










 本文介绍了如何利用灰狼优化算法(GWO)来寻找LSTM神经网络的最佳超参数,包括神经元数量、dropout比率和batch_size。通过迭代寻优,GWO模拟灰狼的狩猎行为以逼近全局最优解。代码中展示了GWO的实现过程,并给出了实际数据集(zgpa_train.csv和DIANCHI.csv)的预处理和模型训练。最终,使用找到的最优参数训练LSTM模型并评估性能。
本文介绍了如何利用灰狼优化算法(GWO)来寻找LSTM神经网络的最佳超参数,包括神经元数量、dropout比率和batch_size。通过迭代寻优,GWO模拟灰狼的狩猎行为以逼近全局最优解。代码中展示了GWO的实现过程,并给出了实际数据集(zgpa_train.csv和DIANCHI.csv)的预处理和模型训练。最终,使用找到的最优参数训练LSTM模型并评估性能。
1、摘要
本文主要讲解:使用灰狼算法优化LSTM超参数-神经元个数-dropout-batch_size
主要思路:
- 灰狼算法 Parameters : 迭代次数、狼的寻值范围、狼的数量
- LSTM Parameters 神经网络第一层神经元个数、神经网络第二层神经元个数、dropout比率、batch_size
- 开始搜索:初始化所有狼的位置、迭代寻优、返回超出搜索空间边界的搜索代理、计算每个搜索代理的目标函数、更新 Alpha, Beta, and Delta
- 训练模型,使用灰狼算法找到的最好的全局最优参数
- plt.show()
2、数据介绍
zgpa_train.csv
DIANCHI.csv
需要数据的话去我其他文章的评论区
可接受定制
3、相关技术
灰狼优化算法(GWO),灵感来自于灰狼.GWO算法模拟了自然界灰狼的领导层级和狩猎机制.四种类型的灰狼。此外,还实现了狩猎的三个主要步骤:寻找猎物、包围猎物和攻击猎物。
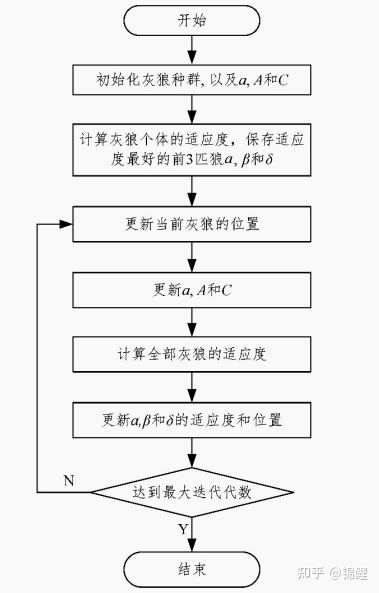
PSO与GWO对比试验结果如下图: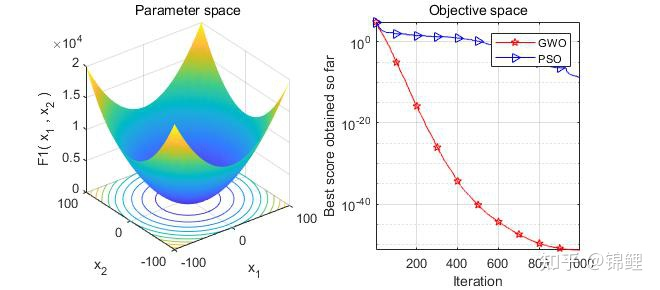
灰狼算法
4、完整代码和步骤
此程序运行代码版本为:
tensorflow==2.5.0
numpy==1.19.5
keras==2.6.0
matplotlib==3.5.2
代码输出如下:
主运行程序入口
LSTM_GWO.py
import math
import os
import random
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from sklearn.metrics import mean_squared_error
from sklearn.preprocessing import MinMaxScaler
from tensorflow.python.keras.callbacks import EarlyStopping
from tensorflow.python.keras.layers import Dense, Dropout, LSTM
from tensorflow.python.keras.layers.core import Activation
from tensorflow.python.keras.models import Sequential
import numpy as numpy
os.chdir(r'D:\项目\PSO-LSTM\具体需求')
'''
灰狼算法优化LSTM
'''
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
def GWO(objf, lb, ub, dim, SearchAgents_no, Max_iter):
# ===初始化 alpha, beta, and delta_pos=======
Alpha_pos = numpy.zeros(dim) # 位置.形成30的列表
Alpha_score = float("inf") # 这个是表示“正负无穷”,所有数都比 +inf 小;正无穷:float("inf"); 负无穷:float("-inf")
Beta_pos = numpy.zeros(dim)
Beta_score = float("inf")
Delta_pos = numpy.zeros(dim)
Delta_score = float("inf") # float() 函数用于将整数和字符串转换成浮点数。
# ====list列表类型=============
if not isinstance(lb, list): # 作用:来判断一个对象是否是一个已知的类型。其第一个参数(object)为对象,第二个参数(type)为类型名,若对象的类型与参数二的类型相同则返回True
lb = [lb] * dim # 生成[100,100,.....100]30个
if not isinstance(ub, list):
ub = [ub] * dim
# ========初始化所有狼的位置===================
Positions = numpy.zeros((SearchAgents_no, dim))
for i in range(dim): # 形成5*30个数[-100,100)以内
Positions[:, i] = numpy.random.uniform(0, 1, SearchAgents_no) * (ub[i] - lb[i]) + lb[
i] # 形成[5个0-1的数]*100-(-100)-100
Convergence_curve = numpy.zeros(Max_iter)
# ========迭代寻优=====================
for l in range(0, Max_iter): # 迭代1000
for i in range(0, SearchAgents_no): # 5
# ====返回超出搜索空间边界的搜索代理====
for j in range(dim): # 30
Positions[i, j] = numpy.clip(Positions[i, j], lb[j], ub[
j]) # clip这个函数将将数组中的元素限制在a_min(-100), a_max(100)之间,大于a_max的就使得它等于 a_max,小于a_min,的就使得它等于a_min。
# ===计算每个搜索代理的目标函数==========
fitness = objf(Positions[i, :]) # 把某行数据带入函数计算
# print("经过计算得到:",fitness)
# ====更新 Alpha, Beta, and Delta================
if fitness < Alpha_score:
Alpha_score = fitness # Update alpha
Alpha_pos = Positions[i, :].copy()
