









 本文介绍了一种预测微博互动(转发、评论、点赞)的方法。通过对用户历史数据的统计分析,提取了每位用户的互动特征,利用这些特征对新发布的微博互动数量进行预测。实验表明,采用中位数作为预测依据的效果最佳。
本文介绍了一种预测微博互动(转发、评论、点赞)的方法。通过对用户历史数据的统计分析,提取了每位用户的互动特征,利用这些特征对新发布的微博互动数量进行预测。实验表明,采用中位数作为预测依据的效果最佳。
竞赛题目*
对于一条原创博文而言,转发、评论、赞等互动行为能够体现出用户对于博文内容的兴趣程度,也是对博文进行分发控制的重要参考指标。本届赛题的任务就是根据抽样用户的原创博文在发表一天后的转发、评论、赞总数,建立博文的互动模型,并预测用户后续博文在发表一天后的互动情况。
天池官方请移步:新浪微博互动预测
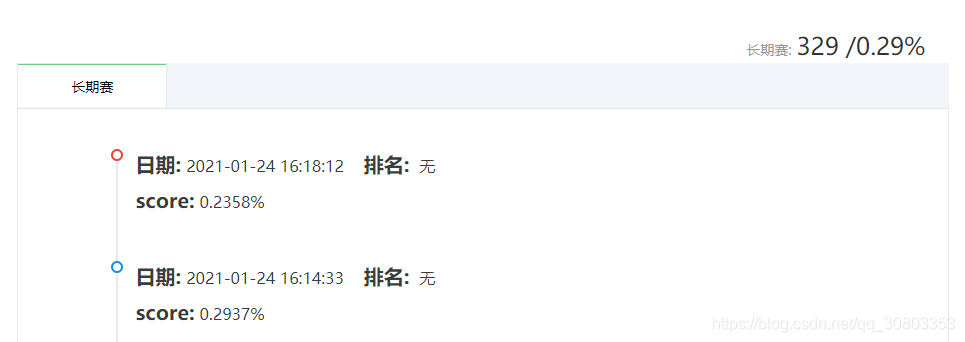
0.2937%的代码:
具体思路:
- 加载数据
- 计算统计特征(如平均值、中位数),统计每一个用户的分享数、评论数、点赞数
- 将每一行数据都存储到字典中,用于线性时间搜索
- 获取每个uid的统计信息
- 对固定UID值的测试数据进行预测,生成提交文件
"""
大约80%的训练数据是:0(向前数,评论数,点赞数),
受此启发,我们为所有uid尝试一些固定值,并计算他们在训练数据上的得分:
另一个明智的解决办法是分别用uid的统计数据(如平均值、中位数)进行预测
中位数效果最好
"""
import pandas as pd
import os
os.chdir(r'E:\项目文件\天池比赛\微博互动预测\Weibo Data')
def loadData():
traindata = pd.read_csv("weibo_train_data.txt", header=None, sep='\t')
traindata.columns = ["uid", "mid", "date", "forward", "comment", "like", "content"]
testdata = pd.read_csv("weibo_predict_data.txt", header=None, sep='\t')
testdata.columns = ["uid", "mid", "date", "content"]
return traindata, testdata
# 统计每一个用户的分享数、评论数、点赞数
def genUidStat():
traindata, _ = loadData()
train_stat = traindata[['uid', 'forward', 'comment', 'like']].groupby('uid').agg(['min', 'max', 'median', 'mean'])
train_stat.columns = ['forward_min', 'forward_max', 'forward_median', 'forward_mean',
'comment_min', 'comment_max', 'comment_median', 'comment_mean',
'like_min', 'like_max', 'like_median', 'like_mean']
train_stat = train_stat.apply(pd.Series.round)
# 存储到字典中,用于线性时间搜索
stat_dic = {}
for uid, stats in train_stat.iterrows():
stat_dic[uid] = stats # type(stats) : pd.Series
return stat_dic
def predict_with_stat(stat="median"):
stat_dic = genUidStat()
traindata, testdata = loadData()
# 获取每个uid的统计信息
forward, comment, like = [], [], []
for uid in traindata['uid']:
if uid in stat_dic.keys():
forward.append(int(stat_dic[uid]["forward_" + stat]))
comment.append(int(stat_dic[uid]["comment_" + stat]))
like.append(int(stat_dic[uid]["like_" + stat]))
else:
forward.append(0)
comment.append(0)
like.append(0)
train_real_pred = traindata[['forward', 'comment', 'like']]
train_real_pred['fp'], train_real_pred['cp'], train_real_pred['lp'] = forward, comment, like
# 对固定UID值的测试数据进行预测,生成提交文件
test_pred = testdata[['uid', 'mid']]
forward, comment, like = [], [], []
for uid in testdata['uid']:
if uid in stat_dic.keys():
forward.append(int(stat_dic[uid]["forward_" + stat]))
comment.append(int(stat_dic[uid]["comment_" + stat]))
like.append(int(stat_dic[uid]["like_" + stat]))
else:
forward.append(0)
comment.append(0)
like.append(0)
test_pred['fp'], test_pred['cp'], test_pred['lp'] = forward, comment, like
result = []
filename = "weibo_predict_{}.txt".format(stat)
for _, row in test_pred.iterrows():
result.append("{0}\t{1}\t{2},{3},{4}\n".format(row[0], row[1], row[2], row[3], row[4]))
f = open(filename, 'w')
f.writelines(result)
f.close()
if __name__ == "__main__":
predict_with_stat(stat="median")
0.23%的代码
main.py
主要运行程序
from tianchi.weibo_forecast.features import uid_features
delimiter = "\t"
def dataset_input(weibo_train_file_path, weibo_predict_file_path):
weibo_train_file = open(weibo_train_file_path)
dataset_train = list(weibo_train_file)
for i in range(len(dataset_train)):
dataset_train[i] = [float(x) for x in dataset_train[i]]
print(dataset_train)
return dataset_train
def score(weibo_result_file_path, weibo_real_file_path):
weibo_real_file = open(weibo_real_file_path, encoding='utf-8')
weibo_result_file = open(weibo_result_file_path, encoding='utf-8')
p1 = 0
