







这两天在玩一个新开源模型,阿里通义实验室做的,叫 LHM。
它解决的问题其实很明确:从单张图像还原出可动画的人体模型。
这个方向不是新鲜事,业内做3D人体重建的项目一直不少。但 LHM 的效果和使用体验,确实让我觉得,它对内容创作者这个群体来说,有点意思。
所以简单写一下我使用后的观察,不宣传、不唱高调,分享一些实际的感受和可能的落点。
单图 → 可动3D人形:真的快、也真的能用
LHM 最大的特点,在于“轻”:
-
输入只需要一张图,不需要视频,不需要多角度数据
-
输出是可驱动的3D人体模型,也就是说,它不是一张3D图,而是能绑定动作、可以动起来的数字人
-
整个流程几秒内完成,前馈式结构,无需优化器那种反复迭代
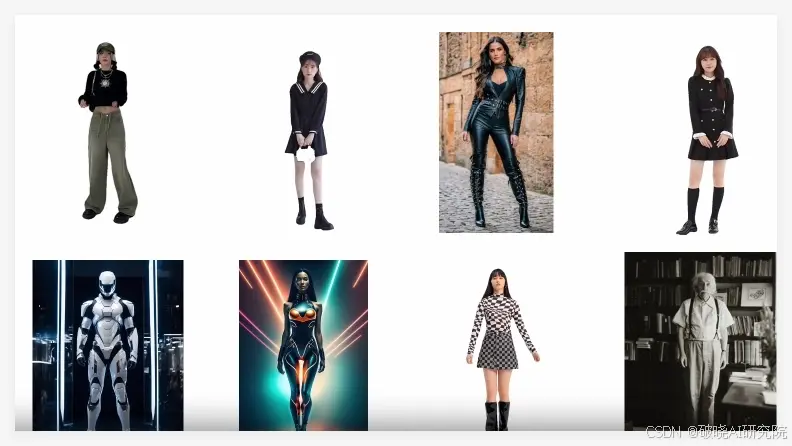
目前在 Hugging Face 上已经可以在线体验,我试了几张普通的半身照,不挑角度、不挑背景,也没有复杂设置,默认参数直接跑。
出来的模型结构清晰,衣服的纹理、人体比例、头部五官这些还原得不错,支持旋转查看,有实时渲染效果,整体是非常利落的建模结果。
在我试过的众多3D人体模型里,LHM 是少数让我觉得“即使不是技术人员也能直接落地”的那个。
下面是官方的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









