






一、Redis注意事项
在SpringBoot2.x之后,原来的jedis被替换为lettuce
jedis:直接采用直连,多个线程操作的话,是不安全的,如果想要避免不安全,使用jedis pool连接池!当数据量大时处理麻烦(和BIO阻塞模式场景相似)
lettuce:采用netty,实例可以再多个线程中进行共享,不存在线程不安全情况!可以减少线程数据(NIO模式场景相似)
二、Redis通用指令
-
KEYS:查看符合模板的所有key,不建议在生产环境设备上使用
-
DEL:删除一个指定的key
-
EXISTS:判断key是否存在
-
EXPIRE:给一个key设置有效期,有效期到期时该key会被自动删除
-
TTL:查看设置的有效期
-
FLUSHALL:删除所有库
-
FLUSHDB:删除当前库
-
SETNX:不存在则创建
-
INFO replication:查看集群状态信息
三、Redis事务
Redis事务本质:一组命令的集合!一个事务中的所有命令都会被序列化,在事务执行过程中,会按照顺序执行!
即一次性、顺序行、排他性!执行一些列的命令!
----------队列 set set set set .... 执行------
单独的隔离操作!
事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断!
Redis事务没有隔离级别的概念!
所有的命令在事务中,并没有直接被执行!只有发起执行命令的时候才会被执行!Exec执行命令
Redis单条命令式保存原子性的,但是事务不保证原子性!
事务中如果有一条命令执行失败,其后的命令仍然会被执行,没有回滚
redis的事务:
-
开启事务(multi)---返回一个ok
-
命令入队(.......)-----返回一个QUEUED
-
执行事务(exec)-----返回一个结果集
127.0.0.1:6379> multi #开启事务 OK #命令入队 127.0.0.1:6379(TX)> set k1 v1 QUEUED 127.0.0.1:6379(TX)> set k2 v2 QUEUED 127.0.0.1:6379(TX)> get k2 QUEUED 127.0.0.1:6379(TX)> set k3 v3 QUEUED 127.0.0.1:6379(TX)> exec #执行事务 1) OK 2) OK 3) "v2" 4) OK #每一次事务执行完,该事务消失,如果需要新的事务,需要再次开启
锁:redis可以实现乐观锁:watch
127.0.0.1:6379> multi #开启事务
OK
#命令入队
127.0.0.1:6379(TX)> set k1 v1
QUEUED
127.0.0.1:6379(TX)> set k2 v2
QUEUED
127.0.0.1:6379(TX)> set k4 v4
QUEUED
127.0.0.1:6379(TX)> discard #取消事务
OK
127.0.0.1:6379> get k4 #事务队列中命令都不会执行!
(nil)放弃事务
127.0.0.1:6379> multi #开启事务
OK
#命令入队
127.0.0.1:6379(TX)> set k1 v1
QUEUED
127.0.0.1:6379(TX)> set k2 v2
