







1.EXPLAIN 要常用

id :
Id值相同,从上往下顺序执行,t-tc-c
表的执行顺序因数据数量的改变而改变的原因:笛卡尔积
数据小的表优先查询
Id值不同:越大越优先执行(本质:在嵌套子查询时,先查内层,再查外层)
Select_type:
Primary:包含子查询的主查询(最外层)
Subquery:包含子查询的子查询(非最外层)
Simple:简单查询(不包含子查询、union)
Derived:衍生查询(用到了临时表)
A.在from子查询中只有一张表
select c.name from( Select * from course where tid in (1,2))as c
B.在from子查询中,如果有table1 union table2,则table1就是derived
Union
Union result
Type(索引类型)
System>const>eq_ref>ref>range>index>all 从左到右性能越来越低
其中system和const只是理想状态, 实际的只是ref和range
System:只有一条数据的系统表或衍生表只有一条数据的主查询
Const: 仅仅能查到一条数据的sql,用于primary_key 或unique索引(类型与索引类型有关)
Eq_ref:唯一性索引,对于每个索引键的查询,返回匹配唯一行数据(有且只有一个,不能多,不能0)
Ref
非唯一性索引,对于每个索引键的查询,可以有0或多行数据
Range
检索指定范围的行,where后面是一个范围查询(between,in…)
In的范围查询会失效变为all
Index
:查询全部索引中的数据
All
:查询全部表中的数据
Possible_keys
可能用到的索引,是一种预测
Key
实际使用到的索引
Key_length
索引的长度,用于判断复合索引是否被完全使用
Char不为null加粗样式

char 可以为null

复合索引

Varchar为null

Ref
作用:指明当前表所参照的字段

Rows:
被索引优化查询的数据个数(实际通过索引查询到的数据个数)
Extra
Using filesort:
性能消耗比较大,需要额外一次查询或排序,常出现在order by语句中
小结:对于单索引,如果排序和查询是一个字段就不会出现using filesort ,如果查询和排序不是同一个字段就会出现using filesort
复合索引:不能跨列(最佳左前缀)

Using temporary:
性能损耗大,用到临时表,一般出现在group by 语句中
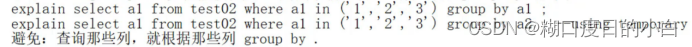
Using index


Using where 需要回原表查询

Impossible where 该where语句为false

A1不可能既等于x又等于y
复合索引
Alter table test03 add index index_a1_a2_a3_a4(a1,a2,a3,a4)

上面第一种写法推荐,以上俩sql都使用了全部的复合索引
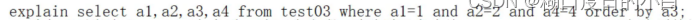
A1和a2是有效索引,不需要回表查询using index,而a4属于跨列使用,造成索引失效,using where,a3也是有效索引,没有跨列

