- 网站状态
- CPU
- 内存
- 磁盘 I/O
- 连接数
- sal
- cal
- dal
- load
- gc
- ce
- service
- 业务层面
- 接口调用量
- 接口成功量
- 接口失败量
- 接口耗时
- 接口成功率
- 业务成功率
Zabbix 监控数据库监控哪些参数
- 主从状态
- 进程
- 性能指标(比如查询吞吐量、查询执行性能)
- 连接情况
- 缓冲池情况
- 模板导入监控
Zabbix 有哪些监控项
- 模板自带监控项
- 自定义监控项
监控一台服务器时,你觉得应该监控服务器的哪些资源
系统层:
- CPU
- 内存
- 硬盘
- 磁盘 I/O
- 连接数
- sal
- cal
- dal
- load
- gc
- ce
- service
应用层:
- 进程状态
- 服务性能状态
- 主从同步状态
- error报错情况
- sql耗时
- 端口不通
- 接口调用量
- 接口成功率
- 接口耗时
- 限流情况
- 可以的话,监控压测流量
- 消息情况
你们监控的时候日志平台会监控吗?
只监控日志监控平台服务器性能监控,并实现预警,其他就没有做。
你们会监控数据库的性能吗?会定标准码?有实际遇到过吗,如何解决?
cpu、内存、qps总量、不同类型的sql RT情况、连接数、线程池
写 shell 脚本监控 MySQL 主从的思路
判断 IO 和 SQL 线程是否为 yes。
一、核心监控指标
监控脚本需重点关注以下主从同步状态参数:
- Slave_IO_Running:IO线程是否运行(Yes/No)
- Slave_SQL_Running:SQL线程是否运行(Yes/No)
- Seconds_Behind_Master:主从延迟秒数(0表示无延迟)
- Last_IO_Error/Last_SQL_Error:最近错误信息(故障排查依据)
二、脚本设计要点
1. 防止重复执行
通过进程检查确保每分钟只运行一个监控实例:
# 获取脚本名称并过滤自身进程
s_name=$(basename "$0")
ps aux | grep "$s_name" | grep -v "grep" > /tmp/ps.tmp
p_num=$(wc -l /tmp/ps.tmp | awk '{print $1}')
# 存在未完成的进程则退出
if [ $p_num -gt 0 ]; then
exit 1
fi
2. 主从状态检测
通过 show slave status\G 获取关键参数:
# 连接MySQL获取状态
mysql_cmd="mysql -uroot -ptpH40Kznv"
$mysql_cmd -e "show slave status\G" > /tmp/mysql_slave.log 2>/tmp/mysql_error.log
# 提取关键参数
slave_io=$(grep "Slave_IO_Running:" /tmp/mysql_slave.log | awk '{print $2}')
slave_sql=$(grep "Slave_SQL_Running:" /tmp/mysql_slave.log | awk '{print $2}')
seconds_behind=$(grep "Seconds_Behind_Master:" /tmp/mysql_slave.log | awk '{print $2}')
3. 异常判断逻辑
# 主从状态判断
if [[ "$slave_io" != "Yes" ]] || [[ "$slave_sql" != "Yes" ]] || [[ $seconds_behind -gt 300 ]]; then
send_alert "主从同步异常:IO=$slave_io, SQL=$slave_sql, 延迟=${seconds_behind}s"
fi
4. 告警收敛机制
通过时间戳文件实现30分钟发送间隔:
alert_log="/tmp/mysql_slave_alert.log"
# 检查时间间隔
last_alert_time=$(tail -1 $alert_log 2>/dev/null || echo 0)
current_time=$(date +%s)
if [ $((current_time - last_alert_time)) -gt 1800 ]; then
send_email "admin@admin.com" "MySQL主从异常" "/tmp/mysql_slave.log"
echo $current_time >> $alert_log
fi