QUEUED
127.0.0.1:6379(TX)> set k4 v4
QUEUED
127.0.0.1:6379(TX)> discard #取消事务
OK
127.0.0.1:6379> get k4 #事务队列中命令都不会执行!
(nil)编译型异常(代码有问题!命令有错!)事务中所有的命令都不会被执行!
127.0.0.1:6379> multi #开启事务
OK
127.0.0.1:6379(TX)> set k1 v1
QUEUED
127.0.0.1:6379(TX)> set k2 v2
QUEUED
127.0.0.1:6379(TX)> set k3 v3
QUEUED
127.0.0.1:6379(TX)> getset k3 #编译型异常----错误的命令
(error) ERR wrong number of arguments for 'getset' command
127.0.0.1:6379(TX)> set k4 v4
QUEUED
127.0.0.1:6379(TX)> set k5 v5
QUEUED
127.0.0.1:6379(TX)> exec #执行事务报错
(error) EXECABORT Transaction discarded because of previous errors.
127.0.0.1:6379> get k5 #所有的命令都不会被执行!
(nil)运行时异常(比如1/0)事务队列中存在语法性错误,执行命令的时候,其他命令是可以正常执行的!错误的命令会抛出异常
127.0.0.1:6379> set k1 "v1"
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379(TX)> incr k1 #k1值 +1
QUEUED
127.0.0.1:6379(TX)> set k2 v2
QUEUED
127.0.0.1:6379(TX)> set k3 v3
QUEUED
127.0.0.1:6379(TX)> get k3
QUEUED
127.0.0.1:6379(TX)> exec
1) (error) ERR value is not an integer or out of range #运行时错误,不是integer类型
2) OK
3) OK
4) "v3"
127.0.0.1:6379> get k2
"v2"
127.0.0.1:6379> get k3
"v3" #其他命令正常执行监控!Watch
悲观锁:
-
很悲观,什么时候都判断会出问题,无论做什么都会加锁!结束之后在解锁!
-
每次操作时,别人不能操作,只能等我释放锁后,别人才能操作!
乐观锁:
-
很乐观,认为什么时候都不会出问题,所以不会上锁!更新数据的时候去判断一下,在此期间是否有人修改过这个数据!
-
根据版本号进行操作,如果版本号对不上,就不能执行操作
-
redis使用乐观锁
-
获取version
-
更新的时候比较version
-
Redis测监视测试
127.0.0.1:6379> set money 100
OK
127.0.0.1:6379> set out 0
OK
127.0.0.1:6379> watch money #监视money对象
OK
127.0.0.1:6379> multi #执行事务