p2 = 0
for line in weibo_real_file:
uid, mid, time, fr, cr, lr, content = line.split(delimiter)
count = int(fr) + int(cr) + int(lr)
if count > 100:
count = 100
result_line = weibo_result_file.readline()
value = result_line.split(delimiter)[2]
fp, cp, lp = value.split(",")
df = (abs(float(fp) - float(fr))) / (float(fr) + 5)
dc = (abs(float(cp) - float(cr))) / (float(cr) + 3)
lc = (abs(float(lp) - float(lr))) / (float(lr) + 3)
precision = 1 - 0.5 * df - 0.25 * dc - 0.25 * lc
sgn = lambda x: 1 if x > 0 else 0 if x < 0 else 0
p1 = p1 + (count + 1) * sgn(precision - 0.8)
p2 = p2 + (count + 1)
return str(p1 / p2)
# 排序
def generate_sortedfile(input_file_path, out_file_path):
inputfile = open(input_file_path, encoding='utf-8')
entrys = inputfile.readlines()
entrys.sort(key=lambda x: x.split(",")[0])
sortedfile = open(out_file_path, "w", encoding='utf-8')
for i in entrys:
sortedfile.write(i)
sortedfile.close()
inputfile.close()
import os
from datetime import *
def train_date_split(weibo_train_file_path, seperate_day, begin_date, weibo_train_five_file_path,
weibo_train_last_file_path):
weibo_train_file = open(weibo_train_file_path, encoding='utf-8') # 打开weibo_train_data.txt
ffive = open(weibo_train_five_file_path, 'w', encoding='utf-8')
flast = open(weibo_train_last_file_path, 'w', encoding='utf-8')
interval_days = (seperate_day - begin_date).days
for line in weibo_train_file:
uid, mid, time, forward_count, comment_count, like_count, content = line.split(delimiter)
real_date = date(*parse_date(time))
date_delta = (real_date - begin_date).days
if interval_days < date_delta:
flast.write(line)
else:
ffive.write(line)
# 解析日期
def parse_date(raw_date):
# entry_date = raw_date.decode("gbk")
entry_date = raw_date
year, month, day = entry_date.split(" ")[0].split("-")
return int(year), int(month), int(day)
def weibo_predict(uid_features_str_file_path, weibo_predict_file_path, weibo_result_file_path):
uid_features_str_file = open(uid_features_str_file_path, encoding='utf-8')
weibo_predict_file = open(weibo_predict_file_path, encoding='utf-8')
weibo_result_file = open(weibo_result_file_path, "w", encoding='utf-8')
table = {}
for line in open(uid_features_str_file_path, encoding='utf-8'):
uid, values = line.split("\t")
table["" + uid + ""] = values
for line in open(weibo_predict_file_path, encoding='utf-8'):
uid = line.split(delimiter)[0]
mid = line.split(delimiter)[1]
if uid in table.keys():
weibo_result_file.write(uid + "\t" + mid + "\t" + table["" + uid + ""])
else:
weibo_result_file.write(uid + "\t" + mid + "\t" + str(0) + "," + str(0) + "," + str(0) + "\n")
SEPERATEDAY = date(2015, 6, 30)
BEGINDAY = date(2015, 2, 1)
os.chdir(r'E:\项目文件\微博互动预测\Weibo Data')
weibo_train_file_path = "weibo_train_data.txt"
weibo_train_sort_path = "weibo_train_data_sort.txt"
weibo_predict_file_path = "weibo_predict_data.txt"
weibo_predict_sort_path = "weibo_predict_data_sort.txt"
weibo_train_five_file_path = "weibo_train_five.txt"
weibo_train_last_file_path = "weibo_train_last.txt"
uid_features_str_file_path = "uid_features_str.txt"
weibo_result_file_path = "weibo_result.txt"
starttime = datetime.now()
generate_sortedfile(weibo_train_file_path, weibo_train_sort_path)
print("1.Train sort has been completed")
generate_sortedfile(weibo_predict_file_path, weibo_predict_sort_path)
print("2.Predict sort has been completed")
train_date_split(weibo_train_sort_path, SEPERATEDAY, BEGINDAY, weibo_train_five_file_path, weibo_train_last_file_path)
print("3.Data segmentation has been completed")