三、完整脚本示例
#!/bin/bash
# MySQL主从状态监控脚本 v1.2
# 配置参数
MYSQL_USER="root"
MYSQL_PASS="tpH40Kznv"
ALERT_EMAIL="admin@admin.com"
LOCK_FILE="/tmp/mysql_repl_monitor.lock"
# 防止重复执行
if [ -f $LOCK_FILE ]; then
exit 0
fi
touch $LOCK_FILE
# 获取主从状态
mysql -u$MYSQL_USER -p$MYSQL_PASS -e "SHOW SLAVE STATUS\G" > /tmp/slave_status.log 2>/tmp/mysql_error.log
# 检查MySQL连接状态
if [ $? -ne 0 ]; then
echo "MySQL连接失败!错误日志:" | mail -s "MySQL服务异常" $ALERT_EMAIL
rm -f $LOCK_FILE
exit 1
fi
# 解析关键参数
slave_io=$(grep "Slave_IO_Running:" /tmp/slave_status.log | awk '{print $2}')
slave_sql=$(grep "Slave_SQL_Running:" /tmp/slave_status.log | awk '{print $2}')
delay=$(grep "Seconds_Behind_Master:" /tmp/slave_status.log | awk '{print $2}')
# 状态判断
if [[ "$slave_io" != "Yes" ]] || [[ "$slave_sql" != "Yes" ]]; then
alert_msg="CRITICAL: 主从同步中断!IO线程: $slave_io, SQL线程: $slave_sql"
elif [[ $delay -gt 300 ]]; then
alert_msg="WARNING: 主从延迟超过5分钟,当前延迟: ${delay}秒"
else
alert_msg="OK: 主从同步正常"
fi
# 告警处理
if [[ "$alert_msg" != "OK"* ]]; then
last_alert=$(date -r $LOCK_FILE +%s 2>/dev/null || echo 0)
now=$(date +%s)
if [ $((now - last_alert)) -ge 1800 ]; then
echo "$alert_msg" | mail -s "MySQL主从告警" $ALERT_EMAIL
touch $LOCK_FILE
fi
fi
rm -f $LOCK_FILE
四、部署与测试
-
权限设置
确保运行脚本的用户有MySQL访问权限:GRANT REPLICATION CLIENT ON *.* TO 'monitor'@'localhost' IDENTIFIED BY 'StrongPass123'; -
定时任务配置
通过crontab实现每分钟检测:*/1 * * * * /path/to/mysql_replication_monitor.sh -
测试验证
# 手动停止Slave进程测试 mysql -uroot -p -e "STOP SLAVE;" # 观察脚本是否触发告警
五、增强建议
-
增加心跳表检测
在主库创建心跳表,通过时间戳对比检测同步完整性5:CREATE TABLE replication_heartbeat (id INT PRIMARY KEY, ts TIMESTAMP); INSERT INTO replication_heartbeat VALUES (1, NOW()); -
集成监控系统
将状态数据输出为Prometheus格式,与Grafana集成实现可视化监控9 -
日志轮转机制
使用logrotate管理日志文件,防止磁盘空间耗尽
写 shell 脚本监控所有 IP 是否存活的思路
使用 ping 命令 + for 循环,循环 ping 所有 IP 的列表,能通的就是在线,不能通的就是离线。
公司出口带宽?每天网站 PV?UV?
- 带宽:100M
- PV:100W
- UV:5W
(出口带宽不清楚,以会员业务为例,qpm峰值3k,pv在千万级别)
你们公司的网站出口带宽是多少?网站访问量是多少?是怎么计算的?
我们对外服务器带宽 100M,每天 PV 100 万,UV 大概 2 万。
你们公司是什么架构?都有哪些网上业务?详细说一下?
