







楼主只是个大三狗,去年在技术部工作的时候,师兄要求我写一个抓取教务部信息的小Demo,举一反三,写了三个关于JAVA爬虫的代码。
首先做好准备工作:
了解正则表达式中基本的Select的用法:
此处引用楼主查到的资料
http://www.tuicool.com/articles/ZnyMvu
第一个爬虫:无验证码的简单爬虫
楼主是中南财经政法大学的,就拿本校教务处作为例子,我们的目的是获取教务通知中的标题和超链接
网址:http://jwc.zuel.edu.cn/
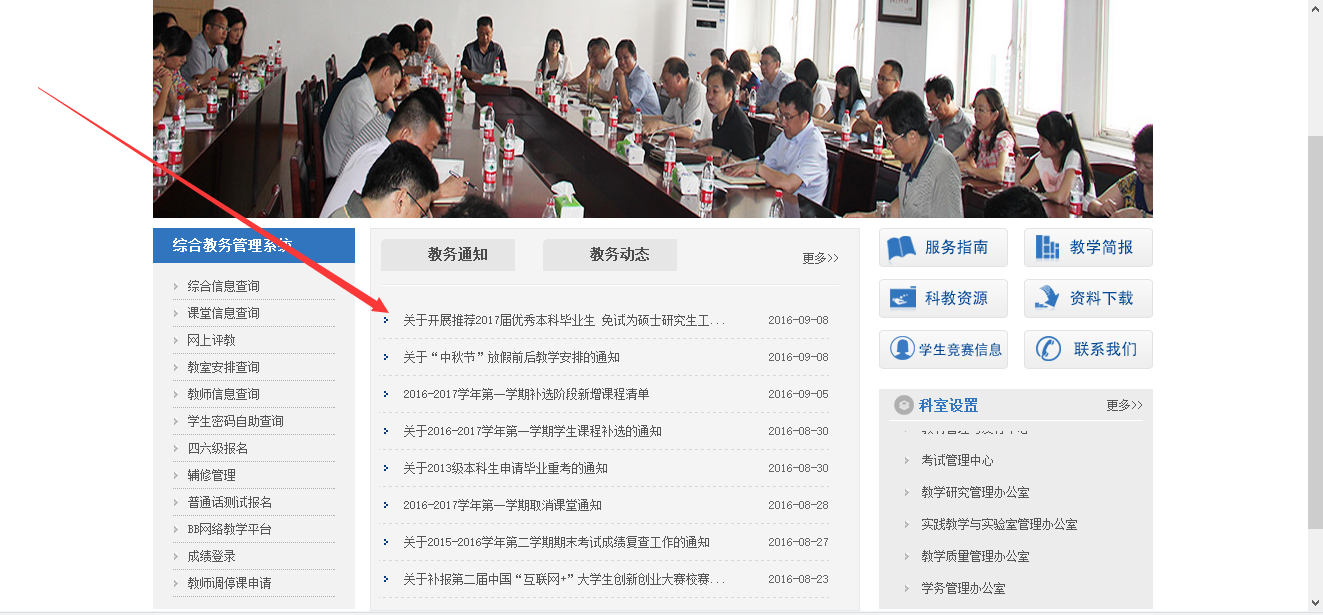
首先查看网页源码,楼主用的是谷歌,F12就可以看到源码。
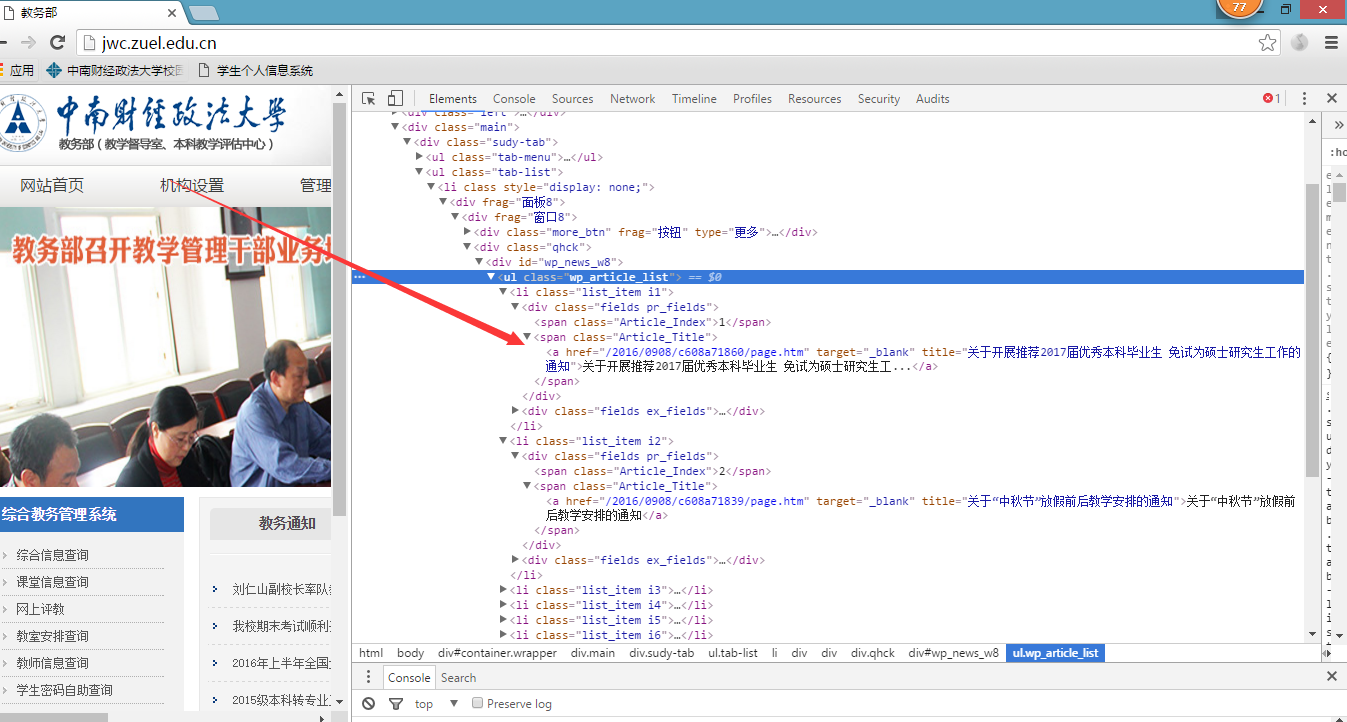
接下来重点!!!!PO出JAVA源码
String url="http://jwc.zuel.edu.cn/";//你要爬的网页地址
//核心代码,链接到该网页
Connection connection=Jsoup.connect(url);
Document Content=connection.get();
//获取指定位置的信息,该Demo中是新闻标题和时间
Elements links=Content.select("[class=Article_Title]");