OK
127.0.0.1:6379(TX)> DECRBY money 20
QUEUED
127.0.0.1:6379(TX)> INCRBY out 20
QUEUED
127.0.0.1:6379(TX)> exec #事务正常结束,数据期间没有发生变动
1) (integer) 80
2) (integer) 20
#正常执行成功!测试多线程修改值,使用watch可以当做redis的乐观锁操作!
127.0.0.1:6379> watch money #监视
OK
127.0.0.1:6379> multi
OK
127.0.0.1:6379(TX)> DECRBY money 10
QUEUED
127.0.0.1:6379(TX)> INCRBY out 10
QUEUED
127.0.0.1:6379(TX)> exec #执行之前,另外一个线程修改了我们的值,这个时候,就会导致事务执行失败!
(nil)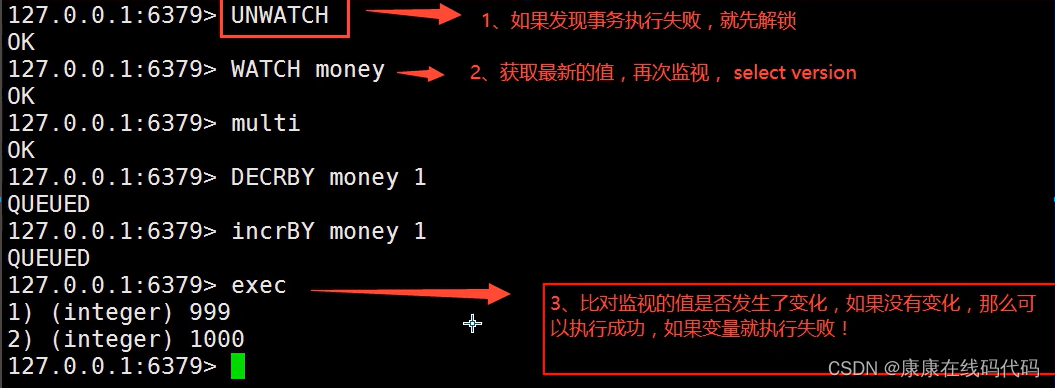 四、Redis缓存
四、Redis缓存
缓存:读写性能较高,降低后端的负载
成本:数据一致性成本、代码维护成本、运维成本
缓存穿透:客户端请求的数据在缓存中和数据库中都不存在,这样缓存永远不会生效,所有请求都会发送的数据库中执行
缓存穿透解决方案
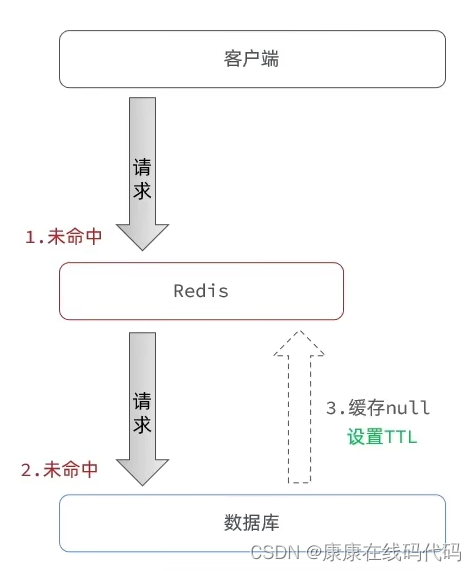
缓存空对象:redis未命中,数据库查询为null,在redis缓存null,确保下次命中
-
优点:实现简单,维护方便
-
缺点:有额外的内存消耗(设置TTL优化内存消耗问题)、可能造成短期的不一致(TTL同样能有效解决不一致问题,但并非完美解决-----可以在插入输入数据库数据后把该数据缓存到redis中覆盖null)
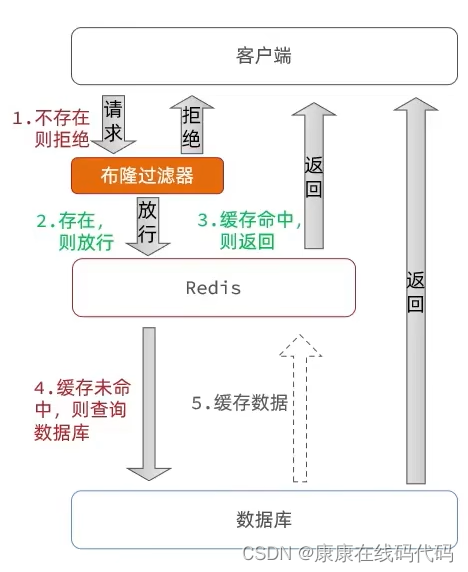
布隆过滤:客户端访问布隆过滤器(判断是否存在),存在则放行,不存在则拒绝(2进制判断原理----不一定百分百准备,也存在穿透风险)
-
优点:内存占用较少,没有多余key
-
缺点:实现复杂、存在误判可能
总结
-
增强id的复杂度,避免被猜测id规律
-
做好数据的基础格式校验
-
加强用户权限校验
-
做好热点参数的限流
缓存雪崩:同一时间段大量的缓存key同时失效或者redis服务器宕机,导致大量请求请求到数据库执行,带来巨大压力
缓存雪崩解决方案
-
给不同的key的TTL添加随机值(避免同一时间段大量的缓存key同时过期)
-
利用redis集群提高服务器的可用性(避免宕机----哨兵模式---主从配置)
-
给缓存业务添加降级限流策略(集群用法)
-
给业务添加多级缓存(集群用法)
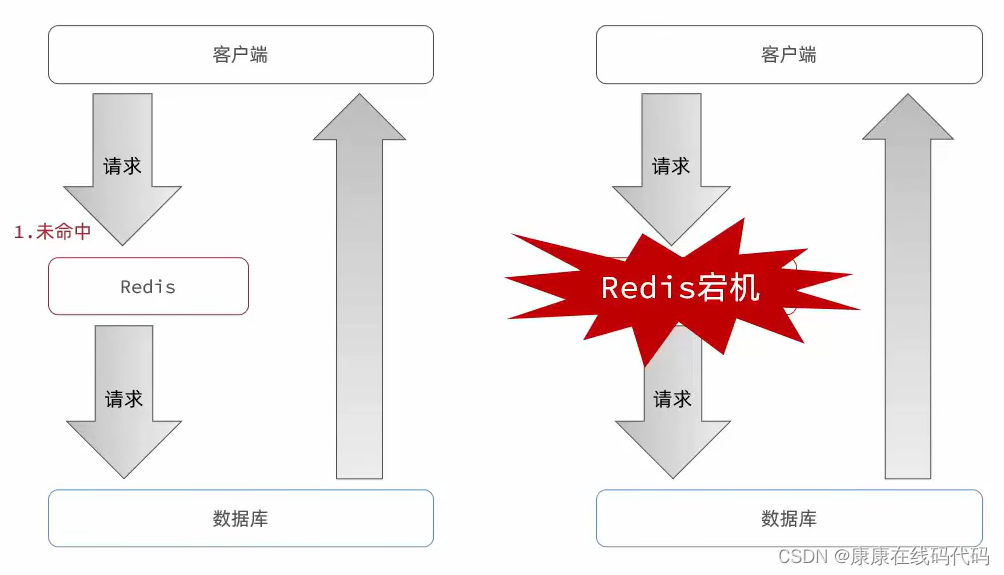
缓存击穿:成为热点key问题,一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给到数据库带来巨大的冲击
缓存击穿解决方案
-
互斥锁(可以使用setnx---实现互斥----释放锁删除key即可)
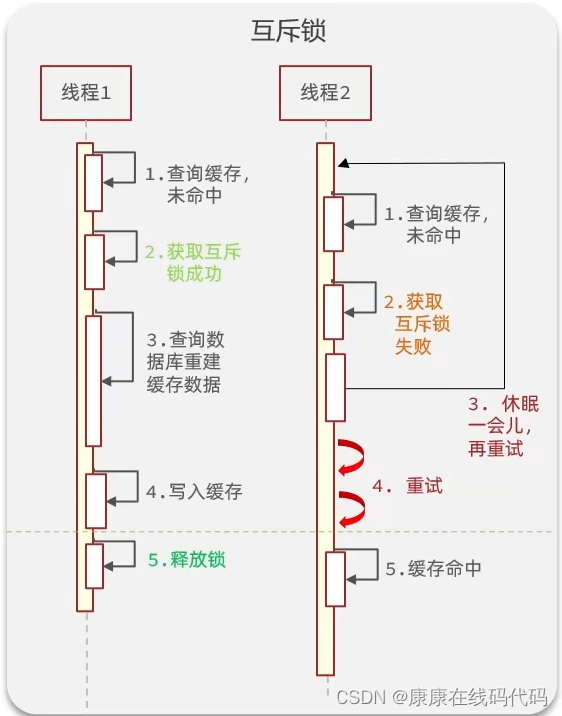
-
逻辑过期
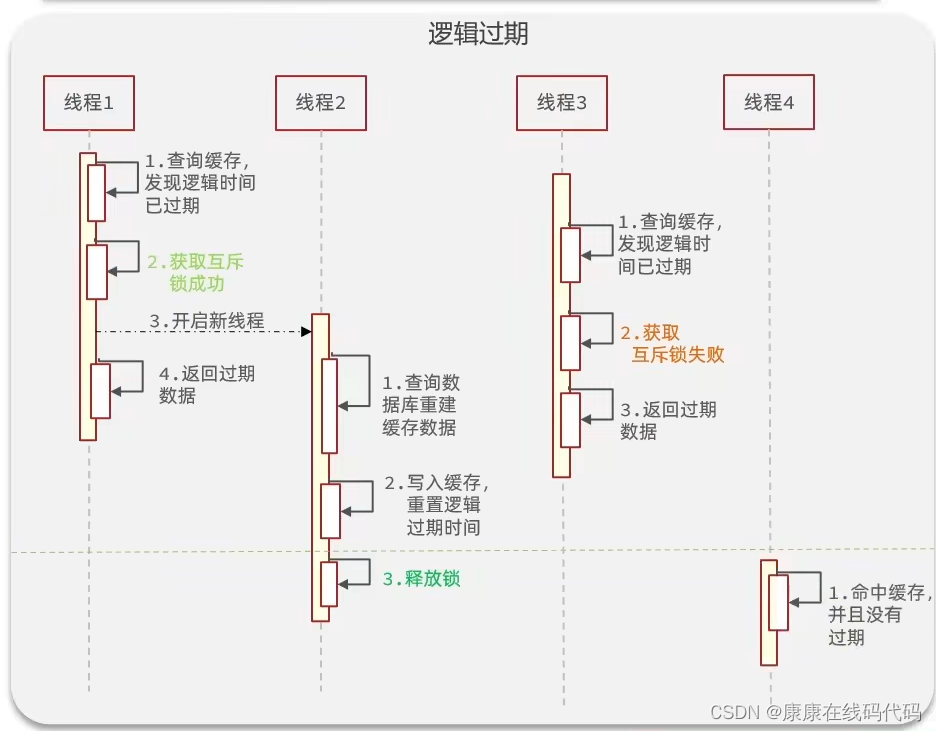
对比:

五、持久化
AOF:AOF是执行完命令后在记录日志

优点:数据的一致性和完整性更高,秒级数据丢失
弊端:
-
执行完命令后还未记录日志中,redis宕机----数据丢失
-
AOF不会阻塞当前命令,但可能阻塞下一个操作
-
数据恢复慢,文件体积大于RDB文件
RDB----默认开启:以快照的形势保存在磁盘上----dump.rdb文件,服务器停机时会自动执行一次PDB保存

优点:恢复大数据集的速度快,适合大规模的数据恢复场景----如备份、全量复制等场景
弊端:
-
无法实时持久化/秒级持久化
-
创建快照过程会阻塞主线程

总结:

AOF和RDB的区别
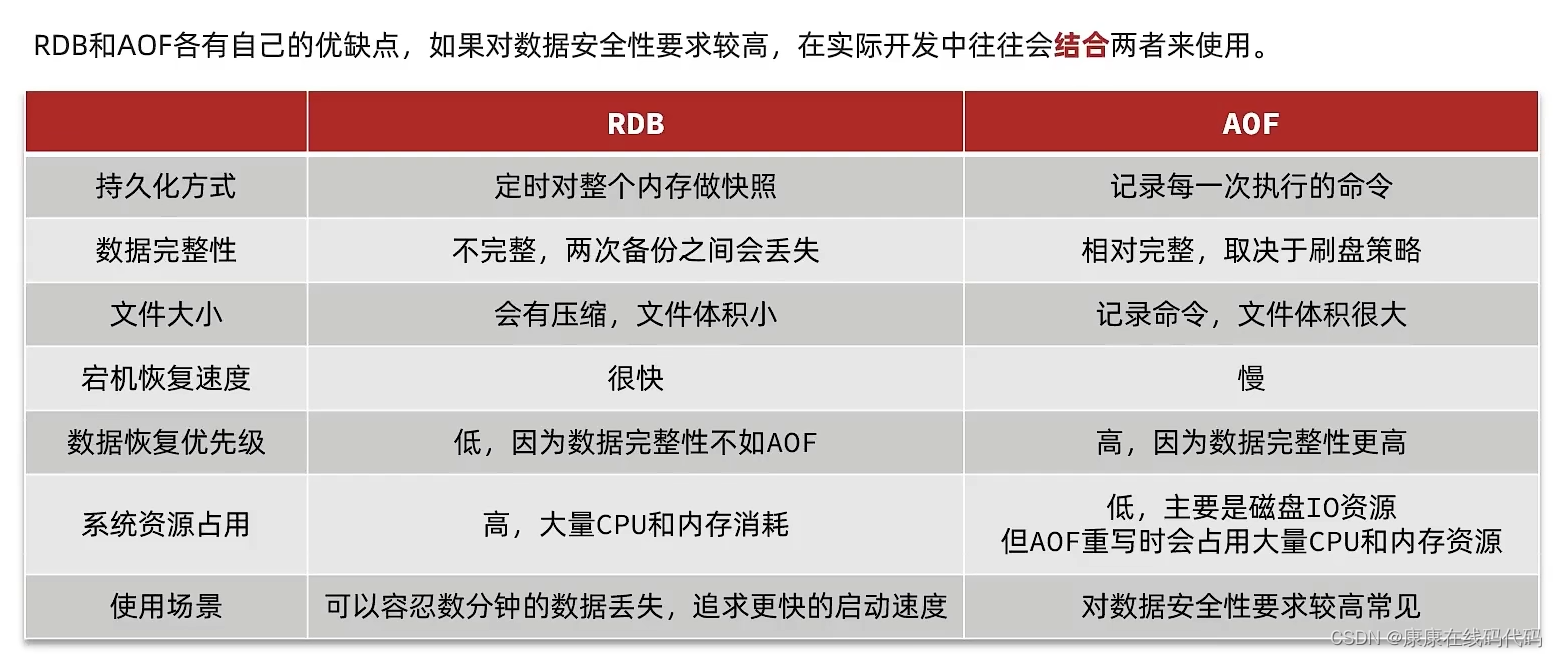