前端使用 SLB 负载均衡、负载 3 台应用服务器、缓存层使用 Redis、数据库层 MySQL 主从架构。
-
LDC架构
- 按uid进入不同的zone(机房),那就有可能人在深圳,却被路由到河源机房?真实情况是否确实如此?确实如此的。
- 什么是LDC架构?(这就是LDC?、LDC架构概述)
为了解决超大用户体量带来的容量瓶颈以及异地容灾等问题,逐步演进出来的一套分布式系统。分为3种类型的zone:- RZone:可以自包含,原则上用户的一个请求会在本zone内完成,能完成完整的业务动作,请求不会逃逸出本zone;拥有自己的业务数据
- Gzone:部署了不可拆分的数据和服务,这些数据或服务可能会被RZone依赖。GZone在全局只有一组,数据仅有一份。
- Czone:主要是为了解决Rzone频繁调用Gzone的延时问题,相当于Gzone数据的缓存,会频繁被Rzone 访问。
-
LDC路由
客户端发起请求到业务方处理请求一共需要经历三个阶段:- 全局负载均衡到 spanner;
- spanner 负载均衡到 mobilegw;
- mobilegw 请求转发到业务系统。
- 详细过程如下:
全局负载均衡GSLB(DNS)先将请求路由就近的zone的spanner上(地理位置感知:通过DNS解析或Anycast技术),spanner会查看用户请求cookie中的zone 信息:
- 如果有zone信息,spanner自己路由到对应zone 的spanner,然后在路由给对应zone的mgw,然后继续路由server
- 如果没有zone 信息,spinner直接路由给本zone的mgw机器,mgw根据路由规则(可以自定义)通过比对uid路由到对应zone 的mgw,然后继续路由给server;需要注意,该请求返回时会携带zone 信息;当用户后续还有请求时,spanner层读取zone信息自身进行路由
-
目前,mgw网管从中心化逐步变成去中心化,MGW 以 JAR 包(mgw.jar) 形式嵌入业务服务进程,与后端服务同 JVM 运行,减少网络跳转开销,90% 的请求通过本地调用完成,显著降低延迟。
-
另外mgw与mosn深入融合。mgw处理用户到服务端的请求,mosn处理服务与服务直接的调用。
-
蚂蚁未直接使用 Nginx,而是基于自研技术栈(如 Spanner 和 MGW)构建网关体系。早期中心化网关(类似 Nginx)因运维复杂和性能瓶颈,逐步演进为去中心化架构
-
SOFAGW 网关简介
- SOFAGW 是一个跨域通信网关,属于通信中间件,致力于做异构站点间的安全通信。
- 为业务应用提供异构站点间的访问通信,有如下场景:
- 蚂蚁和集团通信。
- 蚂蚁各站点间的通信。
- 蚂蚁站点和金融云站点(公网)通信。
你们公司备份策略是什么?数据量多大?备份周期?备份工具?备份方式?是否做数据恢复备份演练?
我们线上服务器数据库采用数据库逻辑备份 mysqldump 每天进行全量备份,binlog 日志保留 7 天。
我们线上服务器异地也有一套环境就是做灾备用和故障演练用的,xbk 备份或逻辑备份,数据量 500G 大小。
你在工作中是怎么做日志分析的?例如:访问日志、错误日志等
我们公司使用 ELK 日志分析系统做的,日志进行可视化,服务器日志每周备份一次进行日志切割。
我司日志采集
蚂蚁日志系统采用分层架构,包括数据采集层、存储计算层、服务治理层和应用层:
- 数据采集层:通过Logtail(无侵入式日志采集代理)实时收集客户端、服务器、容器及中间件的日志数据,支持多协议接入(如HTTP、RPC)。
- 存储计算层:基于分布式存储(如阿里云日志服务SLS)实现PB级数据的弹性存储,支持多副本冗余、冷热分层及跨地域容灾。
- 服务治理层:提供日志隔离(SOFABoot框架)、动态路由、权限控制及自动化告警功能,确保多租户环境下日志互不干扰。
以下是一个完整的Java应用日志生成、Logtail部署(Kubernetes环境)、SLS配置的全流程示例,结合阿里云日志服务(SLS)体系实现:
一、Java应用生成日志(Logback示例)
// 使用Logback框架
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class DemoController {
private static final Logger logger = LoggerFactory.getLogger(DemoController.class);
public void processRequest() {
logger.info("User login: {}", "user123"); // 结构化日志