if (fitness > Alpha_score and fitness < Beta_score):
Beta_score = fitness # Update beta
Beta_pos = Positions[i, :].copy()
if (fitness > Alpha_score and fitness > Beta_score and fitness < Delta_score):
Delta_score = fitness # Update delta
Delta_pos = Positions[i, :].copy()
# ===========以上的循环里,Alpha、Beta、Delta===========
a = 2 - l * ((2) / Max_iter) # a从2线性减少到0
for i in range(0, SearchAgents_no):
for j in range(0, dim):
r1 = random.random() # r1 is a random number in [0,1]主要生成一个0-1的随机浮点数。
r2 = random.random() # r2 is a random number in [0,1]
A1 = 2 * a * r1 - a # Equation (3.3)
C1 = 2 * r2 # Equation (3.4)
# D_alpha表示候选狼与Alpha狼的距离
D_alpha = abs(C1 * Alpha_pos[j] - Positions[
i, j]) # abs() 函数返回数字的绝对值。Alpha_pos[j]表示Alpha位置,Positions[i,j])候选灰狼所在位置
X1 = Alpha_pos[j] - A1 * D_alpha # X1表示根据alpha得出的下一代灰狼位置向量
r1 = random.random()
r2 = random.random()
A2 = 2 * a * r1 - a #
C2 = 2 * r2
D_beta = abs(C2 * Beta_pos[j] - Positions[i, j])
X2 = Beta_pos[j] - A2 * D_beta
r1 = random.random()
r2 = random.random()
A3 = 2 * a * r1 - a
C3 = 2 * r2
D_delta = abs(C3 * Delta_pos[j] - Positions[i, j])
X3 = Delta_pos[j] - A3 * D_delta
Positions[i, j] = (X1 + X2 + X3) / 3 # 候选狼的位置更新为根据Alpha、Beta、Delta得出的下一代灰狼地址。
Convergence_curve[l] = Alpha_score
if (l % 1 == 0):
print(['迭代次数为' + str(l) + ' 的迭代结果' + str(Alpha_score)]) # 每一次的迭代结果
# 绘图
plt.plot(Convergence_curve)
plt.title('Convergence_curve')
plt.show()
print("The best solution obtained by GWO is : " + str(Alpha_pos))
print("The best optimal value of the objective funciton found by GWO is : " + str(Alpha_score))
return Alpha_pos,Alpha_score
def creat_dataset(dataset, look_back):
dataX, dataY = [], []
for i in range(len(dataset) - look_back - 1):
a = dataset[i: (i + look_back)]
dataX.append(a)
dataY.append(dataset[i + look_back])
return np.array(dataX), np.array(dataY)
dataframe = pd.read_csv('zgpa_train.csv', header=0, parse_dates=[0], index_col=0, usecols=[0, 5], squeeze=True)
dataset = dataframe.values
data = pd.read_csv('DIANCHI.csv', header=0)
z = data['fazhi']
scaler = MinMaxScaler(feature_range=(0, 1))
dataset = scaler.fit_transform(dataset.reshape(-1, 1))
train_size = int(len(dataset) * 0.8)
test_size = len(dataset) - train_size
train, test = dataset[0: train_size], dataset[train_size: len(dataset)]
look_back = 10
trainX, trainY = creat_dataset(train, look_back)
testX, testY = creat_dataset(test, look_back)
def build_model(neurons1, neurons2, dropout):
X_train, y_train = trainX, trainY
X_test, y_test = testX, testY
model = Sequential()
# model.add(LSTM(input_dim=1, units=50, return_sequences=True))
model.add(LSTM(input_dim=neurons1, units=50, return_sequences=True, input_shape=(10, 1)))
# model.add(LSTM(input_dim=50, units=100, return_sequences=True))
model.add(LSTM(input_dim=neurons2, units=100, return_sequences=True))
model.add(LSTM(input_dim=100, units=200, return_sequences=True))
model.add(LSTM(300, return_sequences=False))
# model.add(Dropout(0.2))
model.add(Dropout(dropout))
model.add(Dense(100))
model.add(Dense(units=1))
model.add(Activation('relu'))
model.compile(loss='mean_squared_error', optimizer='Adam')