Redis数据备份策略
-
写crontab定时调度脚本,每小时都copy一份rdb或aof的备份到一个目录中去,仅仅保留最近48小时的备份。
-
每天都保留一份当日的数据备份到一个目录中去,可以保留最近1个月的备份。
-
每次copy备份的时候,都把太旧的备份给删了。
-
每天晚上将当前机器上的备份复制一份到其他机器上,以防机器损坏
六、主从集群
主从架构:提高Redis的并发能力,需要搭建主从集群,实现读写分离
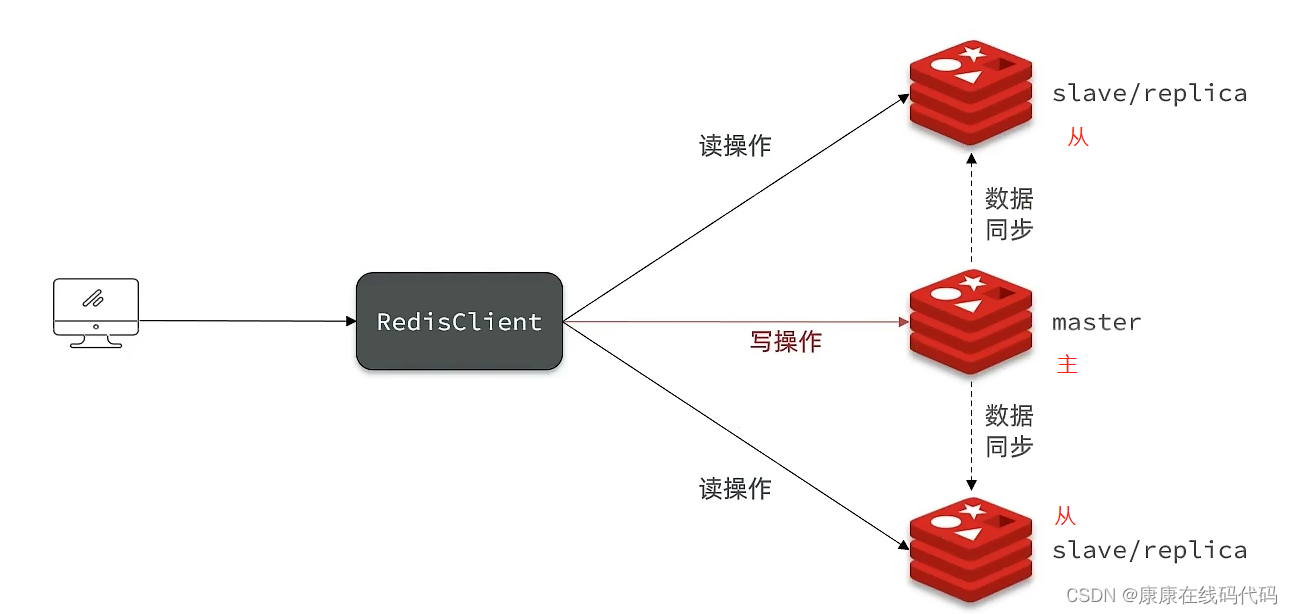
开启主从:
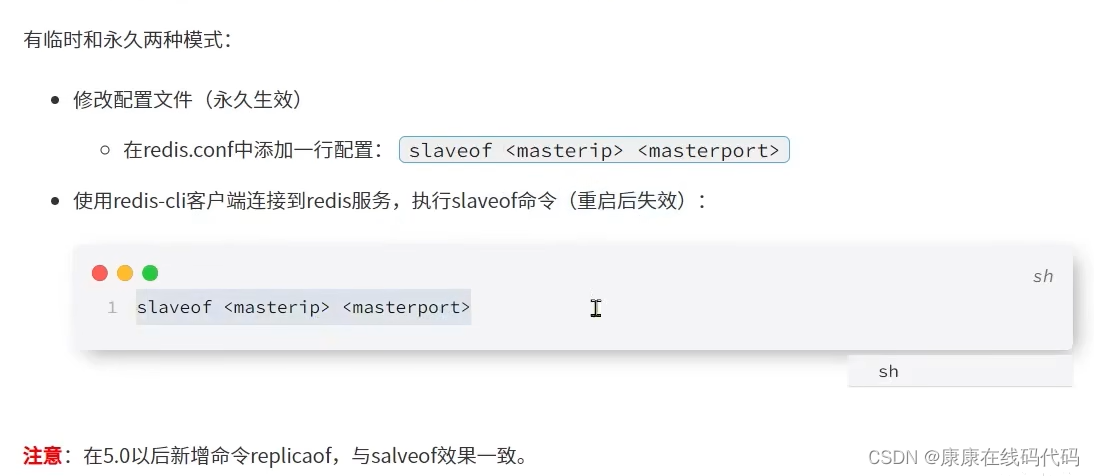