logger.error("Payment failed, orderId: {}", 456, new Exception("Timeout"));
// 日志输出到 /var/log/demo/app.log(需配置logback.xml)
}
}
日志配置文件 logback.xml(路径:src/main/resources/)
<configuration>
<appender name="FILE" class="ch.qos.logback.core.FileAppender">
<file>/var/log/demo/app.log</file>
<encoder>
<pattern>%d{yyyy-MM-dd HH:mm:ss} [%thread] %-5level %logger{36} - %msg%n</pattern>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="FILE"/>
</root>
</configuration>
关键点:日志将输出到容器内路径
/var/log/demo/app.log
二、Kubernetes部署Logtail(DaemonSet方式)
部署YAML示例(通过Helm或直接部署):
# 安装Logtail组件(参考阿里云官方Chart)
helm repo add aliyun https://aliacs-app-catalog.oss-cn-hangzhou.aliyuncs.com/charts/
helm install logtail-ds aliyun/logtail --namespace kube-system \
--set project=your-sls-project \
--set region=cn-hangzhou \
--set aliuid="1234567890"
关键配置说明:
- DaemonSet模式:每个K8s节点部署Logtail容器,采集节点上所有Pod的日志
- Sidecar模式(可选):若需采集特定Pod的日志,可在Pod内挂载Logtail容器
三、SLS控制台配置
1. 创建Project与Logstore
- 进入SLS控制台 → 创建Project(如
prod-log) → 新建Logstore(如app-log)
2. 配置机器组
- K8s机器组标识:使用CRD自动生成机器组(如
k8s-group-cluster1),或手动创建用户自定义标识(如my-k8s-group)
3. 创建Logtail采集配置
YAML示例(CRD方式):
apiVersion: log.alibabacloud.com/v1alpha1
kind: AliyunLogConfig
metadata:
name: java-app-log
spec:
logstore: app-log
inputDetail:
type: plugin
plugin:
inputs:
- type: file
detail:
FilePaths: ["/var/log/demo/*.log"] # 容器内日志路径
DockerIncludeEnv: {
"app": "java-demo"} # 过滤特定标签的Pod
控制台配置步骤:
- 数据接入 → Kubernetes-文件 → 选择Project/Logstore
- 日志路径:填写容器内路径
/var/log/demo/*.log - 高级设置 → 开启K8s元数据采集(自动附加Pod名称、命名空间等字段)
四、日志查询与分析
1. 实时查看日志
- 进入Logstore → 查询分析 → 输入查询语句:
level:ERROR | select pod_name, count(1) as error_count group by pod_name
2. 配置仪表盘
- 新建仪表盘 → 添加图表(如错误率趋势图、Top N错误Pod排行)
完整流程总结
Java应用生成日志 → K8s部署Logtail(DaemonSet/Sidecar) → SLS创建Project/Logstore → 配置采集规则 → 实时查询与分析
优势:
- 全托管采集:Logtail自动适配容器动态扩缩容
- 金融级安全:日志加密存储 + RBAC权限控制
- 开箱即用分析:支持SQL语法、TraceID链路追踪
补充解释
1. Logtail采集目录的配置原理
在Kubernetes中,通过Helm部署Logtail的DaemonSet后,采集目录的指定依赖于CRD(CustomResourceDefinition)配置,而非Helm Chart本身的参数。具体流程如下:
- Helm部署Logtail的作用:
