








1.场景:
在很多公司的文件管理系统中,都有类似于对比多篇文章的相似度,例如在写公众号推文时,如果标记了原创,就会对比当前文章和库里已存在文章的相似程度,如果相似度过于高,则标记为原创的文章无法实现推送,那么,该功能是如何实现的呢?可以参考如下思路。
2.算法:
此例子借助的是海明距离的实现方式,具体原理请移步(海明距离的定义与说明),此处不做过多的阐述。
3.工具类:SimilarityTwoUtils
package com.alex.examples.utils;
import com.hankcs.hanlp.seg.common.Term;
import com.hankcs.hanlp.tokenizer.StandardTokenizer;
import org.apache.commons.lang.StringUtils;
import org.jsoup.Jsoup;
import org.jsoup.safety.Whitelist;
import java.math.BigInteger;
import java.util.*;
/**
* 对比多篇文章中内容相似度算法工具类
*/
public class SimilarityTwoUtils {
/**
* 标题名称
*/
private String topicName;
/**
* 分词向量
*/
private BigInteger bigSimHash;
/**
* 初始桶大小
* 备注:对每条文本根据SimHash 算出签名后,再计算两个签名的海明距离(两个二进制异或后1的个数)即可。根
* 据经验值,对64位的SimHash,海明距离在3以内的可以认为相似度比较高。
* 假设对64位的SimHash,查找海明距离在3以内的所有签名。
* 可以把64位的二进制签名均分成4块,每块16位。根据鸽巢原理(也称抽屉原理,见组合数学),如果两个签名的海明距离在3以内,它们必有一块完全相同。
* 把上面分成的4块中的每一个块分别作为前16位来进行查找。建立倒排索引。
*/
private Integer hashCount = 64;
/**
* 分词最小长度限制
*/
private static final Integer WORD_MIN_LENGTH = 3;
private static final BigInteger ILLEGAL_X = new BigInteger("-1");
public SimilarityTwoUtils(String topicName, Integer myHashCount) {
this.topicName = topicName;
this.bigSimHash = this.simHash();
//如果myHashCount为null,则默认64
if (null != myHashCount) {
this.hashCount = myHashCount;
}
}
/**
* 分词计算向量
*
* @return BigInteger
*/
private BigInteger simHash() {
// 清除特殊字符
this.topicName = this.clearSpecialCharacters(this.topicName);
int[] hashArray = new int[this.hashCount];
// 对内容进行分词处理
List<Term> terms = StandardTokenizer.segment(this.topicName);
// 配置词性权重
Map<String, Integer> weightMap = new HashMap<>(16, 0.75F);
weightMap.put("n", 1);
// 设置停用词
Map<String, String> stopMap = new HashMap<>(16, 0.75F);
stopMap.put("w", "");
// 设置超频词上线
Integer overCount = 5;
// 设置分词统计量
Map<String, Integer> wordMap = new HashMap<>(16, 0.75F);
for (Term term : terms) {
// 获取分词字符串
String word = term.word;
// 获取分词词性
String nature = term.nature.toString();
// 过滤超频词
if (wordMap.containsKey(word)) {
Integer count = wordMap.get(word);
if (count > overCount) {
continue;
} else {
wordMap.put(word, count + 1);
}
} else {
wordMap.put(word, 1);
}
// 过滤停用词
if (stopMap.containsKey(nature)) {
continue;
}
// 计算单个分词的Hash值
BigInteger wordHash = this.getWordHash(word);
for (int i = 0; i < this.hashCount; i++) {
// 向量位移
BigInteger bitMask = new BigInteger("1").shiftLeft(i);
// 对每个分词hash后的列进行判断,
// 例如:1000...1,则数组的第一位和末尾一位加1,中间的62位减一,
// 也就是,逢1加1,逢0减1,一直到把所有的分词hash列全部判断完
// 设置初始权重
Integer weight = 1;
if (weightMap.containsKey(nature)) {
weight = weightMap.get(nature);
}
// 计算所有分词的向量
if (wordHash.and(bitMask).signum() != 0) {
hashArray[i] += weight;
} else {
hashArray[i] -= weight;
}
}
}
// 生成指纹
BigInteger fingerPrint = new BigInteger("0");
for (int i = 0; i < this.hashCount; i++) {
if (hashArray[i] >= 0) {
fingerPrint = fingerPrint.add(new BigInteger("1").shiftLeft(i));
}
}
return fingerPrint;
}
/**
* 计算单个分词的hash值
*
* @return BigInteger
*/
