







这几天写存储过程,有很多次需要先将大致符合条件的数据查出来,放到临时表中。再根临时表中的数据进行更新操作。
期间用到了IN和EXISTS,想知道这两种匹配操作,哪个效率更高一些。
下面两张图是用自己机器上的数据进行的测试:
数据库类型:MySQL
使用IN的时候,
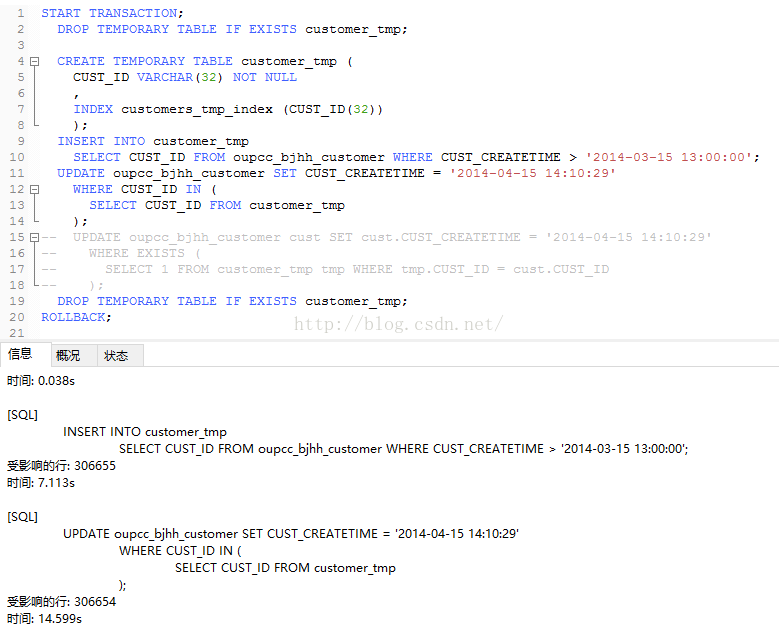
使用EXISTS
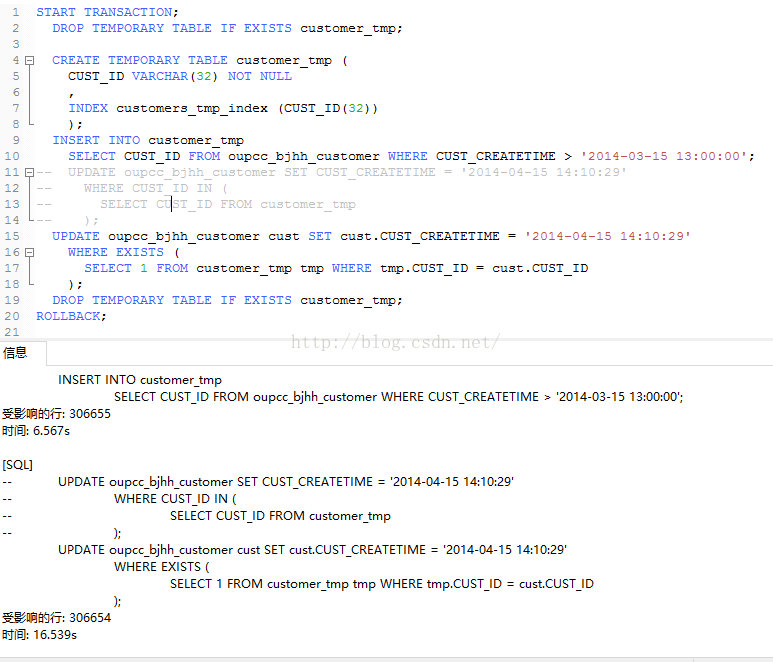
两个放一块,
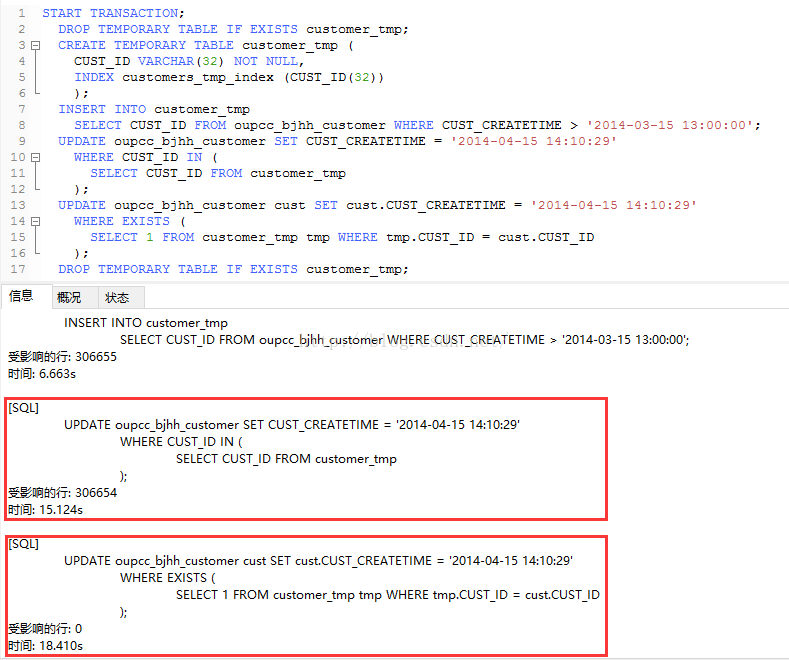
一目了然~了然师兄
注意哈,临时表的CUST_ID我加了索引,如果不加索引,会相当慢,慢到我连等都不想等了。就是说在不加索引的时候,我还没见过他执行完。。。
创建表的时候可以选择引擎,不知道叫存储引擎还是数据库引擎还是数据库表引擎。
反正如果存储在设置为存储在内存的话会更快。当时数据到30w的时候,提示内存不够用了。
上网查了一下,可以修改MAX_HEAP_TABLE_SIZE,MAX_HEAP_TABLE_SIZE默认是16M,修改:
SET MAX_HEAP_TABLE_SIZE = 1024 * 1024 * 100; -- 这样内存就会调整为100M了
这个值好像是在mysql的配置文件中设置的,如果在在SQL代码块中修改了,只有在重启MySQL后才会重置为原来配置的参数。
所以,如果临时调整这个值,最好在用完之后手动重置为原来的值。
好了,就是这些。
PS:写SQL的时候用大写感觉很吊!















 1694
1694

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