Helm Chart主要负责安装Logtail的DaemonSet和控制器(如alibaba-log-controller)。DaemonSet确保每个K8s节点运行一个Logtail容器,用于采集日志[7] [46]。 - CRD定义采集规则:
通过创建AliyunLogConfig类型的CRD资源,明确指定需要采集的日志路径、容器过滤条件等。例如:apiVersion: log.alibabacloud.com/v1alpha1 kind: AliyunLogConfig spec: inputDetail: plugin: inputs: - type: file detail: FilePaths: ["/var/log/demo/*.log"] # 容器内日志路径 DockerIncludeEnv: { "app": "java-demo"} # 仅采集包含此标签的Pod
2. CRD自动生成机器组的机制
**机器组(Machine Group)**是SLS中管理日志采集目标的逻辑单元,CRD方式通过以下步骤自动生成机器组:
- K8s节点标识:
Logtail DaemonSet部署时,每个节点的标识(如节点IP或自定义ID)会自动注册到SLS的机器组中[7] [31]。 - CRD关联机器组:
在AliyunLogConfig中无需显式指定机器组,alibaba-log-controller会自动将CRD配置应用到所有运行Logtail的节点,实现日志采集规则的动态下发[32]。
3. CRD配置的部署位置
CRD配置需部署到业务K8s集群中,具体操作如下:
- YAML文件的应用:
将包含AliyunLogConfig的YAML文件通过kubectl apply命令提交到K8s集群。例如:kubectl apply -f logtail-config.yaml -n your-namespace - 控制器的同步:
alibaba-log-controller会监听CRD资源的变化,自动在SLS中创建对应的Logstore、索引和机器组,无需手动在SLS控制台操作[7] [23]。
4. 完整配置流程示例
- 部署Logtail DaemonSet:
helm repo add aliyun https://aliacs-app-catalog.oss-cn-hangzhou.aliyuncs.com/charts/ helm install logtail-ds aliyun/logtail --namespace kube-system - 创建CRD采集配置(示例文件
app-log.yaml):apiVersion: log.alibabacloud.com/v1alpha1 kind: AliyunLogConfig metadata: name: java-app-log spec: logstore: app-log inputDetail: type: plugin plugin: inputs: - type: file detail: FilePaths: ["/var/log/demo/*.log"] DockerIncludeEnv: { "app": "java-demo"} - 应用配置到集群:
kubectl apply -f app-log.yaml
5. 常见问题解答
- Q:为什么在SLS控制台看不到自动生成的机器组?
A:检查alibaba-log-controller的日志,确保其与SLS的Project地域一致,且RAM权限已正确授予 - Q:如何采集宿主机日志?
A:在CRD中指定宿主机路径(需挂载到Logtail容器),例如/logtail_host/home/logs/app.log
总结
- CRD配置是K8s与SLS集成的核心,通过声明式YAML定义采集规则,实现自动化运维。
- Helm仅部署Logtail组件,具体采集逻辑由CRD控制,两者分工明确。
你们公司日志多久清理一次?
- 设置日志保存时间
- 在SLS控制台中,为每个Logstore(日志库)配置数据保存时间,超期的日志会被系统自动删除。例如:设置保留30天,则31天前的日志将被清理。
- 操作路径:SLS控制台 → 目标Project → Logstore → 修改属性 → 调整“数据保存时间”。
- 数据投递与归档
- 将低频访问的日志投递至OSS(对象存储)或MaxCompute(大数据计算服务),投递后可在SLS中删除原始日志,释放存储空间。
- 适用场景:合规审计、长期备份等需保留日志但无需实时查询的场景。
日志明细数据:7天
监控指标类:30天
金融核心数据:6个月以上
你们公司运维部门有多少人?多少服务器?基本优化项目?
我们现在就我一人,测试环境和生产环境一起是20台服务器,日常系统内核优化
你在上家公司针对防攻击、扩容、容灾等问题是怎么制定和优化解决方案的?