不要跨列使用 where order by
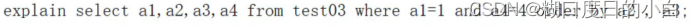
不会using filesort ,只是a4索引失效会回表查询
注意:同时存在联合索引和单列索引(字段有重复的),这个时候查询mysql会怎么用索引呢?
这个涉及到mysql本身的查询优化器策略了,当一个表有多条索引可走时, Mysql 根据查询语句的成本来选择走哪条索引;
有人说where查询是按照从左到右的顺序,所以筛选力度大的条件尽量放前面。网上百度过,很多都是这种说法,但是据我研究,mysql执行优化器会对其进行优化,当不考虑索引时,where条件顺序对效率没有影响,真正有影响的是是否用到了索引!
1.避免使用select *
2.用union all代替union
3.小表驱动大表
小表驱动大表,也就是说用小表的数据集驱动大表的数据集。
假如有order和user两张表,其中order表有10000条数据,而user表有100条数据。
这时如果想查一下,所有有效的用户下过的订单列表。
可以使用in关键字实现:
select * from order
where user_id in (select id from user where status=1)
也可以使用exists关键字实现:
select * from order
where exists (select 1 from user where order.user_id = user.id and status=1)
前面提到的这种业务场景,使用in关键字去实现业务需求,更加合适。
为什么呢?
因为如果sql语句中包含了in关键字,则它会优先执行in里面的子查询语句,然后再执行in外面的语句。如果in里面的数据量很少,作为条件查询速度更快。
而如果sql语句中包含了exists关键字,它优先执行exists左边的语句(即主查询语句)。然后把它作为条件,去跟右边的语句匹配。如果匹配上,则可以查询出数据。如果匹配不上,数据就被过滤掉了。
这个需求中,order表有10000条数据,而user表有100条数据。order表是大表,user表是小表。如果order表在左边,则用in关键字性能更好。
总结一下:
in 适用于左边大表,右边小表。
exists 适用于左边小表,右边大表。
不管是用in,还是exists关键字,其核心思想都是用小表驱动大表。
4.多用limit
5.SQL查找是否"存在",别再count了
6.in中值太多
如果我们不做任何限制,该查询语句一次性可能会查询出非常多的数据,很容易导致接口超时。
可以在sql中对数据用limit做限制。
public List<Category> getCategory(List<Long> ids) {
if(CollectionUtils.isEmpty(ids)) {
return null;
}
if(ids.size() > 500) {
throw new BusinessException("一次最多允许查询500条记录")
}
return mapper.getCategoryList(ids);
}
如果ids超过500条记录,可以分批用多线程去查询数据。每批只查500条记录,最后把查询到的数据汇总到一起返回。
不过这只是一个临时方案,不适合于ids实在太多的场景。因为ids太多,即使能快速查出数据,但如果返回的数据量太大了,网络传输也是非常消耗性能的,接口性能始终好不到哪里去。
7.7 增量查询
有时候,我们需要通过远程接口查询数据,然后同步到另外一个数据库。
select * from user
where id>#{lastId} and create_time >= #{lastCreateTime}
limit 100;
按id和时间升序,每次只同步一批数据,这一批数据只有100条记录。每次同步完成之后,保存这100条数据中最大的id和时间,给同步下一批数据的时候用。
通过这种增量查询的方式,能够提升单次查询的效率。
8 高效的分页
有时候,列表页在查询数据时,为了避免一次性返回过多的数据影响接口性能,我们一般会对查询接口做分页处理。
在mysql中分页一般用的limit关键字:
select id,name,age
from user limit 10,20;
如果表中数据量少,用limit关键字做分页,没啥问题。但如果表中数据量很多,用它就会出现性能问题。
比如现在分页参数变成了:
select id,name,age
from user limit 1000000,20;
mysql会查到1000020条数据,然后丢弃前面的1000000条,只查后面的20条数据,这个是非常浪费资源的。
那么,这种海量数据该怎么分页呢?
优化sql:
select id,name,age
from user where id > 1000000 limit 20;
先找到上次分页最大的id,然后利用id上的索引查询。不过该方案,要求id是连续的,并且有序的。
还能使用between优化分页。
select id,name,age
from user where id between 1000000 and 1000020;
需要注意的是between要在唯一索引上分页,不然会出现每页大小不一致的问题。
9 用连接查询代替子查询
mysql中如果需要从两张以上的表中查询出数据的话,一般有两种实现方式:子查询 和 连接查询。
select * from order
where user_id in (select id from user where status=1)
子查询语句可以通过in关键字实现,一个查询语句的条件落在另一个select语句的查询结果中。程序先运行在嵌套在最内层的语句,再运行外层的语句。
子查询语句的优点是简单,结构化,如果涉及的表数量不多的话。