return model, X_train, y_train, X_test, y_test
def training(X):
neurons1 = int(X[0])
neurons2 = int(X[1])
dropout = round(X[2], 6)
batch_size = int(X[3])
print(X)
model, X_train, y_train, X_test, y_test = build_model(neurons1, neurons2, dropout)
model.fit(
X_train,
y_train,
batch_size=batch_size,
epochs=1,
validation_split=0.1,
verbose=0,
callbacks=[EarlyStopping(monitor='val_loss', patience=22, restore_best_weights=True)])
pred = model.predict(X_test)
temp_mse = mean_squared_error(y_test, pred)
print(temp_mse)
return temp_mse
if __name__ == '__main__':
'''
神经网络第一层神经元个数
神经网络第二层神经元个数
dropout比率
batch_size
'''
ub = [10, 26, 0.25, 8]
lb = [6, 22, 0.2, 2]
# ===========主程序================
Max_iter = 3 # 迭代次数
dim = 4 # 狼的寻值范围
SearchAgents_no = 5 # 寻值的狼的数量
Alpha_pos,Alpha_score = GWO(training, lb, ub, dim, SearchAgents_no, Max_iter)
print('best_params is ', Alpha_pos)
print('best_precision is', Alpha_score)
# 训练模型 使用PSO找到的最好的神经元个数
neurons1 = int(Alpha_pos[0])
neurons2 = int(Alpha_pos[1])
dropout = Alpha_pos[2]
batch_size = int(Alpha_pos[3])
model, X_train, y_train, X_test, y_test = build_model(neurons1, neurons2, dropout)
history = model.fit(X_train, y_train, epochs=333, batch_size=batch_size, validation_split=0.2, verbose=1,
callbacks=[EarlyStopping(monitor='val_loss', patience=29, restore_best_weights=True)])
trainPredict = model.predict(trainX)
testPredict = model.predict(testX)
trainPredict = scaler.inverse_transform(trainPredict)
trainY = scaler.inverse_transform(trainY)
testPredict = scaler.inverse_transform(testPredict)
testY = scaler.inverse_transform(testY)
trainScore = math.sqrt(mean_squared_error(trainY, trainPredict[:, 0]))
# print('Train Score %.2f RMSE' %(trainScore))
testScore = math.sqrt(mean_squared_error(testY, testPredict[:, 0]))
# print('Test Score %.2f RMSE' %(trainScore))
trainPredictPlot = np.empty_like(dataset)
trainPredictPlot[:] = np.nan
trainPredictPlot = np.reshape(trainPredictPlot, (dataset.shape[0], 1))
trainPredictPlot[look_back: len(trainPredict) + look_back, :] = trainPredict
testPredictPlot = np.empty_like(dataset)
testPredictPlot[:] = np.nan
testPredictPlot = np.reshape(testPredictPlot, (dataset.shape[0], 1))
testPredictPlot[len(trainPredict) + (look_back * 2) + 1: len(dataset) - 1, :] = testPredict
plt.plot(history.history['loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.show()
fig2 = plt.figure(figsize=(20, 15))
plt.rcParams['font.family'] = ['STFangsong']
ax = plt.subplot(222)
plt.plot(scaler.inverse_transform(dataset), 'b-', label='实验数据')
plt.plot(trainPredictPlot, 'r', label='训练数据')
plt.plot(testPredictPlot, 'g', label='预测数据')
plt.plot(z, 'k-', label='寿命阀值RUL')
plt.ylabel('capacity', fontsize=20)
plt.xlabel('cycle', fontsize=20)
plt.legend()
name = 'neurons1_' + str(neurons1) + 'neurons2_' + str(neurons2) + '_dropout' + str(
dropout) + '_batch_size' + str(batch_size)
plt.savefig('D:\项目\PSO-LSTM\具体需求\photo\\' + name + '.png')
plt.show()



















 1725
1725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