- 防攻击我们公司使用脚本做的实时探测异常ip多次请求,拉黑机制
- 扩容制作运维扩充方法,发送邮件通知有关人员知悉,先写文档,在测试环境测试好后,再正式坏境再做
- 容灾我们公司没有做,我们架构基本都是有高可用。
我司
- 攻防演练
- 日志注入/监控注入:通过接口篡改日志数据,演练监控情况,监控是否配置全面、告警配置是否合理
- 性能类:发起大量请求,攻击cpu、线程等
- GC类:注入大对象,临时性(重启机器可恢复)、持久性(重启不可恢复)
- 网络类:制造丢包等
- 恢复手段:机器重启、机器替换、扩容等
通过蓝军准备的ranger异常module,模拟持续型、缓慢型的OOM或内存使用率飙升。因为ranger module的安装是通过spacestack管控台安装,当集群100%安装异常模块时,重启、替换都会将异常模块激活,导致故障注入,引起系统的不稳定或直接故障。
- 扩容:pass平台调sigma完成扩容,中间还有一层容量管理(目的是控制每个系统的额度)
- 容灾演练
- 业务高峰期容灾演练:不断网,做机房间切流
- 凌晨断网演练:机房断网,做切流
你们公司如何自动化代码上线?
我们公司代码上线使用jenkinstmave.自动构建编译打包推送到应用服务器
如果是手动方法:我们有制定手动代码上线流程
根据流程上线:如果测试环境溯试没有问题时候,使用灰度方法发布上线
linke做dev、线下环境部署
pass做预发、灰度、生产、仿真部署
部署其实就是替换镜像的过程,机器重启,拉取最新的镜像,然后部署
你们公司都有哪些应用集群?
我们公司集群只有 tomcat,Eedis集群,k8s集群等
你们公司用的是物理服务器还是云服务?
阿里云服务器,物理机也有
你们公司安全方面怎么我做的?监控体系结构是怎样的?
- 服务器有外网 ip 全部去掉,采用内网通信除了对外服务器必须对外,只有nginx对外开放外网让
- 关闭密码认证登录服务器,采用秘钥认证登录服务器
- 服务器权限不对外开放
- 利用防火墻和阿里云安全组关闭没必要的对外端口
- jumpservez跳板机使用
- 更改 ssh 端口
如何查看Linux 系统当前的状态,CPU、内存的使用情况及负载
- top
- free -h
- uptime
- Linux 磁盘管理常用三个命令为 df、du 和 fdisk。
- df(英文全称:disk free):列出文件系统的整体磁盘使用量
- du(英文全称:disk used):检查磁盘空间使用量
- du -h 显示当前目录总大小,以及下级目录(文件夹)总大小,不会显示具体文本大小
- du -sh 只显示当前目录总大小
- du -ah 当前目前、下级目录、当前目录中文件、下级目录中文件的大小
写出你所了解的门户网站的服务架构,可用什么方式实现的高可用、负载均衡?
Ivs+keepalived
nginx+keepalived
nginx +tomcat
nginx负责转发和处理静态资源 tomcat 负责动态
Nginx 日志的路径为 /opt/logs/access.logs,假设日志不能自动分割,写脚本让日志每天能够定时自动分割
cp access.logs /tmp/"%Y%m%d".access.logs
echo > access.log
解释:
-
复制日志文件:
cp access.logs /tmp/"%Y%m%d".access.logs这行命令将当前的
access.logs文件复制到/tmp/目录,并以当前日期命名(例如20230915.access.logs)。 -
清空原日志文件:
echo > access.log这行命令会清空原来的
access.log文件,使其成为一个空文件,以便新的日志记录可以继续写入。
完整脚本示例:
#!/bin/bash
# 获取当前日期
current_date=$(date +"%Y%m%d")
# 复制日志文件到临时目录,并以当前日期命名
cp /opt/logs/access.log /tmp/${current_date}.access.log
# 清空原日志文件
echo > /opt/logs/access.log
调度任务:
为了确保这个脚本每天定时执行,可以将其添加到 cron 定时任务中。例如,每天凌晨 0 点执行:
-
打开
crontab编辑器:crontab -e -
添加以下行:
0 0 * * * /path/to/your/script.sh这表示每天凌晨 0 点执行位于
/path/to/your/script.sh的脚本。
Nginx日志按天自动分割配置指南(基于Logrotate)
一、核心方案选择与对比