但缺点是mysql执行子查询时,需要创建临时表,查询完毕后,需要再删除这些临时表,有一些额外的性能消耗。
这时可以改成连接查询。具体例子如下:
select o.* from order o
inner join user u on o.user_id = u.id
where u.status=1
10 join的表不宜过多
根据阿里巴巴开发者手册的规定,join表的数量不应该超过3个
select a.name,b.name.c.name,d.name
from a
inner join b on a.id = b.a_id
inner join c on c.b_id = b.id
inner join d on d.c_id = c.id
inner join e on e.d_id = d.id
inner join f on f.e_id = e.id
inner join g on g.f_id = f.id
如果join太多,mysql在选择索引的时候会非常复杂,很容易选错索引。
并且如果没有命中中,nested loop join 就是分别从两个表读一行数据进行两两对比,复杂度是 n^2。
所以我们应该尽量控制join表的数量。
select a.name,b.name.c.name,a.d_name
from a
inner join b on a.id = b.a_id
inner join c on c.b_id = b.id
如果实现业务场景中需要查询出另外几张表中的数据,可以在a、b、c表中冗余专门的字段,比如:在表a中冗余d_name字段,保存需要查询出的数据。
不过我之前也见过有些ERP系统,并发量不大,但业务比较复杂,需要join十几张表才能查询出数据。
所以join表的数量要根据系统的实际情况决定,不能一概而论,尽量越少越好。
11 join时要注意
我们在涉及到多张表联合查询的时候,一般会使用join关键字。
而join使用最多的是left join和inner join。
left join:求两个表的交集外加左表剩下的数据。
inner join:求两个表交集的数据。
使用inner join的示例如下:
select o.id,o.code,u.name
from order o
inner join user u on o.user_id = u.id
where u.status=1;
如果两张表使用inner join关联,mysql会自动选择两张表中的小表,去驱动大表,所以性能上不会有太大的问题。
使用left join的示例如下:
select o.id,o.code,u.name
from order o
left join user u on o.user_id = u.id
where u.status=1;
如果两张表使用left join关联,mysql会默认用left join关键字左边的表,去驱动它右边的表。如果左边的表数据很多时,就会出现性能问题。
要特别注意的是在用left join关联查询时,左边要用小表,右边可以用大表。如果能用inner join的地方,尽量少用left join。
12 控制索引的数量
众所周知,索引能够显著的提升查询sql的性能,但索引数量并非越多越好。
因为表中新增数据时,需要同时为它创建索引,而索引是需要额外的存储空间的,而且还会有一定的性能消耗。
阿里巴巴的开发者手册中规定,单表的索引数量应该尽量控制在5个以内,并且单个索引中的字段数不超过5个。
mysql使用的B+树的结构来保存索引的,在insert、update和delete操作时,需要更新B+树索引。如果索引过多,会消耗很多额外的性能。
那么,问题来了,如果表中的索引太多,超过了5个该怎么办?
这个问题要辩证的看,如果你的系统并发量不高,表中的数据量也不多,其实超过5个也可以,只要不要超过太多就行。
但对于一些高并发的系统,请务必遵守单表索引数量不要超过5的限制。
那么,高并发系统如何优化索引数量?
能够建联合索引,就别建单个索引,可以删除无用的单个索引。
将部分查询功能迁移到其他类型的数据库中,比如:Elastic Seach、HBase等,在业务表中只需要建几个关键索引即可。
13 选择合理的字段类型
char表示固定字符串类型,该类型的字段存储空间的固定的,会浪费存储空间。
varchar表示变长字符串类型,该类型的字段存储空间会根据实际数据的长度调整,不会浪费存储空间。
我们在选择字段类型时,应该遵循这样的原则:
能用数字类型,就不用字符串,因为字符的处理往往比数字要慢。
尽可能使用小的类型,比如:用bit存布尔值,用tinyint存枚举值等。
金额字段用decimal,避免精度丢失问题。
14 提升group by的效率
我们有很多业务场景需要使用group by关键字,它主要的功能是去重和分组。
通常它会跟having一起配合使用,表示分组后再根据一定的条件过滤数据。
select user_id,user_name from order
group by user_id,user_namr
having user_id <= 200;
这种写法性能不好,它先把所有的订单根据用户id分组之后,再去过滤用户id大于等于200的用户。
分组是一个相对耗时的操作,为什么我们不先缩小数据的范围之后,再分组呢?
正例:
select user_id,user_name from order
where user_id <= 200
group by user_id,user_name
使用where条件在分组前,就把多余的数据过滤掉了,这样分组时效率就会更高一些















 454
454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









