







前言
volatile是jvm用于保证变量的可见性和防止代码重排序而推出的解决方案, 但其如何实现的这两项功能一直不是特别的清楚, 各种书籍博客干燥的知识点无法上下联系清楚, 无法联系清楚知识点那么又很容易忘记它, 这篇文章将自底向上的分析怎么实现的volatile
本文假设一个
cpu一个核心吧
前置知识
你事先得了解的知识点, 如果你已经了解了, 可以选择跳过一部分
cpu缓存结构
是什么?
cpu实现的一、二级私有缓存, 三级跨cpu共享缓存结构(一般情况, 有些cpu存在四级缓存等情况)

从图中可以分析出, 核心附近是一级缓存接着到二级三级最后到内存
为什么需要缓存?
cpu的执行速度相较于内存的速度是非常快的, 当内存成为瓶颈时,
- 要不找个速度更快的东西替换内存(大概率不计成本, 方便程序员, 就是贵)
- 要不就找个小一点的缓冲带, 去缓冲频繁的读取(成本稍微便宜点的方案, 更加复杂了)几种实现方案
而cpu核心的多级缓存结构便是成本问题导致, 既要提高cpu的执行效率有的考虑成本, 自然就显的更加复杂了
如果不考虑成本, 直接丢掉内存, 搞个大一点的一级缓存便可, 网上很多人都说一级缓存大, cpu操作一级缓存的速度就越慢, 其实可以在每个缓存单元都加上比较器, 对于速度不会有太大的影响
但你真的以为就这样??? 来张更详细一点的图片看看