根据搜索结果,推荐使用logrotate工具实现日志分割,其优势在于:
- 系统级集成:Linux默认安装,与crontab无缝协作
- 功能完善:支持压缩、保留策略、权限控制等高级功能
- 零侵入性:无需修改Nginx配置,通过信号机制实现日志重载
| 方法 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| logrotate | 系统原生支持,功能全面 | 需理解配置文件语法 | 生产环境标准方案 |
| 自定义脚本+crontab | 灵活性高 | 需手动处理压缩、清理等逻辑 | 简单临时方案 |
| Nginx时间变量 | 日志按日期直接生成 | 性能损耗,需修改Nginx配置 | 特殊格式需求场景 |
二、Logrotate标准配置流程(推荐方案)
1. 创建配置文件
sudo vim /etc/logrotate.d/nginx
写入以下内容:
/var/log/nginx/*.log {
daily # 每天轮转<sup>2</sup><sup>5</sup>
missingok # 日志不存在时不报错
rotate 30 # 保留30天历史日志<sup>3</sup>
compress # 启用gzip压缩旧日志
delaycompress # 延迟压缩前一个日志文件<sup>6</sup>
notifempty # 空文件不轮转
create 0640 www-data adm # 新日志权限与属主<sup>5</sup>
sharedscripts # 所有日志处理完执行一次脚本<sup>6</sup>
postrotate
# 向Nginx主进程发送USR1信号重新打开日志
[ -f /var/run/nginx.pid ] && kill -USR1 $(cat /var/run/nginx.pid)
endscript
}
2. 关键参数说明
| 参数 | 作用 | 推荐值 |
|---|---|---|
dateext |
使用日期作为日志后缀(如access.log-20240415) | 建议添加6 |
dateformat .%s |
自定义日期格式 | 需配合dateext使用 |
size |
按大小触发轮转(如size 100M) | 可与daily组合使用 |
olddir |
指定历史日志存储目录 | /var/log/nginx/archive/ |
3. 手动测试配置
# 调试模式(不实际执行)
sudo logrotate -d /etc/logrotate.d/nginx
# 强制执行
sudo logrotate -vf /etc/logrotate.d/nginx
执行后检查:
ls -lh /var/log/nginx/*.gz # 应看到前一天的压缩日志
4. 验证自动执行
系统每日6:25自动运行(可通过以下方式查看):
grep logrotate /etc/crontab
# 输出:25 6 * * * root /usr/sbin/logrotate -s /var/lib/logrotate/status /etc/logrotate.conf
写一个脚本,查找15天前以Png结尾的文件并删除
#!/bin/bash
find /picture/*.png* -type f -mtime +15 -exec rm {
} \;
find /mnt -type f -mtime +15 -name *.png -exec rm {
} \;
参数解释:
-
find:find是一个强大的命令行工具,用于在目录树中查找文件和目录。
-
/picture/*.png*:/picture/:指定要查找的目标路径(即/picture目录)。*.png*:匹配所有以.png开头或结尾的文件名。注意,这里的通配符可能会匹配到不符合预期的文件,因此建议使用更精确的表达式(如*.png)。
-
-type f:- 指定只查找普通文件(
f表示文件)。如果需要查找目录,则可以使用-type d。
- 指定只查找普通文件(
-
-mtime +15:-mtime用于根据文件的修改时间进行匹配。+15表示查找修改时间超过 15 天的文件。+15:表示超过 15 天(不包括第 15 天)。15:表示正好是 15 天。-15:表示少于 15 天。
-
-exec rm {} \;:-exec:对找到的每个文件执行指定的命令。rm {}:{}是一个占位符,表示find找到的每一个文件。rm是删除命令,用于删除文件。
\;:表示-exec的结束标志。\;是转义后的分号,告诉find命令执行到这里结束。
你们为什么使用 Redis?