private BigInteger getWordHash(String word) {
if (StringUtils.isEmpty(word)) {
// 如果分词为null,则默认hash为0
return new BigInteger("0");
} else {
// 分词补位,如果过短会导致Hash算法失败
while (word.length() < SimilarityTwoUtils.WORD_MIN_LENGTH) {
word = word + word.charAt(0);
}
// 分词位运算
char[] wordArray = word.toCharArray();
BigInteger x = BigInteger.valueOf(wordArray[0] << 7);
BigInteger m = new BigInteger("1000003");
// 初始桶pow运算
BigInteger mask = new BigInteger("2").pow(this.hashCount).subtract(new BigInteger("1"));
for (char item : wordArray) {
BigInteger temp = BigInteger.valueOf(item);
x = x.multiply(m).xor(temp).and(mask);
}
x = x.xor(new BigInteger(String.valueOf(word.length())));
if (x.equals(ILLEGAL_X)) {
x = new BigInteger("-2");
}
return x;
}
}
/**
* 过滤特殊字符
*
* @return BigInteger
*/
private String clearSpecialCharacters(String topicName) {
// 将内容转换为小写
topicName = StringUtils.lowerCase(topicName);
// 过来HTML标签
topicName = Jsoup.clean(topicName, Whitelist.none());
// 过滤特殊字符
String[] strings = {" ", "\n", "\r", "\t", "\\r", "\\n", "\\t", " ", "&", "<", ">", """, "&qpos;"};
for (String string : strings) {
topicName = topicName.replaceAll(string, "");
}
return topicName;
}
/**
* 获取标题内容的相似度
*
* @return Double
*/
public Double getSimilar(SimilarityTwoUtils simHashUtil) {
// 获取海明距离
Double hammingDistance = (double) this.getHammingDistance(simHashUtil);
// 求得海明距离百分比
Double scale = (1 - hammingDistance / this.hashCount) * 100;
Double formatScale = Double.parseDouble(String.format("%.2f", scale));
return formatScale;
}
/**
* 获取标题内容的海明距离
*
* @return Double
*/
private int getHammingDistance(SimilarityTwoUtils simHashUtil) {
// 求差集
BigInteger subtract = new BigInteger("1").shiftLeft(this.hashCount).subtract(new BigInteger("1"));
// 求异或
BigInteger xor = this.bigSimHash.xor(simHashUtil.bigSimHash).and(subtract);
int total = 0;
while (xor.signum() != 0) {
total += 1;
xor = xor.and(xor.subtract(new BigInteger("1")));
}
return total;
}
}4.测试类:ArticleSimilarityTest
package com.alex.examples;
import cn.hutool.core.io.FileUtil;
import com.alex.examples.utils.SimilarityTwoUtils;
public class ArticleSimilarityTest {
public static void main(String[] args) {
// 简单模拟,此处【库里已存在的文章】可以通过数据库查询后,再做对比
String str1 = FileUtil.readString("你当前的文章", "utf-8");
String str2 = FileUtil.readString("库里已存在的文章", "utf-8");
// 计算相似度
SimilarityTwoUtils mySimHash_1 = new SimilarityTwoUtils(str1, 64);
SimilarityTwoUtils mySimHash_2 = new SimilarityTwoUtils(str2, 64);
Double similar = mySimHash_1.getSimilar(mySimHash_2);
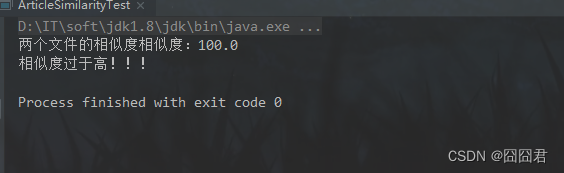
System.out.println("两个文件的相似度相似度:" + similar);
if (similar >= 95L) { // 这个相似度值的界限,根据公司的要求定义即可
System.out.println("相似度过于高!!!");
}
}
}
4.运行结果:
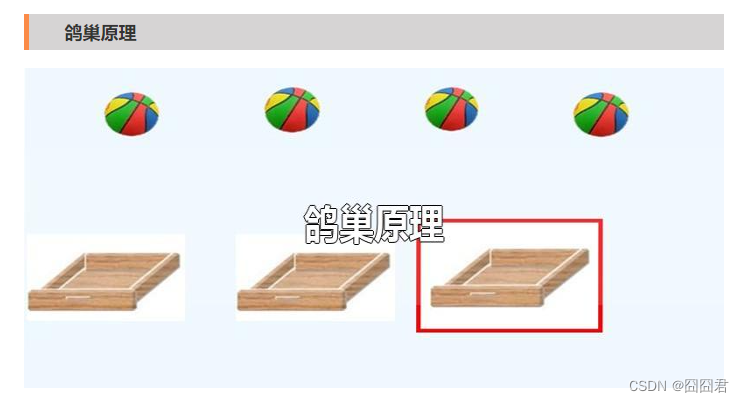
5.鸽巢原理(对文章出现的鸽巢原理进行讲解):
鸽巢原理也称为抽屉原理,是组合数学中一个重要的原理。
抽屉原理的含义:如果每个抽屉代表一个集合,每一个皮球代表一个元素,假如有N+1个元素放到N个集合中,其实必定有一个集合里至少含有两个元素,如图:















 517
517











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