发现了没??? 这张图在cpu核心(后面都叫core吧)和缓存之间还隔着几个东西
还是那两个方案的后者, 一级缓存速度已经够了, 但是如果不加上load buffer、store buffer和wcbuffers, 你会发现core和一级二级甚至是三级缓存存在着实时同步性
这种方式存在什么问题呢???
我们知道, 如果一次打印一个字符, 你会发现速度很慢, 但是如果把这个字符先放入一个队列或者字符串中, 一次打印, 你就会发现速度极快
对于文本流的操作也一样, 每次一行一行的打印, 速度不是很快, 但如果一次读取一个合适大小的字符数组时, 你会发现效率绝对比你一次一次打印的速度要快
那么回到core和缓存之间呢?
就有一点类似于这种方式, 但实际上远不止这些, 出现load buffer 和store buffer这种缓冲区后, core就多出了异步操作缓存的空间, core可以将自己的读写方式分别存放到各种的缓冲区, 此时core就可以不用等待缓存的更新直接做别的事情, 然后找个时间将其一次性存入缓存即可, 这种方式便诞生了第一个问题__ [1] __
__[1]: __
- 如果当前
buffer中存在cpu后续需要写入的数据, 则会出现问题 – 使用屏障解决, 在发生屏障, 清空store buffer, 然后再开始写入 - 那需要读取的数据呢? 先从
buffer开始找然后到缓存中找
你以为上面那张图就完整了??? 再来一张
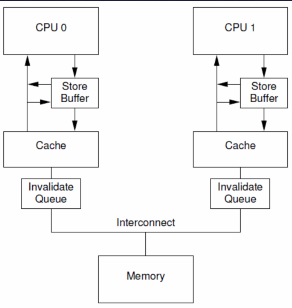
发现了么??? 多了个invalidate queue失效队列!!!这又是干嘛用的???
在core修改缓存时, 他会发出失效消息给其他core, 其他core需要反馈ack响应后, core才能够发现开始写入, 但是跨核发送消息和等待反馈的效率太低了, 当前core需要等待其他core的反馈, 这其他core处理失效消息和反馈的过程很慢, 这时, invalidate queues出现了, 它可以存放这些失效消息, 在合适的时候给他处理掉, 其他core只要把这个消息放入失效队列就立即可以反馈ack了, 这样即使当前core还会阻塞, 那时间也比没有失效队列来的快
这就是invalidate的价值
至于看这里write combine buffer
考虑到有些人无法访问, 我贴一点
Write combining (WC[1]) is a computer bus technique for allowing data to be combined and temporarily stored in a buffer – the write combine buffer (WCB) – to be released together later in burst mode instead of writing (immediately) as single bits or small chunks.
Write combining cannot be used for general memory access (data or code regions) due to the weak ordering. Write-combining does not guarantee that the combination of writes and reads is done in the expected order. For example, a Write/Read/Write combination to a specific address would lead to the write combining order of Read/Write/Write which can lead to obtaining wrong values with the first read (which potentially relies on the write before).
In order to avoid the problem of read/write order described above, the write buffer can be treated as a fully associative cache and added into the memory hierarchy of the device in which it is implemented.[2] Adding complexity slows down the memory hierarchy so this technique is often only used for memory which does not need strong ordering (always correct) like the frame buffers of video cards.
上面这段话大概的介绍了下WCB, 我就不再详述了
什么情况下缓存行刷新到主存?
在一个cpu中存在多个core, 这些核心在找不到缓存时, 从其他核心或者直接从主存中加载变量到缓存中, 但加载完毕后, 什么时候刷新到主存中呢???
我们不了解核心和主存之间的问题, 但了解多线程修改共享变量时的关系
你会发现在多线程下, 如果共享变量不添加volatile关键字, 那么这个变量将在各自的线程独有一份, 仅在第一次使用时加载一次这个变量, 其后续操作都在线程自己的副本中进行, 直到遇到内存屏障或者创建了个新的引用对象等情况(有些还特奇葩比如final字段被初始化, 不过final字段内部也是有内存屏障的)
那么同样的情况在核心之间估计也是差不多的, 比如遇到内存屏障, 至于创建引用对象, 我估计不行, 但如果原本存储在缓存中的变量在将被从缓存中踢出的前提下, 它将被刷新回主存中
缓存行
我们操作一些东西都需要定义一个单位以提高其管理的效率或者定义一个原子操作, 比如cpu每次读取内存以块为单位, 一块一块的读取(内存对齐的原因), 固态硬盘4k对齐, 都需要区分出一个单位来, 而缓存也一样
缓存的单位是叫缓存行(cache line)的东西, 每行缓存行大小一般为8byte, 64bit(一般情况下)
缓存行伪共享
经常会在一些高性能并发框架Disruptor博客会看到这样一段代码:
long p1, p2, p3, p4, p5, p6, p7; // 无用字段填充 7 * 8bit
volatile long val; // 8 bit 总计: 56 + 8 == 64 bit
- 为什么要用无用字段填充满一个缓存行呢?
其目的就是要让val独自在一行, 要说这样做的目的, 不得不说一说一个新的概念, 叫缓存行伪共享