数据同步原理
全量同步:第一次同步----全量同步
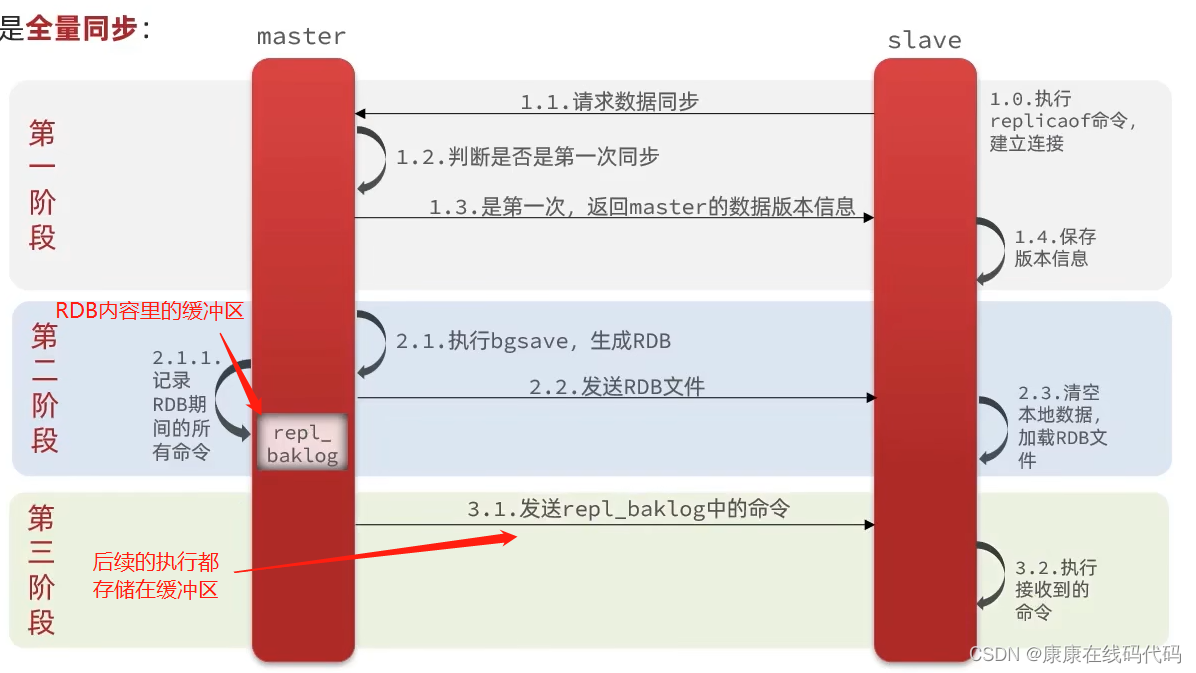
 简述全量同步流程
简述全量同步流程

增量同步:


同步优化
-
在master中配置repl-diskless-sync yes启动无磁盘复制,避免全量同步时的磁盘IO
-
Redis单节点上的内存占用不要太大,减少RDB导致的过多磁盘IO
-
适当提高repl_baklog的大小,发现slave宕机时尽快实现故障恢复,尽可能避免全量同步
-
限制一个master上的slave节点数量,如果实在是太多slave,则可以采用主-从-从链式结构,减少master压力
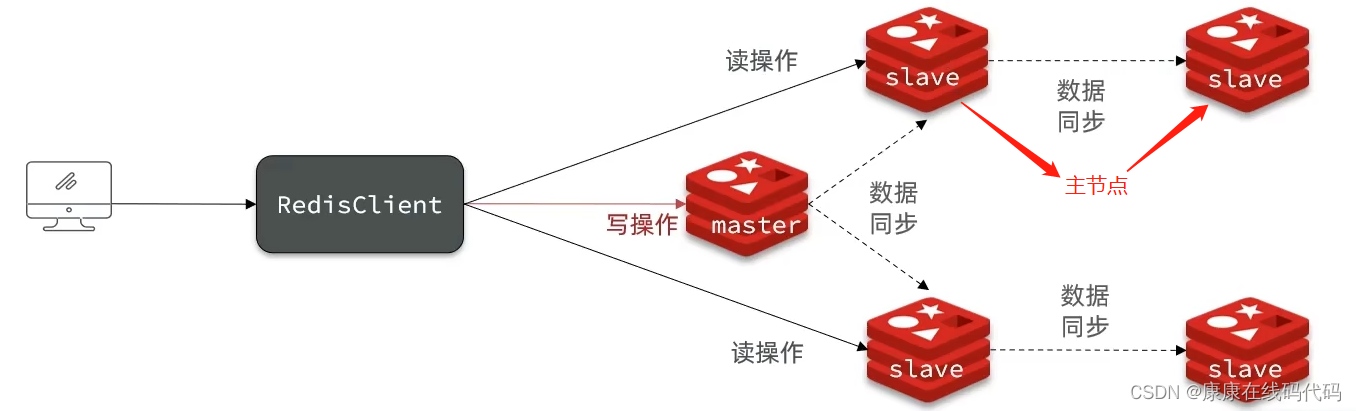
同步总结

七、哨兵模式:实现主从集群的自动故障恢复
-
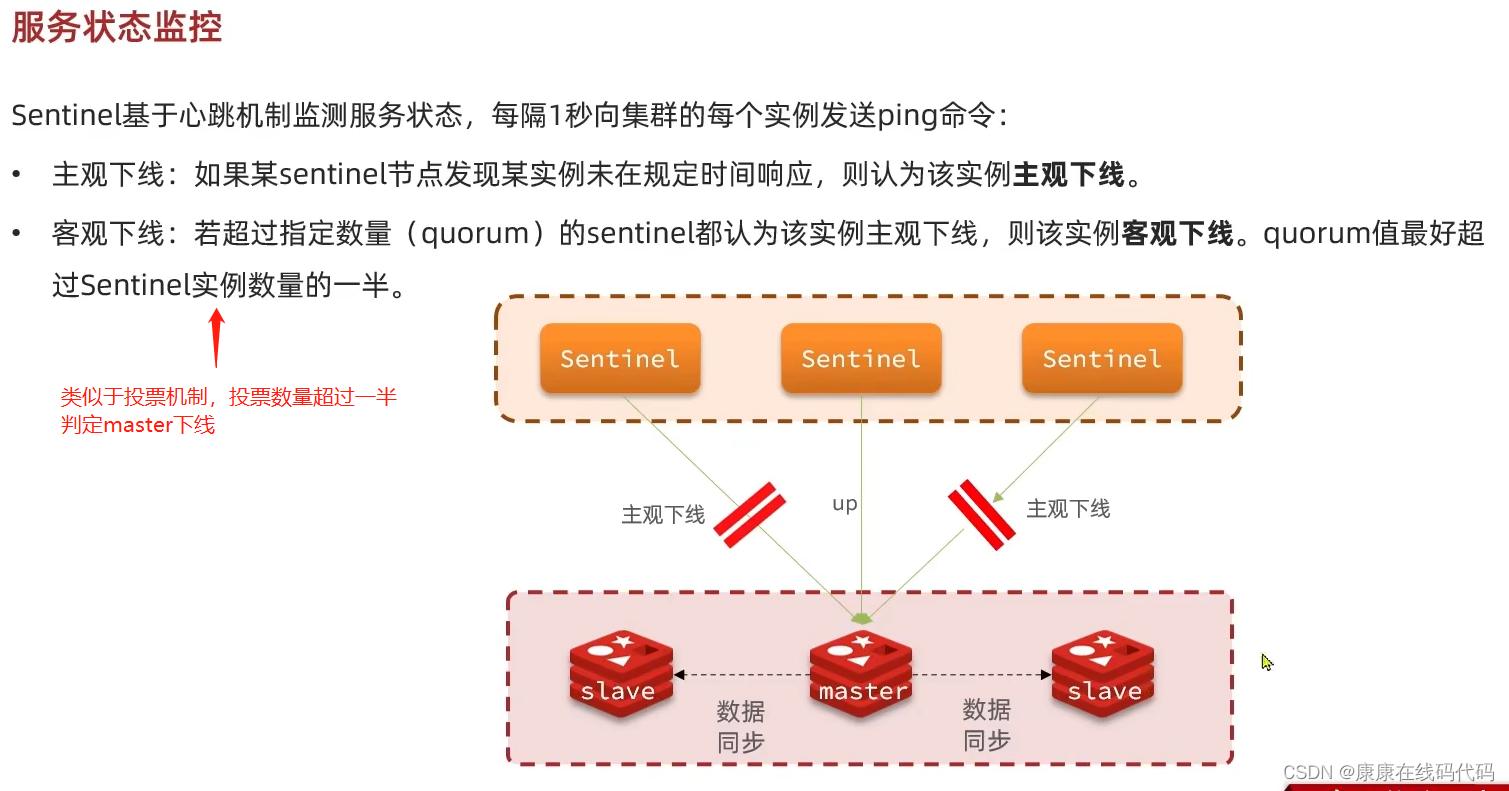
监控:Sentinel会不断检查master和slave是否按预期工作
-
自动故障恢复:如果master故障,Sentinel会将一个slave提升为master。当故障实例恢复后也以新的master为主
-
通知:Sentinel充当Redis客户端的服务发现来源,当集群发送故障转移时,会将最新信息推送给Redis的客户端
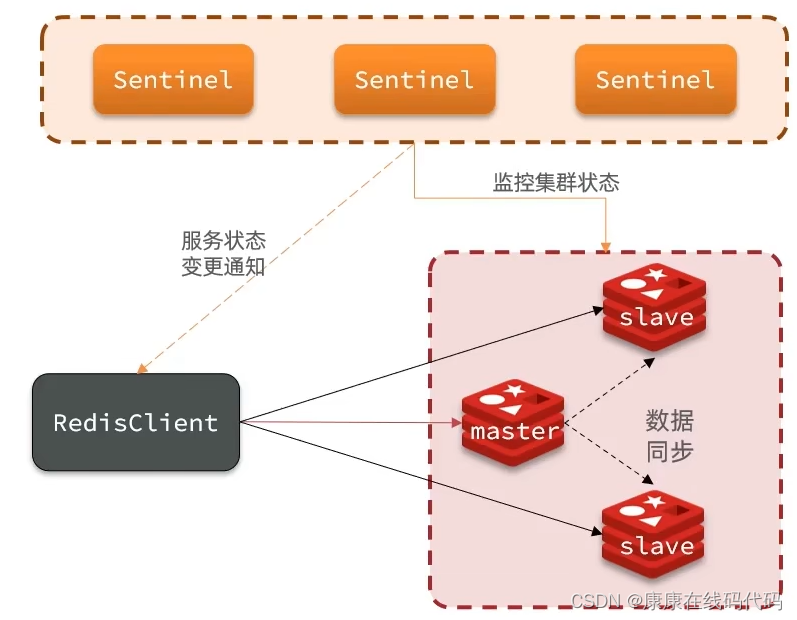
服务状态监控
选举新的master(主节点)