答:面试官好,我们的数据库主要用的是 MySQL,目前的业务发展设计到高并发场景下的库存扣减,网站首页访问流量高峰等等,数据库已经支撑不住如此高的并发,于是我们引入了缓存中间件,市面上的中间件 redis 和 memcached 我们有在用。我在使用过程中对 redis 和 memcached 做了下对比:
1). redis 相比 memcached 来说拥有更多的数据结构和支持更丰富的数据操作。所以像我们公司设计复杂的结构和操作,我们选择了 redis。
2). 在内存使用效率上做了下对比,单纯使用 key-value 存储的话,memcached 的内存利用率更高,但 redis 采用 hash 结构来做 key-value 存储,由于其组合式的压缩,让内存的利用率高于了 memcached。
3). 在性能上,redis 只使用单核,而 memcached 可以使用多核,所以平均每一个核上的 redis 在存储小数据时比 memcached 性能要高。在使用过程中,有时候也设计到 100K 以上的数据,这个时候,redis 的性能就稍逊于 memcached。
4). 在数据持久化支持上,redis 提供了两种持久化策略,分别是 RDB 快照和 AOF 日志,而 memcached 不支持数据持久化操作。所以综合下来我们选择了 redis。
Redis有哪些数据类型
答:关于Redis的数据类型,我知道的有这么几个:字符串 string,字典 hash,列表 list,集合 set,有序集合 SortedSet。因为公司涉及到高并发,所以还接触过Bloom Filter,以及支持全文搜索的RediSearch等。
Redis 是怎么做持久化的?
答:持久化有两种方式 RDB 和 AOF。RDB 做镜像全量持久化,AOF 做增量持久化。我们公司一般 RDB 和 AOF 会配合起来使用。在 Redis 实例重启的时候,会使用 RDB 持久化文件重构内存,再使用 AOF 存放近期的操作指令来恢复重启前的状态。
当然 Redis 的机制是 AOF 开启且存在 AOF 文件时,优先加载 AOF 文件。AOF 关闭或者 AOF 文件不存在的时候,加载 RDB 文件。
大流量的时候不要开 AOF,开 RDB 即可。
如果服务器突然断电,可以使用 AOF 恢复,AOF 日志有 sync 属性配置,在高性能场景下使用定时 sync,比如 1s1 次,这样即使断电最多丢失 1s 的数据。
redis 集群你们怎么做的?
以下是 Redis 三种典型部署模式的原理与适用场景分析,结合技术实现与典型应用需求进行综合说明:
一、主从模式(Master-Slave)
原理
-
数据同步机制
- 主节点(Master)负责写入操作,从节点(Slave)通过 SYNC 命令 请求全量数据同步,主节点生成 RDB 快照 并通过缓冲区记录增量写命令,依次发送给从节点完成数据复制
- 后续增量同步通过 命令传播(Command Propagate) 实现,主节点将写命令实时发送给从节点
-
读写分离
- 主节点处理读写请求,从节点仅支持读请求,有效分散读负载
适用场景
- 中小型业务:适用于数据量较小、读多写少的场景,如静态资源缓存、低频查询服务。
- 数据备份:通过从节点实现数据冗余,防止单点数据丢失。
- 缺点:主节点故障需手动切换,存在服务中断风险
二、主从+哨兵模式(Sentinel)
原理
-
哨兵监控机制
- 哨兵(Sentinel)集群通过 心跳检测(PING-PONG) 监控主从节点健康状态,半数以上哨兵判定主节点下线时触发 故障转移(Failover)
-
自动选举新主
- 优先选择数据最新的从节点(基于 复制偏移量),若偏移量相同则按 节点优先级 或 运行ID 升序选举新主节点
适用场景
- 高可用需求:如电商订单系统、实时消息队列,需自动容灾恢复。
- 监控告警:哨兵支持故障通知,适用于需实时掌握集群状态的场景。
- 缺点:存储容量受单节点限制,扩容需手动调整
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 1824
1824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