上图中,一个运行在处理器 core1上的线程想要更新变量X 的值,同时另外一个运行在处理器core2上的线程想要更新变量 Y的值。但是,这两个频繁改动的变量都处于同一条缓存行。两个线程就会轮番发送 RFO消息,占得此缓存行的拥有权。当 core1 取得了拥有权开始更新 X,则 core2 对应的缓存行需要设为I 状态。当 core2 取得了拥有权开始更新 Y,则 core1 对应的缓存行需要设为 I 状态(失效态)。轮番夺取拥有权不但带来大量的 RFO 消息,而且如果某个线程需要读此行数据时,L1 和 L2 缓存上都是失效数据,只有 L3 缓存上是同步好的数据。但读 L3 的数据非常影响性能。更坏的情况是跨槽读取,L3 都要 miss,只能从内存上加载。
表面上 X 和 Y都是被独立线程操作的,而且两操作之间也没有任何关系。只不过它们共享了一个缓存行,但所有竞争冲突都是来源于共享。
内存屏障
前面__[1]: __的地方存在一个屏障问题, 我们来仔细研究研究它
首先它有以下几种类型:
- store 对应的指令
sfence, 将store buffer中的数据刷新到缓存, 并强制更新到主存中, core不会对其进行重排序 - load 对应的指令
lfence, 刷新invalidate queue和load buffer到缓存中, 并强制读取主存的数据到缓存中. 防止指令重排序 - full 对应的指令
mfence, 先刷新store buffer中的数据到缓存中, 并强制更新到主存中, 并刷新掉invalidate queue和load buffer到缓存中, 强制读取主存中的值到缓存中, 还能够防止core对指令的重排序
但实际上, jvm并不会使用到 lfence 、sfence和mfence, 原因是, 这三个指令效率不是很快, 而且并不是所有的core都支持这三个指令
看volatile底层实现就知道
OrderAccess::storeload();
// linux_x86.cpp
inline void OrderAccess::fence() {
if (os::is_MP()) {
// always use locked addl since mfence is sometimes expensive
#ifdef AMD64
__asm__ volatile ("lock; addl $0,0(%%rsp)" : : : "cc", "memory");
#else
__asm__ volatile ("lock; addl $0,0(%%esp)" : : : "cc", "memory");
#endif
}
}
看上面的这段英文: always use locked addl since mfence is sometimes expensive
使用的是Lock前缀指令方案, 而非那三个指令, 使用的还是锁总线或者锁缓存方案
java内存模型
JMM 即 Java Memory Model,它定义了主存、工作内存抽象概念,底层对应着 CPU 寄存器、缓存、硬件内存、
CPU 指令优化等。
JMM 体现在以下几个方面
- 原子性 - 在JMM中, 用于标记java一行或者多行指令的原子性, 多行包装成一个不可分割的代码块, 不会受到多线程的影响, 保证了多线程在这块代码块是单线程指令的
- 可见性 - 在JMM中表示, 标记了一个变量, 此变量在读写之间都要与主存做同步更新, 说白了保证缓存和主存之间的数据一致, 你改了缓存就得同步到主存, 读取了缓存, 就得先将主存的值copy到缓存中再读取
- 有序性 - 保证指令不会受 cpu 指令并行优化的影响, 不会出现明明先赋值的a后赋值的b, 出现了先赋值b后赋值a的情况

主存和工作内存
主存是我们的内存, 但工作内存就不好说了, 它是一个抽象的概念, 其中组成有缓存, 寄存器, 写缓冲和其他硬件或者jit的优化等抽象成工作内存的
而在整个主存到工作内存到线程的关系看这张图(不是本篇重点, 可以看这篇文章)