uid_features(weibo_train_five_file_path, uid_features_str_file_path)
print("4.User feature extraction has been completed")
weibo_predict(uid_features_str_file_path, weibo_train_last_file_path, weibo_result_file_path)
print("5.Forecast has been completed")
endtime = datetime.now()
print("Total running time: %f s" % (endtime - starttime).seconds)
features.py
delimiter = "\t"
def uid_features(same_uid_train_file_path, uid_features_file_path):
same_uid_train_file = open(same_uid_train_file_path, encoding='utf-8')
uid_features_str_file = open(uid_features_file_path, 'w', encoding='utf-8')
uid_features = {'uid': "",
'forward_count': 0,
'comment_count': 0,
'like_count': 0,
'uid_time_count': 0,
'fc_median': 0,
'cc_median': 0,
'lc_median': 0,
'fc_variance': 0,
'cc_variance': 0,
'lc_variance': 0,
'fc_list': [],
'cc_list': [],
'lc_list': [],
}
firstline = same_uid_train_file.readline()
pre_train_uid, pre_train_mid, pre_train_time, pre_train_forward_count, pre_train_comment_count, pre_train_like_count, pre_train_content = firstline.split(
delimiter)
same_uid_train_file.seek(0)
for line in same_uid_train_file:
train_uid, train_mid, train_time, train_forward_count, train_comment_count, train_like_count, train_content = line.split(
delimiter)
if train_uid == pre_train_uid:
uid_features['uid'] = train_uid
uid_features['forward_count'] += int(train_forward_count)
uid_features['comment_count'] += int(train_comment_count)
uid_features['like_count'] += int(train_like_count)
uid_features['uid_time_count'] += 1
uid_features['fc_list'].append(int(train_forward_count))
uid_features['cc_list'].append(int(train_comment_count))
uid_features['lc_list'].append(int(train_like_count))
if not train_uid == pre_train_uid:
uid_features['fc_median'] = median(uid_features['fc_list'])
uid_features['cc_median'] = median(uid_features['cc_list'])
uid_features['lc_median'] = median(uid_features['lc_list'])
uid_features_str_file.write(get_uid_features_str(uid_features))
uid_feature = initial_uid_features(uid_features)
uid_features['uid'] = train_uid
uid_features['forward_count'] += int(train_forward_count)
uid_features['comment_count'] += int(train_comment_count)
uid_features['like_count'] += int(train_like_count)
uid_features['uid_time_count'] += 1
uid_features['fc_list'].append(int(train_forward_count))
uid_features['cc_list'].append(int(train_comment_count))
uid_features['lc_list'].append(int(train_like_count))
pre_train_uid = train_uid
uid_features_str_file.write(get_uid_features_str(uid_features))
def get_uid_features_str(uid_features):
uid_features_str = str(uid_features["uid"]) + "\t" \
+ str(uid_features["fc_median"]) + "," \
+ str(uid_features["cc_median"]) + "," \
+ str(uid_features["lc_median"]) + "\n"
return uid_features_str
def initial_uid_features(uid_features):
uid_features['uid'] = ""
uid_features['forward_count'] = 0
uid_features['comment_count'] = 0
uid_features['like_count'] = 0
uid_features['uid_time_count'] = 0
uid_features['fc_median'] = 0
uid_features['cc_median'] = 0
uid_features['lc_median'] = 0
uid_features['fc_variance'] = 0
uid_features['cc_variance'] = 0
uid_features['lc_variance'] = 0
uid_features['fc_list'] = []
uid_features['cc_list'] = []
uid_features['lc_list'] = []
return uid_features
def median(lst):
if not lst:
return
lst = sorted(lst)
if len(lst) % 2 == 1:
return int(lst[len(lst) // 2])
else:
return int((lst[len(lst) // 2 - 1] + lst[len(lst) // 2]) / 2)
喜欢请一键三连


















 1724
1724

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









