







前言
卡方校验可以用作特征选取,尤其在数据预处理中起到一定的作用.例如,在文本分类中,我们可以利用卡方校验来判断某些词对类别分类的影响程度,从而筛选出特征词.而对于多维属性的对象,我也可以通过卡方校验来筛选出特征属性.卡方校验其实是数理统计中一种常用的校验两个变量独立性的方法.通常,我们会用一个相关性表格来描述卡方校验,具体理论知识,我们可以参考一下的网址:
特征选取算法之卡方校验
卡方校验的实现
多维属性的特征选取
如果是对于多维属性的矩阵列表做卡方校验,我在学习scikit-learn的过程中,接触到了类似的解决方法,截个图来说明一下:

具体的代码如下:
from sklearn.datasets import load_iris
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
iris = load_iris()
X, y = iris.data, iris.target
print X.shape
>>>(150, 4)
X_new = SelectKBest(chi2, k=2).fit_transform(X, y)
print X_new.shape
>>>(150, 2)说明:
ris以鸢尾花的特征作为数据来源,常用在分类操作中。该数据集由3种不同类型的鸢尾花的50个样本数据构成。其中的一个种类与另外两个种类是线性可分离的,后两个种类是非线性可分离的。
该数据集包含了5个属性:
& Sepal.Length(花萼长度),单位是cm;
& Sepal.Width(花萼宽度),单位是cm;
& Petal.Length(花瓣长度),单位是cm;
& Petal.Width(花瓣宽度),单位是cm;
& 种类:Iris Setosa(山鸢尾)、Iris Versicolour(杂色鸢尾),以及Iris Virginica(维吉尼亚鸢尾)。
iris.data:
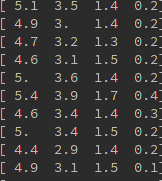
iris.target:
关键点:
sklearn中有丰富的特征选取包feature_selection,其中selectkBest为选取前k个特征,但是这个不能单独使用,需要有如chi,特定的特征提取方法嵌套.只要运行SelectKBest(chi2, k=2).fit_transform(data, target),便可得到特征选取后的矩阵.
文本分类中的特征选取
曾经, 我在一个项目内担任算法工程的工作,当时的业务是这样子的:
在微博平台上获取不同的话题类别,并利用特征选取的方法尽可能筛选出特征词,以用作后期的话题分类
于是乎,我在微博上搜寻出24种具有代表性的话题,具体如下:
categories = [u’健康养生’, u’军事历史’, u’时政’, u’公益’, u’读书’, u’电视剧’, u’IT互联网’, u’教育’, u’艺术’, u’电影’, u’动漫’, u’游戏’, u’旅游’, u’美食’, u’摄影’, u’萌宠’,u’服装美容’, u’体育’, u’设计’, u’综艺’, u’星座’, u’音乐’, u’健身’, u’财经’]
随后,我根据这24种不同的话题,分别找了每个类别中20个对应的大V,并且爬取每个大V的前50条微博.利用结巴分词和哈工大的停用词表,我对数据做初步的处理,如图:

(注:每一行代表的是每一个大V的50条微博经过处理的结果,而最后一个是大V所属的类别,在这里没能截取到全部)
处理后,我便用python实现了卡方校验,但是实现后的效果没有达到很好的理想程度,于是乎,我在看论文的时候,学习到了一篇关于如何改进卡方校验的方法,感觉挺不错,我把这里文章放到了文库上,此下为文章的链接:
基于改进卡方统计的微博特征提取方法
主要的要点有以下两点:
1.引入频度改进卡方统计量:
—-卡方统计量只计算了特征词在所有文档中出现次数,没有计算特征在某一文档中出现的频数.因此,引入参数频度进行调节.
2.去除特征项的出现与类别负相关的情况
—-由卡方的计算公式可看出,如果B和C都比较大,而A和D都比较小,并且BC>AD (A表示属于类别c且包含特征项w的文档频数,B为不属于类别c但包含特征项w的文档频数,C表示属于类别c但不包含特征项w的文档频数,D表示既不属于类别c也不包含特征项w的文档频数) ,则该特征对类别c产生负影响,故将卡方统计量设为0.
在实验中,我为了增加词在文档中的影响力,便再引入tfidf的影响因子,
故改进后的chi为:
new_chi = chi * frequency * tfidf实验的效果如图:
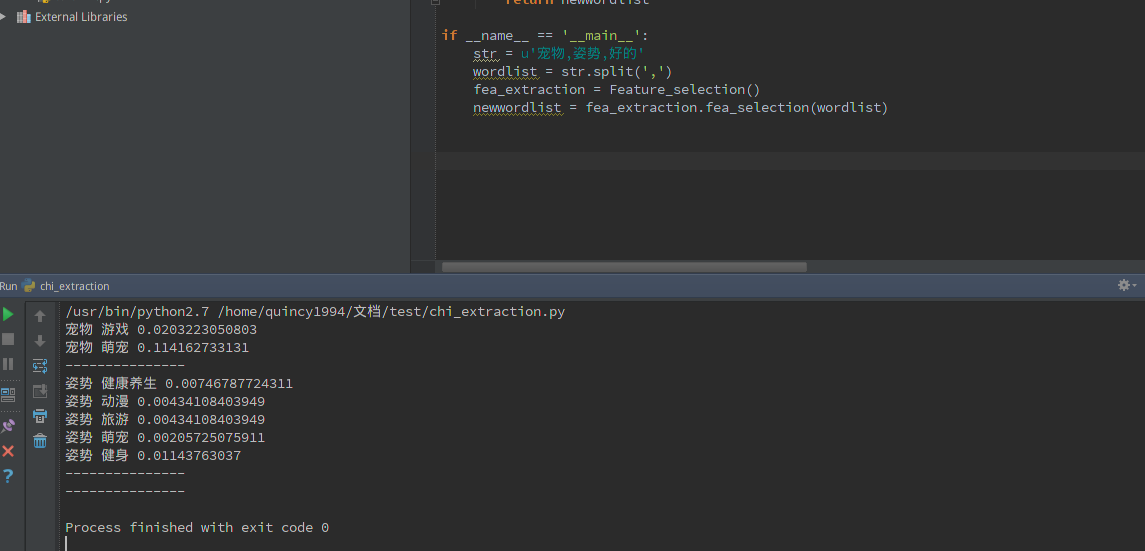
测试集为’宠物,姿势,好的’,经过chi特征选择后,我们可以看到,”宠物”对分类到”萌宠”话题的影响程度最大, “姿势”偏向于”健身”话题,而”好的”没有偏向于任何话题,故被过滤掉.
详尽的代码实现可以访问我的github:
chi代码实现
在chi_selection.py封装了原来的chi方法,以及改进后的chi方法
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