这种工作内存和主存方案存在严重的延迟问题, 这导致时常core1修改了变量, core2根本发现不了, 相当于一个变量被拷贝了多份变量, 每份变量都是独立的, 需要使用特殊的手段才能够发现比如内存屏障
大概的了解java内存模型, 我们就可以来总结下volatile关键字
volatile的功能
volatile底层实现使用的方案是lock前缀指令, 说到底还是锁的方式实现
所以他的功能有两个:
- 主存和工作内存的同步更新
- 防止代码重排序
java的volatile内存屏障语义
为了实现volatile的内存屏障, 编译器在生成字节码时会在指令序列中插入内存屏障来实现上面的两个功能, 但对于编译器来说,发现一个最优布置来最小化插入屏障的总数几乎不可能。为此,JMM采取保守策略
StoreStore: 在volatile指令修饰的变量被写之前插入StoreStore内存屏障StoreLoad: 在volatile指令修饰的变量被写之后插入StoreLoad内存屏障LoadLoad: 在volatile指令修饰的变量被读之前插入LoadLoad内存屏障StoreLoad: 在volatile指令修饰的变量被读之后插入StoreLoad内存屏障
但我喜欢另一种叫法, 有存储器命名的另一种方式
Release BarrierStore BarrierAcquire BarrierLoad Barrier
通常Release Barrier和Store Barrier配合使用
Release Barrier的功能表示: 屏障的处理要晚于它之前代码的操作, 意思是说发生屏障操作时, 前面的代码必须先执行完毕才能够执行屏障之后的代码, 保证了指令的顺序执行, 防止指令重排序
Store Barrier的作用: 刷新掉高速缓存 同时将core的修改同步到其他core和主存中
Acquire Barrier的作用: 屏障处理完毕后才能够执行其后面的代码, 防止其后面的指令重排序到屏障之前
Load Barrier的作用: 刷新掉高速缓存, 加载主存中的变量到缓存中
在列举一个例子
private volatile int a = 0;
int x = 100;
// 防止前面的代码和屏障重排
// Release Barrier
a = 10; // 写入到volatile变量中
// Store Barrier 此行前面的所有不论是volatile变量还是普通变量的写入都会写入到主存中
// Load Barrier, 此行后面的所有普通还是volatile变量的读取都将从主存中读取
int b = a; // 这里的 a 是最新的值
// Acquire Barrier
// 防止后面的代码重排序到主存前面
虽然上面的代码注释是这样子说, 但实际测试结果更符合StoreStore, StoreLoad, LoadLoad和StoreLoad这种方式
我们给个例子看看
public class VolatileDemo {
private static boolean b = false;
public static void main(String[] args) throws Exception {
ExecutorService threadPool = Executors.newFixedThreadPool(4);
threadPool.submit(() -> {
while (!b) {
}
System.out.println("线程A退出前打印");
});
TimeUnit.SECONDS.sleep(1);
threadPool.submit(() -> {
b = true;
});
threadPool.shutdown();
}
}
上面这段代码由于变量b并未添加volatile关键字, 所以他在不同的线程是不同的备份, 不同线程对自己备份的修改不会和其他线程有任何的影响, 甚至是主存中的变量也不会有任何的影响, 除非遇到屏障操作, 或者new了个包装类 又或者当前变量即将被从core核心中被替换删除掉的时
看看例子加深影响
volatile变量读之前的普通变量读对于其他线程可见, 看代码例子:
public class ReadVolatileReadDemo {
private static volatile int vol = 0;
private static boolean b = false;
public static void main(String[] args) throws Exception {
ExecutorService threadPool = Executors.newFixedThreadPool(4);
threadPool.submit(() -> {
sleep(100);
b = true;
while (true);
});
threadPool.submit(() -> {
sleep(200);
int x = 0;
int a = 0;
while (!b) {
a++;
x = vol; // volatile变量读之前的普通读是有效的
}
System.out.println("线程退出...a = " + a); // 线程退出...a = 0
});
threadPool.shutdown();
}
private static void sleep(long timeout) {
try {
TimeUnit.MILLISECONDS.sleep(timeout);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
通过上面的测试发现, 读取volatile变量之后的所有普通变量读取都是从主存中读取出来的
写volatile之前的普通变量读对于其他线程不可见, 看下面代码
private static volatile int a = 0;
private static boolean b = false;
threadPool.submit(() -> {
sleep(100);
int k = 0;
b = true;
while (true) {
k++;
}
});
threadPool.submit(() -> {
while (!b) {
a++; // 写volatile之前的普通读是无效的
}
System.out.println("线程退出...a = " + a); // 线程退出...a = 13903934
});
写volatile之后的普通变量读对于其他线程可见, 看代码:
private static volatile int a = 0;
private static boolean b = false;
threadPool.submit(() -> {
sleep(100);
int k = 0;
b = true;
while (true) {
k++;
}
});
threadPool.submit(() -> {
sleep(200);
boolean c = b;
a++; // 写volatile之后的普通读是有效的
while (!b) {
}
System.out.println("线程退出...a = " + a); // 线程退出...a = 1
System.out.println("c = " + c);
});
看到这里就和上面讲到的Store Barrier和Load Barrier讲的差不多
写volatile主要看前面, 前面的普通读/写是直接从主存中读取的
读volatile主要看后面, 后面的普通读/写直接操作的主存














 6843
6843











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