Elements Date=Content.select("[class=Article_PublishDate]");
//首先显示了8个新闻,用一个for循环
for(int i=0;i<8;i++)
{
//得到所需字符串
String webContent=links.select("a").get(i).text();
String webDate=Date.get(i).text();
//得到超链接的代码比较特殊 这里进行标注
String herf=links.select("a").get(i).attr("abs:href");
System.out.println(herf);
str[i*2]=webContent;
str[i*2+1]=webDate;
strings[i]=herf;
}
for(int m=0;m<16;m++)
{
System.out.println(str[m]);
System.out.println(str[++m]);
}
// 下面是结果图(改一改就可以应用到JSP和微信中也是可以,是不是很棒!):
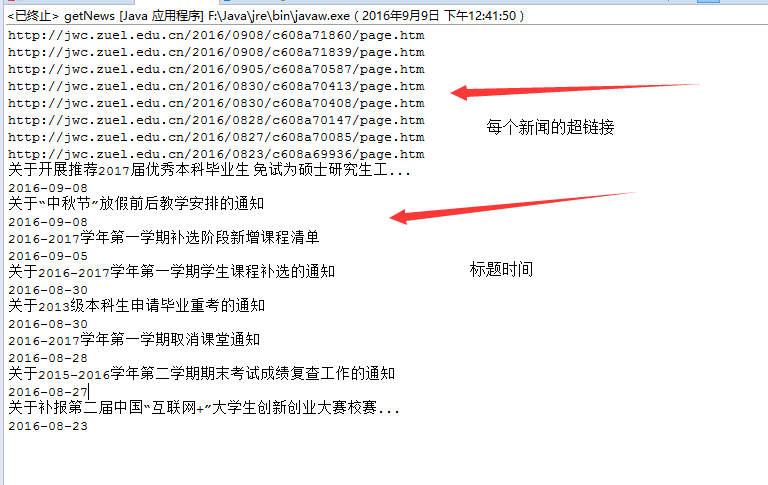















 334
334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