实现故障转移机制

总结

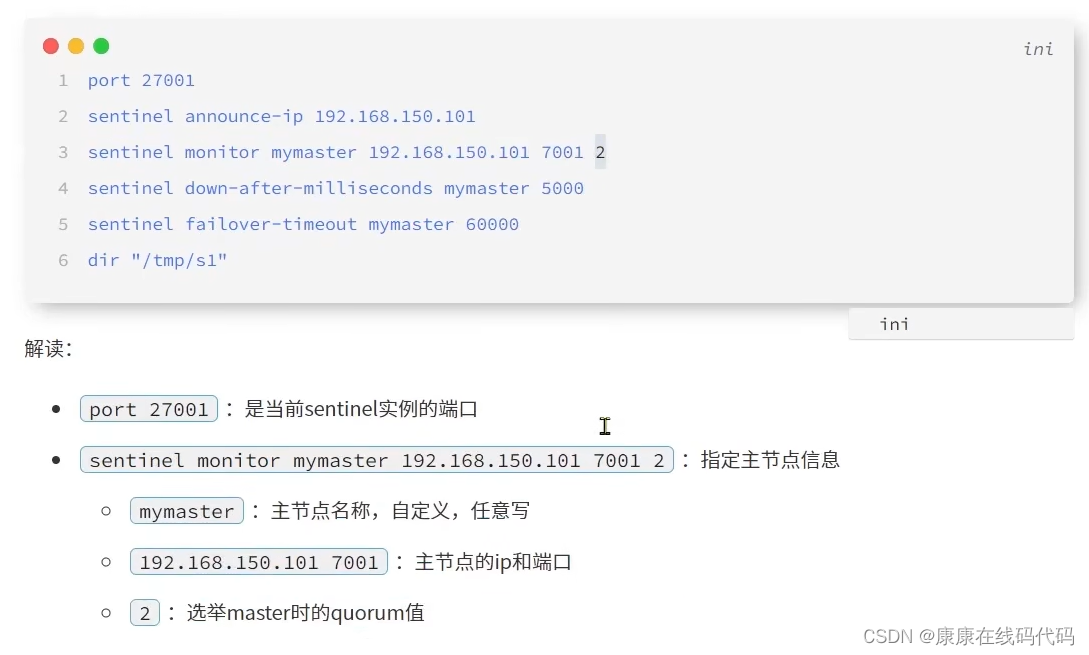
哨兵集群搭建















 2849
2849











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









